C++дёӯдҪҚеӣҫе’ҢеёғйҡҶиҝҮж»ӨеҷЁзҡ„зӨәдҫӢеҲҶжһҗ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶC++дёӯдҪҚеӣҫе’ҢеёғйҡҶиҝҮж»ӨеҷЁзҡ„зӨәдҫӢеҲҶжһҗпјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« д№ӢеҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©е°Ҹзј–еёҰзқҖеӨ§е®¶дёҖиө·дәҶи§ЈдёҖдёӢгҖӮ
C++е“ҲеёҢеә”з”Ёзҡ„дҪҚеӣҫе’ҢеёғйҡҶиҝҮж»ӨеҷЁ
дёҖгҖҒдҪҚеӣҫ
1.дҪҚеӣҫзҡ„жҰӮеҝө
жүҖи°“дҪҚеӣҫпјҢе°ұжҳҜз”ЁжҜҸдёҖдҪҚжқҘеӯҳж”ҫжҹҗз§ҚзҠ¶жҖҒпјҢйҖӮз”ЁдәҺжө·йҮҸж•°жҚ®пјҢж•°жҚ®ж— йҮҚеӨҚзҡ„еңәжҷҜгҖӮйҖҡеёёжҳҜз”ЁжқҘеҲӨж–ӯжҹҗдёӘж•°жҚ®еӯҳдёҚеӯҳеңЁзҡ„гҖӮ
2.дҪҚеӣҫзҡ„йқўиҜ•йўҳ
з»ҷ40дәҝдёӘдёҚйҮҚеӨҚзҡ„ж— з¬ҰеҸ·ж•ҙж•°пјҢжІЎжҺ’иҝҮеәҸгҖӮз»ҷдёҖдёӘж— з¬ҰеҸ·ж•ҙж•°пјҢеҰӮдҪ•еҝ«йҖҹеҲӨж–ӯдёҖдёӘж•°жҳҜеҗҰеңЁиҝҷ40дәҝдёӘж•°дёӯгҖӮгҖҗи…ҫи®ҜгҖ‘
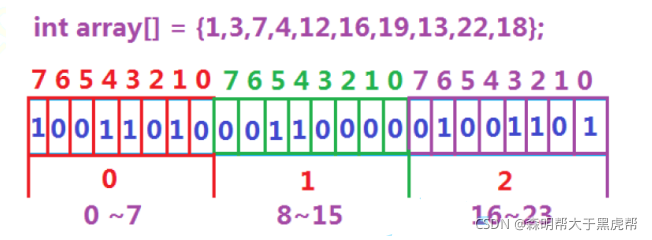
ж•°жҚ®жҳҜеҗҰеңЁз»ҷе®ҡзҡ„ж•ҙеҪўж•°жҚ®дёӯпјҢз»“жһңжҳҜеңЁжҲ–иҖ…дёҚеңЁпјҢеҲҡеҘҪжҳҜдёӨз§ҚзҠ¶жҖҒпјҢйӮЈд№ҲеҸҜд»ҘдҪҝз”ЁдёҖдёӘдәҢиҝӣеҲ¶жҜ”зү№дҪҚжқҘд»ЈиЎЁж•°жҚ®жҳҜеҗҰеӯҳеңЁзҡ„дҝЎжҒҜпјҢеҰӮжһңдәҢиҝӣеҲ¶жҜ”зү№дҪҚдёә1пјҢд»ЈиЎЁеӯҳеңЁпјҢдёә0д»ЈиЎЁдёҚеӯҳеңЁгҖӮжҜ”еҰӮпјҡ
3.дҪҚеӣҫзҡ„е®һзҺ°
#include<iostream>
