MySQLжҖҺд№Ҳж”Ҝж’‘иө·дәҝзә§жөҒйҮҸ
е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢMySQLжҖҺд№Ҳж”Ҝж’‘иө·дәҝзә§жөҒйҮҸпјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳдёҚжҖҺд№ҲдәҶи§ЈпјҢеӣ жӯӨеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©жҲ‘们дёҖиө·еҺ»дәҶи§ЈдёҖдёӢеҗ§пјҒ
1 дё»д»ҺиҜ»еҶҷеҲҶзҰ»
еӨ§йғЁеҲҶдә’иҒ”зҪ‘дёҡеҠЎйғҪжҳҜиҜ»еӨҡеҶҷе°‘пјҢеӣ жӯӨдјҳе…ҲиҖғиҷ‘DBеҰӮдҪ•ж”Ҝж’‘жӣҙй«ҳжҹҘиҜўж•°пјҢйҰ–е…Ҳе°ұйңҖиҰҒеҢәеҲҶиҜ»гҖҒеҶҷжөҒйҮҸпјҢиҝҷжүҚж–№дҫҝй’ҲеҜ№иҜ»жөҒйҮҸеҚ•зӢ¬жү©еұ•пјҢеҚідё»д»ҺиҜ»еҶҷеҲҶзҰ»гҖӮ
иӢҘеүҚз«ҜжөҒйҮҸзӘҒеўһеҜјиҮҙд»Һеә“иҙҹиҪҪиҝҮй«ҳпјҢDBAдјҡдјҳе…ҲеҒҡдёӘд»Һеә“жү©е®№дёҠеҺ»пјҢиҝҷж ·еҜ№DBзҡ„иҜ»жөҒйҮҸе°ұдјҡиҗҪеҲ°еӨҡдёӘд»Һеә“пјҢжҜҸдёӘд»Һеә“зҡ„иҙҹиҪҪе°ұйҷҚдәҶдёӢжқҘпјҢ然еҗҺејҖеҸ‘еҶҚе°ҪеҠӣе°ҶжөҒйҮҸжҢЎеңЁDBеұӮд№ӢдёҠгҖӮ
Cache V.S MySQLиҜ»еҶҷеҲҶзҰ»
з”ұдәҺд»ҺејҖеҸ‘е’Ңз»ҙжҠӨзҡ„йҡҫеәҰиҖғиҷ‘пјҢеј•е…Ҙзј“еӯҳдјҡеј•е…ҘеӨҚжқӮеәҰпјҢиҰҒиҖғиҷ‘зј“еӯҳж•°жҚ®дёҖиҮҙжҖ§пјҢз©ҝйҖҸпјҢйҳІйӣӘеҙ©зӯүй—®йўҳпјҢ并且д№ҹеӨҡз»ҙжҠӨдёҖзұ»з»„件гҖӮжүҖд»ҘжҺЁиҚҗдјҳе…ҲйҮҮз”ЁиҜ»еҶҷеҲҶзҰ»пјҢжүӣдёҚдҪҸдәҶеҶҚдҪҝз”ЁCacheгҖӮ
1.1 core
дё»д»ҺиҜ»еҶҷеҲҶзҰ»дёҖиҲ¬е°ҶдёҖдёӘDBзҡ„ж•°жҚ®жӢ·иҙқдёәдёҖжҲ–еӨҡд»ҪпјҢ并且еҶҷе…ҘеҲ°е…¶е®ғзҡ„DBжңҚеҠЎеҷЁдёӯпјҡ
жүҖд»Ҙдё»д»ҺиҜ»еҶҷеҲҶзҰ»зҡ„е…ій”®пјҡ
еҚідё»д»ҺеӨҚеҲ¶
и®©ејҖеҸ‘дәәе‘ҳдҪҝз”Ёж„ҹи§үдҫқж—§еңЁдҪҝз”ЁеҚ•дёҖDB
2 дё»д»ҺеӨҚеҲ¶
MySQLзҡ„дё»д»ҺеӨҚеҲ¶дҫқиө–дәҺbinlogпјҢеҚіи®°еҪ•MySQLдёҠзҡ„жүҖжңүеҸҳеҢ–并д»ҘдәҢиҝӣеҲ¶еҪўејҸдҝқеӯҳеңЁзЈҒзӣҳдёҠдәҢиҝӣеҲ¶ж—Ҙеҝ—ж–Ү件гҖӮ
дё»д»ҺеӨҚеҲ¶е°ұжҳҜе°Ҷbinlogдёӯзҡ„ж•°жҚ®д»Һдё»еә“дј иҫ“еҲ°д»Һеә“пјҢдёҖиҲ¬ејӮжӯҘпјҡдё»еә“ж“ҚдҪңдёҚдјҡзӯүеҫ…binlogеҗҢжӯҘе®ҢжҲҗгҖӮ
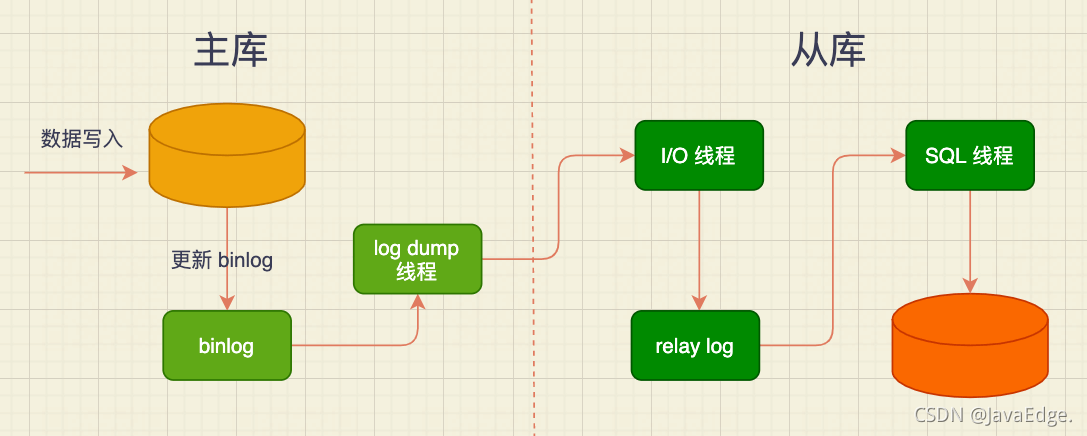
2.1 дё»д»ҺеӨҚеҲ¶зҡ„иҝҮзЁӢ
д»Һеә“еңЁиҝһжҺҘеҲ°дё»иҠӮзӮ№ж—¶дјҡеҲӣе»әдёҖдёӘI/OзәҝзЁӢпјҢд»ҘиҜ·жұӮдё»еә“жӣҙж–°зҡ„binlogпјҢ并жҠҠжҺҘ收еҲ°зҡ„binlogеҶҷе…Ҙrelay logж–Ү件пјҢдё»еә“д№ҹдјҡеҲӣе»әдёҖдёӘlog dumpзәҝзЁӢеҸ‘йҖҒbinlogз»ҷд»Һеә“
д»Һеә“иҝҳдјҡеҲӣе»әдёҖдёӘSQLзәҝзЁӢпјҢиҜ»relay logпјҢ并еңЁд»Һеә“дёӯеҒҡеӣһж”ҫпјҢжңҖз»Ҳе®һзҺ°дё»д»Һзҡ„дёҖиҮҙжҖ§
дҪҝз”ЁзӢ¬з«Ӣзҡ„log dumpзәҝзЁӢжҳҜејӮжӯҘпјҢйҒҝе…ҚеҪұе“Қдё»еә“зҡ„дё»дҪ“жӣҙж–°жөҒзЁӢпјҢиҖҢд»Һеә“еңЁжҺҘ收еҲ°дҝЎжҒҜеҗҺ并дёҚжҳҜеҶҷе…Ҙд»Һеә“зҡ„еӯҳеӮЁпјҢжҳҜеҶҷе…ҘдёҖдёӘrelay logпјҢиҝҷжҳҜдёәйҒҝе…ҚеҶҷе…Ҙд»Һеә“е®һйҷ…еӯҳеӮЁдјҡжҜ”иҫғиҖ—ж—¶пјҢжңҖз»ҲйҖ жҲҗд»Һеә“е’Ңдё»еә“延иҝҹеҸҳй•ҝгҖӮ
еҹәдәҺжҖ§иғҪиҖғиҷ‘пјҢдё»еә“еҶҷе…ҘжөҒзЁӢ并没жңүзӯүеҫ…дё»д»ҺеҗҢжӯҘе®ҢжҲҗе°ұиҝ”еӣһз»“жһңпјҢжһҒз«Ҝжғ…еҶөдёӢпјҢжҜ”еҰӮдё»еә“дёҠbinlogиҝҳжІЎжқҘеҫ—еҸҠиҗҪзӣҳпјҢе°ұеҸ‘з”ҹзЈҒзӣҳжҚҹеқҸжҲ–жңәеҷЁжҺүз”өпјҢеҜјиҮҙbinlogдёўеӨұпјҢдё»д»Һж•°жҚ®дёҚдёҖиҮҙгҖӮдёҚиҝҮжҰӮзҺҮеҫҲдҪҺпјҢеҸҜе®№еҝҚгҖӮ
дё»еә“е®•жңәеҗҺпјҢbinlogдёўеӨұеҜјиҮҙзҡ„дё»д»Һж•°жҚ®дёҚдёҖиҮҙд№ҹеҸӘиғҪжүӢеҠЁжҒўеӨҚгҖӮ
дё»д»ҺеӨҚеҲ¶еҗҺпјҢеҚіеҸҜпјҡ
иҝҷж ·еҚідҪҝеҶҷиҜ·жұӮдјҡй”ҒиЎЁжҲ–й”Ғи®°еҪ•пјҢд№ҹдёҚдјҡеҪұе“ҚиҜ»иҜ·жұӮжү§иЎҢгҖӮй«ҳ并еҸ‘дёӢпјҢеҸҜйғЁзҪІеӨҡдёӘд»Һеә“е…ұеҗҢжүҝжӢ…иҜ»жөҒйҮҸпјҢеҚідёҖдё»еӨҡд»Һж”Ҝж’‘й«ҳ并еҸ‘иҜ»гҖӮ
д»Һеә“д№ҹиғҪеҪ“жҲҗдёӘеӨҮеә“пјҢд»ҘйҒҝе…Қдё»еә“ж•…йҡңеҜјиҮҙж•°жҚ®дёўеӨұгҖӮ
йӮЈж— йҷҗеҲ¶ең°еўһеҠ д»Һеә“е°ұиғҪж”Ҝж’‘жӣҙй«ҳ并еҸ‘еҗ—пјҹ
NOпјҒд»Һеә“и¶ҠеӨҡпјҢд»Һеә“иҝһжҺҘдёҠжқҘзҡ„I/OзәҝзЁӢи¶ҠеӨҡпјҢдё»еә“д№ҹиҰҒеҲӣе»әеҗҢж ·еӨҡlog dumpзәҝзЁӢеӨ„зҗҶеӨҚеҲ¶зҡ„иҜ·жұӮпјҢеҜ№дәҺдё»еә“иө„жәҗж¶ҲиҖ—иҫғй«ҳпјҢеҗҢж—¶еҸ—йҷҗдәҺдё»еә“зҡ„зҪ‘з»ңеёҰе®ҪпјҢжүҖд»ҘдёҖиҲ¬дёҖдёӘдё»еә“жңҖеӨҡжҢӮ3пҪһ5дёӘд»Һеә“гҖӮ
2.2 дё»д»ҺеӨҚеҲ¶зҡ„еүҜдҪңз”Ё
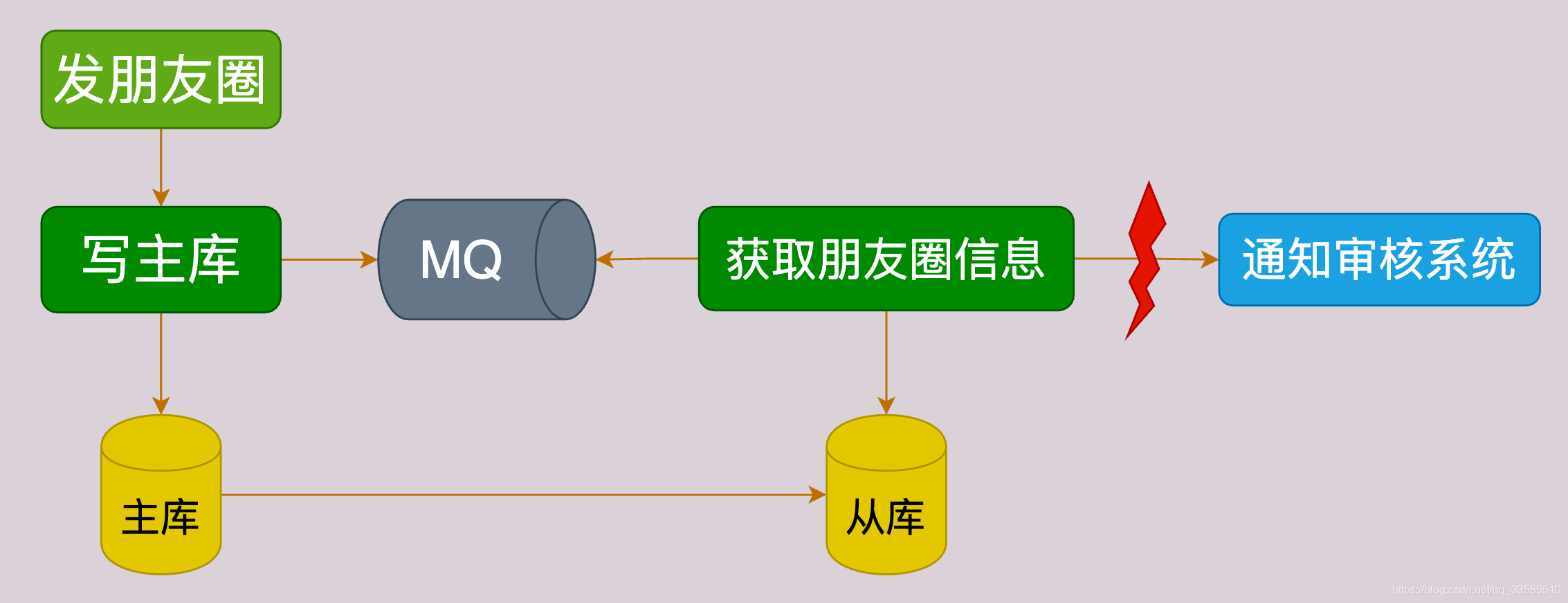
жҜ”еҰӮеҸ‘жңӢеҸӢеңҲиҝҷдёҖж“ҚдҪңпјҢе°ұеӯҳеңЁж•°жҚ®зҡ„пјҡ
еҰӮжӣҙж–°DB
еҰӮе°ҶжңӢеҸӢеңҲеҶ…е®№еҗҢжӯҘз»ҷе®Ўж ёзі»з»ҹ
жүҖд»Ҙжӣҙж–°е®Ңдё»еә“еҗҺпјҢдјҡе°ҶжңӢеҸӢеңҲIDеҶҷе…ҘMQпјҢз”ұConsumerдҫқжҚ®IDеңЁд»Һеә“иҺ·еҸ–жңӢеҸӢеңҲдҝЎжҒҜеҶҚеҸ‘з»ҷе®Ўж ёзі»з»ҹгҖӮ
жӯӨж—¶иӢҘдё»д»ҺDBеӯҳеңЁе»¶иҝҹпјҢдјҡеҜјиҮҙеңЁд»Һеә“еҸ–дёҚеҲ°жңӢеҸӢеңҲдҝЎжҒҜпјҢеҮәзҺ°ејӮеёёпјҒ
дё»д»Һ延иҝҹеҜ№дёҡеҠЎзҡ„еҪұе“ҚзӨәж„Ҹеӣҫ
2.3 йҒҝе…Қдё»д»ҺеӨҚеҲ¶зҡ„延иҝҹ
иҝҷе’ӢеҠһе‘ўпјҹе…¶е®һи§ЈеҶіж–№жЎҲжңүеҫҲеӨҡпјҢж ёеҝғжҖқжғійғҪжҳҜ е°ҪйҮҸдёҚеҺ»д»Һеә“жҹҘиҜўж•°жҚ®гҖӮеӣ жӯӨй’ҲеҜ№дёҠиҝ°жЎҲдҫӢпјҢе°ұжңүеҰӮдёӢж–№жЎҲпјҡ
2.3.1 ж•°жҚ®еҶ—дҪҷ
еҸҜеңЁеҸ‘MQж—¶пјҢдёҚжӯўеҸ‘йҖҒжңӢеҸӢеңҲIDпјҢиҖҢжҳҜеҸ‘з»ҷConsumerйңҖиҰҒзҡ„жүҖжңүжңӢеҸӢеңҲдҝЎжҒҜпјҢйҒҝе…Қд»ҺDBйҮҚж–°жҹҘиҜўж•°жҚ®гҖӮ
жҺЁиҚҗиҜҘж–№жЎҲпјҢеӣ дёәи¶іеӨҹз®ҖеҚ•пјҢдёҚиҝҮеҸҜиғҪйҖ жҲҗеҚ•жқЎж¶ҲжҒҜиҫғеӨ§пјҢд»ҺиҖҢеўһеҠ ж¶ҲжҒҜеҸ‘йҖҒзҡ„еёҰе®Ҫе’Ңж—¶й—ҙгҖӮ
2.3.2 дҪҝз”ЁCache
еңЁеҗҢжӯҘеҶҷDBзҡ„еҗҢж—¶пјҢжҠҠжңӢеҸӢеңҲж•°жҚ®еҶҷCacheпјҢиҝҷж ·ConsumerеңЁиҺ·еҸ–жңӢеҸӢеңҲдҝЎжҒҜж—¶пјҢдјҳе…ҲжҹҘиҜўCacheпјҢиҝҷд№ҹиғҪдҝқиҜҒж•°жҚ®дёҖиҮҙжҖ§гҖӮ
иҜҘж–№жЎҲйҖӮеҗҲж–°еўһж•°жҚ®зҡ„еңәжҷҜгҖӮиӢҘжҳҜеңЁжӣҙж–°ж•°жҚ®еңәжҷҜдёӢпјҢе…Ҳжӣҙж–°CacheеҸҜиғҪеҜјиҮҙж•°жҚ®дёҚдёҖиҮҙгҖӮжҜ”еҰӮдёӨдёӘзәҝзЁӢеҗҢж—¶жӣҙж–°ж•°жҚ®пјҡ
зәҝзЁӢAжҠҠCacheж•°жҚ®жӣҙж–°дёә1
еҸҰдёҖдёӘзәҝзЁӢBжҠҠCacheж•°жҚ®жӣҙж–°дёә2
然еҗҺзәҝзЁӢBеҸҲжӣҙж–°DBж•°жҚ®дёә2
зәҝзЁӢAеҶҚжӣҙж–°DBж•°жҚ®дёә1
жңҖз»ҲDBеҖјпјҲ1пјүе’ҢCacheеҖјпјҲ2пјүдёҚдёҖиҮҙпјҒ
2.3.3 жҹҘиҜўдё»еә“
еҸҜд»ҘеңЁConsumerдёӯдёҚжҹҘиҜўд»Һеә“пјҢиҖҢж”№дёәжҹҘиҜўдё»еә“гҖӮ
дҪҝз”ЁиҰҒж…ҺйҮҚпјҢиҰҒжҳҺзЎ®жҹҘиҜўзҡ„йҮҸзә§дёҚдјҡеҫҲеӨ§пјҢжҳҜеңЁдё»еә“зҡ„еҸҜжүҝеҸ—иҢғеӣҙд№ӢеҶ…пјҢеҗҰеҲҷдјҡеҜ№дё»еә“йҖ жҲҗиҫғеӨ§еҺӢеҠӣгҖӮ
иӢҘйқһдёҮдёҚеҫ—е·ІпјҢдёҚиҰҒдҪҝз”ЁиҜҘж–№жЎҲгҖӮеӣ дёәиҰҒжҸҗдҫӣдёҖдёӘжҹҘиҜўдё»еә“зҡ„жҺҘеҸЈпјҢеҫҲйҡҫдҝқиҜҒе…¶д»–дәәдёҚж»Ҙз”ЁиҜҘж–№жі•гҖӮ
дё»д»ҺеҗҢжӯҘ延иҝҹд№ҹжҳҜжҺ’жҹҘй—®йўҳж—¶е®№жҳ“еҝҪз•ҘгҖӮ
жңүж—¶дјҡйҒҮеҲ°д»ҺDBиҺ·еҸ–дёҚеҲ°дҝЎжҒҜзҡ„иҜЎејӮй—®йўҳпјҢдјҡзә з»“д»Јз ҒдёӯжҳҜеҗҰжңүдёҖдәӣйҖ»иҫ‘жҠҠд№ӢеүҚеҶҷе…ҘеҶ…е®№еҲ йҷӨдәҶпјҢдҪҶеҸ‘зҺ°иҝҮж®өж—¶й—ҙеҶҚеҺ»жҹҘиҜўж—¶еҸҲиғҪиҜ»еҲ°ж•°жҚ®пјҢиҝҷеҹәжң¬е°ұжҳҜдё»д»Һ延иҝҹй—®йўҳгҖӮ
жүҖд»ҘпјҢдёҖиҲ¬жҠҠд»Һеә“иҗҪеҗҺзҡ„ж—¶й—ҙдҪңдёәдёҖдёӘйҮҚзӮ№DBжҢҮж ҮпјҢеҒҡзӣ‘жҺ§е’ҢжҠҘиӯҰпјҢжӯЈеёёж—¶й—ҙеңЁmsзә§пјҢиҫҫеҲ°sзә§е°ұиҰҒе‘ҠиӯҰгҖӮ
дё»д»Һзҡ„延иҝҹж—¶й—ҙйў„иӯҰпјҢйӮЈеҰӮдҪ•йҖҡиҝҮе“ӘдёӘж•°жҚ®еә“дёӯзҡ„е“ӘдёӘжҢҮж ҮжқҘеҲӨеҲ«пјҹ еңЁд»Һд»Һеә“дёӯпјҢйҖҡиҝҮзӣ‘жҺ§show slave
status\Gе‘Ҫд»Өиҫ“еҮәзҡ„Seconds_Behind_MasterеҸӮж•°зҡ„еҖјеҲӨж–ӯпјҢжҳҜеҗҰжңүеҸ‘з”ҹдё»д»Һ延时гҖӮ
иҝҷдёӘеҸӮж•°еҖјжҳҜйҖҡиҝҮжҜ”иҫғsql_threadжү§иЎҢзҡ„eventзҡ„timestampе’Ңio_threadеӨҚеҲ¶еҘҪзҡ„
eventзҡ„timestamp(з®ҖеҶҷдёәts)иҝӣиЎҢжҜ”иҫғпјҢиҖҢеҫ—еҲ°зҡ„иҝҷд№ҲдёҖдёӘе·®еҖјгҖӮ
дҪҶеҰӮжһңеӨҚеҲ¶еҗҢжӯҘдё»еә“bin_logж—Ҙеҝ—зҡ„io_threadзәҝзЁӢиҙҹиҪҪиҝҮй«ҳпјҢеҲҷSeconds_Behind_MasterдёҖзӣҙдёә0пјҢеҚіж— жі•йў„иӯҰпјҢйҖҡиҝҮSeconds_Behind_MasterиҝҷдёӘеҖјжқҘеҲӨж–ӯ延иҝҹжҳҜдёҚеӨҹеҮҶзЎ®гҖӮе…¶е®һиҝҳеҸҜд»ҘйҖҡиҝҮжҜ”еҜ№masterе’Ңslaveзҡ„binlogдҪҚзҪ®гҖӮ
3 еҰӮдҪ•и®ҝй—®DB
дҪҝз”Ёдё»д»ҺеӨҚеҲ¶е°Ҷж•°жҚ®еӨҚеҲ¶еҲ°еӨҡдёӘиҠӮзӮ№пјҢд№ҹе®һзҺ°дәҶDBзҡ„иҜ»еҶҷеҲҶзҰ»пјҢиҝҷж—¶пјҢеҜ№DBзҡ„дҪҝз”Ёд№ҹеҸ‘з”ҹдәҶеҸҳеҢ–пјҡ
дёәйҷҚдҪҺе®һзҺ°зҡ„еӨҚжқӮеәҰпјҢдёҡз•Ңж¶ҢзҺ°дәҶеҫҲеӨҡDBдёӯй—ҙ件解еҶіDBзҡ„и®ҝй—®й—®йўҳпјҢеӨ§иҮҙеҲҶдёәпјҡ
3.1 еә”з”ЁзЁӢеәҸеҶ…йғЁ
еҰӮTDDLпјҲ Taobao Distributed Data LayerпјүпјҢд»Ҙд»Јз ҒеҪўејҸеҶ…еөҢиҝҗиЎҢеңЁеә”з”ЁзЁӢеәҸеҶ…йғЁгҖӮеҸҜзңӢжҲҗжҳҜдёҖз§Қж•°жҚ®жәҗд»ЈзҗҶпјҢе®ғзҡ„й…ҚзҪ®з®ЎзҗҶеӨҡдёӘж•°жҚ®жәҗпјҢжҜҸдёӘж•°жҚ®жәҗеҜ№еә”дёҖдёӘDBпјҢеҸҜиғҪжҳҜдё»еә“жҲ–д»Һеә“гҖӮ
еҪ“жңүдёҖдёӘDBиҜ·жұӮж—¶пјҢдёӯй—ҙ件е°ҶSQLиҜӯеҸҘеҸ‘з»ҷжҹҗдёӘжҢҮе®ҡж•°жҚ®жәҗпјҢ然еҗҺиҝ”еӣһеӨ„зҗҶз»“жһңгҖӮ
дјҳзӮ№
з®ҖеҚ•жҳ“з”ЁпјҢйғЁзҪІжҲҗжң¬дҪҺпјҢеӣ дёәжӨҚе…Ҙеә”з”ЁзЁӢеәҸеҶ…йғЁпјҢдёҺзЁӢеәҸдёҖеҗҢиҝҗиЎҢпјҢйҖӮеҗҲиҝҗз»ҙиҫғејұзҡ„е°ҸеӣўйҳҹгҖӮ
зјәзӮ№
зјәд№ҸеӨҡиҜӯиЁҖж”ҜжҢҒпјҢйғҪжҳҜJavaиҜӯиЁҖејҖеҸ‘зҡ„пјҢж— жі•ж”ҜжҢҒе…¶д»–зҡ„иҜӯиЁҖгҖӮзүҲжң¬еҚҮзә§д№ҹдҫқиө–дҪҝз”Ёж–№зҡ„жӣҙж–°гҖӮ
3.2 зӢ¬з«ӢйғЁзҪІзҡ„д»ЈзҗҶеұӮж–№жЎҲ
еҰӮMycatгҖҒAtlasгҖҒDBProxyгҖӮ
иҝҷзұ»дёӯй—ҙ件йғЁзҪІеңЁзӢ¬з«ӢжңҚеҠЎеҷЁпјҢдёҡеҠЎд»Јз ҒеҰӮеҗҢеңЁдҪҝз”ЁеҚ•дёҖDBпјҢе®һйҷ…дёҠе®ғеҶ…йғЁз®ЎзҗҶзқҖеҫҲеӨҡзҡ„ж•°жҚ®жәҗпјҢеҪ“жңүDBиҜ·жұӮж—¶пјҢе®ғдјҡеҜ№SQLиҜӯеҸҘеҒҡеҝ…иҰҒзҡ„ж”№еҶҷпјҢ然еҗҺеҸ‘еҫҖжҢҮе®ҡж•°жҚ®жәҗгҖӮ
дјҳзӮ№
зјәзӮ№
д»ҘдёҠжҳҜвҖңMySQLжҖҺд№Ҳж”Ҝж’‘иө·дәҝзә§жөҒйҮҸвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ





