本篇文章为大家展示了如何运用LIST和RANGE与HASH分区解决热点数据的分散,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
热点数据通俗的讲是指被高频使用到的数据,比如某些热点事件,由于网络的发酵效应,短时间能够达到几十万甚至上百万的并发量,针对这类场景,我们需要分析系统瓶颈所在,以及应对的技术实现
大并发架构演进
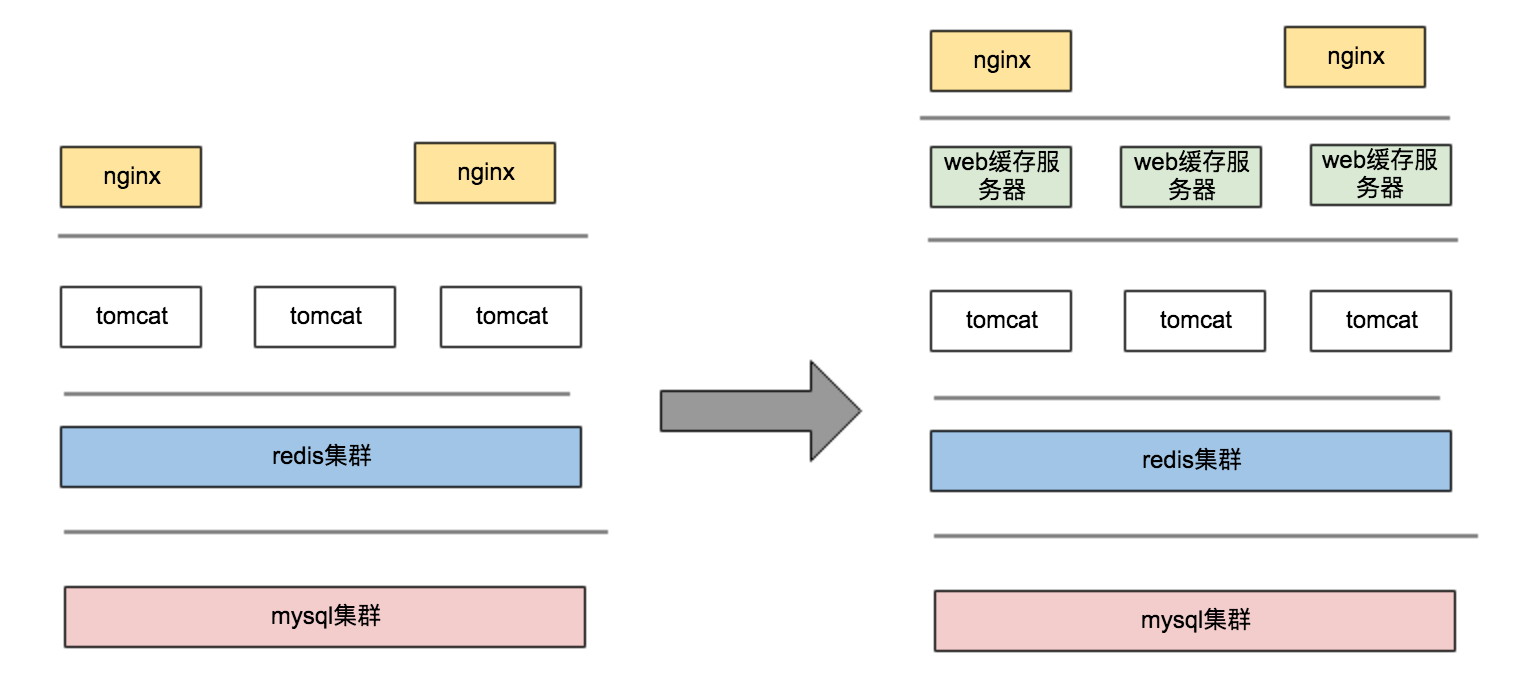
1、图1和图2的区别是中间会有一层web缓存服务器,该服务它可以由nginx+lua+redis进行设计完成,缓存层的热点数据分散,将会在后续的‘高并发度’章节做介绍。
2、热点数据肯定能在web层的缓存服务器被拦截住,防止把大量的请求打到应用服务器,但是对于非热点的数据穿透缓存后会请求至DB,这部分数据每秒几千的QPS对DB造成的压力也是非常大的,这个时候我们需要一定的方案,保证请求的时效性,就是如何降低DB层面的IO次数
场景分类
热点数据并发分为读和写两种场景,日常高并发遇到的大多数都是读场景,无论是采用何种的架构设计,都需要在缓存层和DB层面做热点数据的分散,本章着重介绍后者
原理分析
大家都知道对热点数据分散后,系统的性能会有显著提升,是什么原理导致的,接下来我们探讨一下db存储的一些关键知识,上面两个是大家经常用到的两种mysql存储引擎,尤其是后者,基本上笔者在工作中遇到的绝大多数的表都定义成了innodb引擎,两者的差异在哪里?使用场景的区别在什么地方?