#include<vector>
#include<math.h>
namespace yyw
{
class bitset
{
public:
bitset(size_t N)
{
_bits.resize(N / 32 + 1, 0);
_num = 0;
}
//е°ҶxдҪҚзҡ„жҜ”зү№дҪҚи®ҫзҪ®дёә1
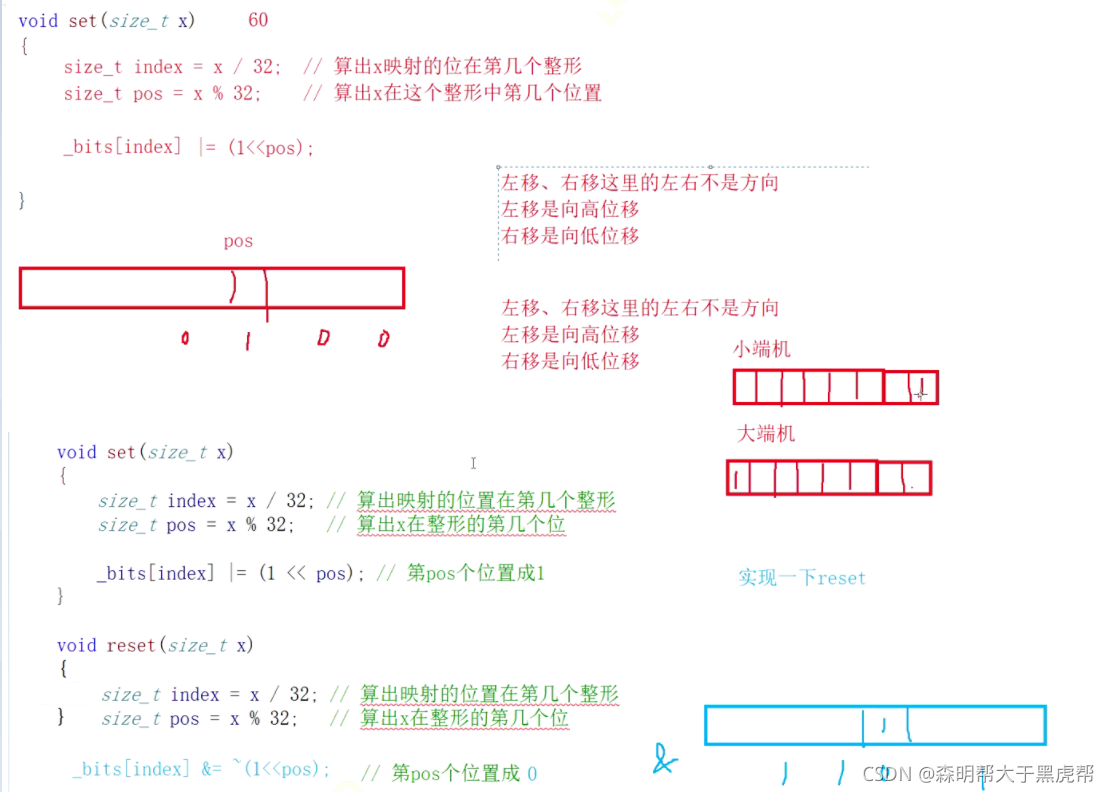
void set(size_t x)
{
size_t index = x / 32; //жҳ е°„еҮәxеңЁз¬¬еҮ дёӘж•ҙеҪў
size_t pos = x % 32; //жҳ е°„еҮәxеңЁж•ҙеҪўзҡ„第еҮ дёӘдҪҚзҪ®
_bits[index] |= (1 << pos);
_num++;
}
//е°ҶxдҪҚзҡ„жҜ”зү№дҪҚи®ҫзҪ®дёә0
void reset(size_t x)
{
size_t index = x / 32;
size_t pos = x % 32;
_bits[index] &= ~(1 << pos);
_num--;
}
//еҲӨж–ӯxдҪҚжҳҜеҗҰеңЁдёҚеңЁ
bool test(size_t x)
{
size_t index = x / 32;
size_t pos = x % 32;
return _bits[index] & (1 << pos);
}
//дҪҚеӣҫдёӯжҜ”зү№дҪҚзҡ„жҖ»дёӘж•°
size_t size()
{
return _num;
}
private:
std::vector<int> _bits;
size_t _num; //жҳ е°„еӯҳеӮЁдәҶеӨҡе°‘дёӘж•°жҚ®
};
void tes_bitset()
{
bitset bs(100);
bs.set(99);
bs.set(98);
bs.set(97);
bs.set(10);
for (size_t i = 0; i < 100; i++)
{
printf("[%d]:%d\n", i, bs.test(i));
}
//40дәҝдёӘж•°жҚ®пјҢеҲӨж–ӯжҹҗдёӘж•°жҳҜеҗҰеңЁж•°жҚ®дёӯ
//bs.reset(-1);
//bs.reset(pow(2, 32));
}
