жҖҺд№ҲзҗҶи§ЈNode.jsдёӯзҡ„BufferжЁЎеқ—
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңжҖҺд№ҲзҗҶи§ЈNode.jsдёӯзҡ„BufferжЁЎеқ—вҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңжҖҺд№ҲзҗҶи§ЈNode.jsдёӯзҡ„BufferжЁЎеқ—вҖқеҗ§пјҒ

зҗҶи§ЈBuffer
JavaScriptеҜ№дәҺеӯ—з¬ҰдёІзҡ„ж“ҚдҪңеҚҒеҲҶеҸӢеҘҪ
BufferжҳҜдёҖдёӘеғҸArrayзҡ„еҜ№иұЎпјҢдё»иҰҒз”ЁдәҺж“ҚдҪңеӯ—иҠӮгҖӮ
Bufferз»“жһ„
BufferжҳҜдёҖдёӘе…ёеһӢзҡ„JavaScriptе’ҢC++з»“еҗҲзҡ„жЁЎеқ—пјҢе°ҶжҖ§иғҪзӣёе…ійғЁеҲҶз”ЁC++е®һзҺ°пјҢе°ҶйқһжҖ§иғҪзӣёе…ійғЁеҲҶз”ЁJavaScriptе®һзҺ°гҖӮ
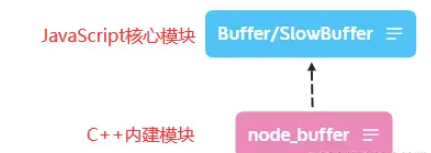
BufferжүҖеҚ з”Ёзҡ„еҶ…еӯҳдёҚжҳҜйҖҡиҝҮV8еҲҶй…ҚпјҢеұһдәҺе ҶеӨ–еҶ…еӯҳгҖӮ з”ұдәҺV8еһғеңҫеӣһ收жҖ§иғҪеҪұе“ҚпјҢе°Ҷеёёз”Ёзҡ„ж“ҚдҪңеҜ№иұЎз”Ёжӣҙй«ҳж•Ҳе’Ңдё“жңүзҡ„еҶ…еӯҳеҲҶй…Қеӣһ收ж”ҝзӯ–жқҘз®ЎзҗҶжҳҜдёӘдёҚй”ҷзҡ„жҖқи·ҜгҖӮ
BufferеңЁNodeиҝӣзЁӢеҗҜеҠЁж—¶е°ұе·Із»Ҹд»·еҖјпјҢ并且ж”ҫеңЁе…ЁеұҖеҜ№иұЎпјҲglobalпјүдёҠгҖӮжүҖд»ҘдҪҝз”Ёbufferж— йңҖrequireеј•е…Ҙ
BufferеҜ№иұЎ
BufferеҜ№иұЎзҡ„е…ғзҙ жңӘ16иҝӣеҲ¶зҡ„дёӨдҪҚж•°пјҢеҚі0-255зҡ„ж•°еҖј
let buf01 = Buffer.alloc(8);
console.log(buf01); // <Buffer 00 00 00 00 00 00 00 00>
еҸҜд»ҘдҪҝз”ЁfillеЎ«е……bufзҡ„еҖј(й»ҳи®Өдёәutf-8зј–з Ғ)пјҢеҰӮжһңеЎ«е……зҡ„еҖји¶…иҝҮbufferпјҢе°ҶдёҚдјҡиў«еҶҷе…ҘгҖӮ
еҰӮжһңbufferй•ҝеәҰеӨ§дәҺеҶ…е®№пјҢеҲҷдјҡеҸҚеӨҚеЎ«е……
еҰӮжһңжғіиҰҒжё…з©әд№ӢеүҚеЎ«е……зҡ„еҶ…е®№пјҢеҸҜд»ҘзӣҙжҺҘfill()
buf01.fill('12345678910')
console.log(buf01); // <Buffer 31 32 33 34 35 36 37 38>
console.log(buf01.toString()); // 12345678еҰӮжһңеЎ«е…Ҙзҡ„еҶ…е®№жҳҜдёӯж–ҮпјҢеңЁutf-8зҡ„еҪұе“ҚдёӢпјҢдёӯж–Үеӯ—дјҡеҚ з”Ё3дёӘе…ғзҙ пјҢеӯ—жҜҚе’ҢеҚҠи§’ж ҮзӮ№з¬ҰеҸ·еҚ з”Ё1дёӘе…ғзҙ гҖӮ
let buf02 = Buffer.alloc(18, 'ејҖе§ӢжҲ‘们зҡ„ж–°и·ҜзЁӢ', 'utf-8');
console.log(buf02.toString()); // ејҖе§ӢжҲ‘们зҡ„ж–°
BufferеҸ—Arrayзұ»еһӢеҪұе“ҚеҫҲеӨ§пјҢеҸҜд»Ҙи®ҝй—®lengthеұһжҖ§еҫ—еҲ°й•ҝеәҰпјҢд№ҹеҸҜд»ҘйҖҡиҝҮдёӢж Үи®ҝй—®е…ғзҙ пјҢд№ҹеҸҜд»ҘйҖҡиҝҮindexOfжҹҘзңӢе…ғзҙ дҪҚзҪ®гҖӮ
console.log(buf02); // <Buffer e5 bc 80 e5 a7 8b e6 88 91 e4 bb ac e7 9a 84 e6 96 b0>
console.log(buf02.length) // 18еӯ—иҠӮ
console.log(buf02[6]) // 230пјҡ e6 иҪ¬жҚўеҗҺе°ұжҳҜ 230
console.log(buf02.indexOf('жҲ‘')) // 6пјҡеңЁз¬¬7дёӘеӯ—иҠӮдҪҚзҪ®
console.log(buf02.slice(6, 9).toString()) // жҲ‘: еҸ–еҫ—<Buffer e6 88 91>пјҢиҪ¬жҚўеҗҺе°ұжҳҜ'жҲ‘'еҰӮжһңз»ҷеӯ—иҠӮиөӢеҖјдёҚжҳҜ0255д№Ӣй—ҙзҡ„ж•ҙж•°пјҢжҲ–иҖ…иөӢеҖјж—¶е°Ҹж•°ж—¶пјҢиөӢеҖје°ҸдәҺ0пјҢе°ҶиҜҘеҖјйҖҗж¬ЎеҠ 256.зӣҙеҲ°еҫ—еҲ°0255д№Ӣй—ҙзҡ„ж•ҙж•°гҖӮеҰӮжһңеӨ§дәҺ255пјҢе°ұйҖҗж¬ЎеҮҸеҺ»255гҖӮ еҰӮжһңжҳҜе°Ҹж•°пјҢиҲҚеҺ»е°Ҹж•°йғЁеҲҶ(дёҚеҒҡеӣӣиҲҚдә”е…Ҙ)
BufferеҶ…еӯҳеҲҶй…Қ
BufferеҜ№иұЎзҡ„еҶ…еӯҳеҲҶй…ҚдёҚжҳҜеңЁV8зҡ„е ҶеҶ…еӯҳдёӯпјҢиҖҢжҳҜеңЁNodeзҡ„C++еұӮйқўе®һзҺ°еҶ…еӯҳзҡ„з”іиҜ·гҖӮ еӣ дёәеӨ„зҗҶеӨ§йҮҸзҡ„еӯ—иҠӮж•°жҚ®дёҚиғҪйҮҮз”ЁйңҖиҰҒдёҖзӮ№еҶ…еӯҳе°ұеҗ‘ж“ҚдҪңзі»з»ҹз”іиҜ·дёҖзӮ№еҶ…еӯҳзҡ„ж–№ејҸгҖӮдёәжӯӨNodeеңЁеҶ…еӯҳдёҠдҪҝз”Ёзҡ„жҳҜеңЁC++еұӮйқўз”іиҜ·еҶ…еӯҳпјҢеңЁJavaScriptдёӯеҲҶй…ҚеҶ…еӯҳзҡ„ж–№ејҸ
