memcached 是高性能的分布式内存缓存服务器。一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态 Web 应用的速度、提高可扩展性。很显然,弄清楚它的内存存储,很有必要。还是那句话,不需要兜书包了,把自己整理的相关memcached内存管理方面的框架图分享一下。
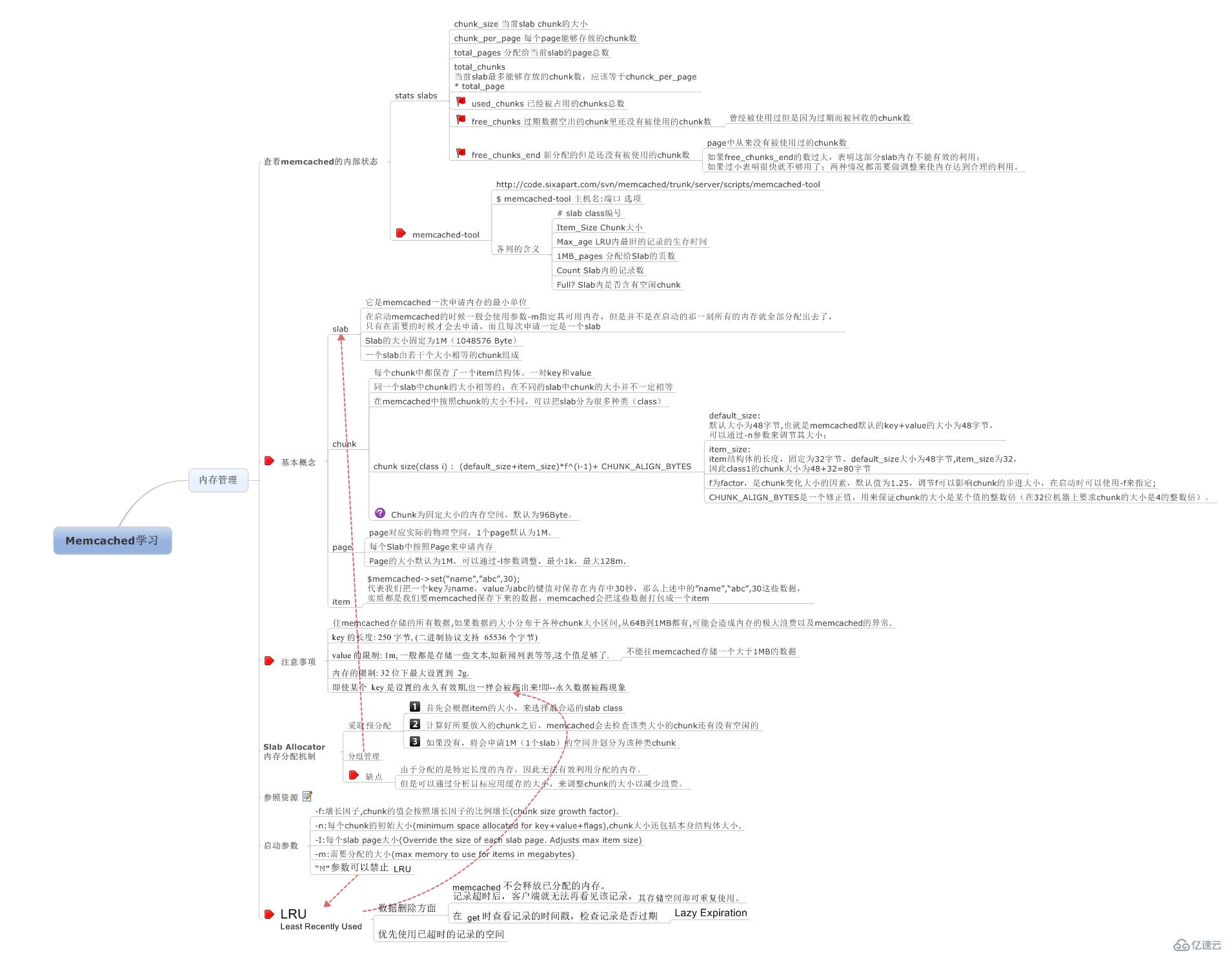
个人喜欢把内存管理,分为3个学习单元。
如何分配内存?
如何回收内存?
如何监控内存?
当然,本文的主要演练重点也有了。
内存如何分配
内存如何回收
认识监控参数
验证一些边界数据
1.如何分配内存?
1.1 默认启动内存分配情况
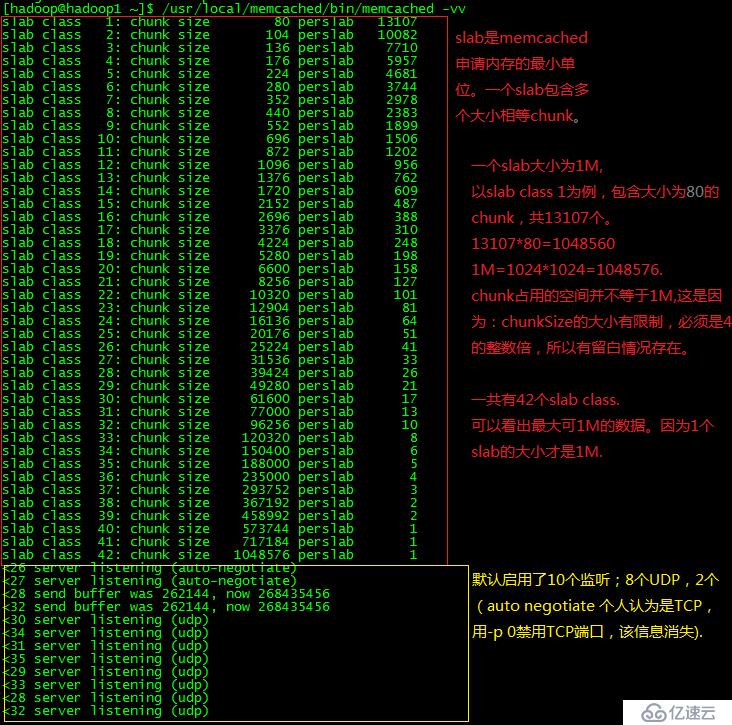
这段输出日志,可以分成2部分阅读。第一部分是slab内存分配信息;第二个:启用监听情况。
有3点没太搞清楚。
为什么每次启动都是2个"send buffer....",而且都是28,32。
每个server listening前面的26-35的数字编号是何含义?为什么不从0开始。
括号里面的udp,是说明监听UDP类型协议吗?监听TCP协议监听呢呢?
有对这一块比较清楚的麻烦指导下,但还好不清楚这几点不影响大局。
1.2 自定义启动规则
接下来,通过修改下启动参数,看下输出的日志。对比学习下。
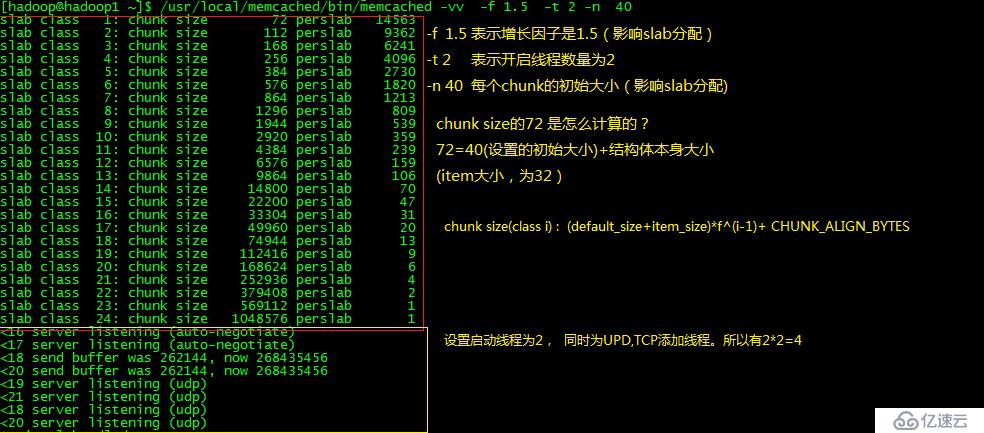
通过对比,我们很容易理解一些基本概念。chunk size,增长因子。
值得一提的的有一个指标。
## -t 4时,监控curr_connections ## 4*2+2=10 [root@hadoop1 hadoop]# echo stats | nc 127.0.0.1 11211 |grep connection STAT curr_connections 10 ## -t 2时,监控curr_connections ## 2*2+2=6 [root@hadoop1 hadoop]# echo stats | nc 127.0.0.1 11211 |grep connection STAT curr_connections 6
3. 监控保存数据前后slab信息
保存数据之前监控slabs信息如下
[root@hadoop1 hadoop]# echo stats slabs | nc 127.0.0.1 11211 STAT active_slabs 0 STAT total_malloced 0
保存数据之后监控slabs信息如下
set key 1 1 1 1 STORED set key2 1 0 1 1 STORED set key2 1 0 1 1 STORED set key3 1 0 1 3 STORED [root@hadoop1 hadoop]# echo stats slabs | nc 127.0.0.1 11211 STAT 1:chunk_size 80 STAT 1:chunks_per_page 13107 STAT 1:total_pages 1 STAT 1:total_chunks 13107 STAT 1:used_chunks 2 STAT 1:free_chunks 13105 STAT 1:free_chunks_end 0 STAT 1:mem_requested 108 STAT 1:get_hits 0 STAT 1:cmd_set 4 STAT 1:delete_hits 0 STAT 1:incr_hits 0 STAT 1:decr_hits 0 STAT 1:cas_hits 0 STAT 1:cas_badval 0 STAT 1:touch_hits 0 STAT active_slabs 1 STAT total_malloced 1048560 END
通过分析日志,可以很清楚的知道,发起的操作记录。
共发起了4个set或add操作.使用了2个大小为80的chunk。
值得一提下,保存的数据都非常小,却占用了160字节。好心疼浪费的存储空间啊。
通过监控total_malloced指标,还验证了,memcached采用预分配,分组管理方式。
当真正有数据保存时,才真正分配内存空间。而且,只有slab class被使用了之后,才能通过stat slabs监控到。
2.内存如何回收
内存回收不太方便验证,LRU算法使用情况,我们可以从侧面验证下。
我的演练思路:批量添加等大小的数据。然后dump出想要数据,确认下最小的KEY。
虽然简单粗暴,但大体可以说明LRU算法吧。
2.1 准备批量添加数据代码
使用的是《memcached演练(2) 访问memcached服务 》提到的spymemcached
public void test111() throws ExecutionException, InterruptedException {
final MemcachedClient mcc = MemcachedUtil.getSpyMemcachedClient();
final Lock lock = new ReentrantLock();