1、读数据
myisam:与innodb一样都采用BTREE实现,myisam是非聚集索引,索引文件和数据文件分离,它对读的效率非常好,为什么呢,是因为它的存储结构决定的,数据顺序存储,树的叶子节点指向的是文件物理地址,所以查询起来效率较高
innodb:它是通过聚集索引实现,按照主键聚集,所以innodb引擎必须要拥有一个唯一标识这列数据的标识,对于聚集索引它的叶子节点存放的是数据,对于innodb的辅助索引它的叶子节点是主键的值,所以查询的时候增加了二次查找,为了避免这种情况,可以直接使用聚集索引去查,但是现实情况是大多数的业务场景我们依然需要借助于辅助索引
2、写数据
myisam:不支持事物,且写优先级高于读优先级,多线程读可并发,读和插入通过优化参数可并发,读和更新不可并发,锁的级别是表级别锁
innodb:支持事物,可以实现读写并发,行级别锁,写性能优于myisam的引擎
3、数据页
是innodb数据存储的一个基本单位,可以通过优化innodb_page_size参数进行修改,默认是16K,根据上面提到的聚集索引的原理,索引的大小、单条数据的大小决定了该数据页所能包含的记录条数,包含的数据记录越多,需要做翻页的几率就越小,进行IO的次数相对就会减小
垂直分表
垂直分表是对列做拆解,可以根据业务功能或者冷热去拆解,比如对用户表根据使用冷热场景进行拆解的示意图如下:
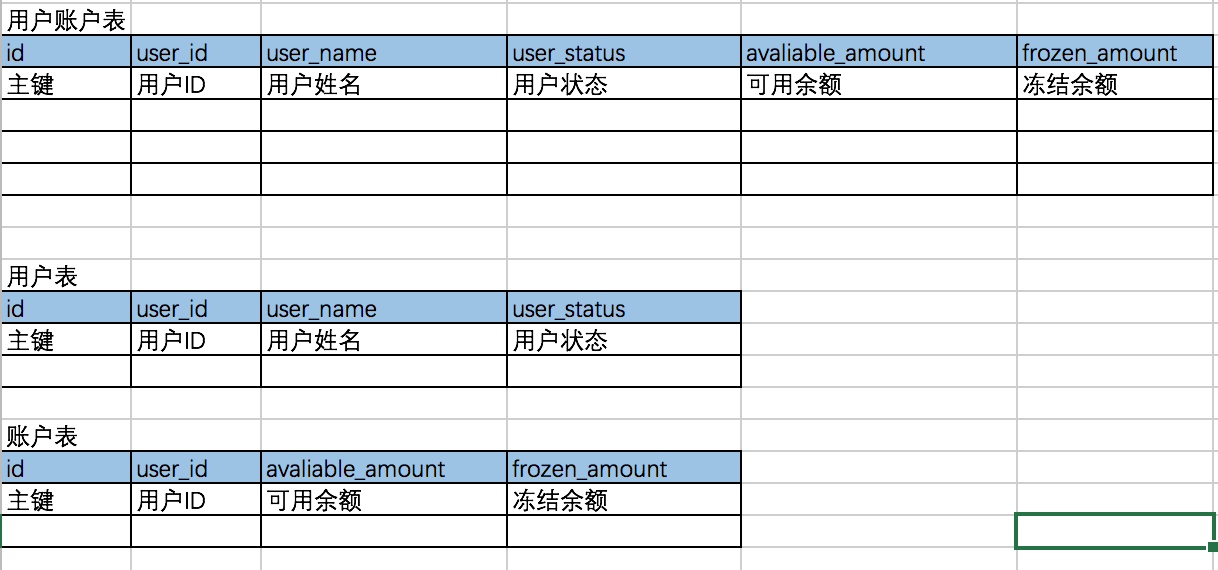
垂直分表的意义是在于将热表进一步拆分,降低数据表的因为单行长度过大,导致的多页查询,引起的IO过多问题
水平分表
水平分表是对行做拆解,拆完以后单张表的数据量会更小
比如对5000万的数据量,做水平分表,原来单表5000万的数据记录,拆分为10张表以后,每张表则为500万记录
每个索引页的大小固定默认16K,所以在单页大小固定的情况下,单表记录越多,索引页的页数越多,查询期间分页的概率和频次就会增加
水平分表就是解决这个问题,分表的实现方式:分区、分表/分库,具体参考下面的介绍。
最佳实践
1、冷热数据分离
以文章内容系统为例:标题、作者、分类、创建时间、点赞数、回复数、最近回复时间
1.1、冷数据:可以理解成偏静态的数据,会频繁的被读取,但是几乎或者很少被改变,这类数据对读的性能要求较高,数据存储可以使用myisam引擎
1.2、热数据:数据内容被频繁改变,这类数据对并发读写要求较高,我们可以使用innodb引擎存储
根据具体的使用场景使用不同的存储引擎,以达到性能的相对最优,将文章内容系统的表结构进行冷热拆分,拆分后的表结构如下:

1.3、拆分前后性能比对
插入100000条数据,对拆分前后的文章表做查询,性能比对的趋势如下,同样都是模拟50个并发,一共2500次请求,每个线程50个请求,采用ID随机,这样更贴近真实的查询场景,很明显拆分后的效果更胜一筹:
拆分后单表测试:
mysqlslap -h227.0.0.1 -uroot -P3306 -p --concurrency=50 --iterations=1 --engine=myisam --number-of-queries=2500 --query='select * from cms_blog_static where id=RAND()*1000000' --create-schema=test
未拆分测试:
mysqlslap -h227.0.0.1 -uroot -P3306 -p --concurrency=50 --iterations=1 --engine=innodb --number-of-queries=2500 --query='select * from cms_blog where id=RAND()*1000000' --create-schema=test
2、减少单行数据大小
对于拆分以后的数据表,我们能否进一步降低单行数据的大小呢,总结起来常用的方法如下:
2.1、设置合理的字段长度
大家都知道不同的字段类型占用的存储空间不同,如下图:
| 类型 | 长度(字节) | 定长/非定长 | |
| TINYINT | 1 | 定长 | |
| SMALLINT | 2 | 定长 | |
| MEDIUMINT | 3 | 定长 | |
| INT | 4 | 定长 | |
| BIGINT | 8 | 定长 | |
| FLOAT(m) | 4字节(m<=24)、8字节(m>=24 and m<=53) | 非定长 | |
| FLOAT | 4 | 定长 | |
| DOUBLE | 8 | 定长 | |
| DOUBLE PRECISION | 8 | 定长 | |
| DECIMAL(m,d) | m字节(m>d)、d+2字节(m<d) | 非定长 | |
| NUMBER(m,d) | m字节(m>d)、d+2字节(m<d) | 非定长 | |
| DATE | 3 | 定长 | |
| DATETIME | 8 | 定长 | |
| TIMESTAMP | 4 | 定长 | |
| TIME | 3 | 定长 | |
| YEAR | 1 | 定长 | |
| CHAR(m) | m | 非定长 | |
| VARCHAR(m) | l字节,l就是实际存储字节(l<=m) | 非定长 | |
| BLOB, TEXT | l+2字节,l就是实际存储字节 | 非定长 | |
| LONGBLOB, LONGTEXT | l+4字节,l就是实际存储字节 | 非定长 |
我们在实际使用中,需要根据实际的需要选择合理的类型,能有效的减小单行数据的大小,比如,user_status,一般我们定义成tinyint(1)即可,没必要定义成int,白白多占用3个字节
2.2、设置合理的索引长度
2.2.1、对于需要建索引的字段,如果字段占用的空间越大,对于索引来说,建立索引的长度就越长,索引页大小不变的情况下,数据条数就越少,查询需要做IO的次数就越频繁
2.2.2、对于某些索引字段,如果我们可以通过前缀字段能达到很好的区分度,则可以控制创建索引的长度,目的是索引页的含的数据行数更多,减少IO,方式如下:
//如下,我们根据字段1和字段2,指定的组合索引的长度
alter table table_name add index index_name (field1(length2),field2(length3))2.2.3、索引的选择性
索引本身是由开销的,首先是存储资源,然后插入和更新带来的对B+Tree树的维护,数据更新带来的性能下降,所以对于我们的原则是:索引该不该建,以及用什么字段建
数据量少-则不建,区分度或者选择性不高-则不建,数据量少大家很容易理解,小于1W条数据全表扫描也能接收,选择性或者区分度是指,数据的分散程度,比如某个用户表,有一个性别字段,数据量越大它的索引选择性越差,计算公式如下:
//返回值范围(0,1],该值越大,索引选择性越高
select distinct(col)/count(*) from table_name同理,对于需要控制索引长度的字段,计算选择性如下:
select distinct(left(col,n))/count(*) from table_name2.2.4、性能比较
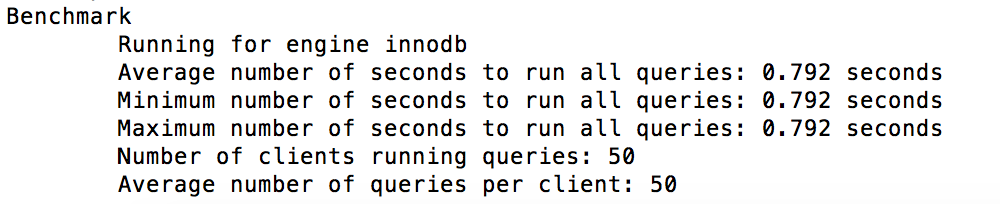
通过对100w的数据,对数据行大小做优化,前后性能比对结果如下:
优化前后的表结构定义如下:
--优化前
CREATE TABLE `cms_blog` (
`id` bigint(20) NOT NULL auto_increment,
`title` varchar(60) NOT NULL,
`creator` varchar(20) NOT NULL,
`blog_type` tinyint(1) not NULL,
`reply_praise` int(10) UNSIGNED,
`reply_count` int(10) UNSIGNED,
`create_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00',
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=innodb DEFAULT CHARSET=utf8;
--创建索引
alter table cms_blog add index idx_reply_count (reply_count);
--优化后reply_praise和reply_count
CREATE TABLE `cms_blog_v2` (
`id` bigint(20) NOT NULL auto_increment,
`title` varchar(60) NOT NULL,
`creator` varchar(20) NOT NULL,
`blog_type` tinyint(1) not NULL,
`reply_praise` MEDIUMINT(10) UNSIGNED,
`reply_count` MEDIUMINT(10) UNSIGNED,
`create_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00',
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=innodb DEFAULT CHARSET=utf8;
--创建索引
alter table cms_blog_v2 add index idx_reply_count (reply_count);压测脚本如下:
--压测脚本,旧表
mysqlslap -h227.0.0.1 -uroot -P3306 -p --concurrency=50 --iterations=1 --engine=innodb --number-of-queries=2500 --query='select * from cms_blog where reply_count>999990' --create-schema=test
--压测脚本,新表
mysqlslap -h227.0.0.1 -uroot -P3306 -p --concurrency=50 --iterations=1 --engine=innodb --number-of-queries=2500 --query='select * from cms_blog_v2 where reply_count>999990' --create-schema=test性能表现,旧表和新表压测表现如下:

新表优化后性能明显有提升:
2.3、主键的选择
尽量使用保持单调性的自增主键,避免使用uuid、hash方式、业务自定义主键,减少索引重建对性能的影响
3、分散数据页查询
3.1、数据分区
数据分区可以有效的提升查询的性能,充分利用不同分区所关联的IO存储,在逻辑上是属于同一张表,物理上可以分散到不同的磁盘存储,缺点是跨分区查询的性能稍差,所以互联网公司在实际当中很少用到数据分区,一般建议物理分表的方式实现
CREATE TABLE table_name (
id INT AUTO_INCREMENT,
customer_surname VARCHAR(30),
store_id INT,
salesperson_id INT,
order_date DATE,
note VARCHAR(500),
INDEX idx (id)
) ENGINE = INNODB
PARTITION BY LIST(store_id) (
PARTITION p1
VALUES IN (1, 3, 4, 17)
INDEX DIRECTORY = '/var/path3'
DATA DIRECTORY = '/var/path2';3.1.1、分区方式
3.1.1.1、RANGE partitioning