NodeйҮҮз”ЁдәҶslabеҲҶй…ҚжңәеҲ¶пјҢslabжҳҜд»ҘдёӯеҠЁжҖҒеҶ…еӯҳз®ЎзҗҶжңәеҲ¶пјҢзӣ®еүҚеңЁдёҖдәӣ*nixж“ҚдҪңзі»з»ҹз”Ёдёӯжңүе№ҝжіӣзҡ„еә”з”ЁпјҢжҜ”еҰӮLinux
slabе°ұжҳҜдёҖеқ—з”іиҜ·еҘҪзҡ„еӣәе®ҡеӨ§е°Ҹзҡ„еҶ…еӯҳеҢәеҹҹпјҢslabе…·жңүд»ҘдёӢдёүз§ҚзҠ¶жҖҒпјҡ
fullпјҡе®Ңе…ЁеҲҶй…ҚзҠ¶жҖҒ
partialпјҡйғЁеҲҶеҲҶй…ҚзҠ¶жҖҒ
emptyпјҡжІЎжңүиў«еҲҶй…ҚзҠ¶жҖҒ
Nodeд»Ҙ8KBдёәз•ҢйҷҗжқҘеҢәеҲҶBufferжҳҜеӨ§еҜ№иұЎиҝҳжҳҜе°ҸеҜ№иұЎ
console.log(Buffer.poolSize); // 8192
иҝҷдёӘ8KBзҡ„еҖје°ұйўқжҳҜжҜҸдёӘslabзҡ„еӨ§е°ҸеҖјпјҢеңЁJavaScriptеұӮйқўпјҢд»Ҙе®ғдҪңдёәеҚ•дҪҚеҚ•е…ғиҝӣиЎҢеҶ…еӯҳзҡ„еҲҶй…Қ
еҲҶй…Қе°ҸbufferеҜ№иұЎ
еҰӮжһңжҢҮе®ҡBufferеӨ§е°Ҹе°ҸдәҺ8KBпјҢNodeдјҡжҢүз…§е°ҸеҜ№иұЎж–№ејҸиҝӣиЎҢеҲҶй…Қ
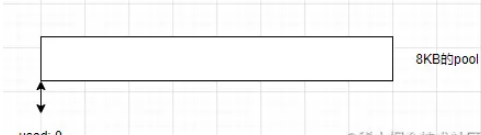
жһ„йҖ дёҖдёӘж–°зҡ„slabеҚ•е…ғпјҢзӣ®еүҚslabеӨ„дәҺemptyз©әзҠ¶жҖҒ
жһ„йҖ е°ҸbufferеҜ№иұЎ1024KBпјҢеҪ“еүҚзҡ„slabдјҡиў«еҚ з”Ё1024KBпјҢ并且记еҪ•дёӢжҳҜд»ҺиҝҷдёӘslabзҡ„е“ӘдёӘдҪҚзҪ®ејҖе§ӢдҪҝз”Ёзҡ„

иҝҷж—¶еҶҚеҲӣе»әдёҖдёӘbufferеҜ№иұЎпјҢеӨ§е°Ҹдёә3072KBгҖӮ жһ„йҖ иҝҮзЁӢдјҡеҲӨж–ӯеҪ“еүҚslabеү©дҪҷз©әй—ҙжҳҜеҗҰи¶іеӨҹпјҢеҰӮжһңи¶іеӨҹпјҢдҪҝз”Ёеү©дҪҷз©әй—ҙпјҢ并жӣҙж–°slabзҡ„еҲҶй…ҚзҠ¶жҖҒгҖӮ 3072KBз©әй—ҙиў«дҪҝз”ЁеҗҺпјҢзӣ®еүҚжӯӨslabеү©дҪҷз©әй—ҙ4096KBгҖӮ
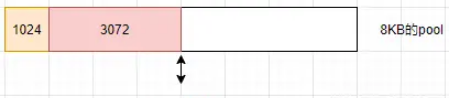
еҰӮжһңжӯӨж—¶еҲӣе»әдёҖдёӘ6144KBеӨ§е°Ҹзҡ„bufferпјҢеҪ“еүҚslabз©әй—ҙдёҚи¶іпјҢдјҡжһ„йҖ ж–°зҡ„slabпјҲиҝҷдјҡйҖ жҲҗеҺҹslabеү©дҪҷз©әй—ҙжөӘиҙ№пјү

жҜ”еҰӮдёӢйқўзҡ„дҫӢеӯҗдёӯпјҡ
Buffer.alloc(1)
Buffer.alloc(8192)
第дёҖдёӘslabдёӯеҸӘдјҡеӯҳеңЁ1еӯ—иҠӮзҡ„bufferеҜ№иұЎпјҢиҖҢеҗҺдёҖдёӘbufferеҜ№иұЎдјҡжһ„е»әдёҖдёӘж–°зҡ„slabеӯҳж”ҫ
з”ұдәҺдёҖдёӘslabеҸҜиғҪеҲҶй…Қз»ҷеӨҡдёӘBufferеҜ№иұЎдҪҝз”ЁпјҢеҸӘжңүиҝҷдәӣе°ҸbufferеҜ№иұЎеңЁдҪңз”ЁеҹҹйҮҠж”ҫ并йғҪеҸҜд»Ҙеӣһ收时пјҢslabзҡ„з©әй—ҙжүҚдјҡиў«еӣһ收гҖӮ е°Ҫз®ЎеҸӘеҲӣе»ә1еӯ—иҠӮзҡ„bufferеҜ№иұЎпјҢдҪҶжҳҜеҰӮжһңдёҚйҮҠж”ҫпјҢе®һйҷ…жҳҜ8KBзҡ„еҶ…еӯҳйғҪжІЎжңүйҮҠж”ҫ
е°Ҹз»“пјҡ
зңҹжӯЈзҡ„еҶ…еӯҳжҳҜеңЁNodeзҡ„C++еұӮйқўжҸҗдҫӣпјҢJavaScriptеұӮйқўеҸӘжҳҜдҪҝз”ЁгҖӮеҪ“иҝӣиЎҢе°ҸиҖҢйў‘з№Ғзҡ„Bufferж“ҚдҪңж—¶пјҢйҮҮз”Ёslabзҡ„жңәеҲ¶иҝӣиЎҢйў„е…Ҳз”іиҜ·е’Ңж—¶еҖҷеҲҶй…ҚпјҢдҪҝеҫ—JavaScriptеҲ°ж“ҚдҪңзі»з»ҹд№Ӣй—ҙдёҚеҝ…жңүиҝҮеӨҡзҡ„еҶ…еӯҳз”іиҜ·ж–№йқўзҡ„зі»з»ҹи°ғз”ЁгҖӮ еҜ№дәҺеӨ§еқ—зҡ„bufferпјҢзӣҙжҺҘдҪҝз”ЁC++еұӮйқўжҸҗдҫӣзҡ„еҶ…еӯҳеҚіеҸҜпјҢж— йңҖз»Ҷи…»зҡ„еҲҶй…Қж“ҚдҪңгҖӮ
Bufferзҡ„жӢјжҺҘ
bufferеңЁдҪҝз”ЁеңәжҷҜдёӯпјҢйҖҡеёёжҳҜд»ҘдёҖж®өж®өзҡ„ж–№ејҸиҝӣиЎҢдј иҫ“гҖӮ
const fs = require('fs');
let rs = fs.createReadStream('./йқҷеӨңжҖқ.txt', { flags:'r'});
let str = ''
rs.on('data', (chunk)=>{
str += chunk;
})
rs.on('end', ()=>{
console.log(str);
})д»ҘдёҠжҳҜиҜ»еҸ–жөҒзҡ„иҢғдҫӢпјҢdataж—¶й—ҙдёӯиҺ·еҸ–еҲ°зҡ„chunkеҜ№иұЎе°ұжҳҜbufferеҜ№иұЎгҖӮ
дҪҶжҳҜеҪ“иҫ“е…ҘжөҒдёӯжңүе®Ҫеӯ—иҠӮзј–з ҒпјҲдёҖдёӘеӯ—еҚ еӨҡдёӘеӯ—иҠӮпјүж—¶пјҢй—®йўҳе°ұдјҡжҡҙйңІгҖӮеңЁstr += chunkдёӯйҡҗи—ҸдәҶtoString()ж“ҚдҪңгҖӮзӯүд»·дәҺstr = str.toString() + chunk.toString()гҖӮ
дёӢйқўе°ҶеҸҜиҜ»жөҒзҡ„жҜҸж¬ЎиҜ»еҸ–bufferй•ҝеәҰйҷҗеҲ¶дёә11.
fs.createReadStream('./йқҷеӨңжҖқ.txt', { flags:'r', highWaterMark: 11});иҫ“еҮәеҫ—еҲ°пјҡ
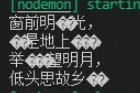
дёҠйқўеҮәзҺ°дәҶд№ұз ҒпјҢдёҠйқўйҷҗеҲ¶дәҶbufferй•ҝеәҰдёә11пјҢеҜ№дәҺд»»ж„Ҹй•ҝеәҰзҡ„bufferиҖҢиЁҖпјҢе®Ҫеӯ—иҠӮеӯ—з¬ҰдёІйғҪжңүеҸҜиғҪеӯҳеңЁиў«жҲӘж–ӯзҡ„жғ…еҶөпјҢеҸӘдёҚиҝҮbufferи¶Ҡй•ҝеҮәзҺ°жҰӮзҺҮи¶ҠдҪҺгҖӮ
encoding
дҪҶжҳҜеҰӮжһңи®ҫзҪ®дәҶencodingдёәutf-8пјҢе°ұдёҚдјҡеҮәзҺ°жӯӨй—®йўҳдәҶгҖӮ
fs.createReadStream('./йқҷеӨңжҖқ.txt', { flags:'r', highWaterMark: 11, encoding:'utf-8'});
еҺҹеӣ пјҡ иҷҪз„¶ж— и®әжҖҺд№Ҳи®ҫзҪ®зј–з ҒпјҢжөҒзҡ„и§ҰеҸ‘ж¬Ўж•°йғҪжҳҜдёҖж ·пјҢдҪҶжҳҜеңЁи°ғз”ЁsetEncodingж—¶пјҢеҸҜиҜ»жөҒеҜ№иұЎеңЁеҶ…йғЁи®ҫзҪ®дәҶдёҖдёӘdecoderеҜ№иұЎгҖӮжҜҸж¬ЎdataдәӢ件йғҪдјҡйҖҡиҝҮdecoderеҜ№иұЎиҝӣиЎҢbufferеҲ°еӯ—з¬ҰдёІзҡ„и§Јз ҒпјҢ然еҗҺдј йҖ’з»ҷи°ғз”ЁиҖ…гҖӮ
string_decoder жЁЎеқ—жҸҗдҫӣдәҶз”ЁдәҺе°Ҷ Buffer еҜ№иұЎи§Јз Ғдёәеӯ—з¬ҰдёІпјҲд»Ҙдҝқз•ҷзј–з Ғзҡ„еӨҡеӯ—иҠӮ UTF-8 е’Ң UTF-16 еӯ—з¬Ұзҡ„ж–№ејҸпјүзҡ„ API
const { StringDecoder } = require('string_decoder');
let s1 = Buffer.from([0xe7, 0xaa, 0x97, 0xe5, 0x89, 0x8d, 0xe6, 0x98, 0x8e, 0xe6, 0x9c])
let s2 = Buffer.from([0x88, 0xe5, 0x85, 0x89, 0xef, 0xbc, 0x8c, 0x0d, 0x0a, 0xe7, 0x96])
console.log(s1.toString());
console.log(s2.toString());
console.log('------------------');
const decoder = new StringDecoder('utf8');
console.log(decoder.write(s1));
console.log(decoder.write(s2));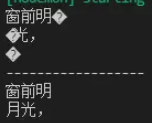
StringDecoderеңЁеҫ—еҲ°зј–з Ғд№ӢеҗҺпјҢзҹҘйҒ“дәҶе®Ҫеӯ—иҠӮеӯ—з¬ҰдёІеңЁutf-8зј–з ҒдёӢжҳҜд»Ҙ3дёӘеӯ—иҠӮзҡ„ж–№ејҸеӯҳеӮЁзҡ„пјҢжүҖд»Ҙ第дёҖж¬Ўdecoder.writeеҸӘдјҡиҫ“еҮәеүҚ9дёӘеӯ—иҠӮиҪ¬з Ғзҡ„еӯ—з¬ҰпјҢеҗҺдёӨдёӘеӯ—иҠӮдјҡиў«дҝқз•ҷеңЁStringDecoderеҶ…йғЁгҖӮ
BufferдёҺжҖ§иғҪ
bufferеңЁж–Ү件I/Oе’ҢзҪ‘з»ңI/Oдёӯиҝҗз”Ёе№ҝжіӣпјҢе°Өе…¶еңЁзҪ‘з»ңдј иҫ“дёӯпјҢжҖ§иғҪдёҫи¶іиҪ»йҮҚгҖӮеңЁеә”з”ЁдёӯпјҢйҖҡеёёдјҡж“ҚдҪңеӯ—з¬ҰдёІпјҢдҪҶжҳҜдёҖж—ҰеңЁзҪ‘з»ңдёӯдј иҫ“пјҢйғҪйңҖиҰҒиҪ¬жҚўжҲҗbufferпјҢд»ҘиҝӣиЎҢдәҢиҝӣеҲ¶ж•°жҚ®дј иҫ“гҖӮ еңЁwebеә”з”ЁдёӯпјҢеӯ—з¬ҰдёІиҪ¬жҚўеҲ°bufferжҳҜж—¶ж—¶еҲ»еҲ»еҸ‘з”ҹзҡ„пјҢжҸҗй«ҳеӯ—з¬ҰдёІеҲ°bufferзҡ„иҪ¬жҚўж•ҲзҺҮпјҢеҸҜд»ҘеҫҲеӨ§зЁӢеәҰең°жҸҗй«ҳзҪ‘з»ңеҗһеҗҗзҺҮгҖӮ
еҰӮжһңйҖҡиҝҮзәҜеӯ—з¬ҰдёІзҡ„ж–№ејҸеҗ‘е®ўжҲ·з«ҜеҸ‘йҖҒпјҢжҖ§иғҪдјҡжҜ”еҸ‘йҖҒbufferеҜ№иұЎжӣҙе·®пјҢеӣ дёәbufferеҜ№иұЎж— йЎ»еңЁжҜҸж¬Ўе“Қеә”ж—¶иҝӣиЎҢиҪ¬жҚўгҖӮйҖҡиҝҮйў„е…ҲиҪ¬жҚўйқҷжҖҒеҶ…е®№дёәbufferеҜ№иұЎпјҢеҸҜд»Ҙжңүж•Ҳең°еҮҸе°‘CPUйҮҚеӨҚдҪҝз”ЁпјҢиҠӮзңҒжңҚеҠЎеҷЁиө„жәҗгҖӮ
еҸҜд»ҘйҖүжӢ©е°ҶйЎөйқўдёӯеҠЁжҖҒе’ҢйқҷжҖҒеҶ…е®№еҲҶзҰ»пјҢйқҷжҖҒеҶ…е®№йғЁеҲҶйў„е…ҲиҪ¬жҚўдёәbufferзҡ„ж–№ејҸпјҢдҪҝеҫ—жҖ§иғҪеҫ—еҲ°жҸҗеҚҮгҖӮ
еңЁж–Ү件зҡ„иҜ»еҸ–ж—¶пјҢhighWaterMarkи®ҫзҪ®еҜ№жҖ§иғҪеҪұе“ҚиҮіе…ійҮҚиҰҒгҖӮеңЁзҗҶжғізҠ¶жҖҒдёӢпјҢжҜҸж¬ЎиҜ»еҸ–зҡ„й•ҝеәҰе°ұжҳҜз”ЁжҲ·жҢҮе®ҡзҡ„highWaterMarkгҖӮ
highWaterMarkеӨ§е°ҸеҜ№жҖ§иғҪжңүдёӨдёӘеҪұе“Қзҡ„зӮ№пјҡ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңжҖҺд№ҲзҗҶи§ЈNode.jsдёӯзҡ„BufferжЁЎеқ—вҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№жҖҺд№ҲзҗҶи§ЈNode.jsдёӯзҡ„BufferжЁЎеқ—иҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ





