这篇文章主要讲解了“nodejs是单进程吗”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“nodejs是单进程吗”吧!
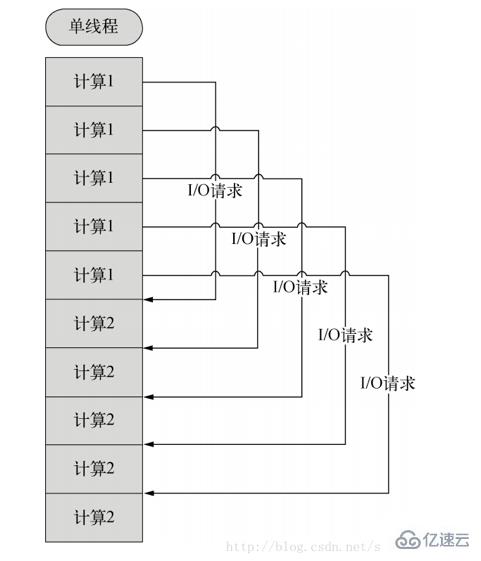
nodejs是单进程。node.js采用单线程异步非阻塞模式,也就是说每一个计算独占cpu,遇到“I/O”请求不阻塞后面的计算,当“I/O”完成后,以事件的方式通知,继续执行下一个计算。

本教程操作环境:windows7系统、nodejs 12.19.0版、Dell G3电脑。
像java、python这个可以具有多线程的语言。多线程同步模式是这样的,将cpu分成几个线程,每个线程同步运行。
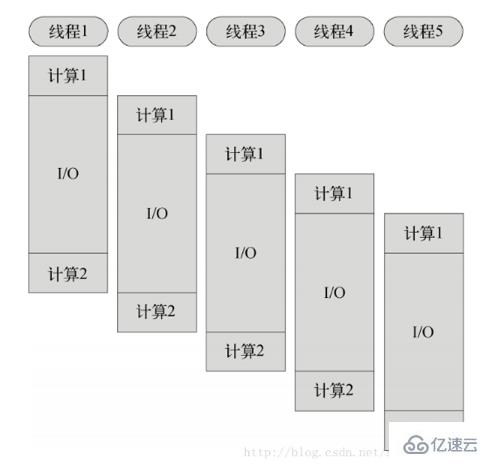
而node.js采用单线程异步非阻塞模式,也就是说每一个计算独占cpu,遇到I/O请求不阻塞后面的计算,当I/O完成后,以事件的方式通知,继续执行计算2。
事件驱动、异步、单线程、非阻塞I/O,这是我们听得最多的关于nodejs的介绍。看到上面的关键字,可能我们会好奇:
为什么在浏览器中运行的 Javascript 能与操作系统进行如此底层的交互?
nodejs既然是单线程,如何实现异步、非阻塞I/O?
nodejs全是异步调用和非阻塞I/O,就真的不用管并发数了吗?
nodejs事件驱动是如何实现的?和浏览器的event loop是一回事吗?
nodejs擅长什么?不擅长什么?
