本篇内容介绍了“事件驱动和CQRS有什么作用”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
一、前言:从物流详情开始
二、领域事件
2.1、建模领域事件
2.2、领域事件代码解读
2.3、领域事件的存储
2.3.1、单独的EventStore
2.3.2、与业务数据一起存储
2.4、领域事件如何发布
2.4.1、由领域聚合发送领域事件
2.4.2、事件总线VS消息中间件
三、Saga分布式事务
3.1、Saga概要
3.2、Saga实现
3.2.1、协同式(choreography)
3.2.2、编排式(orchestration)
3.2.3、补偿策略
四、CQRS
五、自治服务和系统
六、结语
大家对物流跟踪都不陌生,它详细记录了在什么时间发生了什么,并且数据作为重要凭证是不可变的。我理解其背后的价值有这么几个方面:业务方可以管控每个子过程、知道目前所处的环节;另一方面,当需要追溯时候仅仅通过每一步的记录就可以回放整个历史过程。
我在之前的文章中提出过“软件项目也是人类社会生产关系的范畴,只不过我们所创造的劳动成果看不见摸不着而已”。所以我们可以借鉴物流跟踪的思路来开发软件项目,把复杂过程拆解为一个个步骤、子过程、状态,这和我们事件划分是一致的,这就是事件驱动的典型案例。
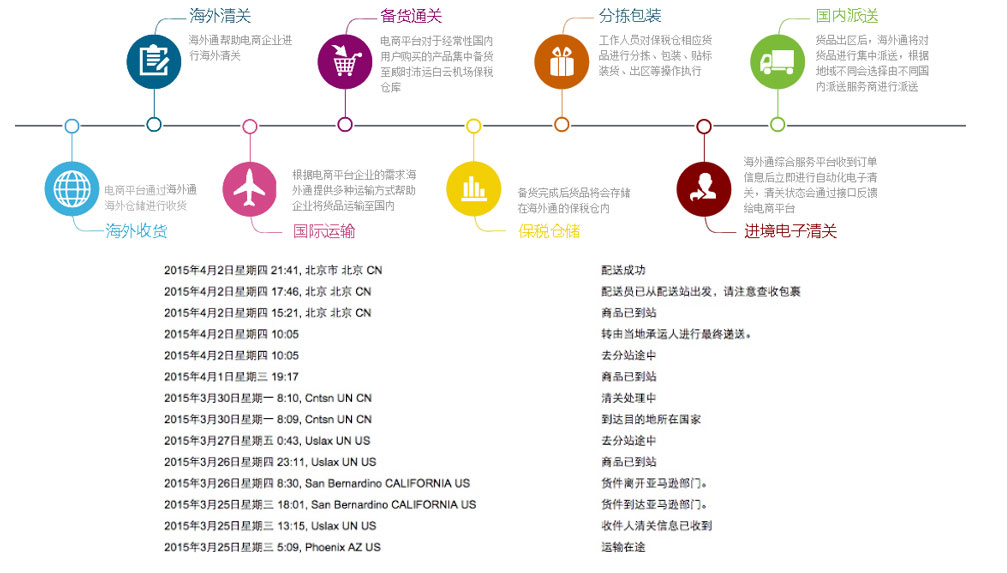
领域事件(Domain Events)是领域驱动设计(Domain Driven Design,DDD)中的一个概念,用于捕获我们所建模的领域中所发生过的事情。
领域事件本身也作为通用语言(Ubiquitous Language)的一部分成为包括领域专家在内的所有项目成员的交流用语。
比如在前述的跨境物流例子中,货品达到保税仓以后需要分派工作人员进行分拣分包,那么“货品已到达保税仓”便是一个领域事件。
首先,从业务逻辑来说该事件关系到整个流程的成功或者失败;同时又将触发后续子流程;而对于业务方来说,该事件也是一个标志性的里程碑,代表自己的货品就快配送到自己手中。
所以通常来说,一个领域事件具有以下几个特征:较高的业务价值,有助于形成完整的业务闭环,将导致进一步的业务操作。这里还要强调一点,领域事件具有明确的边界。
比如:如果你建模的是餐厅的结账系统,那么此时的“客户已到达”便不是你关心的重点,因为你不可能在客户到达时就立即向对方要钱,而“客户已下单”才是对结账系统有用的事件。
在建模领域事件时,我们应该根据限界上下文中的通用语言来命名事件及属性。如果事件由聚合上的命令操作产生,那么我们通常根据该操作方法的名字来命名领域事件。
对于上面的例子“货品已到达保税仓”,我们将发布与之对应的领域事件
GoodsArrivedBondedWarehouseEvent(当然在明确的界限上下文中也可以去掉聚合的名字,直接建模为ArrivedBondedWarehouseEvent,这都是命名方面的习惯)。
事件的名字表明了聚合上的命令方法在执行成功之后所发生的事情,换句话说待定项以及不确定的状态是不能作为领域事件的。
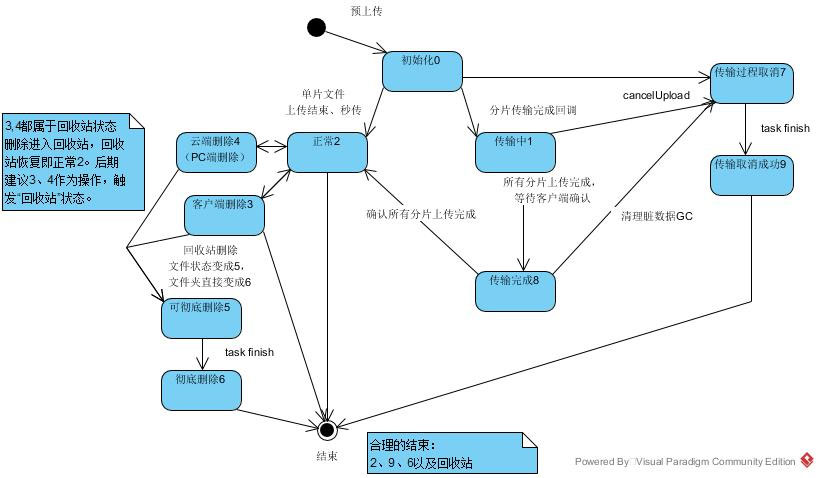
一个行之有效的方法是画出当前业务的状态流转图,包含前置操作以及引起的状态变更,这里表达的是已经变更完成的状态所以我们不用过去时态表示,比如删除或者取消,即代表已经删除或者已经取消。
然后对于其中的节点进行事件建模。如下图是文件云端存储的业务,我们分别对预上传、上传完成确认、删除等环节建模“过去时”事件,PreUploadedEvent、ConfirmUploadedEvent、RemovedEvent。

package domain.event;
import java.util.Date;
import java.util.UUID;
public class DomainEvent {
