Redisдёӯзј“еӯҳйӣӘеҙ©гҖҒзј“еӯҳеҮ»з©ҝе’Ңзј“еӯҳз©ҝйҖҸзҡ„зӨәдҫӢеҲҶжһҗ
иҝҷзҜҮж–Үз« дё»иҰҒдёәеӨ§е®¶еұ•зӨәдәҶвҖңRedisдёӯзј“еӯҳйӣӘеҙ©гҖҒзј“еӯҳеҮ»з©ҝе’Ңзј“еӯҳз©ҝйҖҸзҡ„зӨәдҫӢеҲҶжһҗвҖқпјҢеҶ…е®№з®ҖиҖҢжҳ“жҮӮпјҢжқЎзҗҶжё…жҷ°пјҢеёҢжңӣиғҪеӨҹеё®еҠ©еӨ§е®¶и§ЈеҶіз–‘жғ‘пјҢдёӢйқўи®©е°Ҹзј–еёҰйўҶеӨ§е®¶дёҖиө·з ”究并еӯҰд№ дёҖдёӢвҖңRedisдёӯзј“еӯҳйӣӘеҙ©гҖҒзј“еӯҳеҮ»з©ҝе’Ңзј“еӯҳз©ҝйҖҸзҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« еҗ§гҖӮ

зј“еӯҳйӣӘеҙ©
зј“еӯҳеҮ»з©ҝ
зј“еӯҳз©ҝйҖҸ
зӣёдҝЎиҝҷдёүдёӘй—®йўҳпјҢзҪ‘дёҠе·Із»ҸжңүеҫҲеӨҡзҡ„дјҷдјҙи®ІиҝҮдәҶпјҢдҪҶжҳҜд»ҠеӨ©жҲ‘иҝҳжҳҜжғіиҜҙдёӢпјҢдјҡеӨҡз”»еӣҫпјҢи®©еӨ§е®¶еҠ ж·ұеҚ°иұЎпјҢиҝҷдёүдёӘй—®йўҳд№ҹй«ҳйў‘зҡ„йқўиҜ•йўҳпјҢдҪҶжҳҜиғҪжҠҠиҝҷеҮ дёӘй—®йўҳиҜҙжё…жҘҡпјҢд№ҹжҳҜйңҖиҰҒжҠҖе·§зҡ„гҖӮ
еҶҚиҜҙиҝҷдёүдёӘй—®йўҳзҡ„ж—¶еҖҷпјҢе…ҲиҜҙдёӢжӯЈеёёзҡ„иҜ·жұӮжөҒзЁӢпјҢзңӢеӣҫиҜҙиҜқпјҡ
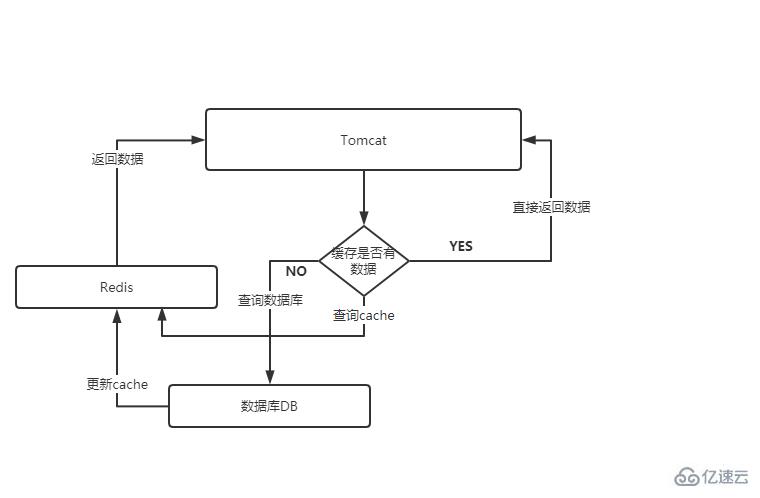
дёҠеӣҫзҡ„ж„ҸжҖқеӨ§иҮҙеҰӮдёӢпјҡ
йҰ–е…ҲдјҡеңЁдҪ зҡ„д»Јз ҒдёӯпјҢеҸҜиғҪжҳҜtomcat д№ҹеҸҜд»ҘжҳҜдҪ зҡ„rpc жңҚеҠЎдёӯпјҢе…ҲеҲӨж–ӯзј“еӯҳcache дёӯжҳҜеҗҰеӯҳеңЁдҪ жғіиҰҒзҡ„ж•°жҚ®пјҢеҰӮжһңеӯҳеӮЁдәҶпјҢйӮЈд№ҲзӣҙжҺҘиҝ”еӣһз»ҷи°ғз”Ёз«ҜпјҢеҰӮжһңдёҚеӯҳеңЁпјҢйӮЈд№Ҳе°ұйңҖиҰҒжҹҘиҜўж•°жҚ®еә“пјҢжҹҘиҜўеҮәз»“жһңжқҘпјҢеҶҚ继з»ӯзј“еӯҳеҲ°cacheдёӯпјҢ然еҗҺиҝ”еӣһз»“жһңз»ҷи°ғз”Ёж–№пјҢдёӢж¬ЎеҶҚжқҘзҡ„жҹҘиҜўзҡ„ж—¶еҖҷпјҢд№ҹе°ұе‘Ҫдёӯзј“еӯҳдәҶгҖӮ
зј“еӯҳйӣӘеҙ©
е®ҡд№ү
