жҖҺд№Ҳз”ЁPython3е®һзҺ°Two-Passз®—жі•
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңжҖҺд№Ҳз”ЁPython3е®һзҺ°Two-Passз®—жі•вҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңжҖҺд№Ҳз”ЁPython3е®һзҺ°Two-Passз®—жі•вҖқеҗ§пјҒ
зӣ®еҪ•
жҠҖжңҜиғҢжҷҜ
Two-Passз®—жі•
жөӢиҜ•ж•°жҚ®зҡ„з”ҹжҲҗ
Two-Passз®—жі•зҡ„е®һзҺ°
з®—жі•зҡ„жү§иЎҢжөҒзЁӢ
ж Үзӯҫзҡ„йҮҚжҳ е°„
е…¶д»–зҡ„жөӢиҜ•з”ЁдҫӢ
жҖ»з»“жҰӮиҰҒ
жҠҖжңҜиғҢжҷҜ
иҝһйҖҡжҖ§жЈҖжөӢжҳҜеӣҫи®әдёӯеёёеёёйҒҮеҲ°зҡ„дёҖдёӘй—®йўҳпјҢжҲ‘们еҸҜд»Ҙз”Ёдә”еӯҗжЈӢзҡ„жҖқи·ҜжқҘзҗҶи§ЈиҝҷдёӘй—®йўҳдә”еӯҗжЈӢдёӯпјҢжЁӘгҖҒз«–гҖҒж–ңзӣёйӮ»зҡ„дёӨдёӘжЈӢеӯҗпјҢиў«и®ӨдёәжҳҜзӣёиҝһжҺҘзҡ„пјҢиҖҢдёҖж ·зҡ„йҒ“зҗҶпјҢеңЁдёҖдёӘдәҢз»ҙзҡ„еӣҫдёӯпјҢеҸӘиҰҒеңЁжЁӘгҖҒз«–гҖҒж–ңдёүдёӘж–№еҗ‘дёӯзҡ„дёҖдёӘеӯҳеңЁзӣёйӮ»зҡ„жғ…еҶөпјҢе°ұеҸҜд»Ҙи®ӨдёәеӣҫдёҠзӣёиҝһйҖҡзҡ„гҖӮжҜ”еҰӮд»ҘдёӢжЎҲдҫӢдёӯзҡ„pythonж•°з»„пјҢ3еҸ·е…ғзҙ е’Ң5еҸ·е…ғзҙ е°ұжҳҜзӣёиҝһжҺҘзҡ„пјҢ5еҸ·е…ғзҙ е’Ң6еҸ·е…ғзҙ д№ҹжҳҜзӣёиҝһжҺҘзҡ„пјҢеӣ жӯӨиҝҷдёүдёӘе…ғзҙ е®һйҷ…дёҠжҳҜеұһдәҺеҗҢдёҖдёӘеҢәеҹҹзҡ„пјҡ
array([[0, 3, 0],
[0, 5, 0],
[6, 0, 0]])
иҖҢеҶҚеҰӮдёӢйқўиҝҷдёӘдҫӢеӯҗпјҢе…¶дёӯзҡ„1гҖҒ2гҖҒ3дёүдёӘе…ғзҙ жҳҜзӣёиҝһзҡ„пјҢ4гҖҒ5гҖҒ6дёүдёӘе…ғзҙ д№ҹжҳҜзӣёиҝһзҡ„пјҢдҪҶжҳҜиҝҷдёӨдёӘеҢәеҹҹдёҚеӯҳеңЁиҝһжҺҘжҖ§пјҢеӣ жӯӨиҝҷдёӘзҪ‘ж јиў«еҲҶжҲҗдәҶдёӨдёӘеҢәеҹҹпјҡ
array([[1, 0, 4],
[2, 0, 5],
[3, 0, 6]])
йӮЈд№ҲеҰӮдҪ•й«ҳж•Ҳзҡ„жЈҖжөӢдёҖеј еӣҫзүҮжҲ–иҖ…дёҖдёӘзҹ©йҳөдёӯзҡ„жүҖжңүиҝһйҖҡеҢәеҹҹ并жү“дёҠж ҮзӯҫпјҢе°ұжҳҜжҲ‘们жүҖе…іжіЁзҡ„дёҖдёӘй—®йўҳгҖӮ
