这篇文章将为大家详细讲解有关开源 Levin:数据闪电加载方案,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
互联网某些业务场景下,我们常会遇到这种情况:服务启动需要加载大量数据到内存,数据规模达数十G,数据更新频率较低(天级、小时级、分钟级),使用方式为静态查询。如业务订单数据、线下挖掘的策略规则,地图路网数据等。而在线服务基于稳定性考虑通常至少加载双版本数据,服务启动通常需要数分钟之久。暴露的问题包括服务上线旷日持久,人力成本高;需求排队无法快速迭代,时间成本高;回滚速度慢,由于要加载大量数据故障实例无法快速恢复造成稳定性隐患。
Levin是针对上述低频更新、静态使用、大规模数据的快速加载方案,高效托管大规模静态数据,加速大内存服务冷启动和热加载。
服务启动唯快不破,但是在单纯的服务变更场景中(比如上线、回滚、故障恢复)虽然并不涉及任何数据变更,服务进程重启导致堆和栈内存数据都会随之消亡,启动后需要重新加载数据。那么数据能不能在进程间传递复用呢?最高效的进程间数据传递方式就是共享内存,共享内存可以突破进程生命周期实现跨进程重用,并且具有内存对象访问效率和充足的可用地址空间(下图Memory Mapping Area),鱼(启动速度)与熊掌(查询效率)可以兼得。
Levin1.jpg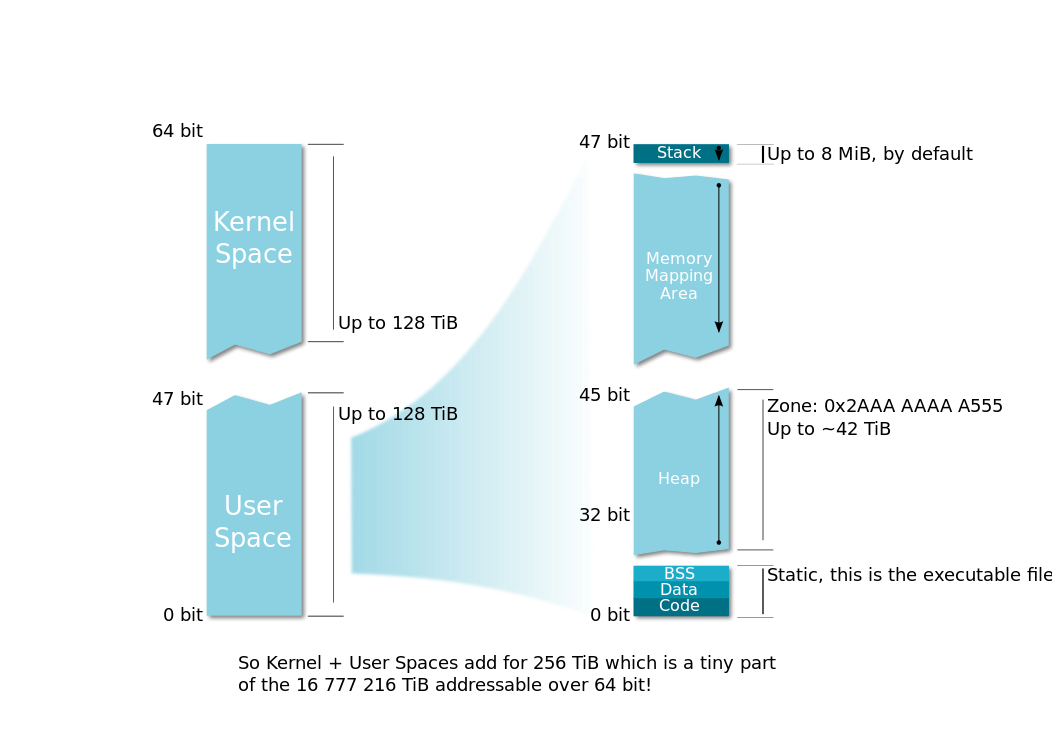
再考虑数据更新场景,通常指数据版本切换,此时磁盘数据读取在所难免,那么从数十G的数据文件到内存数据对象(通常为STL容器),是否存在更高效的转换方式?思考如果直接离线编译出数据对象内存布局写入二进制文件,在线服务启动时进行一次性共享内存分配和IO读取,可以进一步提高加载效率。
在确定了使用共享内存和容器数据离线编译之后,关键的问题来了,如何将容器放入共享内存?最大的障碍是指针和容器内存不连续性。Levin的武器是降维:容器对象内存布局一维化,在一维世界中只需首地址加长度就可以表达、读取和复制整个容器对象。由于同一块共享内存会映射到不同进程的不同虚拟地址,使用偏移量代替容器中的指针,实现地址无关的容器。
我们也对造好的轮子(Boost interprocess容器)进行调研,发现其基线测试性能表现不佳:最常用的vector/hashmap查询效率较标准容器慢10%~20%左右。最终Levin选择了自定义共享内存容器,并在数据静态使用方式的前提下做了一系列优化,具备简单易用、效率高、性能好、内存省的优点。并实现了工程化应用落地不可或缺的功能:如共享容器内存校验、版本管理。
▍STL-like共享内存容器
