如何预测读写锁的死锁问题,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
死锁在日常生活中并不鲜见。生活在大城市的人都或多或少经历过下图所示的场景。在环岛或者十字路口出现的这种情况就是死锁。也许其中有车坏了,但是绝大多数车子是可以运行的。可是因为每辆车都得等着前车走动它才能走动,所有车都走不动,或者更一般地讲它们不能取得进展(Make Forward Progress)。这种情况发生的原因是车辆的等待构成了循环,在这个循环中每辆车的状态都是等待前车,因此所有车都等不到到它所要等待的。这种车辆死锁状态会持续恶化并产生严重的后果:首先造成路口交通堵塞,而堵塞如果进一步扩大会导致大面积交通瘫痪。车辆死锁很难自愈,通过自身走出死锁状态非常困难或者需要很长时间,一般都只能通过人工(如交通警察)干预才能解决。
 图1:环岛道路的交通堵塞(图片来源于网络)
图1:环岛道路的交通堵塞(图片来源于网络)
在多线程或者分布式系统程序中,死锁也会发生。其本质和上述的路口车辆堵塞是一样的,都是因为参与者构成了循环等待,使得所有参与者都等不到想要的结果,从而永远等在那里不能取得进展。Linux 内核当然也会发生死锁,如果核心部分(Core),如调度器和内存管理,或者子系统,如文件系统,发生死锁,都会导致整个系统不可用。
死锁是随机发生的。就像上图中环岛的情况一样,环岛就在那里而死锁并不是总在发生。但是环岛本身就是死锁隐患,尤其在交通压力比较大的路口,环岛会比较容易产生死锁。而如果这种路口设计成交通信号灯就会好很多,如果设计成立交桥则又会好很多。在程序中,我们把可能产生死锁的场景称作潜在死锁(Potential Deadlock Scenario),而把即将发生或正在发生的死锁称为死锁实例(Concrete Deadlock)。
如何对付死锁一直是学术界和应用领域积极研究和解决的问题。我们可以将对死锁的解决方案粗略地分为:死锁发现(Detection)、死锁避免(Prevention)和死锁预测(Prediction)。死锁发现是指在在程序运行中发现死锁实例;死锁避免则是在发现死锁实例即将生成时进一步防止这个实例;而死锁预测则是通过静态或者动态方法找出程序中的潜在死锁,从而从根本上预先消除死锁隐患。
在死锁中,因为用锁(Lock)不当而导致的死锁是一个重要死锁来源。锁是同步的一种主要手段,用锁是不可避免的。对于复杂的同步关系,锁的使用会比较复杂。如果使用不当很容易造成锁的死锁。从等待的角度来说,锁的死锁是由于参与线程等待锁的释放,而这种等待构成了等待循环,如 ABBA 死锁:
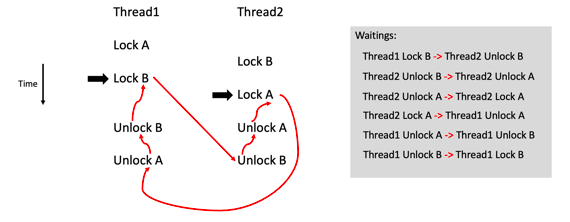 图2:两线程ABBA死锁
图2:两线程ABBA死锁
其中,线程中的黑色箭头代表线程当前执行语句,红色箭头表示线程语句之间的等待关系。可以看到,红色箭头构成了一个圆圈(或者循环)。再一次回顾潜在死锁和死锁实例,如果这两个线程执行的时间稍有改变,那么很有可能不会发生死锁实例,比如如果让 Thread1 执行完这一段代码 Thread2 才开始执行。但是这样的用锁行为(Locking Behavior)毫无疑问是一个潜在死锁。
进一步可以看出,如果我们能够追踪并分析程序的用锁行为就有可能预测死锁或者找出潜在死锁,而不是等死锁发生时才能检测出死锁实例。Linux 内核的 Lockdep 工具就是去刻画内核的用锁行为进而预测潜在死锁并报告出来。
Lockdep 能够刻画出一类锁(Lock Class)的行为,主要是通过记录一类锁中所有锁实例的加锁顺序(Locking Order),即如果一个线程拿着锁A,在没有释放前又去拿锁B,那么锁A和锁B就有一个 A->B 的加锁顺序,在 Lockdep 中这个加锁顺序被称为:锁依赖 (Lock Dependency)。同样的,对于 ABBA 类型的死锁,我们并不需要 Thread1 和 Thread2 恰好产生一个死锁实例,只要有线程产生了 A->B 加锁顺序行为,又有线程产生了一个 B->A 的加锁顺序行为,那么这就构成了一个潜在死锁,如下图所示:
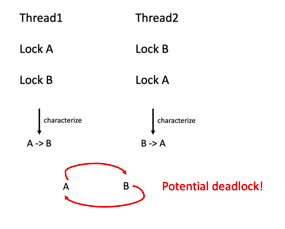 图3:线程ABBA加锁顺序
图3:线程ABBA加锁顺序
由此推广开来,我们可以把所有的加锁顺序(即锁依赖)记录和保存下来,构成一个加锁顺序图(Graph)。其中,如果有锁依赖 A->B ,又有锁依赖 B->C ,那么由于锁依赖的关系(Relation)是传递的(Transitive),因此我们还可以得到锁依赖 A->C 。 A->B 和 B->C 称为直接依赖(Direct Dependency),而 A->C 称为间接依赖(Indirect Dependency)。对于每一个新的直接锁依赖,我们去检查这个依赖是否和图中已经存在的锁依赖构成一个循环,如果是的话,那么我们就可以预测产生了一个潜在死锁。
刚才我们所指的锁都是互斥锁(Exclusive Lock)。读写锁是一种更复杂的锁,或者说一种通用的锁(General Lock),我们可以认为互斥锁是只用写锁的读写锁。只要没有写锁或者写锁的争抢,读锁允许读者(Reader)同时持有。 Linux 内核中有多种读写锁,主要包括: rwsem 、 rwlock 和 qrwlock 等。问题是,读写锁会让死锁预测变得异常复杂, Lockdep 就不能支持这几种读写锁,因此 Lockdep 在使用过程中会产生一些相关的错误假阳性(False Positive)死锁预测和错误假阴性(False Negative)死锁预测。这个问题已经存在超过10年以上,我们提出一个通用的锁的死锁预测算法,并证明这个算法解决了读写锁的死锁预测问题。
在描述这个算法的过程中,我们通过提出几个引理(Lemma)来解释或者证明我们所提出的死锁预测的有效性。
基于引理1,解决死锁预测问题就是在最后一个拿锁顺序(即锁依赖)形成等待圆环(循环)时,通过某种方法计算出这个等待圆环是否构成潜在死锁,而我们的任务就是找到这个方法(算法)。
对于任何一个死锁实例来说,假定有 n 个线程参与到这个死锁实例中,这 n 个线程表示为:
T1,T2,…,Tn
考虑 n 的情况:
如果 n=1:这种死锁即线程自己等待自己,在 Lockdep 中被称为递归死锁(Recursion Deadlock)。由于检查这种死锁较为简单,因此在下面的算法中忽略这种特殊情况。 如果 n>1:这种死锁在 Lockdep 中被称为翻转死锁(Inversion Deadlock)。对于这种情况,我们将这 n 个线程分成两组,即 T1,T2,…,Tn-1 和 Tn ,然后把前一组中的所有锁依赖合并在一起并假想所有这些依赖存在于一个虚拟的线程中,于是得到两个虚拟线程 T1 和 T2 。
这就是引理2中所述的两个虚拟线程。基于引理2,我们提出一个死锁检查双线程模型(Two-Thread Model)来表示内核的加锁行为:
T1 :当前检查锁依赖之前的所有锁依赖,这些依赖形成了一个锁依赖图。 T2 :当前的待检查的直接锁依赖。
基于引理2和死锁检查双线程模型,我们可以得到如下引理:
基于上述3个引理,我们可以进一步将死锁预测问题描述为,当我们得到一个新的直接锁依赖 B->A 时,我们将这个新依赖设想为 T2 ,而之前的所有锁依赖都存在于一个设想的 T1 产生的一个锁依赖图中,于是死锁预测就是检查 T1 中是否存在 A->B 的锁依赖,如果存在即存在死锁,否则就没有死锁并将 T2 合并到 T1 中。如下图所示:
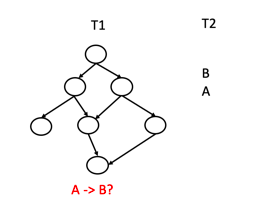 图4:T1的锁依赖图和T2的直接锁依赖
图4:T1的锁依赖图和T2的直接锁依赖
在引入了读写锁之后,锁依赖还取决于其中锁的类型,即读或者写类型。我们根据 Linux 内核中互斥锁和读写锁的设计特性,引入一个锁互斥表来表示锁之间的互斥关系:
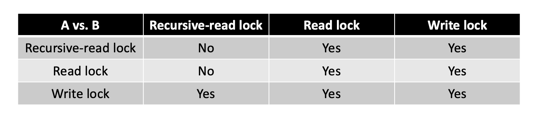 表1:读写锁互斥关系表
表1:读写锁互斥关系表
其中,递归读锁(Recursive-read Lock)是一种特殊的读锁,它能够被同一个线程递归地拿。下面我们首先提出一个简单算法(Simple Algorithm)。基于双线程模型,给定 T1 和 T2 ,和 ABBA 锁:
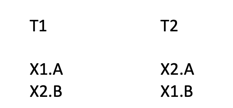 图5:基于双线程模型的简单算法
图5:基于双线程模型的简单算法
简单算法的步骤如下:
如果 X1.A 和 X1.B 是互斥的且 X2.A 和 X2.B 是互斥的,那么 T1 和 T2 构成潜在死锁。
否则, T1 和 T2 不构成潜在死锁。
从简单算法中可以看出,锁类型决定了锁之间的互斥关系,而互斥关系是检查死锁的关键信息。对于读写锁来说,锁类型可能在程序执行过程中变化,那么如何记录所有的锁类型呢?我们基于锁类型的互斥性,即锁类型的互斥性由低到高:递归读锁 < 读锁 < 写锁(互斥锁),提出了锁类型的升级(Lock Type Promotion)。在程序执行过程中,如果碰到了高互斥性的锁类型,那么我们将锁依赖中的锁类型升级到高互斥性的锁依赖。锁类型升级如图所示:
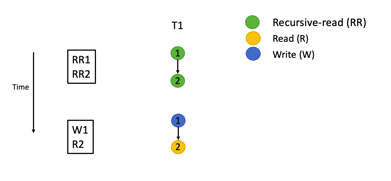 图6:锁类型的升级
图6:锁类型的升级
其中 RRn 表示递归读锁n(Recursive-read Lock n) ,Rn表示读锁n(Read Lock n),Wn代表写锁或者互斥锁n(Write Lock n)。下面 Xn 则表示任意锁n (即递归读、读或者写锁)。
但是,如上简单算法并不能处理所有的死锁预测情况,比如下面这个案例就会躲过简单算法,但事实上它是一个潜在死锁:
 图7:简单算法失败案例
图7:简单算法失败案例
在这个案例中, X1 和 X3 是互斥的从而这个案例构成了潜在死锁。但是简单算法在检查 RR2->X1 时(即 T2 为 RR2->X1 ),根据简单算法能够找到 T1 中有 X1->RR2 ,但是由于 RR 和 RR 不具有互斥性,因而错误认定这个案例不是死锁。分析这个案例为什么得出错误结论,是因为真正的死锁 X1X3X3X1 中的 X3->X1 是间接锁依赖,而间接依赖被简单算法漏掉了。
这个问题的更深层次原因是因为互斥锁之间只有互斥性,因此只要有 ABBA 就是潜在死锁,并不需要检查 T2 的间接锁依赖。而在有读锁的情况下,这一条件不复存在,因此就要去考虑 T2 中的间接锁依赖。
引理4是引理1的引申,根据引理1,这个直接锁依赖一定是形成锁循环的那个最后锁依赖,而引理4说明通过这个锁依赖一定可以通过某种方法判断出锁循环是否是潜在死锁。换句话说,通过修改和加强之前提出的简单算法,新的算法一定能够解决这个问题。但是问题是,原先 T2 中直接锁依赖可能进一步生成了很多间接锁依赖,我们如何才能找到那个最终产生潜在死锁的间接锁依赖呢?更进一步,我们首先需要重新定义 T2 ,再在这个 T2 中找出所有的间接锁依赖,那么 T2 的边界是什么?如果把 T2 扩展到整个锁依赖图,那么算法复杂度会提高非常多,甚至可能超出 Lockdep 的处理能力,让 Lockdep 变得实际上不可用。
根据引理5,我们首先修改之前提出的双线程模型为:
T1:当前检查直接锁依赖之前的所有锁依赖,这些依赖形成了一个图。 T2:当前的待检查的线程的锁栈。
根据引理5和新的双线程模型,我们在简单算法的基础上提出如下最终算法(Final Algorithm):
继续搜索锁依赖图即 T1 寻找一个新的锁依赖循环。 在这个新的循环中,如果有 T2 中的其他锁存在,那么这个锁和 T2 中的直接锁依赖构成一个间接锁依赖,检查这个间接锁依赖是否构成潜在死锁。 如果找到潜在死锁,那么算法结束,如果没有到算法转到1直到搜索完整个锁依赖图为止。
这个最终算法能解决之前出现漏洞的案例吗?答案是可以的,具体检查过程如图所示:
 图8:简单算法的失败案例解决过程
图8:简单算法的失败案例解决过程
然而,对于所有其他情况,引理5是正确的吗?为什么最终算法能够工作呢?我们通过如下两个引理来证明最终算法中的间接锁依赖是必要且充分的。
引理6说明由于读写锁的存在,不能只检查直接锁依赖。
根据引理2和引理3,任何死锁都可以转化成双线程 ABBA 死锁,并且 T1 只能贡献 AB,T2 必须贡献 BA 。在这里,T2 不仅仅是一个虚拟线程,也是一个实际存在的物理线程,因此 T2 需要且只需要检查当前线程。
到这里,一个通用的读写锁死锁预测算法就描述并非正式证明完毕。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4095493/blog/3101963



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