Two-Passз®—жі•
дёҖдёӘе…ёеһӢзҡ„иҝһйҖҡжҖ§жЈҖжөӢзҡ„ж–№жЎҲжҳҜTwo-Passз®—жі•пјҢиҜҘз®—жі•еҸҜд»Ҙз”ЁеҰӮдёӢзҡ„дёҖеј еҠЁжҖҒеӣҫжқҘжј”зӨәпјҡ

иҜҘз®—жі•зҡ„ж ёеҝғеңЁдәҺз”ЁдёӨж¬Ўзҡ„йҒҚеҺҶпјҢдёәжүҖжңүзҡ„иҠӮзӮ№жү“дёҠеҲҶеҢәзҡ„ж ҮзӯҫпјҢеҰӮжһңжҳҜдёҚеҗҢзҡ„еҲҶеҢәпјҢе°ұдјҡжү“дёҠдёҚеҗҢзҡ„ж ҮзӯҫгҖӮе…¶еҹәжң¬зҡ„з®—жі•жӯҘйӘӨеҸҜд»Ҙз”ЁеҰӮдёӢиҜӯиЁҖиҝӣиЎҢжҰӮиҝ°пјҡ
йҒҚеҺҶзҪ‘ж јиҠӮзӮ№пјҢеҰӮжһңзҪ‘ж јзҡ„дёҠгҖҒе·ҰгҖҒе·ҰдёҠдёүдёӘж јзӮ№дёҚеӯҳеңЁе…ғзҙ пјҢеҲҷдёәеҪ“еүҚзҪ‘ж јжү“дёҠж–°зҡ„ж ҮзӯҫпјҢеҗҢж—¶ж Үзӯҫзј–еҸ·еҠ дёҖпјӣ
еҪ“дёҠгҖҒе·ҰгҖҒе·ҰдёҠзҡ„зҪ‘ж јдёӯеӯҳеңЁдёҖдёӘе…ғзҙ ж—¶пјҢе°ҶиҜҘе…ғзҙ еҖјиөӢеҖјз»ҷеҪ“еүҚзҡ„зҪ‘ж јдҪңдёәж Үзӯҫпјӣ
еҪ“дёҠгҖҒе·ҰгҖҒе·ҰдёҠзҡ„зҪ‘ж јдёӯжңүеӨҡдёӘе…ғзҙ ж—¶пјҢеҸ–жңҖдҪҺеҖјдҪңдёәеҪ“еүҚзҪ‘ж јзҡ„ж Үзӯҫпјӣ
еңЁж ҮзӯҫиөӢеҖјж—¶пјҢз•ҷж„Ҹж ҮзӯҫдёҠиҫ№е’Ңе·Ұиҫ№е·Із»Ҹиў«йҒҚеҺҶиҝҮзҡ„4дёӘе…ғзҙ пјҢе°Ҷ4дёӘе…ғзҙ дёӯзҡ„жңҖдҪҺеҖјдёҺиҝҷеӣӣдёӘе…ғзҙ еҲҶеҲ«ж·»еҠ еҲ°Unionзҡ„ж•°жҚ®з»“жһ„дёӯпјҲеҸӮиҖғй“ҫжҺҘ1пјүпјӣ
еҶҚж¬ЎйҒҚеҺҶзҪ‘ж јиҠӮзӮ№пјҢж №жҚ®Unionж•°жҚ®з»“жһ„дёӯзҡ„еҖјеҲ·ж–°зҪ‘ж јдёӯзҡ„ж ҮзӯҫеҖјпјҢжңҖз»Ҳеҫ—еҲ°еҲ’еҲҶеҘҪеҢәеҹҹе’Ңж Үзӯҫзҡ„е…ғзҙ зҹ©йҳөгҖӮ
жөӢиҜ•ж•°жҚ®зҡ„з”ҹжҲҗ
иҝҷйҮҢжҲ‘们д»ҘPython3дёәдҫӢпјҢеҸҜд»Ҙз”ЁNumpyжқҘдә§з”ҹдёҖзі»еҲ—йҡҸжңәзҡ„0-1зҹ©йҳөпјҢиҝҷйҮҢжҲ‘们дә§з”ҹдёҖдёӘ20*20еӨ§е°Ҹзҡ„зҹ©йҳөпјҡ
# two_pass.py
import numpy as np
import matplotlib.pyplot as plt
if __name__ == "__main__":
np.random.seed(1)
graph = np.random.choice([0,1],size=(20,20))
print (graph)
plt.figure()
