йӣ¶жӢ·иҙқзҡ„еҺҹзҗҶд»ҘеҸҠjavaе®һзҺ°ж–№ејҸ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңйӣ¶жӢ·иҙқзҡ„еҺҹзҗҶд»ҘеҸҠjavaе®һзҺ°ж–№ејҸвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
зӣ®еҪ•
йӣ¶жӢ·иҙқ
йӣ¶жӢ·иҙқпјҲZero-CopyпјүжҳҜдёҖз§Қ I/O ж“ҚдҪңдјҳеҢ–жҠҖжңҜпјҢеҸҜд»Ҙеҝ«йҖҹй«ҳж•Ҳең°е°Ҷж•°жҚ®д»Һж–Ү件系з»ҹ移еҠЁеҲ°зҪ‘з»ңжҺҘеҸЈпјҢиҖҢдёҚйңҖиҰҒе°Ҷе…¶д»ҺеҶ…ж ёз©әй—ҙеӨҚеҲ¶еҲ°з”ЁжҲ·з©әй—ҙгҖӮе…¶еңЁ FTP жҲ–иҖ… HTTP зӯүеҚҸи®®дёӯеҸҜд»Ҙжҳҫи‘—ең°жҸҗеҚҮжҖ§иғҪгҖӮдҪҶжҳҜйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢ并дёҚжҳҜжүҖжңүзҡ„ж“ҚдҪңзі»з»ҹйғҪж”ҜжҢҒиҝҷдёҖзү№жҖ§пјҢзӣ®еүҚеҸӘжңүеңЁдҪҝз”Ё NIO е’Ң Epoll дј иҫ“ж—¶жүҚеҸҜдҪҝз”ЁиҜҘзү№жҖ§гҖӮ
йңҖиҰҒжіЁж„ҸпјҢе®ғдёҚиғҪз”ЁдәҺе®һзҺ°дәҶж•°жҚ®еҠ еҜҶжҲ–иҖ…еҺӢзј©зҡ„ж–Ү件系з»ҹдёҠпјҢеҸӘжңүдј иҫ“ж–Ү件зҡ„еҺҹе§ӢеҶ…е®№гҖӮиҝҷзұ»еҺҹе§ӢеҶ…е®№д№ҹеҢ…жӢ¬еҠ еҜҶдәҶзҡ„ж–Ү件еҶ…е®№гҖӮ
дј з»ҹI/Oж“ҚдҪңеӯҳеңЁзҡ„жҖ§иғҪй—®йўҳ
еҰӮжһңжңҚеҠЎз«ҜиҰҒжҸҗдҫӣж–Үд»¶дј иҫ“зҡ„еҠҹиғҪпјҢжҲ‘们иғҪжғіеҲ°зҡ„жңҖз®ҖеҚ•зҡ„ж–№ејҸжҳҜпјҡе°ҶзЈҒзӣҳдёҠзҡ„ж–Ү件иҜ»еҸ–еҮәжқҘпјҢ然еҗҺйҖҡиҝҮзҪ‘з»ңеҚҸи®®еҸ‘йҖҒз»ҷе®ўжҲ·з«ҜгҖӮ
дј з»ҹ I/O зҡ„е·ҘдҪңж–№ејҸжҳҜпјҢж•°жҚ®иҜ»еҸ–е’ҢеҶҷе…ҘжҳҜд»Һз”ЁжҲ·з©әй—ҙеҲ°еҶ…ж ёз©әй—ҙжқҘеӣһеӨҚеҲ¶пјҢиҖҢеҶ…ж ёз©әй—ҙзҡ„ж•°жҚ®жҳҜйҖҡиҝҮж“ҚдҪңзі»з»ҹеұӮйқўзҡ„ I/O жҺҘеҸЈд»ҺзЈҒзӣҳиҜ»еҸ–жҲ–еҶҷе…ҘгҖӮ
д»Јз ҒйҖҡеёёеҰӮдёӢпјҢдёҖиҲ¬дјҡйңҖиҰҒдёӨдёӘзі»з»ҹи°ғз”Ёпјҡ
read(file, tmp_buf, len);
write(socket, tmp_buf, len);
д»Јз ҒеҫҲз®ҖеҚ•пјҢиҷҪ然е°ұдёӨиЎҢд»Јз ҒпјҢдҪҶжҳҜиҝҷйҮҢйқўеҸ‘з”ҹдәҶдёҚе°‘зҡ„дәӢжғ…гҖӮ
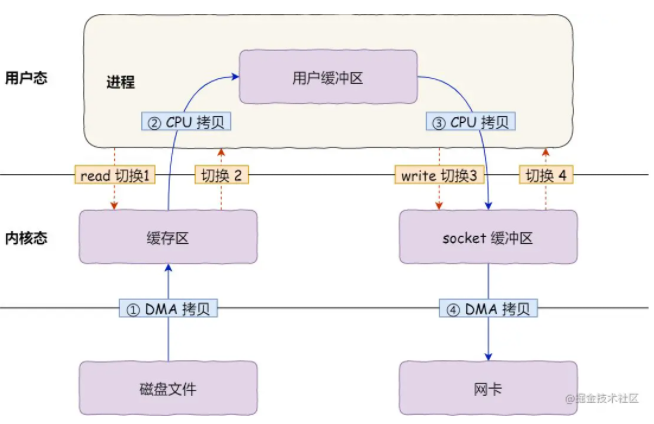
йҰ–е…ҲпјҢжңҹй—ҙе…ұеҸ‘з”ҹдәҶ 4 ж¬Ўз”ЁжҲ·жҖҒдёҺеҶ…ж ёжҖҒзҡ„дёҠдёӢж–ҮеҲҮжҚўпјҢеӣ дёәеҸ‘з”ҹдәҶдёӨж¬Ўзі»з»ҹи°ғз”ЁпјҢдёҖж¬ЎжҳҜ read() пјҢдёҖж¬ЎжҳҜ write()пјҢжҜҸж¬Ўзі»з»ҹи°ғз”ЁйғҪеҫ—е…Ҳд»Һз”ЁжҲ·жҖҒеҲҮжҚўеҲ°еҶ…ж ёжҖҒпјҢзӯүеҶ…ж ёе®ҢжҲҗд»»еҠЎеҗҺпјҢеҶҚд»ҺеҶ…ж ёжҖҒеҲҮжҚўеӣһз”ЁжҲ·жҖҒгҖӮ
дёҠдёӢж–ҮеҲҮжҚўеҲ°жҲҗжң¬е№¶дёҚе°ҸпјҢдёҖж¬ЎеҲҮжҚўйңҖиҰҒиҖ—ж—¶еҮ еҚҒзәіз§’еҲ°еҮ еҫ®з§’пјҢиҷҪ然时й—ҙзңӢдёҠеҺ»еҫҲзҹӯпјҢдҪҶжҳҜеңЁй«ҳ并еҸ‘зҡ„еңәжҷҜдёӢпјҢиҝҷзұ»ж—¶й—ҙе®№жҳ“иў«зҙҜз§Ҝе’Ңж”ҫеӨ§пјҢд»ҺиҖҢеҪұе“Қзі»з»ҹзҡ„жҖ§иғҪгҖӮ
е…¶ж¬ЎпјҢиҝҳеҸ‘з”ҹдәҶ 4 ж¬Ўж•°жҚ®жӢ·иҙқпјҢе…¶дёӯдёӨж¬ЎжҳҜ DMA зҡ„жӢ·иҙқпјҢеҸҰеӨ–дёӨж¬ЎеҲҷжҳҜйҖҡиҝҮ CPU жӢ·иҙқзҡ„пјҢдёӢйқўиҜҙдёҖдёӢиҝҷдёӘиҝҮзЁӢпјҡ
第дёҖж¬ЎжӢ·иҙқпјҢжҠҠзЈҒзӣҳдёҠзҡ„ж•°жҚ®жӢ·иҙқеҲ°ж“ҚдҪңзі»з»ҹеҶ…ж ёзҡ„зј“еҶІеҢәйҮҢпјҢиҝҷдёӘжӢ·иҙқзҡ„иҝҮзЁӢжҳҜйҖҡиҝҮ DMA жҗ¬иҝҗзҡ„гҖӮ
第дәҢж¬ЎжӢ·иҙқпјҢжҠҠеҶ…ж ёзј“еҶІеҢәзҡ„ж•°жҚ®жӢ·иҙқеҲ°з”ЁжҲ·зҡ„зј“еҶІеҢәйҮҢпјҢдәҺжҳҜжҲ‘们еә”з”ЁзЁӢеәҸе°ұеҸҜд»ҘдҪҝз”ЁиҝҷйғЁеҲҶж•°жҚ®дәҶпјҢиҝҷдёӘжӢ·иҙқеҲ°иҝҮзЁӢжҳҜз”ұ CPU е®ҢжҲҗзҡ„гҖӮ
第дёүж¬ЎжӢ·иҙқпјҢжҠҠеҲҡжүҚжӢ·иҙқеҲ°з”ЁжҲ·зҡ„зј“еҶІеҢәйҮҢзҡ„ж•°жҚ®пјҢеҶҚжӢ·иҙқеҲ°еҶ…ж ёзҡ„ socket зҡ„зј“еҶІеҢәйҮҢпјҢиҝҷдёӘиҝҮзЁӢдҫқ然иҝҳжҳҜз”ұ CPU жҗ¬иҝҗзҡ„гҖӮ
第еӣӣж¬ЎжӢ·иҙқпјҢжҠҠеҶ…ж ёзҡ„ socket зј“еҶІеҢәйҮҢзҡ„ж•°жҚ®пјҢжӢ·иҙқеҲ°зҪ‘еҚЎзҡ„зј“еҶІеҢәйҮҢпјҢиҝҷдёӘиҝҮзЁӢеҸҲжҳҜз”ұ DMA жҗ¬иҝҗзҡ„гҖӮ
иҝҷз§Қз®ҖеҚ•еҸҲдј з»ҹзҡ„ж–Үд»¶дј иҫ“ж–№ејҸпјҢеӯҳеңЁеҶ—дҪҷзҡ„дёҠж–ҮеҲҮжҚўе’Ңж•°жҚ®жӢ·иҙқпјҢеңЁй«ҳ并еҸ‘зі»з»ҹйҮҢжҳҜйқһеёёзіҹзі•зҡ„пјҢеӨҡдәҶеҫҲеӨҡдёҚеҝ…иҰҒзҡ„ејҖй”ҖпјҢдјҡдёҘйҮҚеҪұе“Қзі»з»ҹжҖ§иғҪгҖӮ
жүҖд»ҘпјҢиҰҒжғіжҸҗй«ҳж–Үд»¶дј иҫ“зҡ„жҖ§иғҪпјҢе°ұйңҖиҰҒеҮҸе°‘гҖҢз”ЁжҲ·жҖҒдёҺеҶ…ж ёжҖҒзҡ„дёҠдёӢж–ҮеҲҮжҚўгҖҚе’ҢгҖҢеҶ…еӯҳжӢ·иҙқгҖҚзҡ„ж¬Ўж•°гҖӮ
йӣ¶жӢ·иҙқжҠҖжңҜеҺҹзҗҶ
йӣ¶жӢ·иҙқдё»иҰҒжҳҜз”ЁжқҘи§ЈеҶіж“ҚдҪңзі»з»ҹеңЁеӨ„зҗҶ I/O ж“ҚдҪңж—¶пјҢйў‘з№ҒеӨҚеҲ¶ж•°жҚ®зҡ„й—®йўҳгҖӮе…ідәҺйӣ¶жӢ·иҙқдё»иҰҒжҠҖжңҜжңү mmap+writeгҖҒsendfileе’ҢspliceзӯүеҮ з§Қж–№ејҸгҖӮ
иҷҡжӢҹеҶ…еӯҳ
еңЁдәҶи§Јйӣ¶жӢ·иҙқжҠҖжңҜд№ӢеүҚпјҢе…ҲдәҶи§ЈиҷҡжӢҹеҶ…еӯҳзҡ„жҰӮеҝөгҖӮ
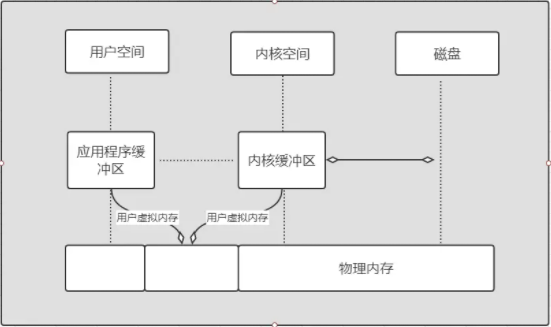
жүҖжңүзҺ°д»Јж“ҚдҪңзі»з»ҹйғҪдҪҝз”ЁиҷҡжӢҹеҶ…еӯҳпјҢдҪҝз”ЁиҷҡжӢҹең°еқҖеҸ–д»Јзү©зҗҶең°еқҖпјҢдё»иҰҒжңүд»ҘдёӢеҮ зӮ№еҘҪеӨ„пјҡ
еҲ©з”ЁдёҠиҝ°зҡ„第дёҖжқЎзү№жҖ§еҸҜд»ҘдјҳеҢ–пјҢеҸҜд»ҘжҠҠеҶ…ж ёз©әй—ҙе’Ңз”ЁжҲ·з©әй—ҙзҡ„иҷҡжӢҹең°еқҖжҳ е°„еҲ°еҗҢдёҖдёӘзү©зҗҶең°еқҖпјҢиҝҷж ·еңЁ I/O ж“ҚдҪңж—¶е°ұдёҚйңҖиҰҒжқҘеӣһеӨҚеҲ¶дәҶгҖӮ
еҰӮдёӢеӣҫеұ•зӨәдәҶиҷҡжӢҹеҶ…еӯҳзҡ„еҺҹзҗҶгҖӮ
mmap/write ж–№ејҸ
дҪҝз”Ёmmap/writeж–№ејҸжӣҝжҚўеҺҹжқҘзҡ„дј з»ҹI/Oж–№ејҸпјҢе°ұжҳҜеҲ©з”ЁдәҶиҷҡжӢҹеҶ…еӯҳзҡ„зү№жҖ§гҖӮдёӢеӣҫеұ•зӨәдәҶmmap/writeеҺҹзҗҶпјҡ
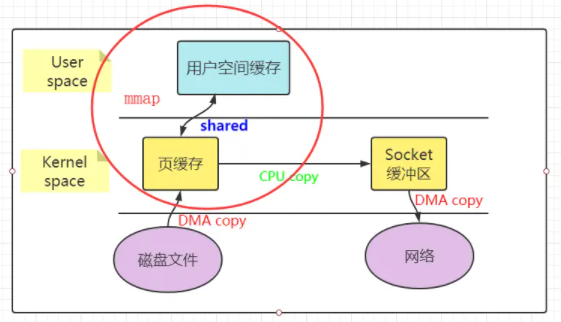
ж•ҙдёӘжөҒзЁӢзҡ„ж ёеҝғеҢәеҲ«е°ұжҳҜпјҢжҠҠж•°жҚ®иҜ»еҸ–еҲ°еҶ…ж ёзј“еҶІеҢәеҗҺпјҢеә”з”ЁзЁӢеәҸиҝӣиЎҢеҶҷе…Ҙж“ҚдҪңж—¶пјҢзӣҙжҺҘжҠҠеҶ…ж ёзҡ„Read Bufferзҡ„ж•°жҚ®еӨҚеҲ¶еҲ°Socket Bufferд»ҘдҫҝеҶҷе…ҘпјҢиҝҷж¬ЎеҶ…ж ёд№Ӣй—ҙзҡ„еӨҚеҲ¶д№ҹжҳҜйңҖиҰҒCPUзҡ„еҸӮдёҺзҡ„гҖӮ
дёҠиҝ°жөҒзЁӢе°ұжҳҜе°‘дәҶдёҖдёӘ CPU COPYпјҢжҸҗеҚҮдәҶ I/O зҡ„йҖҹеәҰгҖӮдёҚиҝҮеҸ‘зҺ°дёҠдёӢж–Үзҡ„еҲҮжҚўиҝҳжҳҜ4次并没жңүеҮҸе°‘пјҢиҝҷжҳҜеӣ дёәиҝҳжҳҜиҰҒеә”з”ЁзЁӢеәҸеҸ‘иө·writeж“ҚдҪңгҖӮ
йӮЈиғҪдёҚиғҪеҮҸе°‘дёҠдёӢж–ҮеҲҮжҚўе‘ў?иҝҷе°ұйңҖиҰҒsendfileж–№ејҸжқҘиҝӣдёҖжӯҘдјҳеҢ–дәҶгҖӮ
sendfile ж–№ејҸ
д»Һ Linux 2.1 зүҲжң¬ејҖе§ӢпјҢLinux еј•е…ҘдәҶ sendfileжқҘз®ҖеҢ–ж“ҚдҪңгҖӮsendfileж–№ејҸеҸҜд»ҘжӣҝжҚўдёҠйқўзҡ„mmap/writeж–№ејҸжқҘиҝӣдёҖжӯҘдјҳеҢ–гҖӮ
sendfileе°Ҷд»ҘдёӢж“ҚдҪңпјҡ
mmap();
write();
жӣҝжҚўдёәпјҡ
sendfile();
иҝҷж ·е°ұеҮҸе°‘дәҶдёҠдёӢж–ҮеҲҮжҚўпјҢеӣ дёәе°‘дәҶдёҖдёӘеә”з”ЁзЁӢеәҸеҸ‘иө·writeж“ҚдҪңпјҢзӣҙжҺҘеҸ‘иө·sendfileж“ҚдҪңгҖӮ
дёӢеӣҫеұ•зӨәдәҶsendfileеҺҹзҗҶпјҡ
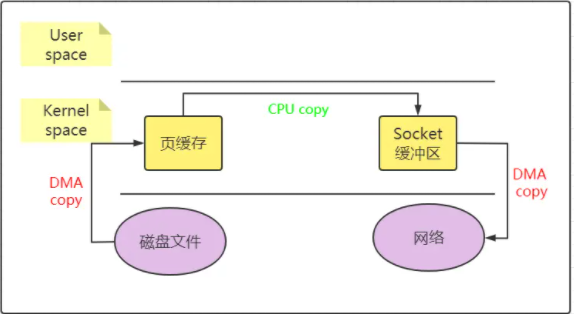
sendfileж–№ејҸеҸӘжңүдёүж¬Ўж•°жҚ®еӨҚеҲ¶пјҲе…¶дёӯеҸӘжңүдёҖж¬Ў CPU COPYпјүд»ҘеҸҠ2ж¬ЎдёҠдёӢж–ҮеҲҮжҚўгҖӮ
йӮЈиғҪдёҚиғҪжҠҠ CPU COPY еҮҸе°‘еҲ°жІЎжңүе‘ўпјҹиҝҷж ·йңҖиҰҒеёҰжңү scatter/gatherзҡ„sendfileж–№ејҸдәҶгҖӮ
еёҰжңү scatter/gather зҡ„ sendfileж–№ејҸ
Linux 2.4 еҶ…ж ёиҝӣиЎҢдәҶдјҳеҢ–пјҢжҸҗдҫӣдәҶеёҰжңү scatter/gather зҡ„ sendfile ж“ҚдҪңпјҢиҝҷдёӘж“ҚдҪңеҸҜд»ҘжҠҠжңҖеҗҺдёҖж¬Ў CPU COPY еҺ»йҷӨгҖӮе…¶еҺҹзҗҶе°ұжҳҜеңЁеҶ…ж ёз©әй—ҙ Read BUffer е’Ң Socket Buffer дёҚеҒҡж•°жҚ®еӨҚеҲ¶пјҢиҖҢжҳҜе°Ҷ Read Buffer зҡ„еҶ…еӯҳең°еқҖгҖҒеҒҸ移йҮҸи®°еҪ•еҲ°зӣёеә”зҡ„ Socket Buffer дёӯпјҢиҝҷж ·е°ұдёҚйңҖиҰҒеӨҚеҲ¶гҖӮе…¶жң¬иҙЁе’ҢиҷҡжӢҹеҶ…еӯҳзҡ„и§ЈеҶіж–№жі•жҖқи·ҜдёҖиҮҙпјҢе°ұжҳҜеҶ…еӯҳең°еқҖзҡ„и®°еҪ•гҖӮ
дёӢеӣҫеұ•зӨәдәҶscatter/gather зҡ„ sendfile зҡ„еҺҹзҗҶпјҡ
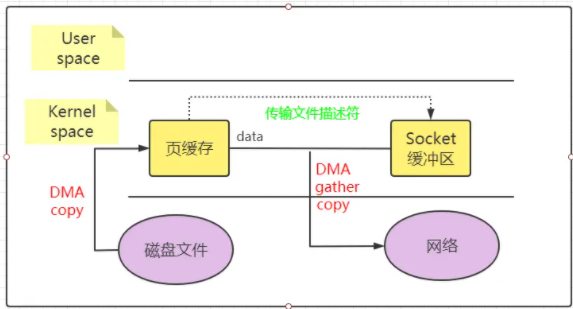
scatter/gather зҡ„ sendfile еҸӘжңүдёӨж¬Ўж•°жҚ®еӨҚеҲ¶пјҲйғҪжҳҜ DMA COPYпјүеҸҠ 2 ж¬ЎдёҠдёӢж–ҮеҲҮжҚўгҖӮCUP COPY е·Із»Ҹе®Ңе…ЁжІЎжңүгҖӮдёҚиҝҮиҝҷдёҖз§Қ收йӣҶеӨҚеҲ¶еҠҹиғҪжҳҜйңҖиҰҒ硬件еҸҠй©ұеҠЁзЁӢеәҸж”ҜжҢҒзҡ„гҖӮ
splice ж–№ејҸ
splice и°ғз”Ёе’Ңsendfile йқһеёёзӣёдјјпјҢз”ЁжҲ·еә”з”ЁзЁӢеәҸеҝ…йЎ»жӢҘжңүдёӨдёӘе·Із»Ҹжү“ејҖзҡ„ж–Ү件жҸҸиҝ°з¬ҰпјҢдёҖдёӘиЎЁзӨәиҫ“е…Ҙи®ҫеӨҮпјҢдёҖдёӘиЎЁзӨәиҫ“еҮәи®ҫеӨҮгҖӮдёҺsendfileдёҚеҗҢзҡ„жҳҜпјҢspliceе…Ғи®ёд»»ж„ҸдёӨдёӘж–Ү件дә’зӣёиҝһжҺҘпјҢиҖҢ并дёҚеҸӘжҳҜж–Ү件дёҺsocketиҝӣиЎҢж•°жҚ®дј