/**
* 领域事件还包含了唯一ID,
* 但是该ID并不是实体(Entity)层面的ID概念,
* 而是主要用于事件追溯和日志。
* 如果是数据库存储,该字段通常为唯一索引。
*/
private final String id;
/**
* 创建时间用于追溯,另一方面不管使用了
* 哪种事件存储都有可能遇到事件延迟,
* 我们通过创建时间能够确保其发生顺序。
*/
private final Date occurredOn;
public DomainEvent() {
this.id = String.valueOf(UUID.randomUUID());
this.occurredOn = new Date();
}
}在创建领域事件时,需要注意2点:
领域事件本身应该是不变的(Immutable);
领域事件应该携带与事件发生时相关的上下文数据信息,但是并不是整个聚合根的状态数据。例如,在创建订单时可以携带订单的基本信息,而对于用户更新订单收货地址事件AddressUpdatedEvent事件,只需要包含订单、用户以及新的地址等信息即可。
public class AddressUpdatedEvent extends DomainEvent {
//通过userId+orderId来校验订单的合法性;
private String userId;
private String orderId;
//新的地址
private Address address;
//略去具体业务逻辑
}事件的不可变性与可追溯性都决定了其必须要持久化的原则,我们来看看常见的几种方案。
有的业务场景中会创建一个单独的事件存储中心,可能是Mysql、Redis、Mongo、甚至文件存储等。这里以Mysql举例,business_code、event_code用来区分不同业务的不同事件,具体的命名规则可以根据实际需要。
这里需要注意该数据源与业务数据源不一致的场景,我们要确保当业务数据更新以后事件能够准确无误的记录下来,实践中尽量避免使用分布式事务,或者尽量避免其跨库的场景,否则你就得想想如何补偿了。千万要避免,用户更新了收货地址,但是AddressUpdatedEvent事件保存失败。
总的原则就是对分布式事务Say No,无论如何,我相信方法总比问题多,在实践中我们总可以想到解决方案,区别在于该方案是否简洁、是否做到了解耦。
# 考虑是否需要分表,事件存储建议逻辑简单
CREATE TABLE `event_store` (
`event_id` int(11) NOT NULL auto increment,
`event_code` varchar(32) NOT NULL,
`event_name` varchar(64) NOT NULL,
`event_body` varchar(4096) NOT NULL,
`occurred_on` datetime NOT NULL,
`business_code` varchar(128) NOT NULL,
UNIQUE KEY (`event id`)
) ENGINE=InnoDB COMMENT '事件存储表';在分布式架构中,每个模块都做的相对比较小,准确的说是“自治”。如果当前业务数据量较小,可以将事件与业务数据一起存储,用相关标识区分是真实的业务数据还是事件记录;或者在当前业务数据库中建立该业务自己的事件存储,但是要考虑到事件存储的量级必然大于真实的业务数据,考虑是否需要分表。
这种方案的优势:数据自治;避免分布式事务;不需要额外的事件存储中心。当然其劣势就是不能复用。
/*
* 一个关于比赛的充血模型例子
* 贫血模型会构造一个MatchService,我们这里通过模型来触发相应的事件
* 本例中略去了具体的业务细节
*/
public class Match {
public void start() {
//构造Event....
MatchEvent matchStartedEvent = new MatchStartedEvent();
//略去具体业务逻辑
DefaultDomainEventBus.publish(matchStartedEvent);
}
public void finish() {
//构造Event....
MatchEvent matchFinishedEvent = new MatchFinishedEvent();
//略去具体业务逻辑
DefaultDomainEventBus.publish(matchFinishedEvent);
}
//略去Match对象基本属性
}微服务内的领域事件可以通过事件总线或利用应用服务实现不同聚合之间的业务协同。即微服务内发生领域事件时,由于大部分事件的集成发生在同一个线程内,不一定需要引入消息中间件。但一个事件如果同时更新多个聚合数据,按照 DDD“一个事务只更新一个聚合根”的原则,可以考虑引入消息中间件,通过异步化的方式,对微服务内不同的聚合根采用不同的事务
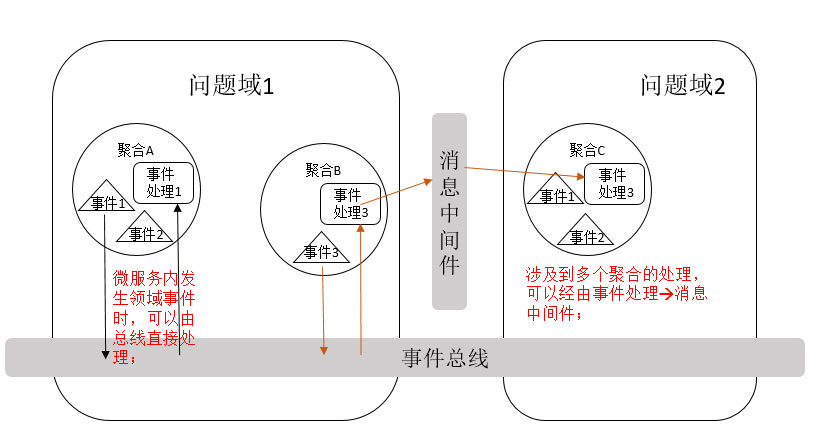
我们看看如何使用 Saga 模式维护数据一致性?
Saga 是一种在微服务架构中维护数据一致性的机制,它可以避免分布式事务所带来的问题。
一个 Saga 表示需要更新的多个服务中的一个,即Saga由一连串的本地事务组成。每一个本地事务负责更新它所在服务的私有数据库,这些操作仍旧依赖于我们所熟悉的ACID事务框架和函数库。
模式:Saga
通过使用异步消息来协调一系列本地事务,从而维护多个服务之间的数据一致性。
请参阅(强烈建议):https://microservices.io/patterns/data/saga.html
Saga与TCC相比少了一步Try的操作,TCC无论最终事务成功失败都需要与事务参与方交互两次。而Saga在事务成功的情况下只需要与事务参与方交互一次, 如果事务失败,需要额外进行补偿回滚。
每个Saga由一系列sub-transaction Ti 组成;
每个Ti 都有对应的补偿动作Ci,补偿动作用于撤销Ti造成的结果;
可以看到,和TCC相比,Saga没有“预留”动作,它的Ti就是直接提交到库。
Saga的执行顺序有两种:
success:T1, T2, T3, ..., Tn ;
failure:T1, T2, ..., Tj, Cj,..., C2, C1,其中0 < j < n;
所以我们可以看到Saga的撤销十分关键,可以说使用Saga的难点就在于如何设计你的回滚策略。
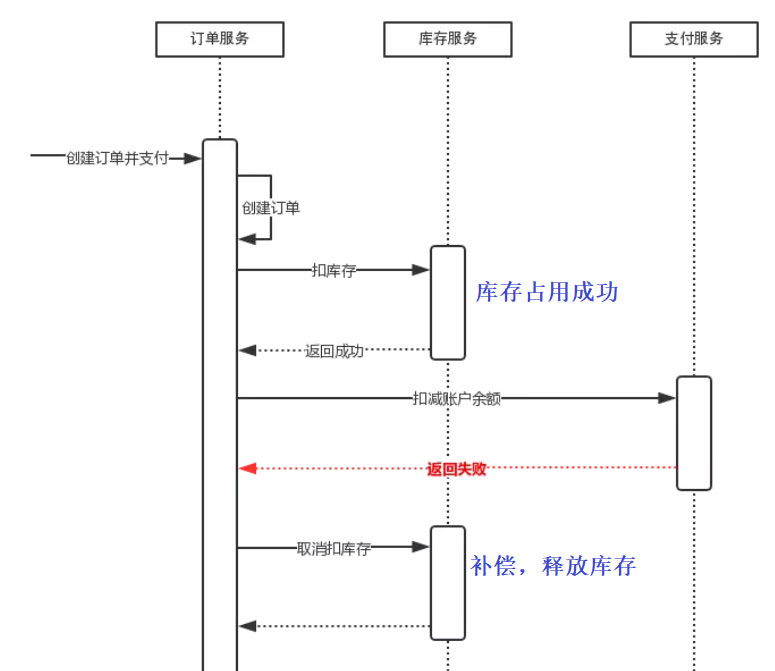
通过上面的例子我们对Saga有了初步的体感,现在来深入探讨下如何实现。当通过系统命令启动Saga时,协调逻辑必须选择并通知第一个Saga参与方执行本地事务。一旦该事务完成,Saga协调选择并调用下一个Saga参与方。
这个过程一直持续到Saga执行完所有步骤。如果任何本地事务失败,则 Saga必须以相反的顺序执行补偿事务。以下几种不同的方法可用来构建Saga的协调逻辑。
把 Saga 的决策和执行顺序逻辑分布在 Saga的每一个参与方中,它们通过交换事件的方式来进行沟通。
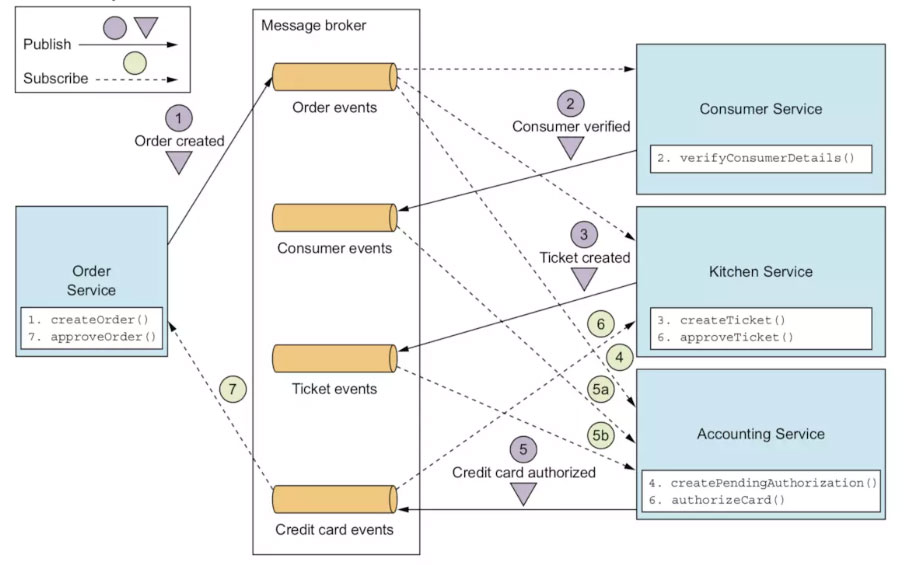
(引用于《微服务架构设计模式》相关章节)
Order服务创建一个Order并发布OrderCreated事件。
Consumer服务消费OrderCreated事件,验证消费者是否可以下订单,并发布ConsumerVerified事件。
Kitchen服务消费OrderCreated事件,验证订单,在CREATE_PENDING状态下创建故障单,并发布TicketCreated事件。
Accounting服务消费OrderCreated事件并创建一个处于PENDING状态的Credit CardAuthorization。
Accounting服务消费TicketCreated和ConsumerVerified事件,向消费者的信用卡收费,并发布信用卡授权失败事件。
Kitchen服务使用信用卡授权失败事件并将故障单的状态更改为REJECTED。
订单服务消费信用卡授权失败事件,并将订单状态更改为已拒绝。
把Saga的决策和执行顺序逻辑集中在一个Saga编排器类中。Saga 编排器发出命令式消息给各个 Saga 参与方,指示这些参与方服务完成具体操作(本地事务)。类似于一个状态机,当参与方服务完成操作以后会给编排器发送一个状态指令,以决定下一步做什么。
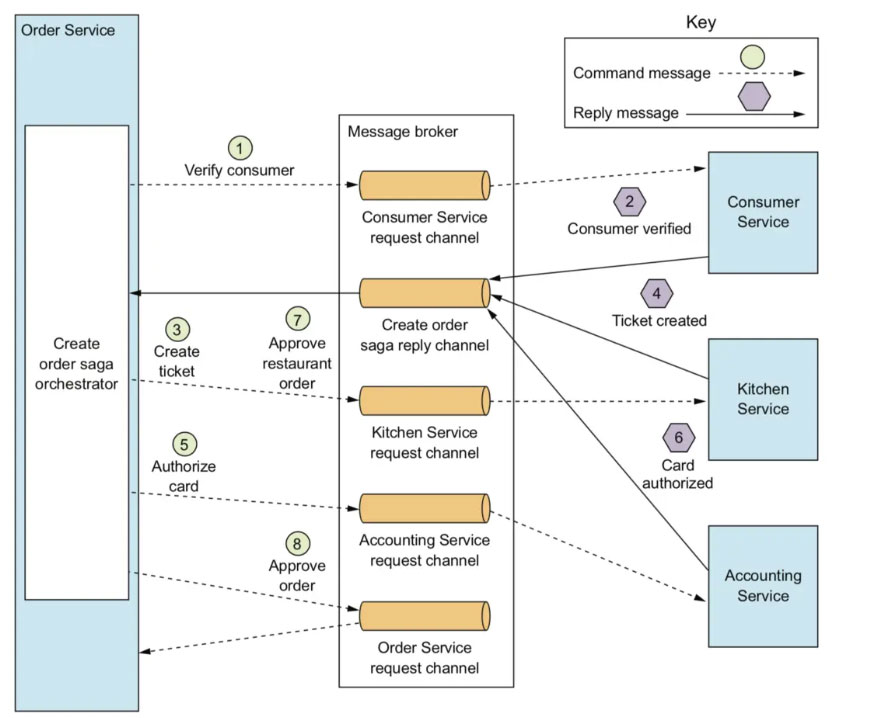
(引用于《微服务架构设计模式》相关章节)
我们来分析一下执行流程
Order Service首先创建一个Order和一个创建订单控制器。之后,路径的流程如下:
Saga orchestrator向Consumer Service发送Verify Consumer命令。
Consumer Service回复Consumer Verified消息。
Saga orchestrator向Kitchen Service发送Create Ticket命令。
Kitchen Service回复Ticket Created消息。
Saga协调器向Accounting Service发送授权卡消息。
Accounting服务部门使用卡片授权消息回复。
Saga orchestrator向Kitchen Service发送Approve Ticket命令。
Saga orchestrator向订单服务发送批准订单命令。
之前的描述中我们说过Saga最重要的是如何处理异常,状态机还定义了许多异常状态。如上面的6就会发生失败,触发AuthorizeCardFailure,此时我们就要结束订单并把之前提交的事务进行回滚。这里面要区分哪些是校验性事务、哪些是需要补偿的事务。
