жҖҺд№ҲеңЁPythonдёӯе®һзҺ°HIVEзҡ„UDFеҮҪж•°
жң¬зҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іжҖҺд№ҲеңЁPythonдёӯе®һзҺ°HIVEзҡ„UDFеҮҪж•°пјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еӯҰд№ пјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·пјҢиҜқдёҚеӨҡиҜҙпјҢи·ҹзқҖе°Ҹзј–дёҖиө·жқҘзңӢзңӢеҗ§гҖӮ
з®ҖеҚ•жқҘеҒҡдёӘд»Ӣз»Қ
select * from(select * from table where dt='2021-03-30')a
еҸҜд»ҘеҶҷжҲҗ
with a as (select * from table where dt='2021-03-30' ) select * from a
з®ҖеҚ•зҡ„SQLзңӢдёҚеҮәиҝҷж ·зҡ„дјҳеҠҝ(з”ҡиҮіжңүзӮ№еӨҡжӯӨдёҖдёҫ)пјҢдҪҶжҳҜеҪ“йҖ»иҫ‘еӨҚжқӮдәҶд№ӢеҗҺжҲ‘们е°ұиғҪзңӢеҮәиҝҷз§ҚиҜӯжі•зҡ„дјҳеҠҝпјҢд»–иғҪд»Һеә•еұӮжҠҪеҸ–дёӯй—ҙиЎЁж јпјҢи®©жҲ‘们еҸӘдё“жіЁдәҺеҪ“еүҚдҪҝз”Ёзҡ„иЎЁж јпјҢиҝӣиҖҢеҸҜд»Ҙе°ҶеӨҚжқӮзҡ„еӨ„зҗҶйҖ»иҫ‘еҲҶи§ЈжҲҗз®ҖеҚ•зҡ„жӯҘйӘӨгҖӮ
еҰӮдёӢйқўең°иЎЁж ји®°еҪ•дәҶз”ЁжҲ·йҖӮз”ЁappиҝҮзЁӢдёӯжҜҸдёӘиЎҢдёәж—Ҙеҝ—ең°ж—¶й—ҙжҲіпјҢжҲ‘们жғіз»ҹи®ЎдёҖдёӢз”ЁжҲ·д»ҠеӨ©з”ЁдәҶеҮ ж¬ЎappпјҢд»ҘеҸҠжҜҸж¬Ўзҡ„иө·е§Ӣж—¶й—ҙе’Ңз»“жқҹж—¶й—ҙжҳҜд»Җд№Ҳж—¶еҖҷпјҢиҝҷдёӘй—®йўҳжҖҺд№Ҳи§Је‘ў?

SQLе®һзҺ°ж–№ејҸ
йҰ–е…Ҳз”Ёwith as жһ„е»әдёҖдёӘдёӯй—ҙиЎЁ(жіЁж„ҸзңӢon е’Ң whereжқЎд»¶)
with t1 as (select x.uid, case when x.rank=1 then y.timestamp_ms else x.timestamp_ms end as start_time, case when x.rank=1 then x.timestamp_ms else y.timestamp_ms end as end_time from (select uid, timestamp_ms, row_number()over(partition by uid order by timestamp_ms) rank from tmp.tmpx) x left outer join (select uid, timestamp_ms, row_number()over(partition by uid order by timestamp_ms) rank from tmp.tmpx) y on x.uid=y.uid and x.rank=y.rank-1 where x.rank=1 or y.rank is null or y.timestamp_ms-x.timestamp_ms>=300)
йҰ–е…ҲжҲ‘们用ејҖзӘ—еҮҪж•°й”ҷдҪҚзӣёеҮҸпјҢз”ЁwhereжқЎд»¶зӯӣйҖүеҮәжҲ‘们йңҖиҰҒзҡ„еҲ—пјҢе…¶дёӯ
x.rank=1 жҠҪеҸ–еҮә第дёҖиЎҢ
y.rank is null жҠҪеҸ–жңҖеҗҺдёҖж ·
y.timestamp_ms-x.timestamp_ms>=300жҠҪеҸ–ж»Ўи¶іжқЎд»¶зҡ„иЎҢпјҢеҰӮдёӢпјҡ

еҪ“然иҝҷдёӘз»“жһң并дёҚжҳҜжҲ‘们иҰҒзҡ„з»“жһңпјҢйңҖиҰҒе°ҶдёҠиҝ°иЎЁж јдёӯжҹҗдёҖиЎҢж•°жҚ®зҡ„end-timeе’ҢдёӢдёҖжқЎж•°жҚ®зҡ„start-timeз»“еҗҲиө·жқҘиө·жқҘпјҢжһ„йҖ еҮәж—¶й—ҙж®ө
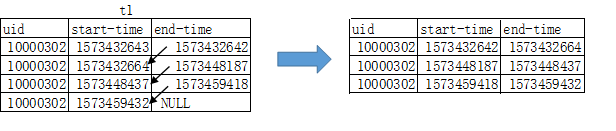
еҘҪзҡ„пјҢжҢүз…§дёҠйқўжҲ‘们жүҖиҜҙзҡ„йӮЈд№ҲдёӢйқўжҲ‘们дёҚз”Ёе…іеҝғеә•еұӮзҡ„йҖ»иҫ‘пјҢе°ҶжіЁж„ҸеҠӣдё“жіЁдәҺиҝҷеј дёӯй—ҙиЎЁt1
select a.uid,end_time as start_time,start_time as end_time from (select uid,start_time,row_number()over(partition by uid order by start_time) as rank from t1) a join (select uid,end_time,row_number()over(partition by uid order by end_time) as rank from t1)b on a.uid=b.uid and a.rank=b.rank+1
еҗҢж ·пјҢжҺ’еәҸеҗҺй”ҷдҪҚзӣёеҮҸпјҢ然еҗҺе°ұеҸҜд»Ҙжү“е®Ң收е·ҘдәҶ~
UDFе®һзҺ°ж–№ејҸ
йҰ–е…ҲжҲ‘们еҒҮи®ҫдёҠиҝ°ж•°жҚ®еӯҳеӮЁеңЁcsvдёӯпјҢ
з”Ёpython еӨ„зҗҶжң¬ең°ж–Ү件data.csvпјҢжҢүз…§pythonзҡ„еӨ„зҗҶж–№ејҸеҶҷд»Јз Ғ(иҝҷйҮҢе°ұдёҚдёҖеҸҘеҸҘи§ЈйҮҠдәҶпјҢдјҡpythonзҡ„еҗҢеӯҰеҸҜд»Ҙи·іиҝҮпјҢдёҚдјҡзҡ„еҗҢеӯҰдёҚеҰЁиҮӘе·ұеҠЁжүӢеҶҷдёҖдёӢ)
def life_cut(files): f=open(files) act_list=[] act_dict={} for line in f: line_list=line.strip().split() key=tuple(line_list[0:1]) if key not in act_dict: act_dict.setdefault(key,[]) act_dict[key].append(line_list[1]) else: act_dict[key].append(line_list[1]) for k,v in act_dict.items(): k_str=k[0]+"\t" start_time = v[0] last_time=v[0] i=1 while i<len(v)-1: if int(v[i])-int(last_time)>=300: print(k_str+"\t"+start_time+"\t"+v[i-1]) start_time=v[i] last_time = v[i] i=i+1 else: last_time = v[i] i=i+1 print(k_str+"\t"+start_time+"\t"+v[len(v)-1]) # print(k_str + "\t" + start_time + "\t" + v[i]) if __name__=="__main__": life_cut("data.csv")еҫ—еҲ°з»“жһңеҰӮдёӢпјҡ

йӮЈд№ҲдёӢйқўжҲ‘们е°ҶдёҠиҝ°еҮҪж•°еҶҷжҲҗudfзҡ„еҪўејҸпјҡ
#!/usr/bin/env python # -*- encoding:utf-8 -*- import sys act_list=[] act_dict={} for line in sys.stdin: line_list=line.strip().split("\t") key=tuple(line_list[0:1]) if key not in act_dict: act_dict.setdefault(key,[]) act_dict[key].append(line_list[1]) else: act_dict[key].append(line_list[1]) for k,v in act_dict.items(): k_str=k[0]+"\t" start_time = v[0] last_time=v[0] i=1 while i<len(v)-1: if int(v[i])-int(last_time)>=300: print(k_str+"\t"+start_time+"\t"+v[i-1]) start_time=v[i] last_time = v[i] i=i+1 else: last_time = v[i] i=i+1 print(k_str+"\t"+start_time+"\t"+v[len(v)-1])иҝҷдёӘеҸҳеҢ–иҝҮзЁӢзҡ„е…ій”®зӮ№жҳҜе°Ҷ for line in f жӣҝжҚўжҲҗ for line in sys.stdinпјҢе…¶д»–еҹәжң¬дёҠжІЎд»Җд№ҲеҸҳеҢ–
然еҗҺжҲ‘们еҶҚжқҘеј•з”ЁиҝҷдёӘеҮҪж•°
е…ҲaddиҝҷдёӘеҮҪж•°зҡ„и·Ҝеҫ„add file /xxx/life_cut.py еҠ иҪҪudfи·Ҝеҫ„пјҢ然еҗҺеҶҚдҪҝз”Ё
select TRANSFORM (uid,timestamp_ms) USING "python life_cut.py" as (uid,start_time,end_time) from tmp.tmpx
д»ҘдёҠе°ұжҳҜжҖҺд№ҲеңЁPythonдёӯе®һзҺ°HIVEзҡ„UDFеҮҪж•°пјҢе°Ҹзј–зӣёдҝЎжңүйғЁеҲҶзҹҘиҜҶзӮ№еҸҜиғҪжҳҜжҲ‘们ж—Ҙеёёе·ҘдҪңдјҡи§ҒеҲ°жҲ–з”ЁеҲ°зҡ„гҖӮеёҢжңӣдҪ иғҪйҖҡиҝҮиҝҷзҜҮж–Үз« еӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮжӣҙеӨҡиҜҰжғ…敬иҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