и®°еҫ—д№ӢеүҚеңЁеҒҡжҺЁиҚҗзі»з»ҹзҡ„ж—¶еҖҷпјҢжңүдәӣж•°жҚ®жҳҜзҰ»зәҝз®—жі•з®—еҮәжқҘзҡ„пјҢйңҖжұӮжҳҜзңӢдәҶиҝҷдёӘе•Ҷе“ҒдјҡжҺЁиҚҗе“Әдәӣзӣёдјјзҡ„е•Ҷе“ҒпјҢиҝҷдёӘз®—еҮәжқҘд№ӢеҗҺдјҡеӯҳеӮЁеҲ°hbaseпјҢеҗҢж—¶еӯҳеӮЁеҲ°redisпјҢз”ұдәҺйғҪжҳҜжү№йҮҸз®—жі•еҮәжқҘзҡ„пјҢеҶҚеӯҳеӮЁеҲ°redis зҡ„ж—¶еҖҷпјҢеҰӮжһңиҝҮжңҹж—¶й—ҙи®ҫзҪ®зӣёеҗҢпјҢйӮЈд№Ҳе°ұдјҡйҖ жҲҗеӨ§жү№йҮҸзҡ„key пјҢеңЁеҗҢдёҖж—¶еҲ»еӨұж•ҲпјҢйӮЈд№Ҳе°ұдјҡжңүеӨ§жү№йҮҸзҡ„иҜ·жұӮдјҡиў«жү“еҲ°еҗҺеҸ°зҡ„ж•°жҚ®еә“дёҠпјҢеӣ дёәж•°жҚ®еә“зҡ„еҗһеҗҗйҮҸжҳҜжңүйҷҗзҡ„пјҢеҫҲжңүеҸҜиғҪдјҡжҠҠж•°жҚ®еә“жү“еһ®зҡ„пјҢиҝҷз§Қжғ…еҶөе°ұжҳҜзј“еӯҳйӣӘеҙ©пјҢзңӢеӣҫиҜҙиҜқпјҡ
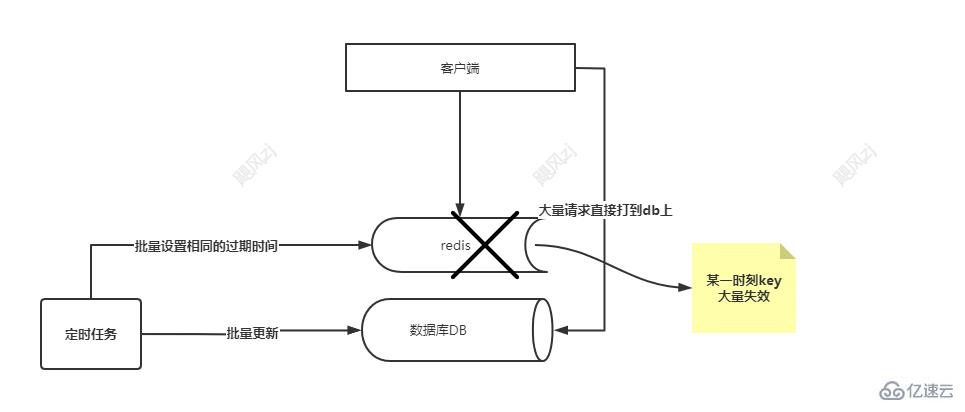
иҝҷдёӘдё»иҰҒжҳҜиҜҙжҳҺдёҖдёӘзј“еӯҳйӣӘеҙ©еҮәзҺ°зҡ„еңәжҷҜпјҢе°Өе…¶жҳҜе®ҡж—¶д»»еҠЎеңЁжү№йҮҸи®ҫзҪ®cacheзҡ„ж—¶еҖҷпјҢдёҖе®ҡиҰҒжіЁж„ҸиҝҮжңҹж—¶й—ҙзҡ„и®ҫзҪ®гҖӮ
еҰӮдҪ•йў„йҳІйӣӘеҙ©
е…¶е®һд№ҹеҫҲз®ҖеҚ•пјҢе°ұжҳҜеңЁдҪ жү№йҮҸи®ҫзҪ®cacheзҡ„зј“еӯҳж—¶й—ҙзҡ„ж—¶еҖҷпјҢз»ҷи®ҫзҪ®зҡ„зј“еӯҳж—¶й—ҙпјҢи®ҫзҪ®дёҖдёӘйҡҸжңәж•°(еҰӮйҡҸжңәж•°еҸҜд»Ҙ10еҲҶй’ҹеҶ…зҡ„ж•°еӯ—пјҢйҡҸжңәж•°зҡ„з”ҹжҲҗеҸҜд»Ҙз”Ёjavaзҡ„Randomз”ҹжҲҗ)пјҢиҝҷж ·пјҢе°ұдёҚдјҡеҮәзҺ°еӨ§йҮҸзҡ„keyпјҢеҶҚеҗҢдёҖж—¶еҲ»йӣҶдҪ“еӨұж•ҲдәҶпјҢзңӢеӣҫиҜҙиҜқпјҡ
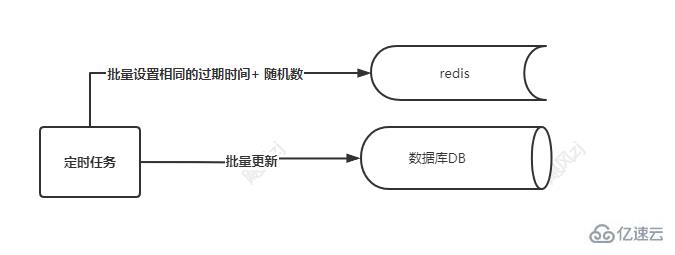
еҰӮжһңзңҹзҡ„еҸ‘з”ҹдәҶйӣӘеҙ©жҖҺд№ҲеҠһпјҹ
жөҒйҮҸдёҚжҳҜеҫҲеӨ§пјҢж•°жҚ®еә“иғҪжҠ—дҪҸпјҢokпјҢжҒӯе–ңдҪ йҖғиҝҮдёҖеҠ«гҖӮ
жөҒйҮҸеҫҲеӨ§пјҢи¶…иҝҮдәҶж•°жҚ®еә“жүҖиғҪеӨ„зҗҶзҡ„иҜ·жұӮж•°зҡ„жһҒйҷҗпјҢж•°жҚ®еә“downжңәдәҶпјҢд№ҹжҒӯе–ңдҪ йўҶдәҶдёҖдёӘP0дәӢж•…еҚ•гҖӮ
жөҒйҮҸеҫҲеӨ§пјҢеҰӮжһңдҪ зҡ„ж•°жҚ®еә“жңүйҷҗжөҒж–№жЎҲпјҢеҪ“иҫҫеҲ°дәҶйҷҗжөҒи®ҫзҪ®зҡ„еҸӮж•°пјҢйӮЈд№Ҳе°ұдјҡжӢ’з»қиҜ·жұӮпјҢд»ҺиҖҢдҝқжҠӨдәҶеҗҺеҸ°dbгҖӮиҝҷйҮҢеҜ№йҷҗжөҒеӨҡиҜҙеҮ еҸҘгҖӮ
еҸҜд»ҘйҖҡиҝҮи®ҫзҪ®жҜҸз§’иҜ·жұӮж•°пјҢжқҘйҷҗеҲ¶еӨ§йҮҸзҡ„иҜ·жұӮеҲ°иҫҫdbз«ҜпјҢжіЁж„ҸиҝҷйҮҢзҡ„жҜҸз§’иҜ·жұӮж•°пјҢжҲ–иҖ…иҜҙжҳҜ并еҸ‘ж•°пјҢ并дёҚжҳҜж•°жҚ®еҪ“еүҚзҡ„жҜҸз§’иҜ·жұӮж•°пјҢеҸҜд»Ҙи®ҫзҪ®дёәжҹҘиҜўжҹҗдёӘkey еҜ№еә”зҡ„жҜҸз§’иҜ·жұӮж•°йҮҸпјҢиҝҷж ·еҒҡзҡ„зӣ®зҡ„пјҢжҳҜйҳІжӯўеӨ§йҮҸзӣёеҗҢkeyзҡ„иҜ·жұӮеҲ°иҫҫеҗҺз«Ҝж•°жҚ®еә“пјҢиҝҷж ·е°ұиғҪжӢҰжҲӘдәҶеӨ§йғЁеҲҶиҜ·жұӮдәҶгҖӮ
зңӢеӣҫиҜҙиҜқпјҡ
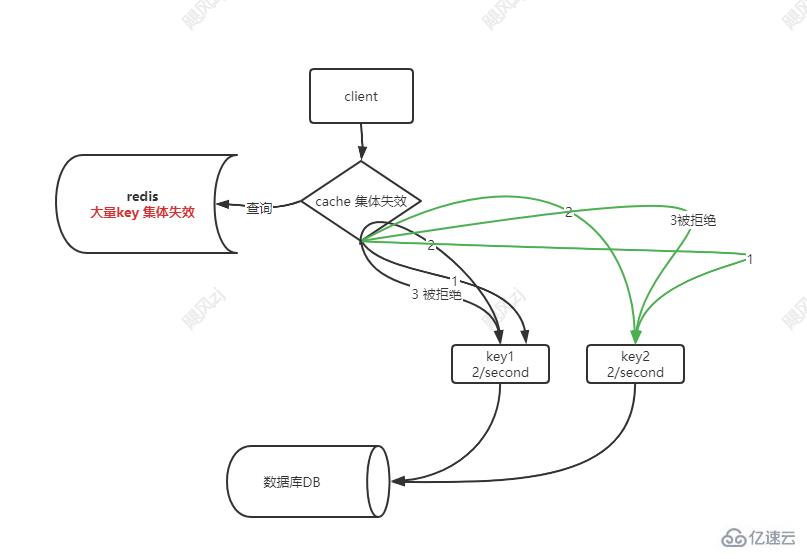
иҝҷж ·зӣёеҗҢзҡ„keyпјҢе°ұдјҡиў«йҷҗжөҒдәҶеӨ§йғЁеҲҶиҜ·жұӮпјҢд»ҺиҖҢдҝқжҠӨдәҶж•°жҚ®еә“dbгҖӮ
е…¶е®һйҷҗжөҒиҝҳеҲҶдёәжң¬ең°йҷҗжөҒе’ҢеҲҶеёғејҸйҷҗжөҒдёӨз§ҚпјҢеҗҺйқўзҡ„ж–Үз« йҮҢпјҢжҲ‘дјҡ д»Ӣз»Қжң¬ең°йҷҗжөҒе’Ңredis е®һзҺ°зҡ„еҲҶеёғејҸйҷҗжөҒгҖӮ
зј“еӯҳеҮ»з©ҝ
е®ҡд№ү
жҜ”еҰӮеңЁжҹҗзҪ‘з«ҷеңЁиҝӣиЎҢеҸҢеҚҒдёҖжҲ–иҖ…еңЁжҗһз§’жқҖзӯүиҝҗиҗҘжҙ»еҠЁзҡ„ж—¶еҖҷпјҢйӮЈд№ҲжӯӨж—¶зҪ‘з«ҷжөҒйҮҸдёҖиҲ¬йғҪдјҡеҫҲеӨ§зҡ„пјҢжҹҗдёӘдёҖдёӘе•Ҷе“Ғеӣ дёәдҝғй”ҖдјҡжҲҗдёәзҲҶе“ҒпјҢжөҒйҮҸи¶…зә§зҡ„еӨ§пјҢеҰӮжһңиҝҷдёӘе•Ҷе“ҒпјҢеңЁиҝҷдёӘж—¶еҖҷпјҢз”ұдәҺжҹҗз§ҚеҺҹеӣ пјҢеңЁcacheеҶ…еӨұж•ҲдәҶпјҢйӮЈд№Ҳе°ұзһ¬й—ҙиҝҷдёӘkeyзҡ„жөҒйҮҸйғҪдјҡж¶Ңеҗ‘ж•°жҚ®еә“дәҶпјҢйӮЈд№ҲdbжңҖз»ҲжҢәдёҚдҪҸдәҶпјҢdownдәҶпјҢеҗҺжһңеҸҜжғіиҖҢзҹҘе•ҠпјҢжӯЈеёёе…¶д»–зҡ„ж•°жҚ®д№ҹжҹҘиҜўдёҚдәҶгҖӮ
зңӢеӣҫиҜҙиҜқпјҡ
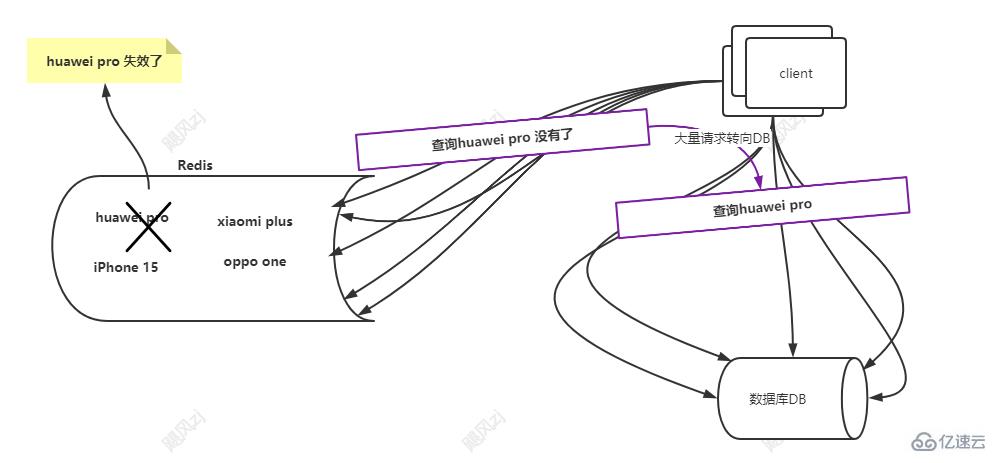
redis дёӯзҡ„huawei pro иҝҷдёӘkey зӘҒ然еӨұж•ҲдәҶпјҢеҸҜиғҪжҳҜеҲ°жңҹдәҶпјҢеҸҜиғҪжҳҜеҶ…еӯҳдёҚеӨҹиў«ж·ҳжұ°дәҶпјҢйӮЈд№Ҳе°ұдјҡжңүеӨ§жөҒйҮҸзҡ„иҜ·жұӮеҲ°иҫҫredis пјҢеҸ‘зҺ°redis жІЎжңүиҝҷдёӘkeyпјҢйӮЈд№ҲиҝҷдәӣжөҒйҮҸпјҢе°ұдјҡиҪ¬еҲ°DB дёҠеҺ»пјҢжҹҘиҜўеҜ№еә”зҡ„huawei proпјҢжӯӨж—¶DB жҢәдёҚдҪҸдәҶпјҢdownдәҶгҖӮ
еҰӮдҪ•и§ЈеҶі
е…¶е®һеҪ’ж №еҲ°еә•иҝҳжҳҜдёҚиғҪи®©жӣҙеӨҡзҡ„жөҒйҮҸеҲ°иҫҫDBе°ұиЎҢдәҶпјҢжүҖд»ҘжҲ‘们е°ұжҳҜиҰҒйҷҗеҲ¶еҲ°иҫҫdbзҡ„жөҒйҮҸе°ұеҸҜд»ҘдәҶгҖӮ
1гҖҒйҷҗжөҒ
е’ҢдёҠйқўиҜҙзҡ„зұ»дјјпјҢдё»иҰҒжҳҜйҷҗеҲ¶жҹҗдёӘkeyзҡ„жөҒйҮҸпјҢеҪ“иҝҷдёӘkey пјҢиў«еҮ»з©ҝеҗҺпјҢйҷҗеҲ¶еҸӘжңүдёҖдёӘжөҒйҮҸиҝӣе…ҘеҲ°dbпјҢе…¶д»–йғҪиў«жӢ’з»қпјҢжҲ–иҖ…зӯүеҫ…йҮҚиҜ•жҹҘиҜўredisгҖӮ
йҷҗжөҒзҡ„еӣҫеҸҜд»ҘеҸӮиҖғзј“еӯҳеҮ»з©ҝйҷҗжөҒзҡ„еӣҫгҖӮ
иҝҷйҮҢд№ҹдјҡеҲҶжң¬ең°йҷҗжөҒе’ҢеҲҶеёғејҸйҷҗжөҒ гҖӮ
дҪ•дёәжң¬ең°йҷҗжөҒпјҢе°ұжҳҜеңЁжң¬ең°еҚ•дёӘе®һдҫӢиҢғеӣҙеҶ…пјҢйҷҗеҲ¶иҝҷдёӘkeyзҡ„жөҒйҮҸеӨҡе°‘пјҢеҸӘеҜ№еҪ“еүҚе®һдҫӢжңүж•ҲгҖӮ
дҪ•дёәеҲҶеёғејҸйҷҗжөҒе‘ўпјҢе°ұжҳҜеңЁеҲҶеёғејҸзҡ„зҺҜеўғдёӢпјҢеӨҡдёӘе®һдҫӢзҡ„иҢғеӣҙеҶ…пјҢиҝҷдёӘkeyзҡ„йҷҗеҲ¶жөҒйҮҸзҡ„зҙҜеҠ жҳҜжқҘиҮӘеӨҡдёӘе®һдҫӢзҡ„жөҒйҮҸпјҢиҫҫеҲ°йҷҗеҲ¶пјҢжүҖжңүзҡ„е®һдҫӢйғҪдјҡйҷҗеҲ¶жөҒйҮҸеҲ°иҫҫDBгҖӮ
2гҖҒеҲ©з”ЁеҲҶеёғејҸй”Ғ
иҝҷйҮҢз®ҖеҚ•иҜҙдёӢеҲҶеёғејҸй”Ғзҡ„е®ҡд№үпјҢеңЁе№¶еҸ‘еңәжҷҜдёӢпјҢйңҖиҰҒдҪҝз”Ёй”ҒеҜ№е…ұдә«иө„жәҗдә’ж–Ҙи®ҝй—®жқҘдҝқиҜҒзәҝзЁӢе®үе…ЁпјӣеҗҢж ·пјҢеңЁеҲҶеёғејҸеңәжҷҜдёӢпјҢд№ҹйңҖиҰҒдёҖз§ҚжңәеҲ¶жқҘдҝқиҜҒеҜ№еӨҡиҠӮзӮ№е…ұдә«иө„жәҗзҡ„дә’ж–Ҙи®ҝй—®пјҢе®һзҺ°жңәеҲ¶е°ұжҳҜеҲҶеёғејҸй”ҒгҖӮ
еңЁиҝҷйҮҢе…ұдә«иө„жәҗе°ұжҳҜдҫӢеӯҗдёӯзҡ„huawei proпјҢд№ҹе°ұжҳҜеңЁи®ҝй—®dbдёӯзҡ„huawei pro зҡ„ж—¶еҖҷпјҢиҰҒдҝқиҜҒеҸӘжңүдёҖдёӘзәҝзЁӢжҲ–иҖ…дёҖдёӘжөҒйҮҸеҺ»и®ҝй—®пјҢе°ұиҫҫеҲ°дәҶеҲҶеёғејҸй”Ғзҡ„ж•ҲжһңгҖӮ
зңӢеӣҫиҜҙиҜқпјҡ
еҺ»жҠўй”Ғпјҡ
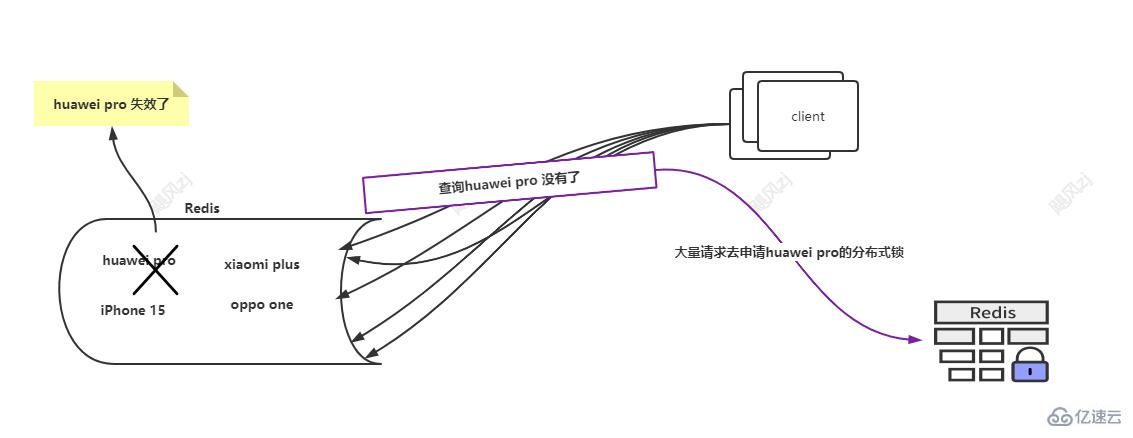