}4.дҪҚеӣҫзҡ„еә”з”Ё
еҝ«йҖҹжҹҘжүҫжҹҗдёӘж•ҙеҪўж•°жҚ®жҳҜеҗҰеңЁдёҖдёӘйӣҶеҗҲдёӯгҖӮ
жҺ’еәҸгҖӮ
жұӮдёӨдёӘйӣҶеҗҲзҡ„дәӨйӣҶгҖҒ并йӣҶзӯүгҖӮ
ж“ҚдҪңзі»з»ҹдёӯзЈҒзӣҳеқ—ж Үи®°гҖӮ
дәҢгҖҒеёғйҡҶиҝҮж»ӨеҷЁ
1.еёғйҡҶиҝҮж»ӨеҷЁзҡ„жҸҗеҮә
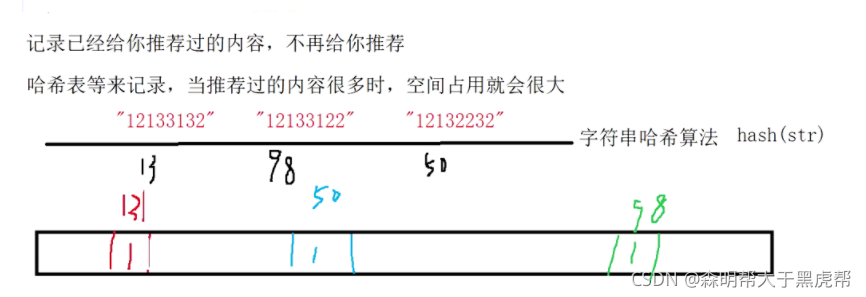
жҲ‘们еңЁдҪҝз”Ёж–°й—»е®ўжҲ·з«ҜзңӢж–°й—»ж—¶пјҢе®ғдјҡз»ҷжҲ‘们дёҚеҒңең°жҺЁиҚҗж–°зҡ„еҶ…е®№пјҢе®ғжҜҸж¬ЎжҺЁиҚҗж—¶иҰҒеҺ»йҮҚпјҢеҺ»жҺүйӮЈдәӣе·Із»ҸзңӢиҝҮзҡ„еҶ…е®№гҖӮй—®йўҳжқҘдәҶпјҢж–°й—»е®ўжҲ·з«ҜжҺЁиҚҗзі»з»ҹеҰӮдҪ•е®һзҺ°жҺЁйҖҒеҺ»йҮҚзҡ„пјҹ з”ЁжңҚеҠЎеҷЁи®°еҪ•дәҶз”ЁжҲ·зңӢиҝҮзҡ„жүҖжңүеҺҶеҸІи®°еҪ•пјҢеҪ“жҺЁиҚҗзі»з»ҹжҺЁиҚҗж–°й—»ж—¶дјҡд»ҺжҜҸдёӘз”ЁжҲ·зҡ„еҺҶеҸІи®°еҪ•йҮҢиҝӣиЎҢзӯӣйҖүпјҢиҝҮж»ӨжҺүйӮЈдәӣе·Із»ҸеӯҳеңЁзҡ„и®°еҪ•гҖӮ еҰӮдҪ•еҝ«йҖҹжҹҘжүҫе‘ўпјҹ
з”Ёе“ҲеёҢиЎЁеӯҳеӮЁз”ЁжҲ·и®°еҪ•пјҢзјәзӮ№пјҡжөӘиҙ№з©әй—ҙгҖӮ
з”ЁдҪҚеӣҫеӯҳеӮЁз”ЁжҲ·и®°еҪ•пјҢзјәзӮ№пјҡдёҚиғҪеӨ„зҗҶе“ҲеёҢеҶІзӘҒгҖӮ
е°Ҷе“ҲеёҢдёҺдҪҚеӣҫз»“еҗҲпјҢеҚіеёғйҡҶиҝҮж»ӨеҷЁгҖӮ
2.еёғйҡҶиҝҮж»ӨеҷЁзҡ„жҰӮеҝө
еёғйҡҶиҝҮж»ӨеҷЁжҳҜз”ұеёғйҡҶпјҲBurton Howard BloomпјүеңЁ1970е№ҙжҸҗеҮәзҡ„ дёҖз§Қзҙ§еҮ‘еһӢзҡ„гҖҒжҜ”иҫғе·§еҰҷзҡ„жҰӮзҺҮеһӢж•°жҚ®з»“жһ„пјҢзү№зӮ№жҳҜй«ҳж•Ҳең°жҸ’е…Ҙе’ҢжҹҘиҜўпјҢеҸҜд»Ҙз”ЁжқҘе‘ҠиҜүдҪ вҖңжҹҗж ·дёңиҘҝдёҖе®ҡдёҚеӯҳеңЁжҲ–иҖ…еҸҜиғҪеӯҳеңЁвҖқпјҢе®ғжҳҜз”ЁеӨҡдёӘе“ҲеёҢеҮҪж•°пјҢе°ҶдёҖдёӘж•°жҚ®жҳ е°„еҲ°дҪҚеӣҫз»“жһ„дёӯгҖӮжӯӨз§Қж–№ејҸдёҚд»…еҸҜд»ҘжҸҗеҚҮжҹҘиҜўж•ҲзҺҮпјҢд№ҹеҸҜд»ҘиҠӮзңҒеӨ§йҮҸзҡ„еҶ…еӯҳз©әй—ҙгҖӮ
3.еёғйҡҶиҝҮж»ӨеҷЁзҡ„жҸ’е…Ҙ
еёғйҡҶиҝҮж»ӨеҷЁеә•еұӮжҳҜдҪҚеӣҫпјҡ
struct HashStr1
{
//BKDR1
size_t operator()(const std::string& str)
{
size_t hash = 0;
for (size_t i = 0; i < str.size(); i++)
{
hash *= 131;
hash += str[i];
}
return hash;
}
};
struct HashStr2
{
//RSHash
size_t operator()(const std::string& str)
{
size_t hash = 0;
size_t magic = 63689; //йӯ”ж•°
for (size_t i = 0; i < str.size();i++)
{
hash *= magic;
hash += str[i];
magic *= 378551;
}
return hash;
}
};
struct HashStr3
{
//SDBHash
size_t operator()(const std::string& str)
{
size_t hash = 0;
for (size_t i = 0; i < str.size(); i++)
{
hash *= 65599;
hash += str[i];
}
return hash;
}
};
//еҒҮи®ҫеёғйҡҶиҝҮж»ӨеҷЁе…ғзҙ зұ»еһӢдёәKпјҢеҰӮжһңзұ»еһӢдёәKиҰҒиҮӘе·ұй…ҚзҪ®д»ҝеҮҪж•°
template<class K,class Hash2=HashStr1,class Hash3=HashStr2,class Hash4=HashStr3>
