这篇文章主要为大家展示了“Python中下划线有什么含义”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“Python中下划线有什么含义”这篇文章吧。
本文介绍了Python中单下划线和双下划线("dunder")的各种含义和命名约定,名称修饰(name mangling)的工作原理,以及它如何影响你自己的Python类。
单下划线和双下划线在 Python 变量和方法名称中都各有其含义。有一些含义仅仅是依照约定,被视作是对程序员的提示,而有一些含义是由 Python 解释器严格执行的。
如果你想知道“Python 变量和方法名称中单下划线和双下划线的含义是什么?”,我会尽我所能在这里为你解答。
在本文中,我将讨论以下五种下划线模式和命名约定,以及它们如何影响 Python 程序的行为:
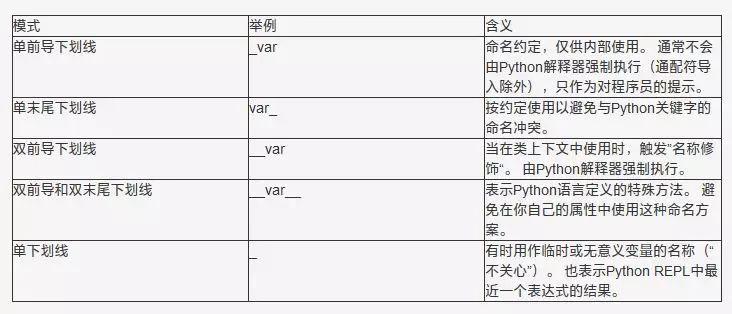
单前导下划线:_var
单末尾下划线:var_
双前导下划线:__var
双前导和末尾下划线:_var_
单下划线:_
在文章结尾处,你可以找到一个简短的“速查表”,总结了五种不同的下划线命名约定及其含义,以及一个简短的视频教程,可让你亲身体验它们的行为。
让我们马上开始!
当涉及到变量和方法名称时,单个下划线前缀有一个约定俗成的含义。 它是对程序员的一个提示,意味着 Python 社区一致认为它应该是什么意思,但程序的行为不受影响。
下划线前缀的含义是告知其他程序员:以单个下划线开头的变量或方法仅供内部使用。 该约定在 PEP8 中有定义。
这不是 Python 强制规定的。 Python 不像 Java 那样在“私有”和“公共”变量之间有很强的区别。 这就像有人提出了一个小小的下划线警告标志,说:
“嘿,这不是真的要成为类的公共接口的一部分。不去管它就好。“
看看下面的例子:
class Test:
def __init__(self):
self.foo = 11
self._bar = 23如果你实例化此类,并尝试访问在__init__构造函数中定义的 foo 和 _bar 属性,会发生什么情况? 让我们来看看:
>>> t = Test()
>>> t.foo
11
>>> t._bar
23你会看到 _bar 中的单个下划线并没有阻止我们“进入”类并访问该变量的值。
这是因为 Python 中的单个下划线前缀仅仅是一个约定,至少相对于变量和方法名而言。
但是,前导下划线的确会影响从模块中导入名称的方式。
假设你在一个名为 my_module 的模块中有以下代码:
# This is my_module.py:
def external_func():
return 23
def _internal_func():
return 42现在,如果使用通配符从模块中导入所有名称,则 Python 不会导入带有前导下划线的名称(除非模块定义了覆盖此行为的__all__列表):
>>> from my_module import *
>>> external_func()
23
>>> _internal_func()
NameError: "name '_internal_func' is not defined"顺便说一下,应该避免通配符导入,因为它们使名称空间中存在哪些名称不清楚 。 为了清楚起见,坚持常规导入更好。
与通配符导入不同,常规导入不受前导单个下划线命名约定的影响:
>>> import my_module
>>> my_module.external_func()
23
>>> my_module._internal_func()
42我知道这一点可能有点令人困惑。 如果你遵循 PEP8 推荐,避免通配符导入,那么你真正需要记住的只有这个:
单个下划线是一个 Python 命名约定,表示这个名称是供内部使用的。 它通常不由 Python 解释器强制执行,仅仅作为一种对程序员的提示。
有时候,一个变量的最合适的名称已经被一个关键字所占用。 因此,像 class 或 def 这样的名称不能用作 Python 中的变量名称。 在这种情况下,你可以附加一个下划线来解决命名冲突:
>>> def make_object(name, class):
SyntaxError: "invalid syntax"
>>> def make_object(name, class_):
... pass总之,单个末尾下划线(后缀)是一个约定,用来避免与 Python 关键字产生命名冲突。 PEP8 解释了这个约定。
到目前为止,我们所涉及的所有命名模式的含义,来自于已达成共识的约定。 而对于以双下划线开头的 Python 类的属性(包括变量和方法),情况就有点不同了。
双下划线前缀会导致 Python 解释器重写属性名称,以避免子类中的命名冲突。
这也叫做名称修饰(name mangling),解释器更改变量的名称,以便在类被扩展的时候不容易产生冲突。
我知道这听起来很抽象。 因此,我组合了一个小小的代码示例来予以说明:
class Test:
def __init__(self):
self.foo = 11
self._bar = 23
self.__baz = 23让我们用内置的 dir() 函数来看看这个对象的属性:
>>> t = Test()
>>> dir(t)
['_Test__baz', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_bar', 'foo']以上是这个对象属性的列表。 让我们来看看这个列表,并寻找我们的原始变量名称 foo,_bar和 __baz , 我保证你会注意到一些有趣的变化。
self.foo 变量在属性列表中显示为未修改为 foo。
self._bar 的行为方式相同 - 它以 _bar 的形式显示在类上。 就像我之前说过的,在这种情况下,前导下划线仅仅是一个约定。 给程序员一个提示而已。
然而,对于 self.__baz 而言,情况看起来有点不同。 当你在该列表中搜索 __baz 时,你会看不到有这个名字的变量。
如果你仔细观察,你会看到此对象上有一个名为 _Test__baz 的属性。 这就是 Python 解释器所做的名称修饰。 它这样做是为了防止变量在子类中被重写。
让我们创建另一个扩展 Test 类的类,并尝试重写构造函数中添加的现有属性:
class ExtendedTest(Test):
def __init__(self):
super().__init__()
self.foo = 'overridden'
self._bar = 'overridden'
self.__baz = 'overridden'现在,你认为 foo,_bar和 __baz 的值会出现在这个 ExtendedTest 类的实例上吗? 我们来看一看:
>>> t2 = ExtendedTest()
>>> t2.foo
'overridden'
>>> t2._bar
'overridden'
>>> t2.__baz
AttributeError: "'ExtendedTest' object has no attribute '__baz'"等一下,当我们尝试查看 t2 .__ baz 的值时,为什么我们会得到 AttributeError? 名称修饰被再次触发了! 事实证明,这个对象甚至没有 __baz 属性:
['_ExtendedTest__baz', '_Test__baz', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_bar', 'foo']正如你可以看到 __baz变成 _ExtendedTest__baz 以防止意外修改:
>>> t2._ExtendedTest__baz
'overridden'但原来的 _Test__baz 还在:
>>> t2._Test__baz
42双下划线名称修饰对程序员是完全透明的。 下面的例子证实了这一点:
class ManglingTest:
def __init__(self):
self.__mangled = 'hello'
def get_mangled(self):
return self.__mangled
>>> ManglingTest().get_mangled()
'hello'
>>> ManglingTest().__mangled
AttributeError: "'ManglingTest' object has no attribute '__mangled'"名称修饰是否也适用于方法名称? 是的,也适用。名称修饰会影响在一个类的上下文中,以两个下划线字符("dunders")开头的所有名称:
class MangledMethod:
def __method(self):
return 42
def call_it(self):
return self.__method()
>>> MangledMethod().__method()
AttributeError: "'MangledMethod' object has no attribute '__method'"
>>> MangledMethod().call_it()
42这是另一个也许令人惊讶的运用名称修饰的例子:
_MangledGlobal__mangled = 23
class MangledGlobal:
def test(self):
return __mangled
>>> MangledGlobal().test()
23在这个例子中,我声明了一个名为_MangledGlobal__mangled 的全局变量。然后我在名为 MangledGlobal 的类的上下文中访问变量。由于名称修饰,我能够在类的 test() 方法内,以 __mangled 来引用_MangledGlobal__mangled全局变量。
Python 解释器自动将名称__mangled 扩展为 _MangledGlobal__mangled,因为它以两个下划线字符开头。这表明名称修饰不是专门与类属性关联的。它适用于在类上下文中使用的两个下划线字符开头的任何名称。
有很多要吸收的内容吧。
老实说,这些例子和解释不是从我脑子里蹦出来的。我作了一些研究和加工才弄出来。我一直使用 Python,有很多年了,但是像这样的规则和特殊情况并不总是浮现在脑海里。
有时候程序员最重要的技能是“模式识别”,而且知道在哪里查阅信息。如果您在这一点上感到有点不知所措,请不要担心。慢慢来,试试这篇文章中的一些例子。
让这些概念完全沉浸下来,以便你能够理解名称修饰的总体思路,以及我向您展示的一些其他的行为。如果有一天你和它们不期而遇,你会知道在文档中按什么来查。
也许令人惊讶的是,如果一个名字同时以双下划线开始和结束,则不会应用名称修饰。 由双下划线前缀和后缀包围的变量不会被Python解释器修改:
class PrefixPostfixTest:
def __init__(self):
self.__bam__ = 42
>>> PrefixPostfixTest().__bam__
42但是,Python保留了有双前导和双末尾下划线的名称,用于特殊用途。 这样的例子有,_init__对象构造函数,或_call --- 它使得一个对象可以被调用。
这些dunder方法通常被称为神奇方法 - 但Python社区中的许多人(包括我自己)都不喜欢这种方法。
最好避免在自己的程序中使用以双下划线(“dunders”)开头和结尾的名称,以避免与将来Python语言的变化产生冲突。
按照习惯,有时候单个独立下划线是用作一个名字,来表示某个变量是临时的或无关紧要的。
例如,在下面的循环中,我们不需要访问正在运行的索引,我们可以使用“_”来表示它只是一个临时值:
>>> for _ in range(32):
... print('Hello, World.')你也可以在拆分(unpacking)表达式中将单个下划线用作“不关心的”变量,以忽略特定的值。 同样,这个含义只是“依照约定”,并不会在Python解释器中触发特殊的行为。 单个下划线仅仅是一个有效的变量名称,会有这个用途而已。
在下面的代码示例中,我将汽车元组拆分为单独的变量,但我只对颜色和里程值感兴趣。 但是,为了使拆分表达式成功运行,我需要将包含在元组中的所有值分配给变量。 在这种情况下,“_”作为占位符变量可以派上用场:
>>> car = ('red', 'auto', 12, 3812.4)
>>> color, _, _, mileage = car
>>> color
'red'
>>> mileage
3812.4
>>> _
12除了用作临时变量之外,“_”是大多数Python REPL中的一个特殊变量,它表示由解释器评估的最近一个表达式的结果。
这样就很方便了,比如你可以在一个解释器会话中访问先前计算的结果,或者,你是在动态构建多个对象并与它们交互,无需事先给这些对象分配名字:
>>> 20 + 3
23
>>> _
23
>>> print(_)
23
>>> list()
[]
>>> _.append(1)
>>> _.append(2)
>>> _.append(3)
>>> _
[1, 2, 3]以下是一个简短的小结,即“速查表”,罗列了我在本文中谈到的五种Python下划线模式的含义:
以上是“Python中下划线有什么含义”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