支持托管在共享内存片段上的容器,包括常用容器vector、set、map、hashset、hashmap等。并支持使用适配、组合、特化等手段自定义共享内存容器。 基线测试表明Levin容器查询性能较标准容器有所提升,内存使用效率优势明显(详见benchmark)
Levin2.jpg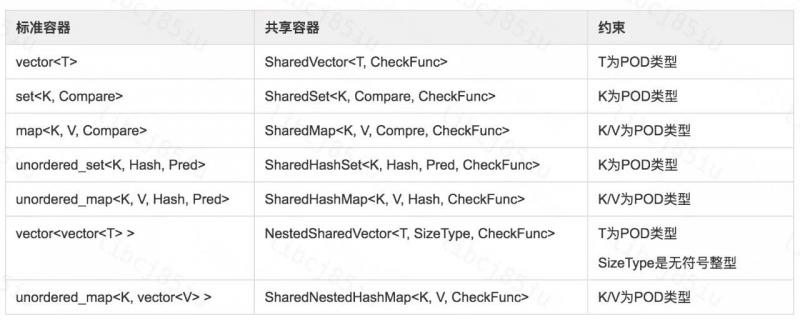
▍离线数据编译
高效使用数据是在线服务的目标,数据规范化是构建复杂系统的前提。 很多以数据为核心的系统都会将数据流程划分为离线编译和在线加载,其中离线数据编译是数据高效转换的重要一环,利用离线单节点把数据转换为可以方便使用的格式,省掉在线服务多节点重复的转换和构建工作。 Levin支持离线数据编译功能,将原始数据编译为进程可直接读入的共享容器对象内存布局二进制文件,为在线服务提供更加高效的数据服务。
▍在线数据加载
加载离线阶段编译产出的数据文件至命名共享内存区域,支持共享容器对象申请、校验、加载、释放。 Levin在线数据加载进行一次性共享内存分配和读取,省掉构建过程大量brk/mmap内存分配系统调用,减少IO次数,为在线服务数据加载进一步提速。下图是以上介绍的数据使用流程,推荐这种方式。
Levin3.jpg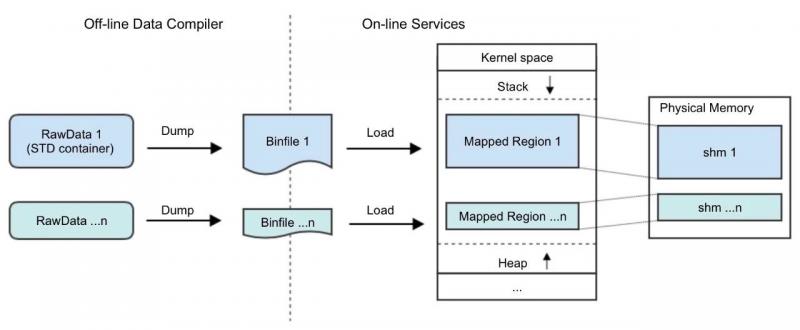
▍管理模块
用户大量使用共享容器时,共享容器使用情况全景不透明,逐个释放容易遗漏,服务出现异常等情况下会导致无用数据驻留内存空间,浪费节点内存资源。 Levin提供管理模块,支持共享容器以集合(group)的方式进行管理,相同生命周期的共享容器可交由同一管理模块实例托管,进行统一的创建、加载,释放。管理模块还支持共享容器全局搜索功能。支持安全释放、清理功能,避免容器数据异常销毁或无用容器驻留系统。支持可定制的数据文件校验方式,降低文件校验耗时。
▍版本切换
使用Levin管理模块对同版本容器数据进行group管理,卸载特定版本时可安全、统一释放相应的共享容器集合,完美支撑用户数据版本热切换需求实现。
Levin内部应用实践效果:落地服务冷启动和热加载耗时均由分钟级降至秒级。内存用量方面优化明显,Levin容器静态数据转而由共享内存托管,与服务session动态数据分离。观察数据版本切换场景,磁盘IO次数大幅降低,切换导致的cpu抖动也明显缓解。以上,本文开头提到的人力、时间成本浪费和稳定性隐患问题迎刃而解。
关于开源 Levin:数据闪电加载方案就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