class bloomfilter
{
public:
bloomfilter(size_t num)
:_bs(5*num)
, _N(5*num)
{
}
void set(const K& key)
{
size_t index1 = Hash2()(key) % _N;
size_t index2 = Hash3()(key) % _N;
size_t index3 = Hash4()(key) % _N;
_bs.set(index1); //дёүдёӘдҪҚзҪ®йғҪи®ҫзҪ®дёә1
_bs.set(index2);
_bs.set(index3);
}
}4.еёғйҡҶиҝҮж»ӨеҷЁзҡ„жҹҘжүҫ
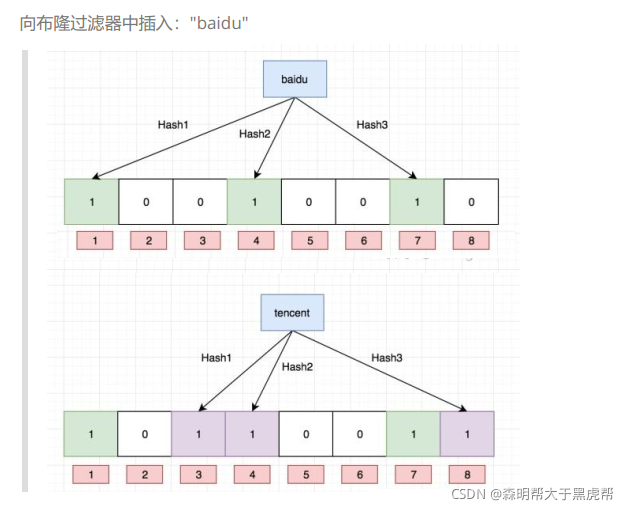
еёғйҡҶиҝҮж»ӨеҷЁзҡ„жҖқжғіжҳҜе°ҶдёҖдёӘе…ғзҙ з”ЁеӨҡдёӘе“ҲеёҢеҮҪж•°жҳ е°„еҲ°дёҖдёӘдҪҚеӣҫдёӯпјҢеӣ жӯӨиў«жҳ е°„еҲ°зҡ„дҪҚзҪ®зҡ„жҜ”зү№дҪҚдёҖе®ҡдёә1гҖӮжүҖд»ҘеҸҜд»ҘжҢүз…§д»ҘдёӢж–№ејҸиҝӣиЎҢжҹҘжүҫпјҡеҲҶеҲ«и®Ўз®—жҜҸдёӘе“ҲеёҢеҖјеҜ№еә”зҡ„жҜ”зү№дҪҚзҪ®еӯҳеӮЁзҡ„жҳҜеҗҰдёәйӣ¶пјҢеҸӘиҰҒжңүдёҖдёӘдёәйӣ¶пјҢд»ЈиЎЁиҜҘе…ғзҙ дёҖе®ҡдёҚеңЁе“ҲеёҢиЎЁдёӯпјҢеҗҰеҲҷеҸҜиғҪеңЁе“ҲеёҢиЎЁдёӯгҖӮ
bool test(const K& key)
{
size_t index1 = Hash2()(key) % _N;
if (_bs.test(index1) == false)
{
return false;
}
size_t index2 = Hash2()(key) % _N;
if (_bs.test(index2) == false)
{
return false;
}
size_t index3 = Hash4()(key) % _N;
if (_bs.test(index3) == false)
{
return false;
}