要弄清楚上面的问题,首先要弄清楚nodejs是怎么工作的。

我们可以看到,Node.js 的结构大致分为三个层次:
1、 Node.js 标准库,这部分是由 Javascript 编写的,即我们使用过程中直接能调用的 API。在源码中的 lib 目录下可以看到。
2、 Node bindings,这一层是 Javascript 与底层 C/C++ 能够沟通的关键,前者通过 bindings 调用后者,相互交换数据。
3、这一层是支撑 Node.js 运行的关键,由 C/C++ 实现。
V8:Google 推出的 Javascript VM,也是 Node.js 为什么使用的是 Javascript 的关键,它为 Javascript 提供了在非浏览器端运行的环境,它的高效是 Node.js 之所以高效的原因之一。
Libuv:它为 Node.js 提供了跨平台,线程池,事件池,异步 I/O 等能力,是 Node.js 如此强大的关键。
C-ares:提供了异步处理 DNS 相关的能力。
http_parser、OpenSSL、zlib 等:提供包括 http 解析、SSL、数据压缩等其他的能力。
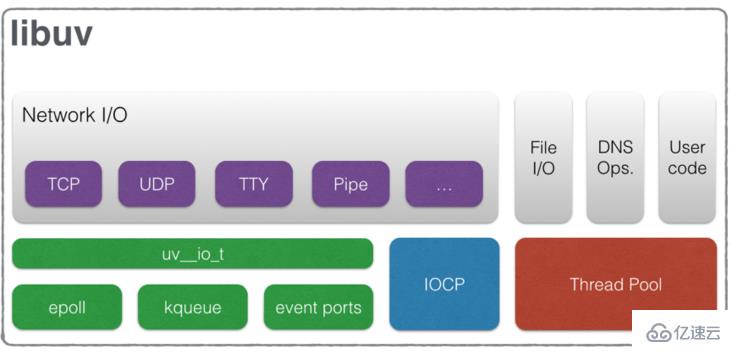
可以看出,几乎所有和操作系统打交道的部分都离不开 libuv的支持。libuv也是node实现跨操作系统的核心所在。
举个简单的例子,我们想要打开一个文件,并进行一些操作,可以写下面这样一段代码:
var fs = require('fs');
fs.open('./test.txt', "w", function(err, fd) {
//..do something
});
fs.open = function(path, flags, mode, callback) {
// ...
binding.open(pathModule._makeLong(path),
stringToFlags(flags),
mode,
callback);
};这段代码的调用过程大致可描述为:lib/fs.js → src/node_file.cc →uv_fs
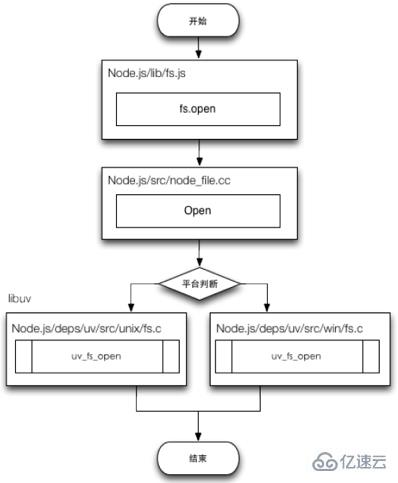
从JavaScript调用Node的核心模块,核心模块调用C++内建模块,内建模块通过 libuv进行系统调用,这是Node里经典的调用方式。总体来说,我们在 Javascript 中调用的方法,最终都会通过node-bindings 传递到 C/C++ 层面,最终由他们来执行真正的操作。Node.js 即这样与操作系统进行互动。
顺便回答标题nodejs真的是单线程吗?其实只有js执行是单线程,I/O显然是其它线程。
js执行线程是单线程,把需要做的I/O交给libuv,自己马上返回做别的事情,然后libuv在指定的时刻回调就行了。其实简化的流程就是酱紫的!细化一点,nodejs会先从js代码通过node-bindings调用到C/C++代码,然后通过C/C++代码封装一个叫 “请求对象” 的东西交给libuv,这个请求对象里面无非就是需要执行的功能+回调之类的东西,给libuv执行以及执行完实现回调。
总结来说,一个异步 I/O 的大致流程如下:
1、发起 I/O 调用
用户通过 Javascript 代码调用 Node 核心模块,将参数和回调函数传入到核心模块;
Node 核心模块会将传入的参数和回调函数封装成一个请求对象;
将这个请求对象推入到 I/O 线程池等待执行;
Javascript 发起的异步调用结束,Javascript 线程继续执行后续操作。
2、执行回调
I/O 操作完成后,会取出之前封装在请求对象中的回调函数,执行这个回调函数,以完成 Javascript 回调的目的。(这里回调的细节下面讲解)
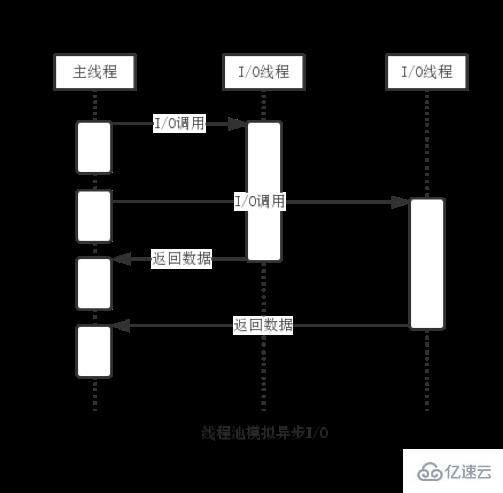
从这里,我们可以看到,我们其实对 Node.js 的单线程一直有个误会。事实上,它的单线程指的是自身 Javascript 运行环境的单线程,Node.js 并没有给 Javascript 执行时创建新线程的能力,最终的实际操作,还是通过 Libuv 以及它的事件循环来执行的。这也就是为什么 Javascript 一个单线程的语言,能在 Node.js 里面实现异步操作的原因,两者并不冲突。
之前我们就提到了线程池的概念,发现nodejs并不是单线程的,而且还有并行事件发生。同时,线程池默认大小是 4 ,也就是说,同时能有4个线程去做文件i/o的工作,剩下的请求会被挂起等待直到线程池有空闲。 所以nodejs对于并发数,是由限制的。
线程池的大小可以通过 UV_THREADPOOL_SIZE 这个环境变量来改变 或者在nodejs代码中通过 process.env.UV_THREADPOOL_SIZE来重新设置。
event loop是一个执行模型,在不同的地方有不同的实现。浏览器和nodejs基于不同的技术实现了各自的event loop。
简单来说:
nodejs的event是基于libuv,而浏览器的event loop则在html5的规范中明确定义。
libuv已经对event loop作出了实现,而html5规范中只是定义了浏览器中event loop的模型,具体实现留给了浏览器厂商。
我们上面提到了libuv接过了js传递过来的 I/O请求,那么何时来处理回调呢?
libuv有一个事件循环(event loop)的机制,来接受和管理回调函数的执行。
event loop是libuv的核心所在,上面我们提到 js 会把回调和任务交给libuv,libuv何时来调用回调就是 event loop 来控制的。event loop 首先会在内部维持多个事件队列(或者叫做观察者 watcher),比如 时间队列、网络队列等等,使用者可以在watcher中注册回调,当事件发生时事件转入pending状态,再下一次循环的时候按顺序取出来执行,而libuv会执行一个相当于 while true的无限循环,不断的检查各个watcher上面是否有需要处理的pending状态事件,如果有则按顺序去触发队列里面保存的事件,同时由于libuv的事件循环每次只会执行一个回调,从而避免了 竞争的发生。Libuv的 event loop执行图:
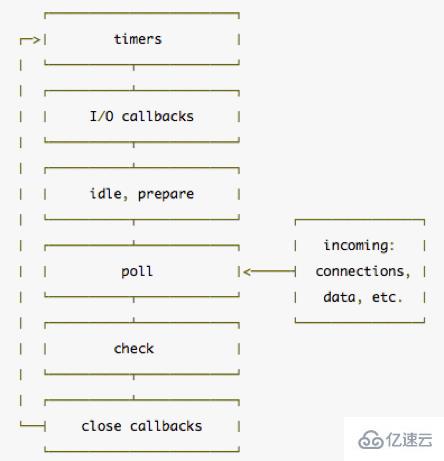
nodejs的event loop分为6个阶段,每个阶段的作用如下:
timers:执行setTimeout() 和 setInterval()中到期的callback。
I/O callbacks:上一轮循环中有少数的I/Ocallback会被延迟到这一轮的这一阶段执行
idle, prepare:仅内部使用
poll:最为重要的阶段,执行I/O callback,在适当的条件下会阻塞在这个阶段
check:执行setImmediate的callback
close callbacks:执行close事件的callback,例如socket.on("close",func)
event loop的每一次循环都需要依次经过上述的阶段。 每个阶段都有自己的callback队列,每当进入某个阶段,都会从所属的队列中取出callback来执行,当队列为空或者被执行callback的数量达到系统的最大数量时,进入下一阶段。这六个阶段都执行完毕称为一轮循环。
附带event loop 源码:
int uv_run(uv_loop_t* loop, uv_run_mode mode) {
int timeout;
int r;
int ran_pending;
/*
从uv__loop_alive中我们知道event loop继续的条件是以下三者之一:
1,有活跃的handles(libuv定义handle就是一些long-lived objects,例如tcp server这样)
2,有活跃的request
3,loop中的closing_handles
*/
r = uv__loop_alive(loop);
if (!r)
uv__update_time(loop);
while (r != 0 && loop->stop_flag == 0) {
uv__update_time(loop);//更新时间变量,这个变量在uv__run_timers中会用到
uv__run_timers(loop);//timers阶段
ran_pending = uv__run_pending(loop);//从libuv的文档中可知,这个其实就是I/O callback阶段,ran_pending指示队列是否为空
uv__run_idle(loop);//idle阶段
uv__run_prepare(loop);//prepare阶段
timeout = 0;
/**
设置poll阶段的超时时间,以下几种情况下超时会被设为0,这意味着此时poll阶段不会被阻塞,在下面的poll阶段我们还会详细讨论这个
1,stop_flag不为0
2,没有活跃的handles和request
3,idle、I/O callback、close阶段的handle队列不为空
否则,设为timer阶段的callback队列中,距离当前时间最近的那个
**/
if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT)
timeout = uv_backend_timeout(loop);
uv__io_poll(loop, timeout);//poll阶段
uv__run_check(loop);//check阶段
uv__run_closing_handles(loop);//close阶段
//如果mode == UV_RUN_ONCE(意味着流程继续向前)时,在所有阶段结束后还会检查一次timers,这个的逻辑的原因不太明确
if (mode == UV_RUN_ONCE) {
uv__update_time(loop);
uv__run_timers(loop);
}
r = uv__loop_alive(loop);
if (mode == UV_RUN_ONCE || mode == UV_RUN_NOWAIT)
break;
}
if (loop->stop_flag != 0)
loop->stop_flag = 0;
return r;
}这里我们再详细了解一下poll阶段:
poll 阶段有两个主要功能:
1、执行下限时间已经达到的timers的回调
2、处理 poll 队列里的事件。
当event loop进入 poll 阶段,并且 没有设定的timers(there are no timers scheduled),会发生下面两件事之一:
1、如果 poll 队列不空,event loop会遍历队列并同步执行回调,直到队列清空或执行的回调数到达系统上限;
2、如果 poll 队列为空,则发生以下两件事之一:
(1)如果代码已经被setImmediate()设定了回调, event loop将结束 poll 阶段进入 check 阶段来执行 check 队列(里的回调)。
(2)如果代码没有被setImmediate()设定回调,event loop将阻塞在该阶段等待回调被加入 poll 队列,并立即执行。
但是,当event loop进入 poll 阶段,并且 有设定的timers,一旦 poll 队列为空(poll 阶段空闲状态):
event loop将检查timers,如果有1个或多个timers的下限时间已经到达,event loop将绕回 timers 阶段。
event loop的一个例子讲述:
var fs = require('fs');
function someAsyncOperation (callback) {
// 假设这个任务要消耗 95ms
fs.readFile('/path/to/file', callback);
}
var timeoutScheduled = Date.now();
setTimeout(function () {
var delay = Date.now() - timeoutScheduled;
console.log(delay + "ms have passed since I was scheduled");
}, 100);
// someAsyncOperation要消耗 95 ms 才能完成
someAsyncOperation(function () {
var startCallback = Date.now();
// 消耗 10ms...
