数据分区分为两种,动态分区和静态分区,那么两种分区是怎样创建的呢?它们各自怎么来使用呢?
一、动态分区
1、从已有的数据动态创建新的分区
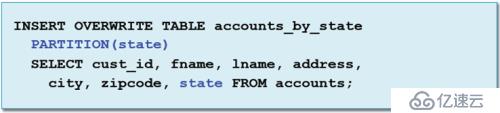
2、分区基于最后一个列值自动创建,如果分区不存在,它将被创建;
如果分区存在,将被覆盖。
二、静态分区
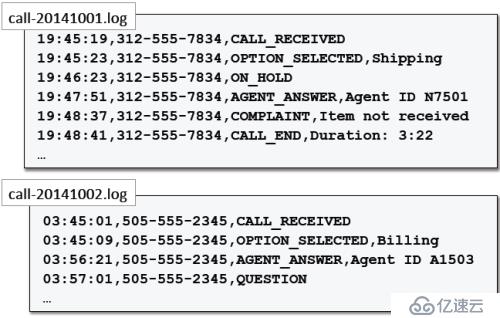
1、 静态分区示例:按天分区呼叫日志
Loudacre的客户服务电话系统生成了详细的呼叫日志,分析员使用这些数据来汇总前一天的呼叫量,比如:

日志按天生成,比如:
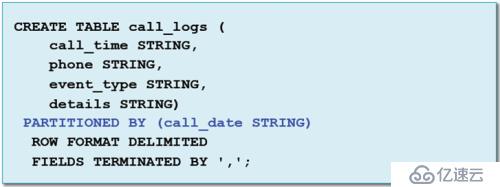
在上面的的示例中,数据基于列值自动分区。现在我们使用静态分区,
因为数据文件不包含分区数据,分区表按照同样的方式来定义:
2、加载数据到静态分区
使用静态分区,你可以根据需要创建新分区,比如:为每天的呼叫日志数据添加一个分区:

这个命令将添加分区到表的元数据,并创建子目录:
/user/hive/warehouse/call_logs/call_date=2014-10-02
然后加载一天的数据到正确的分区

这个命令移动HDFS文件call-20141002.log到分区子目录
3、覆盖分区的所有数据

以上就是关于动态分区和静态分区的介绍,那么在Impala和Hive中,数据是怎样分区的呢?后续将继续分享。不过技术都是有门槛的,大家在实际生活中要多学习和交流,不断汲取别人好的经验知识,改善自己的知识架构。而且当今大数据还在发展中,各方面不算是很成熟,更需要不断去追求,才可以不落伍,这里推荐一个微信公众号“大数据cn”,还不错,有时间可以去关注一下。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