return true; //дҪҶжҳҜиҝҷйҮҢд№ҹдёҚдёҖе®ҡжҳҜзңҹзҡ„еңЁпјҢиҝҳжңүеҸҜиғҪеӯҳеңЁиҜҜеҲӨ
//еҲӨж–ӯдёҚеңЁжҳҜжӯЈзЎ®зҡ„пјҢеҲӨж–ӯеңЁеҸҜиғҪеӯҳеңЁиҜҜеҲӨ
}жіЁж„ҸпјҡеёғйҡҶиҝҮж»ӨеҷЁеҰӮжһңиҜҙжҹҗдёӘе…ғзҙ дёҚеӯҳеңЁж—¶пјҢиҜҘе…ғзҙ дёҖе®ҡдёҚеӯҳеңЁпјҢеҰӮжһңиҜҘе…ғзҙ еӯҳеңЁж—¶пјҢиҜҘе…ғзҙ еҸҜиғҪеӯҳеңЁпјҢеӣ дёәжңүдәӣе“ҲеёҢеҮҪж•°еӯҳеңЁдёҖе®ҡзҡ„иҜҜеҲӨгҖӮ
жҜ”еҰӮпјҡеңЁеёғйҡҶиҝҮж»ӨеҷЁдёӯжҹҘжүҫ"alibaba"ж—¶пјҢеҒҮи®ҫ3дёӘе“ҲеёҢеҮҪж•°и®Ўз®—зҡ„е“ҲеёҢеҖјдёәпјҡ1гҖҒ3гҖҒ7пјҢеҲҡеҘҪе’Ңе…¶д»–е…ғзҙ зҡ„жҜ”зү№дҪҚйҮҚеҸ пјҢжӯӨж—¶еёғйҡҶиҝҮж»ӨеҷЁе‘ҠиҜүиҜҘе…ғзҙ еӯҳеңЁпјҢдҪҶе®һиҜҘе…ғзҙ жҳҜдёҚеӯҳеңЁзҡ„гҖӮ
5.еёғйҡҶиҝҮж»ӨеҷЁзҡ„еҲ йҷӨ
еёғйҡҶиҝҮж»ӨеҷЁдёҚиғҪзӣҙжҺҘж”ҜжҢҒеҲ йҷӨе·ҘдҪңпјҢеӣ дёәеңЁеҲ йҷӨдёҖдёӘе…ғзҙ ж—¶пјҢеҸҜиғҪдјҡеҪұе“Қе…¶д»–е…ғзҙ гҖӮ
жҜ”еҰӮпјҡеҲ йҷӨдёҠеӣҫдёӯ"tencent"е…ғзҙ пјҢеҰӮжһңзӣҙжҺҘе°ҶиҜҘе…ғзҙ жүҖеҜ№еә”зҡ„дәҢиҝӣеҲ¶жҜ”зү№дҪҚзҪ®0пјҢвҖңbaiduвҖқе…ғзҙ д№ҹиў«еҲ йҷӨдәҶпјҢеӣ дёәиҝҷдёӨдёӘе…ғзҙ еңЁеӨҡдёӘе“ҲеёҢеҮҪж•°и®Ўз®—еҮәзҡ„жҜ”зү№дҪҚдёҠеҲҡеҘҪжңүйҮҚеҸ гҖӮ

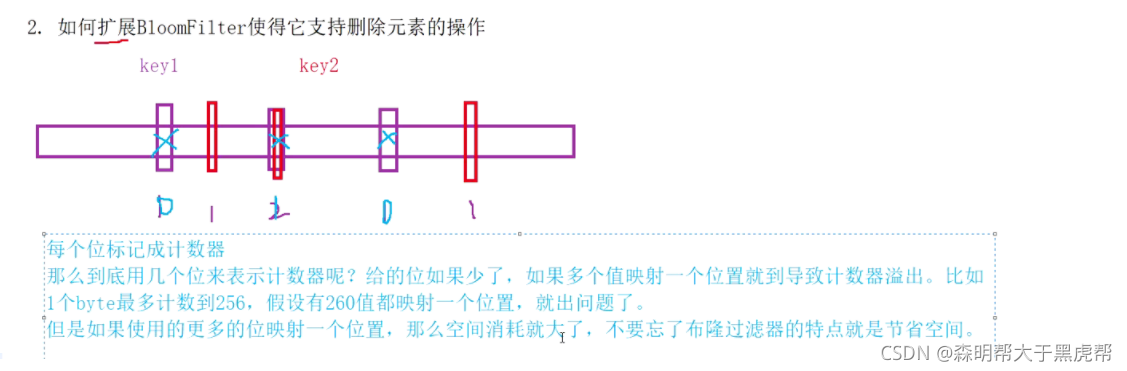
дёҖз§Қж”ҜжҢҒеҲ йҷӨзҡ„ж–№жі•пјҡе°ҶеёғйҡҶиҝҮж»ӨеҷЁдёӯзҡ„жҜҸдёӘжҜ”зү№дҪҚжү©еұ•жҲҗдёҖдёӘе°Ҹзҡ„и®Ўж•°еҷЁпјҢжҸ’е…Ҙе…ғзҙ ж—¶з»ҷkдёӘи®Ўж•°еҷЁ(kдёӘе“ҲеёҢеҮҪж•°и®Ўз®—еҮәзҡ„е“ҲеёҢең°еқҖ)еҠ дёҖпјҢеҲ йҷӨе…ғзҙ ж—¶пјҢз»ҷkдёӘи®Ўж•°еҷЁеҮҸдёҖпјҢйҖҡиҝҮеӨҡеҚ з”ЁеҮ еҖҚеӯҳеӮЁз©әй—ҙзҡ„д»Јд»·жқҘеўһеҠ еҲ йҷӨж“ҚдҪңгҖӮ
зјәйҷ·пјҡ
6.еёғйҡҶиҝҮж»ӨеҷЁзҡ„дјҳзӮ№е’ҢзјәзӮ№
дҪҚеӣҫ
дёүгҖҒжө·йҮҸж•°жҚ®йқўиҜ•йўҳ
1.е“ҲеёҢеҲҮеүІ
в‘ з»ҷдёҖдёӘи¶…иҝҮ100GеӨ§е°Ҹзҡ„log file, logдёӯеӯҳзқҖIPең°еқҖ, и®ҫи®Ўз®—жі•жүҫеҲ°еҮәзҺ°ж¬Ўж•°жңҖеӨҡзҡ„IPең°еқҖпјҹ дёҺдёҠйўҳжқЎд»¶зӣёеҗҢпјҢеҰӮдҪ•жүҫеҲ°top Kзҡ„IPпјҹеҰӮдҪ•зӣҙжҺҘз”ЁLinuxзі»з»ҹе‘Ҫд»Өе®һзҺ°пјҹ
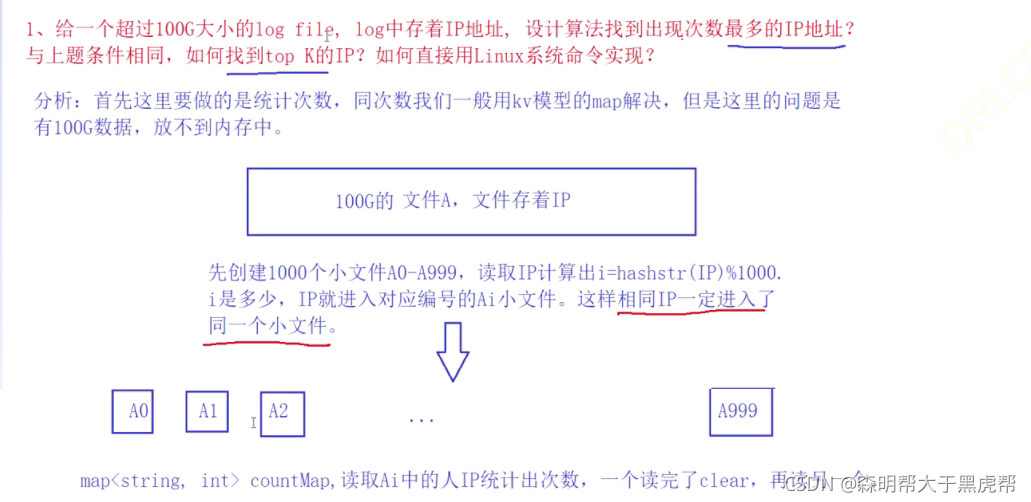
2.дҪҚеӣҫеә”з”Ё
в‘ з»ҷе®ҡ100дәҝдёӘж•ҙж•°пјҢи®ҫи®Ўз®—жі•жүҫеҲ°еҸӘеҮәзҺ°дёҖж¬Ўзҡ„ж•ҙж•°пјҹ

в‘Ўз»ҷдёӨдёӘж–Ү件пјҢеҲҶеҲ«жңү100дәҝдёӘж•ҙж•°пјҢжҲ‘们еҸӘжңү1GеҶ…еӯҳпјҢеҰӮдҪ•жүҫеҲ°дёӨдёӘж–Ү件дәӨйӣҶпјҹ
ж–№жЎҲ1:е°Ҷе…¶дёӯдёҖдёӘж–Ү件1зҡ„ж•ҙж•°жҳ е°„еҲ°дёҖдёӘдҪҚеӣҫдёӯпјҢиҜ»еҸ–еҸҰеӨ–дёҖдёӘж–Ү件2дёӯзҡ„ж•ҙж•°пјҢеҲӨж–ӯеңЁеңЁдёҚеңЁдҪҚеӣҫпјҢеңЁе°ұжҳҜдәӨйӣҶгҖӮж¶ҲиҖ—50OMеҶ…еӯҳ
ж–№жЎҲ2:е°Ҷж–Ү件1зҡ„ж•ҙж•°жҳ е°„еҲ°дҪҚеӣҫ1дёӯпјҢе°Ҷж–Ү件2зҡ„ж•ҙж•°жҳ е°„еҲ°дҪҚеӣҫ2дёӯпјҢ然еҗҺе°ҶдёӨдёӘдҪҚеӣҫдёӯзҡ„ж•°жҢүдҪҚдёҺгҖӮдёҺд№ӢеҗҺдёәl1зҡ„дҪҚе°ұжҳҜдәӨйӣҶгҖӮж¶ҲиҖ—еҶ…еӯҳ1GгҖӮ