plt.imshow(graph)
plt.savefig('random_bin_graph.png')жү§иЎҢзҡ„иҫ“еҮәз»“жһңеҰӮдёӢпјҡ
$ python3 two_pass.py
[[1 1 0 0 1 1 1 1 1 0 0 1 0 1 1 0 0 1 0 0]
[0 1 0 0 1 0 0 0 1 0 0 0 1 1 1 1 1 0 0 0]
[1 1 1 1 1 1 0 1 1 0 0 1 0 0 1 1 1 0 1 0]
[0 1 1 0 1 1 1 1 0 0 1 1 0 0 0 0 1 1 1 0]
[1 0 0 1 1 0 1 1 0 1 0 0 1 1 1 0 1 1 0 1]
[1 1 1 0 0 0 0 0 1 1 1 1 1 1 1 0 0 0 0 0]
[0 1 1 1 1 1 1 0 0 1 1 0 0 1 0 0 0 1 1 1]
[1 1 0 1 0 1 0 0 0 1 1 1 0 1 0 0 0 0 1 0]
[1 0 1 1 1 0 0 0 0 0 0 1 0 0 1 0 0 1 1 0]
[0 0 1 0 0 0 0 1 0 0 0 0 1 1 0 0 1 1 1 0]
[0 0 0 0 1 1 1 0 1 1 0 0 0 1 1 0 1 1 1 0]
[1 1 1 1 0 1 0 0 1 0 1 0 1 1 0 1 1 0 1 1]
[1 0 1 0 1 0 1 1 1 1 1 1 0 0 1 1 0 0 0 1]
[1 0 0 0 0 0 1 1 1 1 1 1 1 0 0 1 0 0 0 1]
[0 1 0 1 0 0 0 0 1 1 0 0 0 1 0 1 1 0 0 1]
[0 1 0 0 0 1 0 1 0 1 1 1 0 1 0 1 1 1 1 0]
[0 1 0 0 0 0 1 1 0 1 1 0 0 1 1 1 1 1 1 1]
[0 0 0 0 0 0 0 1 0 0 0 0 0 1 1 1 1 0 0 0]
[1 0 1 0 1 0 0 0 0 0 0 1 0 0 0 1 0 1 1 0]
[0 1 1 0 1 0 1 0 1 1 0 0 1 0 0 0 0 0 1 1]]
еҗҢж—¶дјҡз”ҹжҲҗдёҖеј зҪ‘ж јзҡ„еӣҫзүҮпјҡ
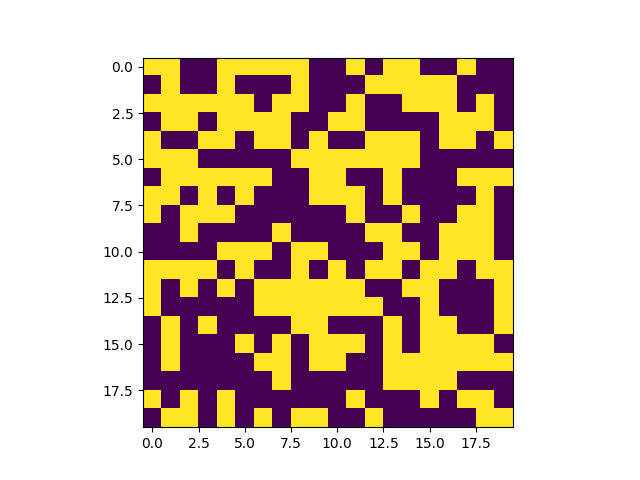
е…¶е®һд»ҺиҝҷдёӘеӣҫзүҮдёӯжҲ‘们еҸҜд»ҘзңӢеҮәпјҢеӣҫзүҮзҡ„дёҠйқўйғЁеҲҶеҮ д№ҺйғҪжҳҜиҝһжҺҘеңЁдёҖиө·зҡ„пјҢеҸӘжңүжңҖдёӢйқўеӯҳеңЁеҮ дёӘзӢ¬з«Ӣзҡ„еҢәеҹҹгҖӮ
Two-Passз®—жі•зҡ„е®һзҺ°
иҝҷйҮҢйңҖиҰҒиҜҙжҳҺзҡ„жҳҜпјҢеӣ дёәжҲ‘们并没жңүдҪҝз”ЁUnionзҡ„ж•°жҚ®з»“жһ„пјҢиҖҢжҳҜеҸӘдҪҝз”ЁдәҶPythonзҡ„еӯ—е…ёж•°жҚ®з»“жһ„пјҢеӣ жӯӨд»Јз ҒеҶҷиө·жқҘдјҡжҜ”иҫғеҶ—дҪҷиҖҢдё”дёҚжҳҜйӮЈд№ҲзҫҺи§ӮпјҢдҪҶжҳҜиҝҷйҮҢжҲ‘们主иҰҒзҡ„зӣ®зҡ„жҳҜе…Ҳз”Ёд»Ји§ЈеҶіиҝҷдёҖе®һйҷ…й—®йўҳпјҢеӣ жӯӨд»Јз Ғд№ұе°ұд№ұдёҖзӮ№еҗ§гҖӮ
# two_pass.py
import numpy as np
import matplotlib.pyplot as plt
from copy import deepcopy
def first_pass(g) -> list:
graph = deepcopy(g)
height = len(graph)
width = len(graph[0])
label = 1
index_dict = {}
for h in range(height):
for w in range(width):
if graph[h][w] == 0:
continue
if h == 0 and w == 0:
graph[h][w] = label
label += 1
continue
if h == 0 and graph[h][w-1] > 0:
graph[h][w] = graph[h][w-1]
continue
if w == 0 and graph[h-1][w] > 0:
if graph[h-1][w] <= graph[h-1][min(w+1, width-1)]:
graph[h][w] = graph[h-1][w]
index_dict[graph[h-1][min(w+1, width-1)]] = graph[h-1][w]
elif graph[h-1][min(w+1, width-1)] > 0:
graph[h][w] = graph[h-1][min(w+1, width-1)]
index_dict[graph[h-1][w]] = graph[h-1][min(w+1, width-1)]
continue
if h == 0 or w == 0:
graph[h][w] = label
label += 1
continue
neighbors = [graph[h-1][w], graph[h][w-1], graph[h-1][w-1], graph[h-1][min(w+1, width-1)]]
neighbors = list(filter(lambda x:x>0, neighbors))
if len(neighbors) > 0:
graph[h][w] = min(neighbors)
for n in neighbors:
if n in index_dict:
index_dict[n] = min(index_dict[n], min(neighbors))
else:
index_dict[n] = min(neighbors)
continue
graph[h][w] = label
label += 1
return graph, index_dict
def remap(idx_dict) -> dict:
index_dict = deepcopy(idx_dict)