while (Date.now() - startCallback < 10) {
; // do nothing
}
});当event loop进入 poll 阶段,它有个空队列(fs.readFile()尚未结束)。所以它会等待剩下的毫秒,直到最近的timer的下限时间到了。当它等了95ms,fs.readFile()首先结束了,然后它的回调被加到 poll的队列并执行——这个回调耗时10ms。之后由于没有其它回调在队列里,所以event loop会查看最近达到的timer的下限时间,然后回到 timers 阶段,执行timer的回调。
所以在示例里,回调被设定 和 回调执行间的间隔是105ms。
到这里我们再总结一下,整个异步IO的流程:
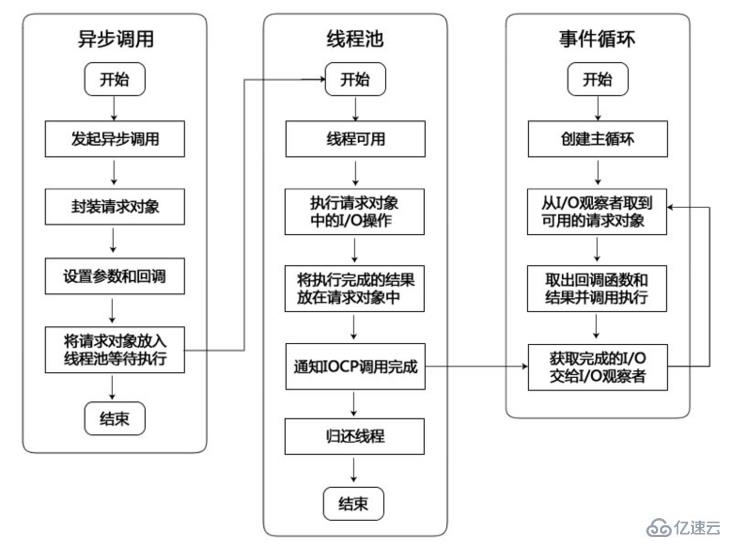
Node.js 通过 libuv 来处理与操作系统的交互,并且因此具备了异步、非阻塞、事件驱动的能力。因此,NodeJS能响应大量的并发请求。所以,NodeJS适合运用在高并发、I/O密集、少量业务逻辑的场景。
上面提到,如果是 I/O 任务,Node.js 就把任务交给线程池来异步处理,高效简单,因此 Node.js 适合处理I/O密集型任务。但不是所有的任务都是 I/O 密集型任务,当碰到CPU密集型任务时,即只用CPU计算的操作,比如要对数据加解密(node.bcrypt.js),数据压缩和解压(node-tar),这时 Node.js 就会亲自处理,一个一个的计算,前面的任务没有执行完,后面的任务就只能干等着 。我们看如下代码:
var start = Date.now();//获取当前时间戳
setTimeout(function () {
console.log(Date.now() - start);
for (var i = 0; i < 1000000000; i++){//执行长循环
}
}, 1000);
setTimeout(function () {
console.log(Date.now() - start);
}, 2000);最终我们的打印结果是:(结果可能因为你的机器而不同)
1000
3738
对于我们期望2秒后执行的setTimeout函数其实经过了3738毫秒之后才执行,换而言之,因为执行了一个很长的for循环,所以我们整个Node.js主线程被阻塞了,如果在我们处理100个用户请求中,其中第一个有需要这样大量的计算,那么其余99个就都会被延迟执行。如果操作系统本身就是单核,那也就算了,但现在大部分服务器都是多 CPU 或多核的,而 Node.js 只有一个 EventLoop,也就是只占用一个 CPU 内核,当 Node.js 被CPU 密集型任务占用,导致其他任务被阻塞时,却还有 CPU 内核处于闲置状态,造成资源浪费。
其实虽然Node.js可以处理数以千记的并发,但是一个Node.js进程在某一时刻其实只是在处理一个请求。
因此,Node.js 并不适合 CPU 密集型任务。
感谢各位的阅读,以上就是“nodejs是单进程吗”的内容了,经过本文的学习后,相信大家对nodejs是单进程吗这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