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN (21)
);3.1.1.2、LIST Partitioning
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LIST(store_id) (
PARTITION pNorth VALUES IN (3,5,6,9,17),
PARTITION pEast VALUES IN (1,2,10,11,19,20),
PARTITION pWest VALUES IN (4,12,13,14,18),
PARTITION pCentral VALUES IN (7,8,15,16)
);3.1.1.3、COLUMNS Partitioning
--range columns
CREATE TABLE rc1 (
a INT,
b INT
)
PARTITION BY RANGE COLUMNS(a, b) (
PARTITION p0 VALUES LESS THAN (5, 12),
PARTITION p3 VALUES LESS THAN (MAXVALUE, MAXVALUE)
);
--list columns
CREATE TABLE customers_1 (
first_name VARCHAR(25),
last_name VARCHAR(25),
street_1 VARCHAR(30),
street_2 VARCHAR(30),
city VARCHAR(15),
renewal DATE
)
PARTITION BY LIST COLUMNS(city) (
PARTITION pRegion_1 VALUES IN('Oskarshamn', 'Högsby', 'Mönsterås'),
PARTITION pRegion_2 VALUES IN('Vimmerby', 'Hultsfred', 'Västervik'),
PARTITION pRegion_3 VALUES IN('Nässjö', 'Eksjö', 'Vetlanda'),
PARTITION pRegion_4 VALUES IN('Uppvidinge', 'Alvesta', 'Växjo')
);3.1.1.4、HASH Partitioning
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY HASH(store_id)
PARTITIONS 4;3.1.1.5、KEY Partitioning
CREATE TABLE tk (
col1 INT NOT NULL,
col2 CHAR(5),
col3 DATE
)
PARTITION BY LINEAR KEY (col1)
PARTITIONS 3;3.2、数据分表/分库
数据分表解决的问题,提升单表的并发能力,文件分布在不同的表文件,对IO性能进一步提升,另外对读写锁影响的数据量变少,插入数据需要做索引重建的数据减少,insert或update性能会更好
3.2.1、分表和分库方式
3.2.1.1:哈希取模方式,hash(关键字)%N
3.2.1.2:按照时间,如按照年或者月分表
3.2.1.3、按照业务,以订单业务为例,平台订单、三方订单
3.2.2、分库分表中间件
整体来说分为在客户端实现,和代理端实现,比如:cobar、sharding-jdbc、mycat等,具体使用可以自行检索
上述内容就是如何运用LIST和RANGE与HASH分区解决热点数据的分散,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/13426421702/blog/3103781



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