for id in idx_dict:
idv = idx_dict[id]
while idv in idx_dict:
if idv == idx_dict[idv]:
break
idv = idx_dict[idv]
index_dict[id] = idv
return index_dict
def second_pass(g, index_dict) -> list:
graph = deepcopy(g)
height = len(graph)
width = len(graph[0])
for h in range(height):
for w in range(width):
if graph[h][w] == 0:
continue
if graph[h][w] in index_dict:
graph[h][w] = index_dict[graph[h][w]]
return graph
def flatten(g) -> list:
graph = deepcopy(g)
fgraph = sorted(set(list(graph.flatten())))
flatten_dict = {}
for i in range(len(fgraph)):
flatten_dict[fgraph[i]] = i
graph = second_pass(graph, flatten_dict)
return graph
if __name__ == "__main__":
np.random.seed(1)
graph = np.random.choice([0,1],size=(20,20))
graph_1, idx_dict = first_pass(graph)
idx_dict = remap(idx_dict)
graph_2 = second_pass(graph_1, idx_dict)
graph_3 = flatten(graph_2)
print (graph_3)
plt.subplot(131)
plt.imshow(graph)
plt.subplot(132)
plt.imshow(graph_3)
plt.subplot(133)
plt.imshow(graph_3>0)
plt.savefig('random_bin_graph.png')е®Ңж•ҙд»Јз Ғзҡ„иҫ“еҮәеҰӮдёӢжүҖзӨәпјҡ
$ python3 two_pass.py
[[1 1 0 0 1 1 1 1 1 0 0 1 0 1 1 0 0 1 0 0]
[0 1 0 0 1 0 0 0 1 0 0 0 1 1 1 1 1 0 0 0]
[1 1 1 1 1 1 0 1 1 0 0 1 0 0 1 1 1 0 1 0]
[0 1 1 0 1 1 1 1 0 0 1 1 0 0 0 0 1 1 1 0]
[1 0 0 1 1 0 1 1 0 1 0 0 1 1 1 0 1 1 0 1]
[1 1 1 0 0 0 0 0 1 1 1 1 1 1 1 0 0 0 0 0]
[0 1 1 1 1 1 1 0 0 1 1 0 0 1 0 0 0 1 1 1]
[1 1 0 1 0 1 0 0 0 1 1 1 0 1 0 0 0 0 1 0]
[1 0 1 1 1 0 0 0 0 0 0 1 0 0 1 0 0 1 1 0]
[0 0 1 0 0 0 0 1 0 0 0 0 1 1 0 0 1 1 1 0]
[0 0 0 0 1 1 1 0 1 1 0 0 0 1 1 0 1 1 1 0]
[1 1 1 1 0 1 0 0 1 0 1 0 1 1 0 1 1 0 1 1]
[1 0 1 0 1 0 1 1 1 1 1 1 0 0 1 1 0 0 0 1]
[1 0 0 0 0 0 1 1 1 1 1 1 1 0 0 1 0 0 0 1]
[0 1 0 2 0 0 0 0 1 1 0 0 0 1 0 1 1 0 0 1]
[0 1 0 0 0 1 0 1 0 1 1 1 0 1 0 1 1 1 1 0]
[0 1 0 0 0 0 1 1 0 1 1 0 0 1 1 1 1 1 1 1]
[0 0 0 0 0 0 0 1 0 0 0 0 0 1 1 1 1 0 0 0]
[3 0 3 0 4 0 0 0 0 0 0 5 0 0 0 1 0 1 1 0]
[0 3 3 0 4 0 6 0 7 7 0 0 5 0 0 0 0 0 1 1]]
еҗҢж ·зҡ„жҲ‘们еҸҜд»ҘзңӢзңӢжӯӨж—¶еҫ—еҲ°зҡ„ж–°зҡ„еӣҫеғҸпјҡ
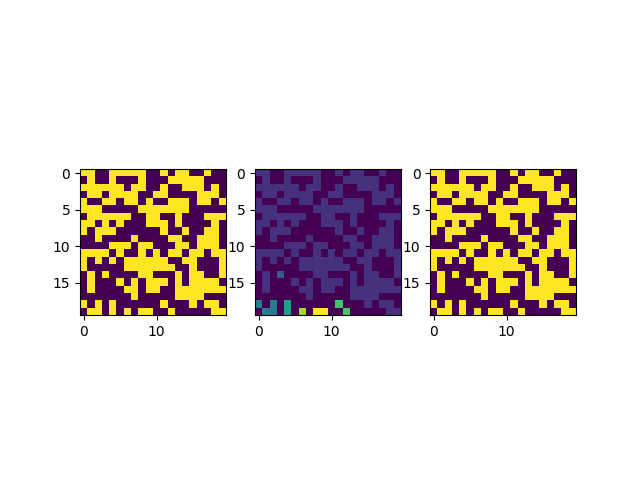
иҝҷйҮҢжҲ‘们并еҲ—зҡ„з”»дәҶдёүеј еӣҫпјҢ第дёҖеј еӣҫжҳҜеҺҹеӣҫпјҢ第дәҢеј еӣҫжҳҜеҲ’еҲҶеҘҪеҢәеҹҹе’Ңж Үзӯҫзҡ„еӣҫпјҢ第дёүеј жҳҜеҜ№з¬¬дәҢеј еӣҫиҝӣиЎҢдәҢе…ғеҢ–зҡ„з»“жһңпјҢд»ҘзЎ®дҝқеңЁиҝҗз®—иҝҮзЁӢдёӯжІЎжңүдёўеӨұеҺҹжң¬зҡ„дҝЎжҒҜгҖӮз»ҸиҝҮзЎ®и®ӨиҝҷдёӘж Үзӯҫзҡ„з»“жһңеҲ’еҲҶжҳҜжӯЈзЎ®зҡ„пјҢдҪҶжҳҜеӣ дёәж¶үеҸҠеҲ°дёҖдәӣз®—жі•е®һзҺ°зҡ„з»ҶиҠӮпјҢиҝҷйҮҢжҲ‘们иҝҳжҳҜйңҖиҰҒеұ•ејҖжқҘд»Ӣз»ҚдёҖдёӢгҖӮ
з®—жі•зҡ„жү§иЎҢжөҒзЁӢ
if __name__ == "__main__":
np.random.seed(1)
graph = np.random.choice([0,1],size=(20,20))
graph_1, idx_dict = first_pass(graph)
idx_dict = remap(idx_dict)
graph_2 = second_pass(graph_1, idx_dict)
graph_3 = flatten(graph_2)
иҝҷдёӘйғЁеҲҶжҳҜз®—жі•зҡ„ж ёеҝғжЎҶжһ¶пјҢеңЁжң¬ж–Үдёӯзҡ„з®—жі•е®һзҺ°жөҒзЁӢдёәпјҡе…Ҳз”Ёfirst_passйҒҚеҺҶдёҖйҒҚзҪ‘ж јиҠӮзӮ№пјҢжҢүз…§дёҠдёҖдёӘз« иҠӮдёӯд»Ӣз»Қзҡ„Two-Passз®—жі•жү“дёҠж ҮзӯҫпјҢ并иҺ·еҫ—дёҖдёӘжҳ е°„е…ізі»пјӣ然еҗҺз”Ёremapе°ҶдёҠйқўеҫ—еҲ°зҡ„жҳ е°„е…ізі»еҒҡдёҖдёӘйҮҚжҳ е°„пјҢзЎ®дҝқжҜҸдёҖдёӘзә§еҲ«зҡ„жҳ е°„йғҪеҜ№еә”еҲ°дәҶжңҖж №йғЁпјҲеҸҜд»ҘиҒ”зі»еҸӮиҖғй“ҫжҺҘ1зҡ„еҶ…е®№иҝӣиЎҢзҗҶи§ЈпјҢиҷҪ然иҝҷйҮҢжІЎжңүдҪҝз”ЁUnionзҡ„ж•°жҚ®з»“жһ„пјҢдҪҶжҳҜжң¬иҙЁдёҠиҝҳжҳҜдёҖдёӘж ‘еҪўзҡ„з»“жһ„пјҢйңҖиҰҒеҒҡдёҖдёӘйҮҚжҳ е°„пјүпјӣ然еҗҺз”Ёsecond_passжү§иЎҢTwo-Passз®—жі•зҡ„第дәҢж¬ЎйҒҚеҺҶпјҢеҫ—еҲ°дёҖз»„жү“дёҠдәҶж–°зҡ„зӢ¬з«Ӣж Үзӯҫзҡ„зҪ‘ж јиҠӮзӮ№пјӣжңҖеҗҺйңҖиҰҒз”Ёflattenе°Ҷж ҮзӯҫиҝӣиЎҢеҺӢе№іпјҢеӣ дёәеүҚйқўжҳ е°„зҡ„е…ізі»пјҢжңүеҸҜиғҪеҜјиҮҙж ҮзӯҫдёҚиҝһз»ӯпјҢжүҖд»ҘжҲ‘们иҝҷйҮҢеҸҲеҒҡдәҶдёҖж¬Ўжҳ е°„пјҢзЎ®дҝқж ҮзӯҫжҳҜиҝһз»ӯеҸҳеҢ–зҡ„пјҢе®һйҷ…еә”з”ЁдёӯеҸҜд»ҘдёҚдҪҝз”ЁиҝҷдёҖжӯҘгҖӮ
ж Үзӯҫзҡ„йҮҚжҳ е°„
е…ідәҺиҠӮзӮ№зҡ„йҒҚеҺҶпјҢеӨ§е®¶еҸҜд»ҘзӣҙжҺҘзңӢз®—жі•д»Јз ҒпјҢиҝҷйҮҢйңҖиҰҒйўқеӨ–и®Іи§Јзҡ„жҳҜж Үзӯҫзҡ„йҮҚжҳ е°„жЁЎеқ—зҡ„д»Јз Ғпјҡ
def remap(idx_dict) -> dict:
index_dict = deepcopy(idx_dict)
for id in idx_dict:
idv = idx_dict[id]
while idv in idx_dict:
if idv == idx_dict[idv]:
break
idv = idx_dict[idv]
index_dict[id] = idv
return index_dict
иҝҷйҮҢзҡ„з®—жі•жҳҜе…ҲеҜ№еҫ—еҲ°зҡ„ж ҮзӯҫиҝӣиЎҢйҒҚеҺҶпјҢеңЁеӯ—е…ёдёӯиҺ·еҸ–еҪ“еүҚж Үзҙўеј•жүҖеҜ№еә”зҡ„еҖјпјҢдҪңдёәж–°зҡ„зҙўеј•пјҢзӣҙеҲ°й”®и·ҹеҖјдёҖиҮҙдёәжӯўпјҢзӣёеҪ“дәҺеңЁдёҖдёӘж ‘еҪўзҡ„ж•°жҚ®з»“жһ„дёӯйҮҚеӨҚеҜ»жүҫзҲ¶иҠӮзӮ№зӣҙеҲ°жүҫеҲ°ж №иҠӮзӮ№гҖӮ
е…¶д»–зҡ„жөӢиҜ•з”ЁдҫӢ
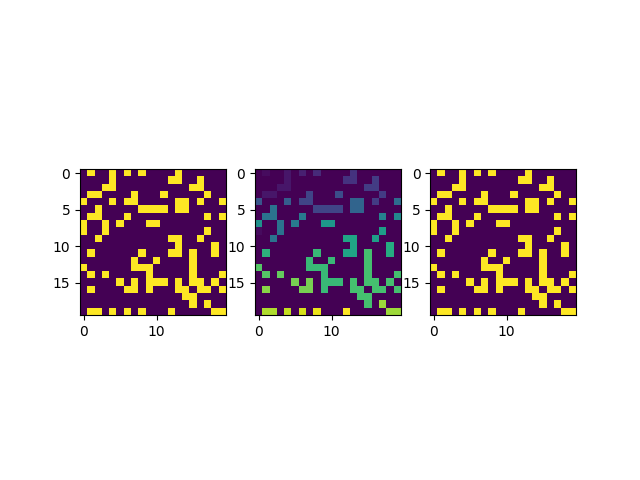
иҝҷйҮҢжҲ‘们еҸҜд»ҘеҶҚйўқеӨ–жөӢиҜ•дёҖдәӣжЎҲдҫӢпјҢжҜ”еҰӮеўһеҠ еҮ дёӘ0е…ғзҙ дҪҝеҫ—зҪ‘ж јиҠӮзӮ№жӣҙеҠ зЁҖз–Ҹпјҡ
graph = np.random.choice([0,0,0,1],size=(20,20))
еҫ—еҲ°зҡ„з»“жһңеӣҫзүҮеҰӮдёӢжүҖзӨәпјҡ
иҝҳеҸҜд»ҘеҶҚзЁҖз–ҸдёҖдәӣпјҡ
graph = np.random.choice([0,0,0,0,0,1],size=(20,20))
еҫ—еҲ°зҡ„з»“жһңеҰӮдёӢеӣҫжүҖзӨәпјҡ
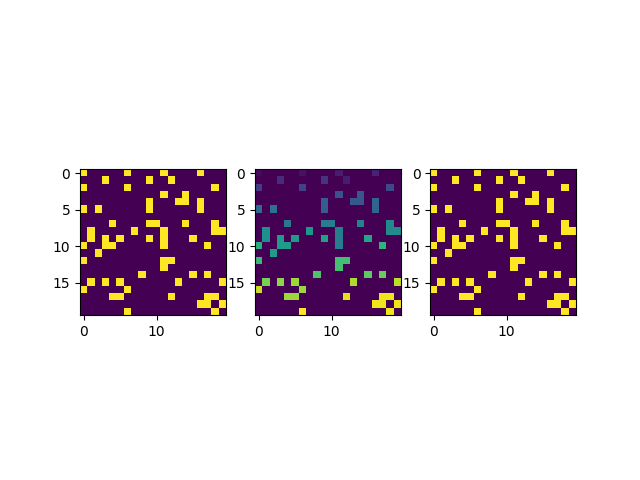
и¶ҠжҳҜзЁҖз–Ҹзҡ„еӣҫпјҢеҫ—еҲ°зҡ„еҲҶз»„з»“жһңе°ұи¶ҠеҲҶж•ЈгҖӮ
жҖ»з»“жҰӮиҰҒ
еңЁжң¬ж–ҮдёӯжҲ‘们主иҰҒд»Ӣз»ҚдәҶеҲ©з”ЁTwo-Passзҡ„з®—жі•жқҘжЈҖжөӢеҢәеҹҹиҝһйҖҡжҖ§пјҢ并з»ҷеҮәдәҶPython3зҡ„д»Јз Ғе®һзҺ°пјҢеҪ“然еңЁе®һзҺ°зҡ„иҝҮзЁӢдёӯеӣ дёәжІЎжңүдҪҝз”ЁеҲ°Unionиҝҷж ·зҡ„ж•°жҚ®з»“жһ„пјҢд»…д»…з”ЁдәҶеӯ—е…ёжқҘеӯҳеӮЁж Үзӯҫд№Ӣй—ҙзҡ„е…ізі»пјҢеӣ жӯӨж•ҲзҺҮе’Ңд»Јз ҒеҸҜиҜ»жҖ§йғҪдјҡдҪҺдёҖдәӣпјҢеҚ•зәҜдҪңдёәз”ЁдҫӢзҡ„жј”зӨәе’Ңе°Ҹ规模еҢәеҹҹеҲ’еҲҶзҡ„и®Ўз®—жҳҜи¶іеӨҹз”ЁдәҶгҖӮеңЁиҜҘд»Јз Ғе®һзҺ°ж–№жЎҲдёӯпјҢиҝҳжңүдёҖзӮ№дёҺеҺҹе§Ӣз®—жі•дёҚдёҖиҮҙзҡ„жҳҜпјҢжң¬е®һзҺ°ж–№жЎҲдёӯжү“ж–°зҡ„ж ҮзӯҫжҳҜиҜ»еҸ–дёҠгҖҒдёҠе·Ұе’Ңе·ҰдёүдёӘж–№еҗ‘зҡ„ж јзӮ№пјҢдҪҶжҳҜеӯҳеӮЁж Үзӯҫзҡ„жҳ е°„е…ізі»ж—¶пјҢжҳҜиҜ»еҸ–дәҶдёҠгҖҒдёҠе·ҰгҖҒдёҠеҸіе’Ңе·ҰиҝҷеӣӣдёӘж–№еҗ‘зҡ„ж јзӮ№гҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңжҖҺд№Ҳз”ЁPython3е®һзҺ°Two-Passз®—жі•вҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№жҖҺд№Ҳз”ЁPython3е®һзҺ°Two-Passз®—жі•иҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ





