这篇文章主要介绍了Node.js Buffer中的encoding的示例分析,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
计算机最小的单位是一个位,也就是 0 和 1,在硬件上通过高低电平来对应。但是只有一位表示的信息太少了,所以又规定了 8 个位为一个字节,之后数字、字符串等各种信息都是基于字节来存储的。
字符怎么存储呢?就是靠编码,不同的字符对应不同的编码,然后在需要渲染的时候根据对应编码去查字体库,然后渲染对应字符的图形。
字符集(charset)最早是 ASCII 码,也就是 abc ABC 123 等 128 个字符,因为计算机最早就是美国发明的。后来欧洲也制定了一套字符集标准,叫做 ISO,后来中国也搞了一套,叫做 GBK。
国际标准化组织觉得不能这样各自搞一套,不然同一个编码在不同字符集里面就不同的意思,于是就提出了 unicode 编码,把全世界大部分编码收录,这样每个字符只有唯一的编码。
但是 ASCII 码只需要 1 个字节就可以存储,而 GBK 需要 2 个字节,还有的字符集需要 3 个字节等,有的只要一个字节存储却存了 2 个字节,比较浪费空间。所以就出现了 utf-8、utf-16、utf-24 等不同编码方案。
utf-8、utf-16、utf-24 都是 unicode 编码,但是具体实现方案不同。
UTF-8 为了节省空间,设计了从 1 到 6 个字节的变长存储方案。而 UTF-16 是固定 2 个字节,UTF-24 是固定 4 个字节。
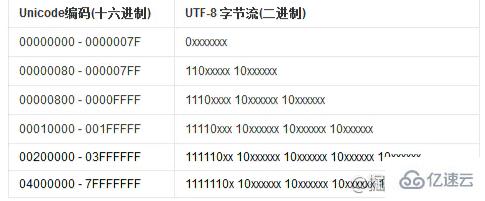
最后,UTF-8 因为占用空间最少,所以被广泛应用。
每种语言都支持字符集的编码解码,Node.js 也同样。
Node.js 里面可以通过 Buffer 来存储二进制的数据,而二进制的数据转为字符串的时候就需要指定字符集,Buffer 的 from、byteLength、lastIndexOf 等方法都支持指定 encoding:
具体支持的 encoding 有这些:
utf8、ucs2、utf16le、latin1、ascii、base64、hex
可能有的同学会发现: base64、hex 不是字符集啊,怎么也出现在这里?
是的,字节到字符的编码方案除了字符集之外,也有用于转为明文字符的 base64、以及转为 16 进制的 hex。
这也是为什么 Node.js 把它叫做 encoding 而不是 charset,因为支持的编解码方案不只是字符集。
如果不指定 encoding,默认是 utf8。
const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
console.log(buf.toString());// hello world我去翻了下 Node.js 关于 encoding 的源码:
这一段是实现 encoding 的:https://github.com/nodejs/node/blob/master/lib/buffer.js#L587-L726
可以看到每个 encoding 都实现了 encoding、encodingVal、byteLength、write、slice、indexOf 这几个 api,因为这些 api 用不同 encoding 方案,会有不同的结果,Node.js 会根据传入的 encoding 来返回不同的对象,这是一种多态的思想。
const encodingOps = {
utf8: {
encoding: 'utf8',
encodingVal: encodingsMap.utf8,
byteLength: byteLengthUtf8,
write: (buf, string, offset, len) => buf.utf8Write(string, offset, len),
slice: (buf, start, end) => buf.utf8Slice(start, end),
indexOf: (buf, val, byteOffset, dir) =>
indexOfString(buf, val, byteOffset, encodingsMap.utf8, dir)
},
ucs2: {
encoding: 'ucs2',
encodingVal: encodingsMap.utf16le,
byteLength: (string) => string.length * 2,
write: (buf, string, offset, len) => buf.ucs2Write(string, offset, len),
slice: (buf, start, end) => buf.ucs2Slice(start, end),
indexOf: (buf, val, byteOffset, dir) =>
indexOfString(buf, val, byteOffset, encodingsMap.utf16le, dir)
},
utf16le: {
encoding: 'utf16le',
encodingVal: encodingsMap.utf16le,
byteLength: (string) => string.length * 2,
write: (buf, string, offset, len) => buf.ucs2Write(string, offset, len),
slice: (buf, start, end) => buf.ucs2Slice(start, end),
indexOf: (buf, val, byteOffset, dir) =>
indexOfString(buf, val, byteOffset, encodingsMap.utf16le, dir)
},
latin1: {
encoding: 'latin1',
encodingVal: encodingsMap.latin1,
byteLength: (string) => string.length,
write: (buf, string, offset, len) => buf.latin1Write(string, offset, len),
slice: (buf, start, end) => buf.latin1Slice(start, end),
indexOf: (buf, val, byteOffset, dir) =>
indexOfString(buf, val, byteOffset, encodingsMap.latin1, dir)
},
ascii: {
encoding: 'ascii',
encodingVal: encodingsMap.ascii,
byteLength: (string) => string.length,
write: (buf, string, offset, len) => buf.asciiWrite(string, offset, len),
slice: (buf, start, end) => buf.asciiSlice(start, end),
indexOf: (buf, val, byteOffset, dir) =>
indexOfBuffer(buf,
fromStringFast(val, encodingOps.ascii),
byteOffset,
encodingsMap.ascii,
dir)
},
base64: {
encoding: 'base64',
encodingVal: encodingsMap.base64,
byteLength: (string) => base64ByteLength(string, string.length),
write: (buf, string, offset, len) => buf.base64Write(string, offset, len),
slice: (buf, start, end) => buf.base64Slice(start, end),
indexOf: (buf, val, byteOffset, dir) =>
indexOfBuffer(buf,
fromStringFast(val, encodingOps.base64),
byteOffset,
encodingsMap.base64,
dir)
},
hex: {
encoding: 'hex',
encodingVal: encodingsMap.hex,
byteLength: (string) => string.length >>> 1,
write: (buf, string, offset, len) => buf.hexWrite(string, offset, len),
slice: (buf, start, end) => buf.hexSlice(start, end),
indexOf: (buf, val, byteOffset, dir) =>
indexOfBuffer(buf,
fromStringFast(val, encodingOps.hex),
byteOffset,
encodingsMap.hex,
dir)
}
};
function getEncodingOps(encoding) {
encoding += '';
switch (encoding.length) {
case 4:
if (encoding === 'utf8') return encodingOps.utf8;
if (encoding === 'ucs2') return encodingOps.ucs2;
encoding = StringPrototypeToLowerCase(encoding);
if (encoding === 'utf8') return encodingOps.utf8;
if (encoding === 'ucs2') return encodingOps.ucs2;
break;
case 5:
if (encoding === 'utf-8') return encodingOps.utf8;
if (encoding === 'ascii') return encodingOps.ascii;
if (encoding === 'ucs-2') return encodingOps.ucs2;
encoding = StringPrototypeToLowerCase(encoding);
if (encoding === 'utf-8') return encodingOps.utf8;
if (encoding === 'ascii') return encodingOps.ascii;
if (encoding === 'ucs-2') return encodingOps.ucs2;
break;
case 7:
if (encoding === 'utf16le' ||
StringPrototypeToLowerCase(encoding) === 'utf16le')
return encodingOps.utf16le;
break;
case 8:
if (encoding === 'utf-16le' ||
StringPrototypeToLowerCase(encoding) === 'utf-16le')
return encodingOps.utf16le;
break;
case 6:
if (encoding === 'latin1' || encoding === 'binary')
return encodingOps.latin1;
if (encoding === 'base64') return encodingOps.base64;
encoding = StringPrototypeToLowerCase(encoding);
if (encoding === 'latin1' || encoding === 'binary')
return encodingOps.latin1;
if (encoding === 'base64') return encodingOps.base64;
break;
case 3:
if (encoding === 'hex' || StringPrototypeToLowerCase(encoding) === 'hex')
return encodingOps.hex;
break;
}
}感谢你能够认真阅读完这篇文章,希望小编分享的“Node.js Buffer中的encoding的示例分析”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