в‘ўдҪҚеӣҫеә”з”ЁеҸҳеҪўпјҡ1дёӘж–Ү件жңү100дәҝдёӘintпјҢ1GеҶ…еӯҳпјҢи®ҫи®Ўз®—жі•жүҫеҲ°еҮәзҺ°ж¬Ўж•°дёҚи¶…иҝҮ2ж¬Ўзҡ„жүҖжңүж•ҙж•°пјҹ
жң¬йўҳи·ҹдёҠйқўзҡ„第1йўҳжҖқи·ҜжҳҜдёҖж ·зҡ„
жң¬йўҳжүҫзҡ„дёҚи¶…иҝҮ2ж¬Ўзҡ„пјҢд№ҹе°ұжҳҜиҰҒжүҫеҮәзҺ°1ж¬Ўе’Ң2ж¬Ўзҡ„
жң¬йўҳиҝҳжҳҜз”ЁдёӨдёӘдҪҚиЎЁзӨәдёҖдёӘж•°пјҢеҲҶдёәеҮәзҺ°0ж¬Ў00иЎЁзӨәпјҢеҮәзҺ°1ж¬Ўзҡ„01иЎЁзӨәвҖ•еҮәзҺ°2ж¬Ўзҡ„10иЎЁзӨәеҮәзҺ°3ж¬ЎеҸҠ3ж¬Ўд»ҘдёҠзҡ„з”Ё11иЎЁзӨә
3.еёғйҡҶиҝҮж»ӨеҷЁ
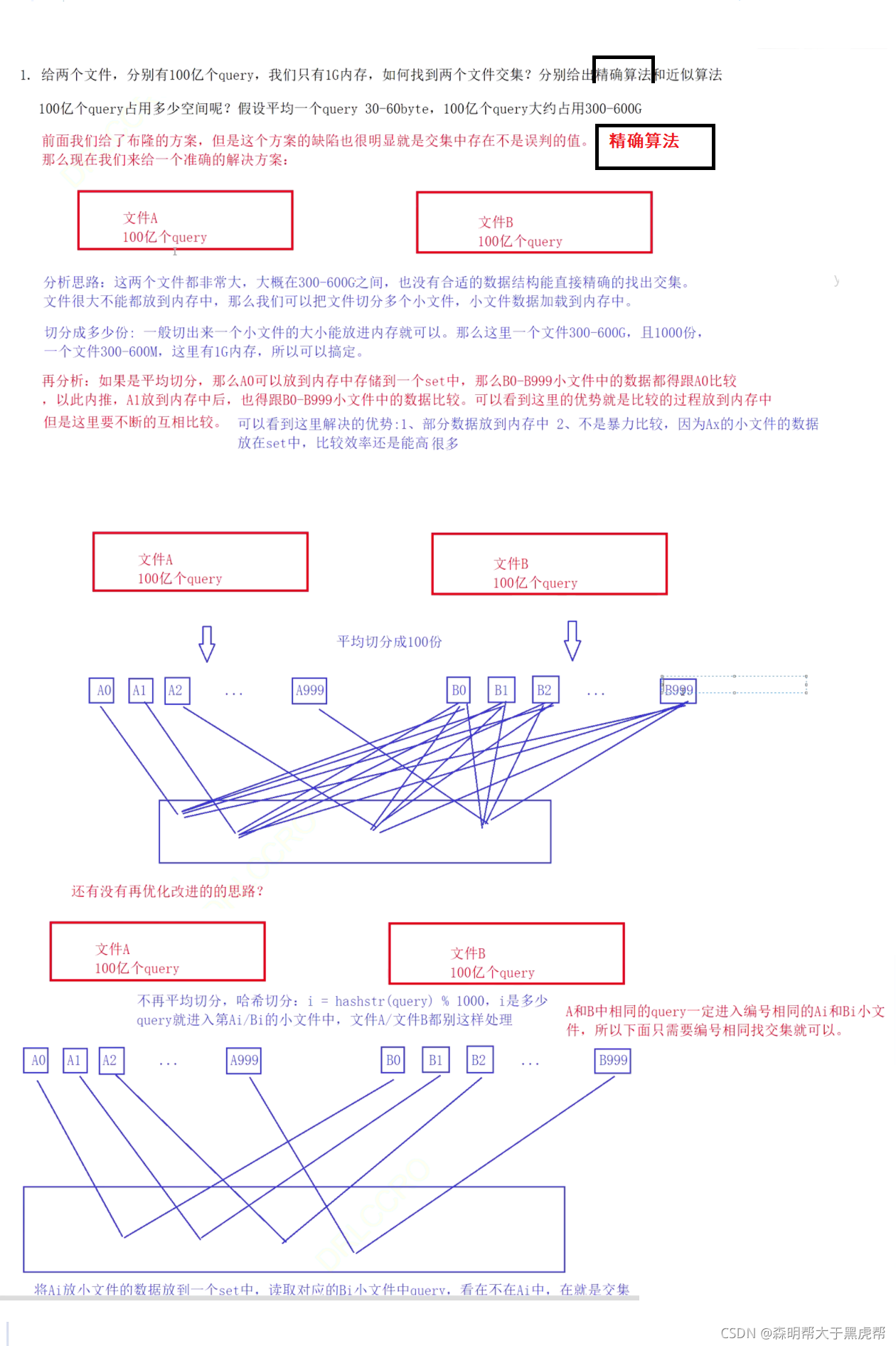
в‘ з»ҷдёӨдёӘж–Ү件пјҢеҲҶеҲ«жңү100дәҝдёӘqueryпјҢжҲ‘们еҸӘжңү1GеҶ…еӯҳпјҢеҰӮдҪ•жүҫеҲ°дёӨдёӘж–Ү件дәӨйӣҶпјҹеҲҶеҲ«з»ҷеҮәзІҫзЎ®з®—жі•е’Ңиҝ‘дјјз®—жі•?
в‘ЎеҰӮдҪ•жү©еұ•BloomFilterдҪҝеҫ—е®ғж”ҜжҢҒеҲ йҷӨе…ғзҙ зҡ„ж“ҚдҪң?
ж„ҹи°ўдҪ иғҪеӨҹи®Өзңҹйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« пјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„вҖңC++дёӯдҪҚеӣҫе’ҢеёғйҡҶиҝҮж»ӨеҷЁзҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« еҜ№еӨ§е®¶жңүеё®еҠ©пјҢеҗҢж—¶д№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘пјҢе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶзӯүзқҖдҪ жқҘеӯҰд№ !





