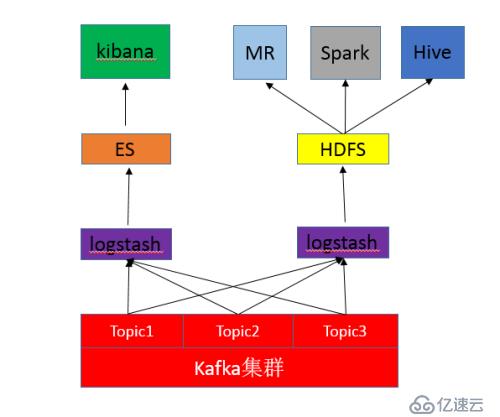
前言:通常情况下,我们将Kafka的日志数据通过logstash订阅输出到ES,然后用Kibana来做可视化分析,这就是我们通常用的ELK日志分析模式。但是基于ELK的日志分析,通常比较常用的是实时分析,日志存个十天半个月都会删掉。那么在一些情况下,我需要将日志数据也存一份到我HDFS,积累到比较久的时间做半年、一年甚至更长时间的大数据分析。下面就来说如何最简单的通过logstash将kafka中的数据订阅一份到hdfs。
一:安装logstash(下载tar包安装也行,我直接yum装了)
#yum install logstash-2.1.1二:从github上克隆代码
#git clone https://github.com/heqin5136/logstash-output-webhdfs-discontinued.git
#ls
logstash-output-webhdfs-discontinued三:安装logstash-output-webhdfs插件
#cd logstash-output-webhdfs-discontinued
logstash的bin目录下有个plugin,使用plugin来安装插件
#/opt/logstash/bin/plugin install logstash-output-webhdfs
四:配置logstash
#vim /etc/logstash/conf.d/logstash.conf
input {
kafka {
zk_connect => '10.10.10.1:2181,10.10.10.2:2181,10.10.10.3:2181' #kafka的zk集群地址
group_id => 'hdfs' #消费者组,不要和ELK上的消费者一样
topic_id => 'apiAppWebCms-topic' #topic
consumer_id => 'logstash-consumer-10.10.8.8' #消费者id,自定义,我写本机ip。
consumer_threads => 1
queue_size => 200
codec => 'json'
}
}
output {
#如果你一个topic中会有好几种日志,可以提取出来分开存储在hdfs上。
if [type] == "apiNginxLog" {
webhdfs {
workers => 2
host => "10.10.8.1" #hdfs的namenode地址
port => 50070 #webhdfs端口
user => "hdfs" #hdfs运行的用户啊,以这个用户的权限去写hdfs。
path => "/data/logstash/apiNginxLog-%{+YYYY}-%{+MM}-%{+dd}/logstash-%{+HH}.log
#按天建目录,按小时建log文件。
flush_size => 500
# compression => "snappy" #压缩格式,可以不压缩
idle_flush_time => 10
retry_interval => 0.5
}
}
if [type] == "apiAppLog" {
webhdfs {
workers => 2
host => "10.64.8.1"
port => 50070
user => "hdfs"
path => "/data/logstash/api/apiAppLog-%{+YYYY}-%{+MM}-%{+dd}.log"
flush_size => 500
# compression => "snappy"
idle_flush_time => 10
retry_interval => 0.5
}
}
stdout { codec => rubydebug }
}
五:启动logstash
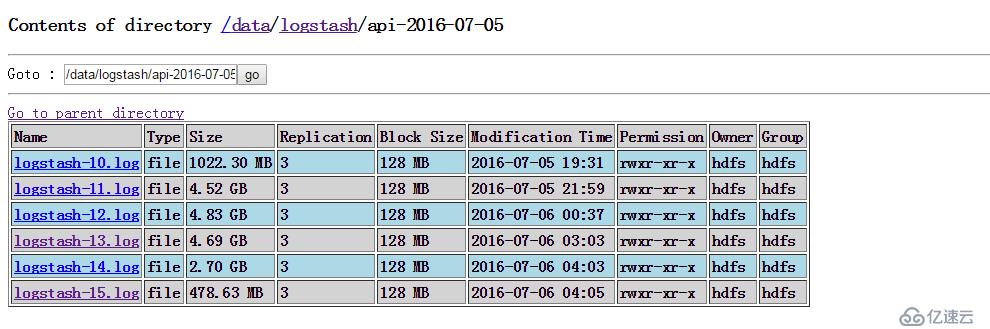
#/etc/init.d/logstash start已经可以成功写入了。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