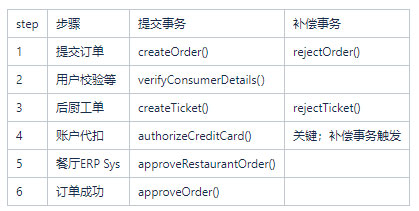

一个Saga由三种不同类型的事务组成:可补偿性事务(可以回滚,因此有一个补偿事务);关键性事务(这是 Saga的成败关键点,比如4账户代扣);以及可重复性事务,它不需要回滚并保证能够完成(比如6更新状态)。
在Create Order Saga 中,createOrder()、createTicket()步骤是可补偿性事务且具有撤销其更新的补偿事务。
verifyConsumerDetails()事务是只读的,因此不需要补偿事务。authorizeCreditCard()事务是这个 Saga的关键性事务。如果消费者的信用卡可以授权,那么这个Saga保证完成。approveTicket()和approveRestaurantOrder()步骤是在关键性事务之后的可重复性事务。
认真拆解每个步骤、然后评估其补偿策略尤为重要,正如你看到的,每种类型的事务在对策中扮演着不同的角色。
前面讲述了事件的概念,又分析了Saga如何解决复杂事务,现在我们来看看CQRS为什么在DDD中广泛被采用。除了读写分离的特征以外,我们用事件驱动的方式来实践Command逻辑能有效降低业务的复杂度。
当你明白如何建模事件、如何规避复杂事务,明白什么时候用消息中间件、什么时候采用事件总线,才能理解为什么是CQRS、怎么正确应用。
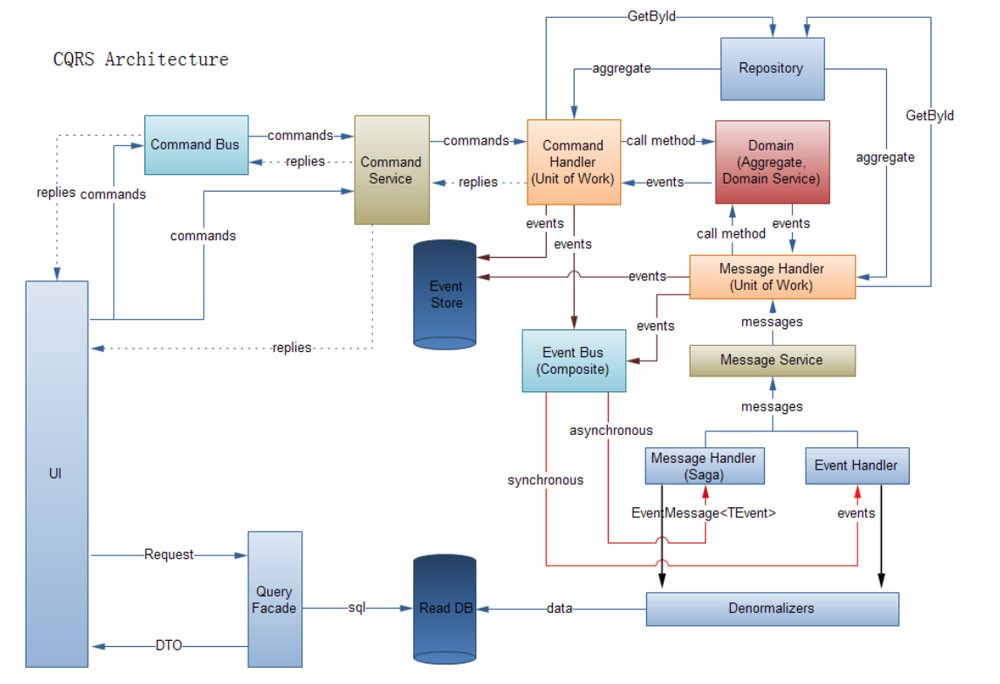
下面是我们项目中的设计,这里为什么会出现Read/Write Service,是为了封装调用,service内部是基于聚合发送事件。因为我发现在实际项目中,很多人都会第一时间问我要XXXService而不是XXX模型,所以在DDD没有完全普及的项目中建议大家采取这种居中策略。这也符合咱们的解耦,对方依赖我的抽象能力,然而我内部是基于DDD还是传统的流程代码对其是无关透明的。
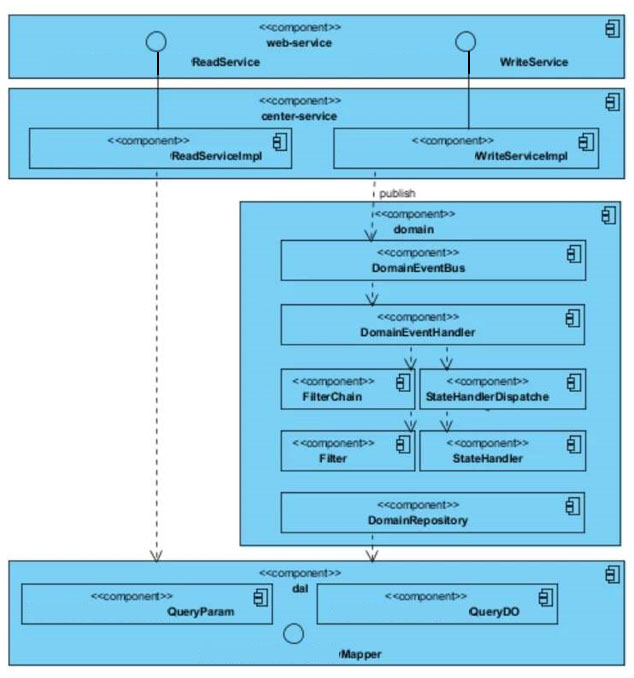
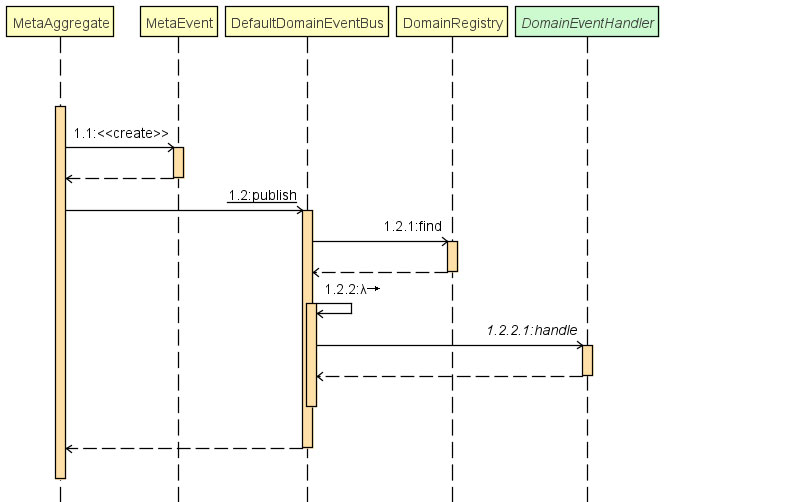
我们先来看看事件以及处理器的时序关系。
这里还是以文件云端存储业务为例,下面是一些处理器的核心代码。注释行是对代码功能、用法以及扩展方面的解读,请认真阅读。
package domain;
import domain.event.DomainEvent;
import domain.handler.event.DomainEventHandler;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class DomainRegistry {
private Map<String, List<DomainEventHandler>> handlerMap =
new HashMap<String, List<DomainEventHandler>>();
private static DomainRegistry instance;
private DomainRegistry() {
}
public static DomainRegistry getInstance() {
if (instance == null) {
instance = new DomainRegistry();
}
return instance;
}
public Map<String, List<DomainEventHandler>> getHandlerMap() {
return handlerMap;
}
public List<DomainEventHandler> find(String name) {
if (name == null) {
return null;
}
return handlerMap.get(name);
}
//事件注册与维护,register分多少个场景根据业务拆分,
//这里是业务流的核心。如果多个事件需要维护前后依赖关系,
//可以维护一个priority逻辑
public void register(Class<? extends DomainEvent> domainEvent,
DomainEventHandler handler) {
if (domainEvent == null) {
return;
}
if (handlerMap.get(domainEvent.getName()) == null) {
handlerMap.put(domainEvent.getName(), new ArrayList<DomainEventHandler>());
}
handlerMap.get(domainEvent.getName()).add(handler);
//按照优先级进行事件处理器排序
。。。
}
}文件上传完毕事件的例子。
package domain.handler.event;
import domain.DomainRegistry;
import domain.StateDispatcher;
import domain.entity.meta.MetaActionEnums;
import domain.event.DomainEvent;
import domain.event.MetaEvent;
import domain.repository.meta.MetaRepository;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
/**
* @Description:一个事件操作的处理器
* 我们混合使用了Saga的两种模式,外层事件交互;
* 对于单个复杂的事件内部采取状态流转实现。
*/
@Component
public class MetaConfirmUploadedHandler implements DomainEventHandler {
@Resource
private MetaRepository metaRepository;
public void handle(DomainEvent event) {
//1.我们在当前的上下文中定义个ThreadLocal变量
//用于存放事件影响的聚合根信息(线程共享)
//2.当然如果有需要额外的信息,可以基于event所
//携带的信息构造Specification从repository获取
// 代码示例
// metaRepository.queryBySpecification(SpecificationFactory.build(event));
DomainEvent domainEvent = metaRepository.load();
//此处是我们的逻辑
。。。。
//对于单个操作比较复杂的,可以使用状态流转进一步拆分
domainEvent.setStatus(nextState);
//在事件触发之后,仍需要一个状态跟踪器来解决大事务问题
//Saga编排式
StateDispatcher.dispatch();
}
@PostConstruct
public void autoRegister() {
//此处可以更加细分,注册在哪一类场景中,这也是事件驱动的强大、灵活之处。
//避免了if...else判断。我们可以有这样的意识,一旦你的逻辑里面充斥了大量
//switch、if的时候来看看自己注册的场景是否可以继续细分
DomainRegistry.getInstance().register(MetaEvent.class, this);
}
public String getAction() {
return MetaActionEnums.CONFIRM_UPLOADED.name();
}
//适用于前后依赖的事件,通过优先级指定执行顺序
public Integer getPriority() {
return PriorityEnums.FIRST.getValue();
}
}事件总线逻辑
package domain;
import domain.event.DomainEvent;
import domain.handler.event.DomainEventHandler;
import java.util.List;
public class DefaultDomainEventBus {
public static void publish(DomainEvent event, String action,
EventCallback callback) {
List<DomainEventHandler> handlers = DomainRegistry.getInstance().
find(event.getClass().getName());
handlers.stream().forEach(handler -> {
if (action != null && action.equals(handler.getAction())) {
Exception e = null;
boolean result = true;
try {
handler.handle(event);
} catch (Exception ex) {
e = ex;
result = false;
//自定义异常处理
。。。
} finally {
//write into event store
saveEvent(event);
}
//根据实际业务处理回调场景,DefaultEventCallback可以返回
if (callback != null) {
callback.callback(event, action, result, e);
}
}
});
}
}DDD中强调限界上下文的自治特性,事实上,从更小的粒度来看,对象仍然需要具备自治的这四个特性,即:最小完备、自我履行、稳定空间、独立进化。其中自我履行是重点,因为不强依赖外部所以稳定、因为稳定才可能独立进化。这就是六边形架构在DDD中较为普遍的原因。
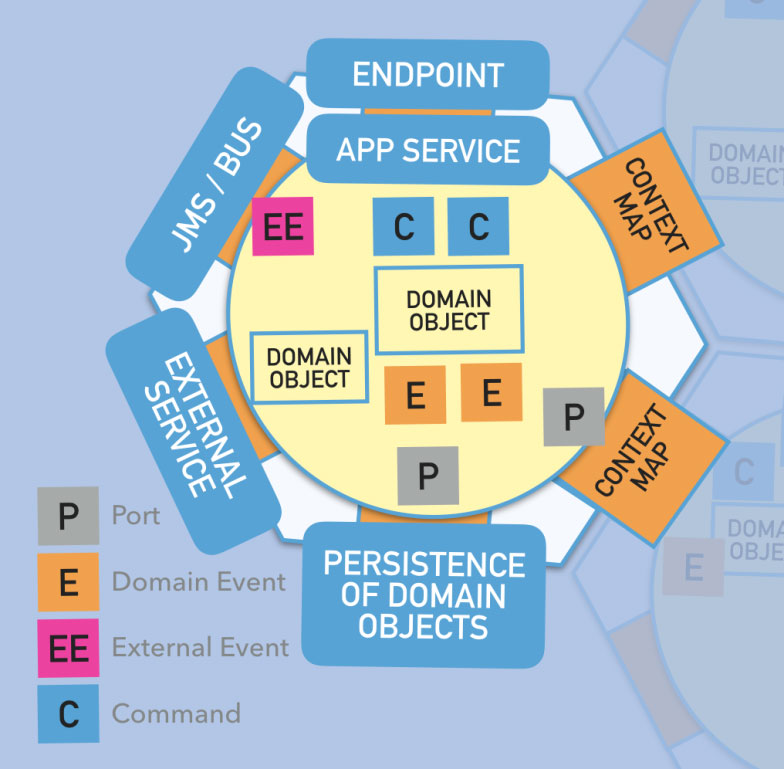
本文所讲述的事件、Saga、CQRS的方案均可以单独使用,可以应用到你的某个method、或者你的整个package。项目中我们并不一定要实践一整套CQRS,只要其中的某些思想解决了我们项目中的某个问题就足够了。
也许你现在已经磨刀霍霍,准备在项目中实践一下这些技巧。不过我们要明白“每一个硬币都有两面性”,我们不仅看到高扩展、解耦的、易编排的优点以外,仍然要明白其所带来的问题。利弊分析以后再去决定如何实现才是正确的应对之道。
这类编程模式有一定的学习曲线;
基于消息传递的应用程序的复杂性;
处理事件的演化有一定难度;
删除数据存在一定难度;
查询事件存储库非常有挑战性。
不过我们还是要认识到在其适合的场景中,六边形架构以及DDD战术将加速我们的领域建模过程,也迫使我们从严格的通用语言角度来解释一个领域,而不是一个个需求。任何更强调核心域而不是技术实现的方式都可以增加业务价值,并使我们获得更大的竞争优势。
“事件驱动和CQRS有什么作用”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



