这篇文章主要讲解了“怎么理解并掌握Python线程”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“怎么理解并掌握Python线程”吧!
自定义进程类,继承Process类,重写run方法(重写Process的run方法)。
from multiprocessing import Process
import time
import os
class MyProcess(Process):
def __init__(self, name): ##重写,需要__init__,也添加了新的参数。 ##Process.__init__(self) 不可以省略,否则报错:AttributeError:'XXXX'object has no attribute '_colsed'
Process.__init__(self)
self.name = name
def run(self):
print("子进程(%s-%s)启动" % (self.name, os.getpid()))
time.sleep(3)
print("子进程(%s-%s)结束" % (self.name, os.getpid()))
if __name__ == '__main__':
print("父进程启动")
p = MyProcess("Ail")
# 自动调用MyProcess的run()方法
p.start()
p.join()
print("父进程结束")# 输出结果
父进程启动
子进程(Ail-38512)启动
子进程(Ail-38512)结束
父进程结束
多进程适合在CPU密集型操作(CPU操作指令比较多,如科学计算、位数多的浮点计算);
多线程适合在IO密集型操作(读写数据操作比较多的,比如爬虫、文件上传、下载)
线程是并发,进程是并行:进程之间互相独立,是系统分配资源的最小单位,同一个进程中的所有线程共享资源。
进程:一个运行的程序或代码就是一个进程,一个没有运行的代码叫程序。进程是系统进行资源分配的最小单位,进程拥有自己的内存空间,所以,进程间数据不共享,开销大。
进程是程序的一次动态执行过程。每个进程都拥有自己的地址空间、内存、数据栈以及其它用于跟踪执行的辅助数据。操作系统负责其上所有进程的执行,操作系统会为这些进程合理地分配执行时间。
线程:调度执行的最小单位,也叫执行路径,不能独立存在,依赖进程的存在而存在,一个进程至少有一个线程,叫做主线程,多个线程共享内存(数据共享和全局变量),因此提升程序的运行效率。
线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。一个线程是一个execution context(执行上下文),即一个CPU执行时所需要的一串指令。
主线程:主线程就是创建线程进程中产生的第一个线程,也就是main函数对应的线程。
协程:用户态的轻量级线程,调度由用户控制,拥有自己的寄存器上下文和栈,切换基本没有内核切换的开销,切换灵活。
进程和线程的关系
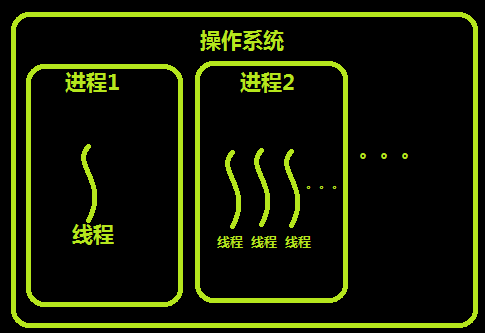
操作系统通过给不同的线程分配时间片(CPU运行时长)来调度线程,当CPU执行完一个线程的时间片后就会快速切换到下一个线程,时间片很短而且切换速度很快,以至于用户根本察觉不到。多个线程根据分配的时间片轮流被CPU执行,如今绝大多数计算机的CPU都是多核的,多个线程在操作系统的调度下,能够被多个CPU并行执行,程序的执行速度和CPU的利用效率大大提升。绝大对数主流的编程语言都能很好地支持多线程,然而,Python由于GIL锁无法实现真正的多线程。
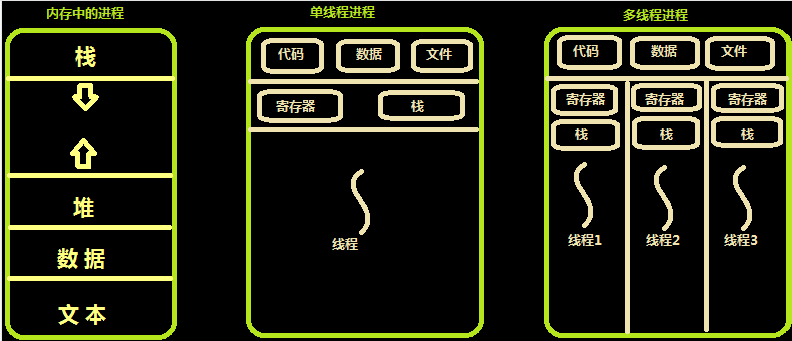
内存中的线程
(1)start() --开始执行该线程;
(2)run() --定义线程的方法(开发者可以在子类中重写);标准的 run() 方法会对作为 target 参数传递给该对象构造器的可调用对象(如果存在)发起调用,并附带从 args 和 kwargs 参数分别获取的位置和关键字参数。
(3)join(timeout=None) --直至启动的线程终止之前一直挂起;除非给出了timeout(单位秒),否则一直被阻塞;因为 join() 总是返回 None ,所以要在 join() 后调用 is_alive() 才能判断是否发生超时 -- 如果线程仍然存活,则 join() 超时。一个线程可以被 join() 很多次。如果尝试加入当前线程会导致死锁, join() 会引起 RuntimeError 异常。如果尝试 join() 一个尚未开始的线程,也会抛出相同的异常。
(4)is_alive() --布尔值,表示这个线程是否还存活;当 run() 方法刚开始直到 run() 方法刚结束,这个方法返回 True 。
(5)threading.current_thread()--返回当前对应调用者的控制线程的 Thread 对象。例如,获取当前线程的名字,可以是current_thread().name。
from threading import Thread
from multiprocessing import Process
import os
def work():
print('hello,',os.getpid())
if __name__ == '__main__':
# 在主进程下开启多个线程,每个线程都跟主进程的pid一样
t1 = Thread(target=work) # 开启一个线程
t2 = Thread(target=work) # 开启两个线程
t1.start() ##start()--It must be called at most once per thread object.It arranges for the object's run() method to be ## invoked in a separate thread of control.This method will raise a RuntimeError if called more than once on the ## same thread object.
t2.start()
print('主线程/主进程pid', os.getpid())
# 开多个进程,每个进程都有不同的pid
p1 = Process(target=work)
p2 = Process(target=work)
p1.start()
p2.start()
print('主线程/主进程pid',os.getpid())线程的状态包括:创建、就绪、运行、阻塞、结束。
(1)创建对象时,代表 Thread 内部被初始化;
(2) 调用 start() 方法后,thread 会开始进入队列准备运行,在未获得CPU、内存资源前,称为就绪状态;轮询获取资源,进入运行状态;如果遇到sleep,则是进入阻塞状态;
(3) thread 代码正常运行结束或者是遇到异常,线程会终止。
(1)定义一个类,继承Thread;
(2)重写__init__ 和 run();
(3)创建线程类对象;
(4)启动线程。
import time
import threading
class MyThread(threading.Thread):
def __init__(self,num):
super().__init__() ###或者是Thread.__init__()
self.num = num
def run(self):
print('线程名称:', threading.current_thread().getName(), '参数:', self.num, '开始时间:', time.strftime('%Y-%m-%d %H:%M:%S'))
if __name__ == '__main__':
print('主线程开始:',time.strftime('%Y-%m-%d %H:%M:%S'))
t1 = MyThread(1)
t2 = MyThread(2)
t1.start()
t2.start()
t1.join()
t2.join()
print('主线程结束:', time.strftime('%Y-%m-%d %H:%M:%S'))如果是全局变量,则每个线程是共享的;
GIL锁:可以用篮球比赛的场景来模拟,把篮球场看作是CPU,一场篮球比赛看作是一个线程,如果只有一个篮球场,多场比赛就要排队进行,类似于一个简单的单核多线程的程序;如果由多块篮球场,多场比赛同时进行,就是一个简单的多核多线程的程序。然而,Python有着特别的规定:每场比赛必须要在裁判的监督之下才允许进行,而裁判只有一个。这样不管你有几块篮球场,同一时间只允许有一个场地进行比赛,其它场地都将被闲置,其它比赛都只能等待。
GIL保证同一时间内一个进程可以有多个线程,但只有一个线程在执行;锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据。
类为threading.Lock
它有两个基本方法, acquire() 和 release() 。
当状态为非锁定时, acquire() 将状态改为 锁定 并立即返回。当状态是锁定时, acquire() 将阻塞至其他线程调用 release() 将其改为非锁定状态,然后 acquire() 调用重置其为锁定状态并返回。
release() 只在锁定状态下调用; 它将状态改为非锁定并立即返回。如果尝试释放一个非锁定的锁,则会引发 RuntimeError 异常。
Caese 如下:
from threading import Thread
from threading import Lock
import time
number = 0
def task(lock):
global number
lock.acquire() ##持有锁
for i in range(100000) number += 1
lock.release() ##释放锁
if __name__ == '__main__':
lock=Lock()
t1 = Thread(target=task,args=(lock,))
t2 = Thread(target=task,args=(lock,)) t3 = Thread(target=task,args=(lock,))
t1.start() t2.start() t3.start() t1.join() t2.join() t3.join() print('number:',number)class threading.Semaphore([values])
values是一个内部计数,values默认是1,如果小于0,则会抛出 ValueError 异常,可以用于控制线程数并发数。
信号量的实现方式:
s=Semaphore(?)
在内部有一个counter计数器,counter的值就是同一时间可以开启线程的个数。每当我们s.acquire()一次,计数器就进行减1处理,每当我们s.release()一次,计数器就会进行加1处理,当计数器为0的时候,其它的线程就处于等待的状态。
程序添加一个计数器功能(信号量),限制一个时间点内的线程数量,防止程序崩溃或其它异常。
Case
import time
import threading
s=threading.Semaphore(5) #添加一个计数器
def task():
s.acquire() #计数器获得锁
time.sleep(2) #程序休眠2秒
print("The task run at ",time.ctime())
s.release() #计数器释放锁
for i in range(40):
t1=threading.Thread(target=task,args=()) #创建线程
t1.start() #启动线程也可以使用with操作,替代acquire ()和release(),上面的代码调整如下:
import time
import threading
s=threading.Semaphore(5) #添加一个计数器
def task(): with s: ## 类似打开文件的with操作
##s.acquire() #计数器获得锁
time.sleep(2) #程序休眠2秒
print("The task run at ",time.ctime())
##s.release() #计数器释放锁
for i in range(40):
t1=threading.Thread(target=task,args=()) #创建线程
t1.start() #启动线程建议使用with。
感谢各位的阅读,以上就是“怎么理解并掌握Python线程”的内容了,经过本文的学习后,相信大家对怎么理解并掌握Python线程这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