еӨ§йҮҸиҜ·жұӮеңЁжІЎжңүиҺ·еҸ–еҲ°huawei pro иҝҷдёӘkeyзҡ„еҖјеҗҺпјҢеҮҶеӨҮеҺ»dbиҺ·еҸ–ж•°жҚ®пјҢжӯӨж—¶иҺ·еҸ–dbзҡ„д»Јз ҒеҠ дәҶеҲҶеёғејҸй”ҒпјҢйӮЈд№ҲжҜҸдёӘиҜ·жұӮпјҢд№ҹжҳҜжҜҸдёӘзәҝзЁӢйғҪдјҡеҺ»иҺ·еҸ–huawei pro зҡ„еҲҶеёғејҸй”Ғ(еӣҫдёӯеҲ©з”Ёredisе®һзҺ°дәҶеҲҶеёғејҸй”ҒпјҢеҗҺйқўжҲ‘дјҡжңүеҚ•зӢ¬дёҖзҜҮж–Үз« жқҘд»Ӣз»ҚеҲҶеёғејҸй”Ғзҡ„е®һзҺ°пјҢдёҚйҷҗдәҺredis)гҖӮ
иҺ·еҸ–й”Ғд№ӢеҗҺпјҡ
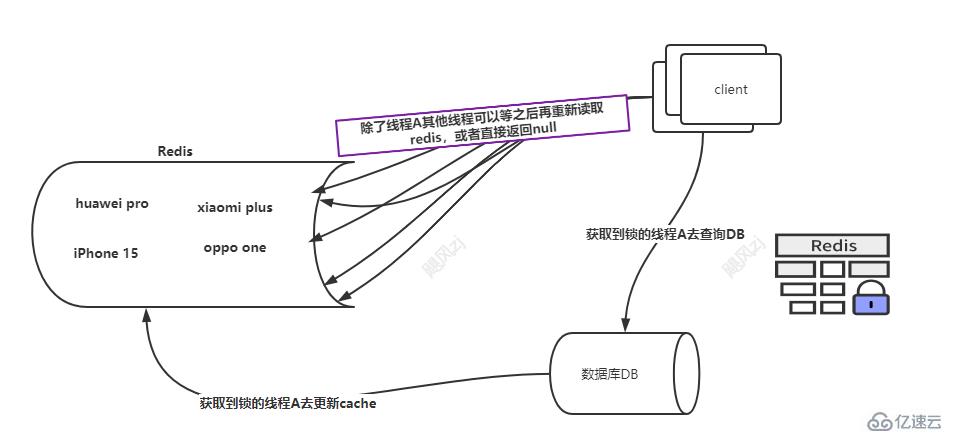
жӯӨж—¶зәҝзЁӢAиҺ·еҸ–дәҶhuawei pro зҡ„еҲҶеёғејҸй”ҒпјҢйӮЈд№ҲзәҝзЁӢAе°ұдјҡеҺ»DBеҠ иҪҪж•°жҚ®пјҢ然еҗҺз”ұзәҝзЁӢAе°Ҷhuawei pro еҶҚж¬Ўи®ҫзҪ®еҲ°cacheеҶ…пјҢ然еҗҺиҝ”еӣһж•°жҚ®гҖӮ
е…¶д»–зҡ„зәҝзЁӢе°ұжІЎжңүиҺ·еҸ–еҲ°пјҢдёҖз§Қж–№ејҸе°ұжҳҜзӣҙжҺҘиҝ”еӣһз©әеҖјз»ҷе®ўжҲ·з«ҜпјҢиҝҳжңүдёҖз§Қзӯүеҫ…50-100ms пјҢеӣ дёәжҹҘиҜўdbе’Ңж”ҫе…Ҙredis дјҡеҫҲеҝ«пјҢжӯӨж—¶зӯүеҫ…пјҢеҶҚж¬ЎжҹҘиҜўзҡ„ж—¶еҖҷпјҢз»“жһңеҸҜиғҪе°ұжңүдәҶпјҢеҰӮжһңжІЎжңүе°ұзӣҙжҺҘиҝ”еӣһnullпјҢеҪ“然д№ҹеҸҜд»ҘйҮҚиҜ•пјҢеҪ“然еңЁеӨ§е№¶еҸ‘зҡ„еңәжҷҜдёӢпјҢиҝҳжҳҜеёҢжңӣиғҪеӨҹеҝ«йҖҹзҡ„иҝ”еӣһз»“жһңпјҢдёҚиғҪеҸ‘з”ҹеӨӘеӨҡж¬Ўж•°зҡ„йҮҚиҜ•ж“ҚдҪңгҖӮ
3гҖҒе®ҡж—¶д»»еҠЎжӣҙж–°зғӯзӮ№key
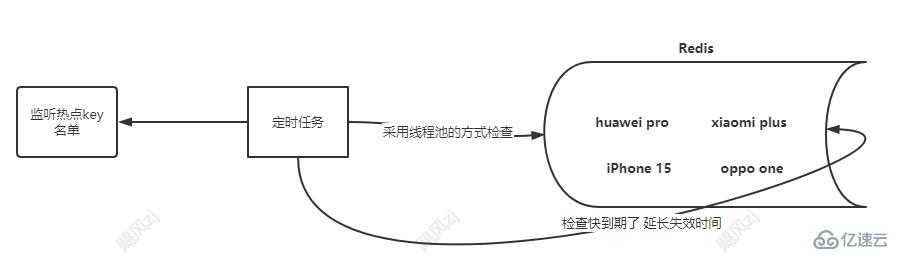
иҝҷдёӘе°ұеҫҲеҘҪзҗҶи§ЈпјҢиҜҙзҷҪдәҶпјҢе°ұжҳҜдёҖдёӘе®ҡж—¶д»»еҠЎе®ҡж—¶зҡ„еҺ»зӣ‘жҺ§жҹҗдәӣзғӯзӮ№keyзҡ„и¶…ж—¶ж—¶й—ҙпјҢжҳҜеҗҰеҲ°жңҹпјҢеҶҚиҝӣиЎҢеҝ«еҲ°жңҹдәҶзҡ„ж—¶еҖҷ延й•ҝkeyеңЁcacheдёӯзҡ„зј“еӯҳж—¶й—ҙе°ұеҸҜд»ҘдәҶгҖӮ
еҚ•дёӘзәҝзЁӢиҪ®иҜўзҡ„ж–№ејҸжЈҖжҹҘе’Ңжӣҙж–°еӨұж•Ҳж—¶й—ҙ,зңӢеӣҫпјҡ
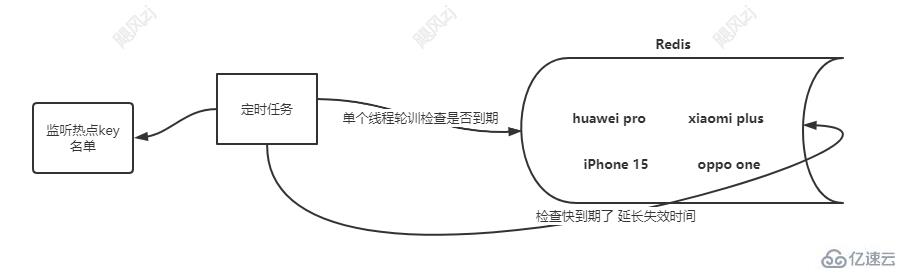
еӨҡзәҝзЁӢзҡ„ж–№ејҸпјҢжіЁж„ҸзғӯзӮ№зҡ„key дёҚиғҪеӨӘеӨҡпјҢжҹҗдёӘзәҝзЁӢдјҡејҖеҗҜеҫҲеӨҡпјҢеҰӮжһңзғӯзӮ№keyеҫҲеӨҡпјҢеҸҜд»ҘйҮҮз”ЁзәҝзЁӢжұ зҡ„ж–№ејҸпјҢзңӢеӣҫпјҡ
延иҝҹйҳҹеҲ—е®һзҺ°
дёҠйқўзҡ„ж–№ејҸиҜҙзҷҪдәҶпјҢж— и®әжҳҜеҚ•дёӘзәҝзЁӢиҝҳжҳҜеӨҡдёӘзәҝзЁӢпјҢйғҪжҳҜдјҡйҮҮз”ЁиҪ®иҜўзҡ„ж–№ејҸпјҲжҜҸж¬ЎзҷҪзҷҪжөӘиҙ№зҡ„cpuпјүпјҢжқҘжЈҖжҹҘжҳҜеҗҰkey еҝ«еҲ°жңҹдәҶпјҢиҝҷз§Қж–№ејҸжЈҖжҹҘдјҡеӯҳеңЁжЈҖжҹҘж—¶й—ҙдёҚеҮҶзЎ®пјҢеҸҜиғҪдјҡйҖ жҲҗж—¶й—ҙзҡ„延иҝҹжҲ–иҖ…дёҚеҮҶзЎ®пјҢдҪ еңЁзӯүеҫ…иҝӣиЎҢдёӢж¬ЎжЈҖжҹҘзҡ„ж—¶еҖҷпјҢиҝҷдёӘkeyе°ұжІЎдәҶпјҢйӮЈд№ҲжӯӨж—¶е°ұе·Із»ҸеҸ‘дәҶеҮ»з©ҝпјҢиҝҷдёӘжғ…еҶөзҡ„еҸ‘з”ҹиҷҪ然жҰӮзҺҮдҪҺпјҢдҪҶд№ҹжҳҜжңүзҡ„пјҢйӮЈд№ҲжҲ‘们жҖҺд№ҲжүҚиғҪйҒҝе…Қе‘ўпјҢе…¶е®һе’ұ们еҸҜд»ҘеҲ©з”Ёе»¶иҝҹйҳҹеҲ—(зҺҜеҪўйҳҹеҲ—жқҘе®һзҺ°пјҢиҝҷйҮҢжҲ‘дёҚж·ұе…Ҙи®ІиҝҷдёӘйҳҹеҲ—зҡ„еҺҹзҗҶдәҶпјҢеӨ§е®¶еҸҜд»ҘиҮӘиЎҢзҷҫеәҰжҲ–иҖ…google)пјҢжүҖи°“зҡ„延иҝҹйҳҹеҲ—е°ұжҳҜдҪ еҫҖиҝҷдёӘйҳҹеҲ—еҸ‘йҖҒж¶ҲжҒҜпјҢеёҢжңӣжҢүз…§дҪ и®ҫзҪ®зҡ„ж—¶й—ҙжқҘиҝӣиЎҢж¶Ҳиҙ№пјҢж—¶й—ҙжІЎеҲ°дёҚдјҡиҝӣиЎҢж¶Ҳиҙ№пјҢж—¶й—ҙеҲ°дәҶе°ұиҝӣиЎҢж¶Ҳиҙ№пјҢеҘҪдәҶпјҢзңӢеӣҫиҜҙиҜқеҗ§пјҡ
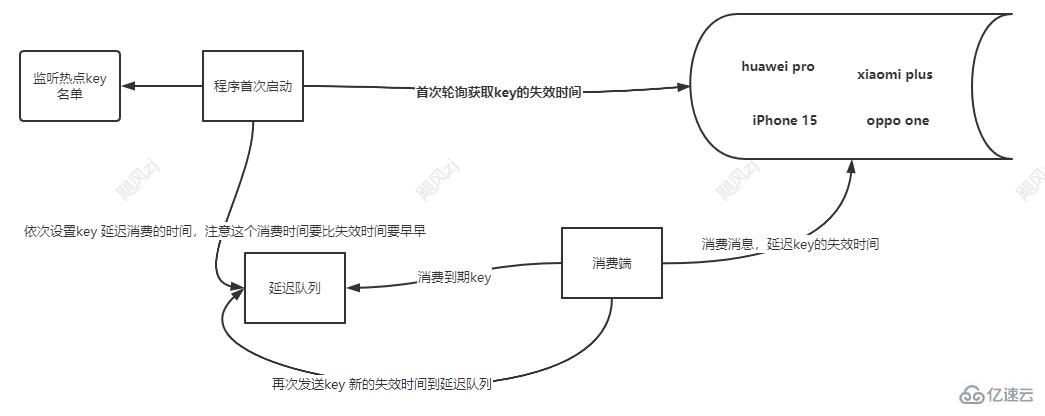
1гҖҒзЁӢеәҸйҰ–ж¬ЎеҗҜеҠЁ иҺ·еҸ–еҗҚеҚ•еҶ…keyзҡ„еӨұж•Ҳж—¶й—ҙгҖӮ
2гҖҒдҫқж¬Ўи®ҫзҪ®key 延иҝҹж¶Ҳиҙ№зҡ„ж—¶й—ҙпјҢжіЁж„ҸиҝҷдёӘж¶Ҳиҙ№ж—¶й—ҙиҰҒжҜ”еӨұж•Ҳж—¶й—ҙиҰҒж—©гҖӮ
3гҖҒ延иҝҹйҳҹеҲ—еҲ°жңҹпјҢж¶Ҳиҙ№з«ҜиҝӣиЎҢж¶Ҳиҙ№keyгҖӮ
4гҖҒж¶Ҳиҙ№з«Ҝж¶Ҳиҙ№ж¶ҲжҒҜпјҢ延иҝҹkeyзҡ„еӨұж•Ҳж—¶й—ҙеҲ°cacheгҖӮ
5гҖҒеҶҚж¬ЎеҸ‘йҖҒkey ж–°зҡ„еӨұж•Ҳж—¶й—ҙеҲ°е»¶иҝҹйҳҹеҲ—пјҢзӯүеҫ…дёӢ次延иҝҹcacheзҡ„еӨұж•Ҳж—¶й—ҙгҖӮ
4гҖҒи®ҫзҪ®key дёҚеӨұж•Ҳ
иҝҷз§Қе…¶е®һд№ҹеҸҜиғҪдјҡеӣ дёәеҶ…еӯҳдёҚи¶іпјҢkey иў«ж·ҳжұ°пјҢеӨ§е®¶еҸҜд»Ҙжғіжғід»Җд№Ҳжғ…еҶөдёӢпјҢkey дјҡиў«ж·ҳжұ°гҖӮ
зј“еӯҳз©ҝйҖҸ
е®ҡд№ү
жүҖи°“з©ҝйҖҸпјҢе°ұжҳҜи®ҝй—®дәҶдёҖдёӘcacheдёҚеӯҳеңЁпјҢж•°жҚ®еә“йҮҢд№ҹдёҚеӯҳеңЁзҡ„keyпјҢйӮЈд№ҲжӯӨж—¶зӣёеҪ“дәҺжөҒйҮҸзӣҙжҺҘеҲ°иҫҫдәҶDB дәҶпјҢйӮЈд№ҲдёҖдәӣжөҒж°“е°ұеҸҜд»ҘеҲ©з”ЁиҝҷдёӘжјҸжҙһпјҢз–ҜзӢӮзҡ„еҲ·дҪ зҡ„жҺҘеҸЈпјҢиҝӣиҖҢжҠҠдҪ зҡ„DBжү“еһ®пјҢдҪ зҡ„дёҡеҠЎд№ҹе°ұдёҚиғҪжӯЈеёёиҝҗиЎҢдәҶгҖӮ
еҰӮдҪ•и§ЈеҶіе‘ўпјҹ
1гҖҒи®ҫзҪ®null жҲ–иҖ…зү№ж®ҠеҖј
жҲ‘们еҸҜд»ҘйҖҡиҝҮи®ҫзҪ®null жҲ–иҖ…зү№е®ҡзҡ„еҖјеҲ°redisеҶ…пјҢдё”дёҚиҝҮжңҹпјҢйӮЈд№ҲдёӢж¬ЎеҶҚжқҘзҡ„ж—¶еҖҷпјҢзӣҙжҺҘд»Һredis иҺ·еҸ–иҝҷдёӘnull жҲ–иҖ… зү№ж®ҠеҖје°ұеҸҜд»ҘдәҶгҖӮ
иҝҷдёӘж–№жЎҲдёҚиғҪи§ЈеҶіж №жң¬жҖ§зҡ„й—®йўҳпјҢеҰӮжһңиҝҷдёӘжөҒйҮҸиғҪд»ҝйҖ еҮәеӨ§йҮҸзҡ„ж— з”ЁkeyпјҢдҪ и®ҫзҪ®еҶҚеӨҡзҡ„nullжҲ–иҖ…зү№ж®Ҡзҡ„еҖјйғҪжҳҜжІЎжңүз”Ёзҡ„пјҢйӮЈд№ҲжҲ‘们еә”иҜҘжҖҺд№Ҳи§ЈеҶіе‘ўпјҹ
2гҖҒеёғйҡҶиҝҮж»ӨеҷЁ
еёғйҡҶиҝҮж»ӨеҷЁ иӢұж–Үдёә bloomfilerпјҢиҝҷйҮҢжҲ‘们еҸӘжҳҜеҒҡз®ҖеҚ•зҡ„д»Ӣз»ҚпјҢд»ӢдәҺзҜҮе№…зҡ„еҺҹеӣ пјҢеҗҺйқўдјҡжңүеҚ•зӢ¬зҡ„ж–Үз« еҒҡд»Ӣз»ҚгҖӮ
дёҫдёӘдҫӢеӯҗпјҢеҰӮжһңжҲ‘们数жҚ®еә“йҮҢеӯҳеӮЁзқҖеҚғдёҮзә§еҲ«зҡ„sku ж•°жҚ®пјҢжҲ‘们зҺ°еңЁзҡ„йңҖжұӮжҳҜеҰӮжһңеә“жңүиҝҷдёӘskuпјҢйӮЈд№Ҳе°ұжҹҘиҜўredis пјҢеҰӮжһңredis жІЎжңүе°ұжҹҘиҜўж•°жҚ®еә“пјҢ然еҗҺжӣҙж–°redisпјҢжҲ‘们жңҖе…ҲжғіеҲ°зҡ„е°ұжҳҜжҠҠskuж•°жҚ®ж”ҫе…ҘеҲ°дёҖhashmapеҶ…пјҢkey е°ұжҳҜskuпјҢеӣ дёәsku зҡ„ж•°йҮҸеҫҲеӨҡпјҢйӮЈд№ҲиҝҷдёӘhashmapеҚ з”Ёзҡ„еҶ…еӯҳз©әй—ҙдјҡеҫҲеӨ§пјҢжңүеҸҜиғҪдјҡж’‘зҲҶеҶ…еӯҳпјҢжңҖеҗҺеҫ—дёҚеҒҝеӨұдәҶпјҢйӮЈд№ҲжҖҺд№ҲжқҘиҠӮзңҒеҶ…еӯҳпјҢжҲ‘们еҸҜд»ҘеҲ©з”ЁдёҖдёӘbitзҡ„ж•°з»„пјҢжқҘеӯҳеӮЁиҝҷдёӘskuжҳҜеҗҰеӯҳеңЁзҠ¶жҖҒпјҢ0 д»ЈиЎЁдёҚеӯҳеңЁпјҢ1 д»ЈиЎЁеӯҳеңЁпјҢжҲ‘们еҸҜд»ҘеҲ©з”ЁдёҖдёӘж•ЈеҲ—еҮҪж•°пјҢз®—еҮәskuзҡ„ж•ЈеҲ—еҖјпјҢ然еҗҺskuзҡ„ж•ЈеҲ—еҖјеҜ№bitж•°з»„иҝӣиЎҢеҸ–жЁЎпјҢжүҫеҲ°жүҖеңЁж•°з»„зҡ„дҪҚзҪ®пјҢ然еҗҺи®ҫзҪ®дёә1пјҢеҪ“иҜ·жұӮжқҘзҡ„ж—¶еҖҷпјҢжҲ‘们дјҡз®—еҮәиҝҷдёӘsku ж•ЈеҲ—еҖјеҜ№еә”зҡ„ж•°з»„дҪҚзҪ®жҳҜеҗҰдёә1 пјҢдёә1 иҜҙжҳҺе°ұеӯҳеңЁпјҢдёә0 иҜҙжҳҺе°ұдёҚеӯҳеңЁгҖӮиҝҷж ·дёҖдёӘз®ҖеҚ•зҡ„bloomfilterе°ұе®һзҺ°дәҶпјҢbloomfiler жҳҜжңүй”ҷиҜҜзҺҮпјҢеҸҜд»ҘиҖғиҷ‘еўһеҠ ж•°з»„й•ҝеәҰе’Ңж•ЈеҲ—еҮҪж•°зҡ„ж•°йҮҸжқҘжҸҗдҫӣеҮҶзЎ®зҺҮпјҢе…·дҪ“еҸҜд»ҘзҷҫеәҰжҲ–иҖ…googleпјҢд»ҠеӨ©еңЁиҝҷйҮҢе°ұдёҚи®ІдәҶгҖӮ
дёӢйқўзңӢзңӢеҲ©з”Ёbloomfiler жқҘйҳІжӯўзј“еӯҳз©ҝйҖҸзҡ„жөҒзЁӢпјҢзңӢеӣҫиҜҙиҜқпјҡ
bloomfilerзҡ„еҲқе§ӢеҢ– еҸҜд»ҘйҖҡиҝҮдёҖдёӘе®ҡж—¶д»»еҠЎжқҘиҜ»еҸ– dbпјҢеҲқе§ӢеҢ–bitж•°з»„зҡ„еӨ§е°ҸпјҢй»ҳи®ӨеҖјйғҪжҳҜдёә0пјҢиЎЁзӨәдёҚеӯҳеңЁпјҢ然еҗҺжҜҸжқЎйғҪи®Ўз®—ж•ЈеҲ—еҖјеҜ№еә”зҡ„ж•°з»„дҪҚзҪ®пјҢ然еҗҺжҸ’е…ҘеҲ°bit ж•°з»„дёӯгҖӮ

иҜ·жұӮжөҒзЁӢпјҢзңӢеӣҫпјҡ
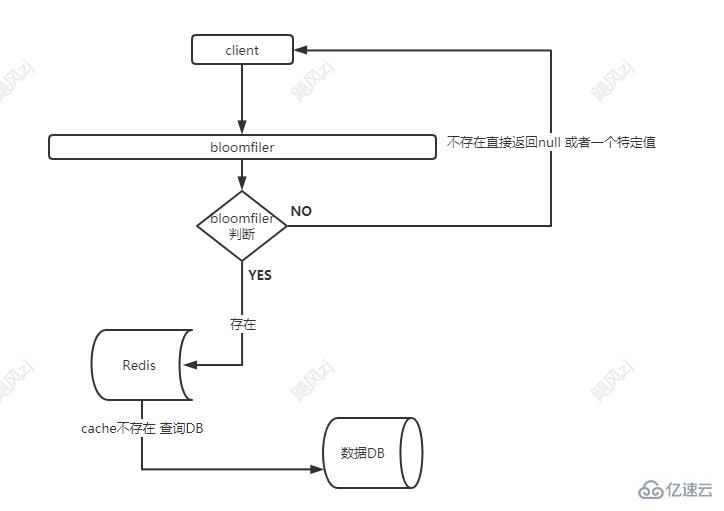
еҰӮжһңдёҚеҲ©з”Ёbloomfiler иҝҮж»ӨеҷЁпјҢеҜ№дәҺдёҖдёӘж•°жҚ®еә“йҮҢж №жң¬дёҚеӯҳеңЁзҡ„keyпјҢе…¶е®һзҷҪзҷҪжөӘиҙ№дәҶдёӨж¬ЎIOпјҢдёҖж¬ЎжҹҘиҜўredisпјҢдёҖж¬ЎжҹҘиҜўDBпјҢжңүдәҶbloomfiler пјҢйӮЈд№Ҳе°ұиҠӮзңҒдәҶиҝҷдёӨж¬Ўж— з”Ёзҡ„IOпјҢеҮҸе°‘еҗҺз«Ҝredis е’Ң DB иө„жәҗзҡ„жөӘиҙ№гҖӮ
жҖ»з»“
зј“еӯҳйӣӘеҙ©
и§ЈеҶіж–№жЎҲпјҡ
зј“еӯҳеҮ»з©ҝ
и§ЈеҶіж–№жЎҲпјҡ
зј“еӯҳз©ҝйҖҸ
и§ЈеҶіж–№жЎҲпјҡ
д»ҘдёҠжҳҜвҖңRedisдёӯзј“еӯҳйӣӘеҙ©гҖҒзј“еӯҳеҮ»з©ҝе’Ңзј“еӯҳз©ҝйҖҸзҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ





