本篇内容介绍了“怎么利用Python快速找到最大文件”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
思路:我们遍历目录,将文件路径和文件大小作为生成器返回,然后插入大小为 10 的大顶堆,最后将大顶堆的内容打印即可。
借助 Python,代码很简洁:
import os
import time
from os.path import join, getsize
from heapq import nlargest
def walk_files_and_sizes(start_at: str):
for root, _, files in os.walk(start_at):
for file in files:
path = join(root, file)
try:
size = getsize(path) # bytes
yield path, size
except OSError:
continue
def largest_files(n: int, start_at: str) -> None:
MB = 1024 * 1024
largest = nlargest(n, walk_files_and_sizes(start_at), key=lambda x: x[1])
for path, size in largest:
print(f'{size//MB} MB {path}')
if __name__ == '__main__':
start = time.perf_counter()
largest_files(10, "/Users/aaron/")
elapsed = time.perf_counter() - start
print(f'{elapsed} seconds elapsed')我在自己电脑上跑了下,200 GB 左右的目录,123 秒就跑完了:
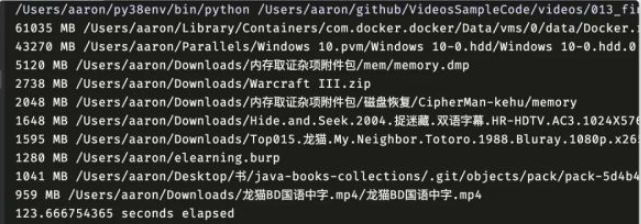
接下来删除不需要的文件就可以了。
如果是 Windows 系统也是可以的:
largest_files(10, "C:/Users/xxx/")
“怎么利用Python快速找到最大文件”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