иҫ“гҖӮеҜ№дәҺд»ҺдёҖдёӘж–Ү件жҸҸиҝ°з¬ҰеҸ‘йҖҒж•°жҚ®еҲ°socketиҝҷз§Қзү№дҫӢжқҘиҜҙпјҢдёҖзӣҙйғҪжҳҜдҪҝз”Ёsendfileзі»з»ҹи°ғз”ЁпјҢиҖҢspliceдёҖзӣҙд»ҘжқҘе°ұеҸӘжҳҜдёҖз§ҚжңәеҲ¶пјҢе®ғ并дёҚд»…йҷҗдәҺsendfileзҡ„еҠҹиғҪгҖӮд№ҹе°ұжҳҜиҜҙ sendfile жҳҜ splice зҡ„дёҖдёӘеӯҗйӣҶгҖӮ
еңЁ Linux 2.6.17 зүҲжң¬еј•е…ҘдәҶ spliceпјҢиҖҢеңЁ Linux 2.6.23 зүҲжң¬дёӯпјҢ sendfile жңәеҲ¶зҡ„е®һзҺ°е·Із»ҸжІЎжңүдәҶпјҢдҪҶжҳҜе…¶ API еҸҠзӣёеә”зҡ„еҠҹиғҪиҝҳеңЁпјҢеҸӘдёҚиҝҮ API еҸҠзӣёеә”зҡ„еҠҹиғҪжҳҜеҲ©з”ЁдәҶ splice жңәеҲ¶жқҘе®һзҺ°зҡ„гҖӮ
е’Ң sendfile дёҚеҗҢзҡ„жҳҜпјҢsplice дёҚйңҖиҰҒ硬件ж”ҜжҢҒгҖӮ
жҖ»з»“
ж— и®әжҳҜдј з»ҹзҡ„ I/O ж–№ејҸпјҢиҝҳжҳҜеј•е…ҘдәҶйӣ¶жӢ·иҙқд№ӢеҗҺпјҢ2 ж¬Ў DMA copyжҳҜйғҪе°‘дёҚдәҶзҡ„гҖӮеӣ дёәдёӨж¬Ў DMA йғҪжҳҜдҫқиө–硬件е®ҢжҲҗзҡ„гҖӮжүҖд»ҘпјҢжүҖи°“зҡ„йӣ¶жӢ·иҙқпјҢйғҪжҳҜдёәдәҶеҮҸе°‘ CPU copy еҸҠеҮҸе°‘дәҶдёҠдёӢж–Үзҡ„еҲҮжҚўгҖӮ
дёӢеӣҫеұ•зӨәдәҶеҗ„з§Қйӣ¶жӢ·иҙқжҠҖжңҜзҡ„еҜ№жҜ”еӣҫпјҡ
| CPUжӢ·иҙқ | DMAжӢ·иҙқ | зі»з»ҹи°ғз”Ё | дёҠдёӢж–ҮеҲҮжҚў |
|---|
| дј з»ҹж–№жі• | 2 | 2 | read/write | 4 |
| еҶ…еӯҳжҳ е°„ | 1 | 2 | mmap/write | 4 |
| sendfile | 1 | 2 | sendfile | 2 |
| scatter/gather copy | 0 | 2 | sendfile | 2 |
| splice | 0 | 2 | splice | 0 |
вҖңйӣ¶жӢ·иҙқзҡ„еҺҹзҗҶд»ҘеҸҠjavaе®һзҺ°ж–№ејҸвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