final String value="abcdef.....";
//不停的set值
Thread t1= new Thread(new Runnable() {
@Override
public void run() {
for(int i=0;i<10000000;i++){
// System.out.println("i="+i);
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
String key = "lrutestkey_"+StringUtils.leftPad(""+i,10,"0");;
mcc.set(key, 19000, value);
}
}
},"setting data");
t1.start();
t1.join();
mcc.shutdown();
}简单dump了几次,片段如下
[root@hadoop1 scripts]# ./memcached-tool localhost:11211 dump |grep add |sort |head -n 10 Dumping memcache contents Number of buckets: 1 Number of items : 13512 Dumping bucket 10 - 13512 total items add lrutestkey_0000000000 0 1471172545 512 add lrutestkey_0000000001 0 1471172545 512 add lrutestkey_0000000002 0 1471172545 512 ... add lrutestkey_0000002688 0 1471172763 512 [root@hadoop1 scripts]# ./memcached-tool localhost:11211 dump |grep add |sort |head -n 10 Dumping memcache contents Number of buckets: 1 Number of items : 7530 Dumping bucket 10 - 7530 total items add lrutestkey_0000002665 0 1471172762 512 add lrutestkey_0000002670 0 1471172762 512 ... [root@hadoop1 scripts]# ./memcached-tool localhost:11211 dump |grep add |sort |head -n 10 Dumping memcache contents Number of buckets: 1 Number of items : 7530 Dumping bucket 10 - 7530 total items add lrutestkey_0000005142 0 1471172787 512 add lrutestkey_0000005143 0 1471172787 512 add lrutestkey_0000005144 0 1471172787 512 ... [root@hadoop1 scripts]# ./memcached-tool localhost:11211 dump |grep add |sort |head -n 10 Dumping memcache contents Number of buckets: 1 Number of items : 7530 Dumping bucket 10 - 7530 total items add lrutestkey_0000016755 0 1471172903 512 add lrutestkey_0000016760 0 1471172903 512 ... [root@hadoop1 scripts]# ./memcached-tool localhost:11211 dump |grep add |sort |head -n 10 Dumping memcache contents Number of buckets: 1 Number of items : 7530 Dumping bucket 10 - 7530 total items add lrutestkey_0000035102 0 1471173087 512 add lrutestkey_0000035103 0 1471173087 512 add lrutestkey_0000035110 0 1471173087 512 ...
对比这5个片段,dump出最小的键值是越来越大,这说明,随着数据的增加,因为越小的KEY,数据越老,所以优先会被踢出。基本可以说明LRU算法逻辑。
还有一点,要说吗,踢出数据的过程,是按时间点进行的,不是时刻进行的。
3.监控slab参数
3,1 插入了100条数据,监控结果
[root@hadoop1 scripts]# echo stats slabs | nc 127.0.0.1 11211 STAT 10:chunk_size 696 STAT 10:chunks_per_page 1506 STAT 10:total_pages 1 STAT 10:total_chunks 1506 STAT 10:used_chunks 100 STAT 10:free_chunks 1406 STAT 10:free_chunks_end 0 STAT 10:mem_requested 58400 STAT 10:get_hits 0 STAT 10:cmd_set 100 STAT 10:delete_hits 0 STAT 10:incr_hits 0 STAT 10:decr_hits 0 STAT 10:cas_hits 0 STAT 10:cas_badval 0 STAT 10:touch_hits 0 STAT active_slabs 1 STAT total_malloced 1048176 END
3.2 调用memcached-tool dump数据
[root@hadoop1 scripts]# ./memcached-tool localhost:11211 dump |grep add |sort |head -n 10 Dumping memcache contents Number of buckets: 1 Number of items : 100 Dumping bucket 10 - 100 total items add lrutestkey_0000000000 0 1471173457 512 ...
3.3 stats slabs监控结果
[hadoop@hadoop1 ~]$ echo stats slabs | nc 127.0.0.1 11211 STAT 10:chunk_size 696 STAT 10:chunks_per_page 1506 STAT 10:total_pages 1 STAT 10:total_chunks 1506 STAT 10:used_chunks 100 STAT 10:free_chunks 1406 STAT 10:free_chunks_end 0 STAT 10:mem_requested 58400 STAT 10:get_hits 100 STAT 10:cmd_set 100 STAT 10:delete_hits 0 STAT 10:incr_hits 0 STAT 10:decr_hits 0 STAT 10:cas_hits 0 STAT 10:cas_badval 0 STAT 10:touch_hits 0 STAT active_slabs 1 STAT total_malloced 1048176 END
结果
memcached-tool 引起了get_hits 的从原来的0变成100;由于,批量添加的100条数据值均是512字节长度。 加上item的长度32,等于544. 再加上key的长度21, 一共是563.
所以会放到slab class 10() chunk size 696 ),而不是放到slab class 9(chunk size 552)。
3.4 memcached-tool监控
3.4.1准备测试数据
public void test111() throws ExecutionException, InterruptedException {
final MemcachedClient mcc = MemcachedUtil.getSpyMemcachedClient();
final Lock lock = new ReentrantLock();
Thread t1= new Thread(new Runnable() {
@Override
public void run() {
for(int i=0;i<1000;i++){
// System.out.println("i="+i);
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
String key = "lrutestkey_"+StringUtils.leftPad(""+i,10,"0");
int size =new Random().nextInt(1000);
String value = RandomStringUtils.randomAlphanumeric(size);
mcc.set(key, 19000, value);
System.out.println(key+"-->"+value);
}
}
},"setting data");
t1.start();
t1.join();
mcc.shutdown();
}3.4.2 运行memcached-tool命令
[hadoop@hadoop1 scripts]$ ./memcached-tool localhost:11211 # Item_Size Max_age Pages Count Full? Evicted Evict_Time OOM 1 80B 23s 1 10 yes 0 0 0 2 104B 23s 1 26 yes 0 0 0 3 136B 24s 1 30 yes 0 0 0 4 176B 22s 1 37 yes 0 0 0 5 224B 24s 1 47 yes 0 0 0 6 280B 24s 1 50 yes 0 0 0 7 352B 24s 1 72 yes 0 0 0 8 440B 24s 1 93 yes 0 0 0 9 552B 24s 1 91 yes 0 0 0 10 696B 24s 1 142 yes 0 0 0 11 872B 24s 1 174 yes 0 0 0 12 1.1K 24s 1 228 yes 0 0 0 [hadoop@hadoop1 scripts]$ ./memcached-tool localhost:11211 display # Item_Size Max_age Pages Count Full? Evicted Evict_Time OOM 1 80B 361s 1 10 yes 0 0 0 2 104B 361s 1 26 yes 0 0 0 3 136B 362s 1 30 yes 0 0 0 4 176B 360s 1 37 yes 0 0 0 5 224B 362s 1 47 yes 0 0 0 6 280B 362s 1 50 yes 0 0 0 7 352B 362s 1 72 yes 0 0 0 8 440B 362s 1 93 yes 0 0 0 9 552B 362s 1 91 yes 0 0 0 10 696B 362s 1 142 yes 0 0 0 11 872B 362s 1 174 yes 0 0 0 12 1.1K 362s 1 228 yes 0 0 0
可以很清楚数据分布情况,把所有的Count列值求和,正好是1000.
当然用 echo stats slabs | nc 127.0.0.1 11211 |grep used_chunks命令也可以,片段如下
[hadoop@hadoop1 scripts]$ echo stats slabs | nc 127.0.0.1 11211 |grep used_chunks STAT 1:used_chunks 10 STAT 2:used_chunks 26 STAT 3:used_chunks 30 STAT 4:used_chunks 37 STAT 5:used_chunks 47 STAT 6:used_chunks 50 STAT 7:used_chunks 72 STAT 8:used_chunks 93 STAT 9:used_chunks 91 STAT 10:used_chunks 142 STAT 11:used_chunks 174 STAT 12:used_chunks 228
./memcached-tool localhost:11211 stats 与 echo stats | nc 127.0.0.1 11211 |sort命令类似
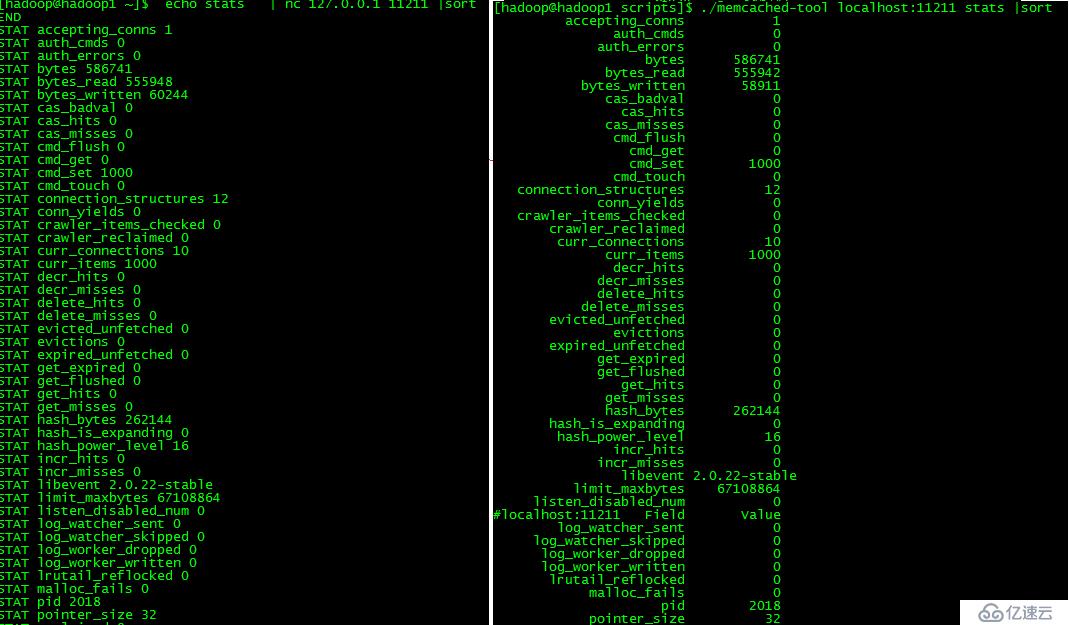
每个指标的含义,网上资料有很多了,而且通过名称也能猜出个所以然了。
4.验证一些边界数据
1. 如果key超过250,报错信息
java.lang.IllegalArgumentException: Key is too long (maxlen = 250)
2. 可以往memcached存储该对象。new byte[100*1024*1024]。明显超过1M了,搞不太清楚。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





