这篇文章主要介绍了Hadoop配置信息怎么处理,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
1 配置文件简介
配置文件是一个灵活系统不可缺少的一部分,虽然配置文件非常重要,但却没有标准。
1.1 Java配置文件
JDK提供了java.util.Properties类,用于处理简单的配置文件。Properties很早就被引入到Java的类库中,并且一直没有什么变化。它继承自Hashtable,表示了一个持久的属性集,该集可保存在流中或从流中加载。属性列表中每个键及其对应值都是字符串类型。
public class Properties extends Hashtable<Object,Object> {
……
}Properties处理的配置文件格式非常简单,它只支持键-值对,等号左边为键,右边为值。值。形式如下:
ENTRY=VALUE
java.util.Properties中用于处理属性列表的主要方法如下:
1、getProperty():用于在属性列表中获取指定键(参数key)对应的属性,它有两个形式,一个不提供默认值,另一个可以提供默认值。
2、setProperty():用于在属性列表中设置/更新属性值。
3、load():该方法从输入流中读取键-值对。
4、store():该方法则将Properties表中的属性列表写入输出流。
相关代码如下:
//用指定的键在此属性列表中搜索属性
public String getProperty(String key)
//功能同上,参数defaultValue提供了默认值
public String getProperty(String key, String defaultValue)
//最终调用Hashtable的方法put
public synchronized Object setProperty(String key, String value)使用输入流和输出流,Properties对象不但可以保存在文件中,而且还可以保存在其他支持流的系统中,如Web服务器。J2SE 1.5版本以后,Properties中的数据也可以以XML格式保存,对应的加载和写出方法是loadFromXML()和storeToXML()。
1.2 Java社区提供的配置文件
由于java.util.Properties提供的能力有限,Java社区中出现了大量的配置信息读/写方案,其中比较有名的是Apache Jakarta Commons工具集中提供的Commons Configuration。
Commons Configuration中的PropertiesConfiguration类提供了丰富的访问配置参数的方法。具体特性如下:
1、支持文本、XML配置文件格式。
2、支持加载多个配置文件。
3、支持分层或多级的配置。
4、提供对单值或多值配置参数的基于类型的访问。
应该说,Commons Configuration是一个功能强大的配置文件处理工具。
1.3 Hadoop提供的配置文件
Hadoop没有使用java.util.Properties管理配置文件,也没有使用Apache Jakarta Commons Configuration管理配置文件,而是使用了一套独有的配置文件管理系统,并提供自己的API。
即使用org.apache.hadoop.conf.Configuration处理配置信息。
2 HadoopConfiguration详解
2.1 Hadoop配置文件的格式
Hadoop配置文件采用XML格式,下面是Hadoop配置文件的一个例子:
<?xml version=“1.0”?>
<?xml-stylesheet type="text/xsl"href="configuration.xsl"?>
<configuration>
<property>
<name>io.sort.factor</name>
<value>10</value>
<final>true</final>
<description>The number of ……</description>
</property>
</configuration>Hadoop配置文件的元素含义如下:
1、Hadoop配置文件的根元素是configuration,一般只包含子元素property。
2、每一个property元素就是一个配置项,配置文件不支持分层或分级。
3、每个配置项一般包括配置属性的名称name、值value和一个关于配置项的描述description。
4、元素final和Java中的关键字final类似,意味着这个配置项是“固定不变的”。final一般不出现,但在合并资源的时候,可以防止配置项的值被覆盖。
5、Hadoop配置系统还有一个很重要的功能,就是属性扩展。如配置项dfs.name.dir的值是${hadoop.tmp.dir}/dfs/name,其中,${hadoop.tmp.dir}会使用Configuration中的相应属性值进行扩展。如果hadoop.tmp.dir的值是"data",那么扩展后的dfs.name.dir的值就是"data/dfs/name"。
2.2 Configuration类概述
在Configuration类中,每个属性都是String类型的,但是值类型可能是以下多种类型,包括Java中的基本类型,如boolean(getBoolean)、int(getInt)、long(getLong)、float(getFloat),也可以是其他类型,如String(get)、java.io.File(getFile)、String数组(getStrings)等。
Configuration类还可以合并资源,合并资源是指将多个配置文件合并,产生一个配置。如果有两个配置文件,也就是两个资源,如core-default.xml和core-site.xml,通过Configuration类的loadResources()方法,把它们合并成一个配置。代码如下:
Configurationconf=new Configuration();
conf.addResource("core-default.xml");
conf.addResource("core-site.xml");如果这两个配置资源都包含了相同的配置项,而且前一个资源的配置项没有标记为final,那么,后面的配置将覆盖前面的配置。
如果在第一个资源中某配置项被标记为final,那么,在加载第二个资源的时候,会有警告提示。
使用Configuration类的一般过程是:构造Configuration对象,并通过类的addResource()方法添加需要加载的资源;然后就可以使用get*方法和set*方法访问/设置配置项,资源会在第一次使用的时候自动加载到对象中。
2.3 Configuration的成员变量
首先来看看org.apache.hadoop.conf.Configuration的类图:
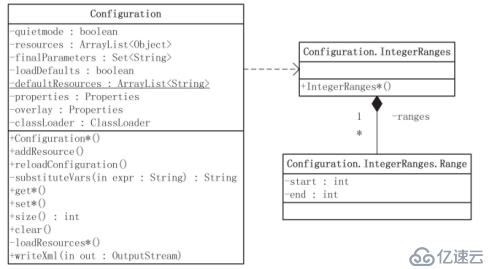
从类图可以看到,Configuration有7个主要的非静态成员变量。
1、quietmode:是布尔变量,用来设置加载配置的模式。如果quietmode为true(默认值),则在加载解析配置文件的过程中,不输出日志信息。该变量只是一个方便开发人员调试的变量。
2、resources:是数组变量,该变量保存了所有通过addResource()方法添加Configuration对象的资源。
3、loadDefaults:布尔变量,用于确定是否加载默认资源,这些默认资源保存在defaultResources中。
注意:defaultResources是个静态成员变量,通过方法addDefaultResource()可以添加系统的默认资源。
在HDFS中,会把hdfs-default.xml和hdfs-site.xml作为默认资源,并通过addDefaultResource()保存在成员变量defaultResources中;
在MapReduce中,默认资源是mapred-default.xml和mapred-site.xml。
4、properties:是java.util.Properties类型,与配置项相关的成员变量。
5、overlay:是java.util.Properties类型的,用于记录通过set()方式改变的配置项。也就是说,出现在overlay中的键-值对是应用设置的,而不是通过对配置资源解析得到的。
6、finalParameters:类型是Set<String>,用来保存所有在配置文件中已经被声明为final的键-值对的键。
提示:
A、Hadoop配置文件解析后的键-值对,都存放在properties中。
B、properties、overlay、finalParameters配置项相关的成员变量
7、classLoader:一个很重要的成员变量,这是一个类加载器变量,可以通过它来加载指定类,也可以通过它加载相关的资源。
了解了Configuration各成员变量的具体含义,Configuration类的其他部分就比较容易理解了,它们都是为了操作这些变量而实现的解析、设置、获取方法。
2.4 Configuration的资源加载
2.4.1 addResource方法
资源通过对象的addResource()方法或类的静态addDefaultResource()方法(设置了loadDefaults标志)添加到Configuration对象中。
addResource方法有4种形式:
addResource(String name)//根据classpath资源加载
addResource(URL url)//根据URL资源加载
addResource(Path file)//根据文件路径对象加载
addResource(InputStream in)//根据一个已经打开的输入流对象加载同时,添加的资源并不会立即加载,只是通过reloadConfiguration()方法清空properties和finalParameters。相关代码如下:
//以classpath资源为例
public void addResource(InputStream in) {
addResourceObject(new Resource(in));
}
private synchronized void addResourceObject(Resource resource) {
resources.add(resource); // 添加到resources成员变量
reloadConfiguration();
}
public synchronized void reloadConfiguration() {
properties = null; // 触发资源的重新加载
finalParameters.clear(); // 清除不改变参数的限制
}
2.4.2 addDefaultResource方法
静态方法addDefaultResource也能清空Configuration对象中的数据(费静态成员变量),这是通过类的静态成员变量REGISTRY作为媒介进行的。
REGISTRY记录了系统中所有的Configuration对象,代码如下:
//静态变量
private static final WeakHashMap<Configuration, Object> REGISTRY = new WeakHashMap<Configuration, Object>();
//记录Configuration对象
public Configuration(boolean loadDefaults) {
this.loadDefaults = loadDefaults;
updatingResource = new ConcurrentHashMap<String, String[]>();
synchronized (Configuration.class) {
REGISTRY.put(this, null);
}
}当addDefaultResource被调用时,遍历REGISTRY的里面的所有的Configuration对象,并在Configuration对象上调用reloadConfiguration方法,这样就可以触发资源的新的加载,相关代码如下:
public static synchronized void addDefaultResource(String name) {
if (!defaultResources.contains(name)) {
defaultResources.add(name);
for (Configuration conf : REGISTRY.keySet()) {
if (conf.loadDefaults) {
conf.reloadConfiguration();
}
}
}
}2.4.3 getProps方法
成员变量properties中的数据,直到需要的时候才会加载进来。在getPrpops方法,如果发现properties为空,将会触发loadResources()方法加载配置资源,这里其实采用了延迟加载的设计模式,当真正需要配置数据的时候,才会开始分析配置文件,这样可以节省系统资源,提高性能。相关代码如下:
protected synchronized Properties getProps() {
if (properties == null) {
properties = new Properties();
Map<String, String[]> backup = new ConcurrentHashMap<String, String[]>(updatingResource);
loadResources(properties, resources, quietmode);
if (overlay != null) {
properties.putAll(overlay);
for (Map.Entry<Object, Object> item : overlay.entrySet()) {
String key = (String) item.getKey();
String[] source = backup.get(key);
if (source != null) {
updatingResource.put(key, source);
}
}
}
}
return properties;
}2.4.4 loadResources方法
Hadoop的配置文件都是XML形式,JAXP,Java API for XML Processing,是一种稳定、可靠的XML处理API处理XML,一般有两种方式
1、SAX,SimpleAPI for XML,提供了一种流式的、事件驱动的XML处理方式,但是编写比较复杂,比较适合处理大的XML文件。
2、DOM,DocumentObject Model,该方式的工作方式是:
A、将XML文档一次性装入内存;
B、根据文档中定义的元素和属性在内存中创建一个树形结构,将文档对象化,文档中的每个节点对应着模型中一个对象。
C、使用对象提供的编程接口,访问XML文档进而操作XML文档。
由于Hadoop的配置文件都是很小文件,因此Configuration对象使用DOM处理XML。
首先分析DOM加载部分的代码:
private Resource loadResource(Properties properties, Resource wrapper, boolean quiet) {
String name = UNKNOWN_RESOURCE;
try {
//得到用于创建DOM解析器的工厂
Object resource = wrapper.getResource();
name = wrapper.getName();
DocumentBuilderFactory docBuilderFactory = DocumentBuilderFactory.newInstance();
// 忽略XML中的注释
docBuilderFactory.setIgnoringComments(true);
// 提供对XML名称空间的支持
docBuilderFactory.setNamespaceAware(true);
try {
//设置Xinclude处理状态为true,即允许XInclude机制
docBuilderFactory.setXIncludeAware(true);
} catch (UnsupportedOperationException e) {
......
}
//获取解析的XML的DocumentBuilder对象
DocumentBuilder builder = docBuilderFactory.newDocumentBuilder();
Document doc = null;
Element root = null;
boolean returnCachedProperties = false;
//根据不同资源,做预处理病调用相应形式的
if (resource instanceof URL) {
//URL资源形式
......
} else if (resource instanceof String) {
//classpath资源形式
......
} else if (resource instanceof Path) {
//hadoop的PATH资源形式
......
} else if (resource instanceof InputStream) {
//输入流的资源形式
......
} else if (resource instanceof Properties) {
//键值对的资源形式
......
} else if (resource instanceof Element) {
//处理configuration对象的子元素
root = (Element) resource;
}
.......一般的JAXP处理都是从工厂开始,通过调用DocumentBuilderFactory的newInstance方法,获得创建DOM解析器的工厂。这里并没有创建出DOM解析器,只是获得一个用于创建DOM解析器的工厂,接下来需要上述newInstance方法得到的DocumentBuilder对象进行一些设置,才能进一步通过DocumentBuilder,得到DOM解析器对象builder。
针对DocumentBuilder对象进行的主要设置包括:
A、忽略XML文档中的注释
B、支持XML空间
C、支持XML的包含机制。
Xinclude机制允许将XML文档分解为多个可管理的块,然后将一个或者多个较小的文档组装成一个大型文档。也就是说,hadoop的一个配置文件中,可以利用XInclude机制将其他配置文件包含进来一并处理。例子如下:
<configuration>
<xi:include href=’ssd.xml’>
</configuration>通过XInclude机制,将引用的xml文件嵌入到当前配置文件,这种方法更有利于对配置文件进行模块化管理,同时就不需要在使用addResource方法再重新加载引用的xml文件。
设置完DocumentBuilderFactory对象以后,通过
DocumentBuilderFactory.newDocumentBuilder获得了DocumentBuilder对象,用于从各种输入解析XML。
在loadResource中,需要根据Configuration对象支持的4种资源分别进行处理,不过这4种情况最终调用DocumentBuilder.parse()函数,返回一个DOM解析结果。
如果输入时一个DOM的子元素,那么将解析结果设置为输入元素。这是为了处理下面出现的元素Configuration包含Configuration子节点的特殊情况。
成员函数loadResource的第二部分代码,就是根据DOM的解析结果设置成Configuration的成员变量properties和finalParameters。
在确认XML的根节点是configuration以后,获取根节点的所有子节点并对所有子节点进行处理。这里需要注意,元素configuration的子节点可以是configuration,也可以是properties。如果是configuration,则递归调用loadResource方法,在loadResource方法的处理过程中,子节点会被作为根节点得到继续的处理。
如果是property子节点,那么试图获取property的子元素name、value和final。在成功获得name和value的值后,根据情况后设置对象的成员变量propertis和finalParameters。相关代码如下:
if (root == null) {
if (doc == null) {
if (quiet) {
return null;
}
throw new RuntimeException(resource + " not found");
}
//根节点应该是configuration
root = doc.getDocumentElement();
}
Properties toAddTo = properties;
if (returnCachedProperties) {
toAddTo = new Properties();
}
if (!"configuration".equals(root.getTagName()))
LOG.fatal("bad conf file: top-level element not <configuration>");
//获取根节点的所有子节点
NodeList props = root.getChildNodes();
DeprecationContext deprecations = deprecationContext.get();
for (int i = 0; i < props.getLength(); i++) {
Node propNode = props.item(i);
if (!(propNode instanceof Element))
//如果子节点不是Element,忽略
continue;
Element prop = (Element) propNode;
if ("configuration".equals(prop.getTagName())) {
//如果是子节点是configuration,递归调用loadResource进行处理,
//这意味着configuration的子节点是configuration
loadResource(toAddTo, new Resource(prop, name), quiet);
continue;
}
//子节点是property
if (!"property".equals(prop.getTagName()))
LOG.warn("bad conf file: element not <property>");
NodeList fields = prop.getChildNodes();
String attr = null;
String value = null;
boolean finalParameter = false;
LinkedList<String> source = new LinkedList<String>();
//查找name、value和final的值
for (int j = 0; j < fields.getLength(); j++) {
Node fieldNode = fields.item(j);
if (!(fieldNode instanceof Element))
continue;
Element field = (Element) fieldNode;
if ("name".equals(field.getTagName()) && field.hasChildNodes())
attr = StringInterner.weakIntern(((Text) field.getFirstChild()).getData().trim());
if ("value".equals(field.getTagName()) && field.hasChildNodes())
value = StringInterner.weakIntern(((Text) field.getFirstChild()).getData());
if ("final".equals(field.getTagName()) && field.hasChildNodes())
finalParameter = "true".equals(((Text) field.getFirstChild()).getData());
if ("source".equals(field.getTagName()) && field.hasChildNodes())
source.add(StringInterner.weakIntern(((Text) field.getFirstChild()).getData()));
}
source.add(name);
......2.4.5 get*方法
get*一共代表21个方法,它们用于在configuration对象中获取相应的配置信息。
这些配置信息可以是boolean、int、long等基本类型,也可以是其他一些hadoop常用类型,如类的信息ClassName、Classes、Class,String数组StringCollection、Strings,URL等。这些方法里最重要的是get()方法,它根据配置项的键获取对应的值,如果键不存在,则返回默认值defaultValue。其他的方法都会依赖于get()方法,并在get()的基础上做进步一处理。先关代码如下:
public String get(String name) {
String[] names = handleDeprecation(deprecationContext.get(), name);
String result = null;
for (String n : names) {
result = substituteVars(getProps().getProperty(n));
}
return result;
}get原生方法会调用Configuration的私有方法substitutevars方法,该方法会完成配置的属性扩展。
属性扩展是指配置项的值包含${key}这种格式的变量,这些变量会被自动替换成相应的值。也就是说${key}会被替换成以key为键的配置项的值。
注意,如果${key}替换后,得到的配置项值仍然包含变量,这个过程会继续进行,知道替换后的值中不再出现变量为止。
最后一点需要注意的是,subsititute中进行的属性扩展,不但可以使用保存在Configuration对象的键值对,而且还可以使用java虚拟的系统属性。属性扩展优先使用系统属性,然后才是Configuration对象中保存的键值对。但是为了防止属性扩展的获取的死循环,故而循环20次后就终止获取,20次后还没有获取到值的话,将抛出异常。
2.4.6 set*方法
相对get*来说,set*的大多数方法都很简单,这些方法相对输入进行类型转换等处理后,最终都调用了set()方法,这个方法简单调用了成员变量properties和overlay的setroperty方法,保存传入的键值对。代码如下:
public void set(String name, String value, String source) {
//预检查参数
Preconditions.checkArgument(name != null, "Property name must not be null");
Preconditions.checkArgument(value != null, "The value of property " + name + " must not be null");
name = name.trim();
DeprecationContext deprecations = deprecationContext.get();
if (deprecations.getDeprecatedKeyMap().isEmpty()) {
//加载资源
getProps();
}
getOverlay().setProperty(name, value);
getProps().setProperty(name, value);
String newSource = (source == null ? "programatically" : source);
if (!isDeprecated(name)) {
updatingResource.put(name, new String[] { newSource });
String[] altNames = getAlternativeNames(name);
if (altNames != null) {
for (String n : altNames) {
if (!n.equals(name)) {
getOverlay().setProperty(n, value);
getProps().setProperty(n, value);
updatingResource.put(n, new String[] { newSource });
}
}
}
} else {
String[] names = handleDeprecation(deprecationContext.get(), name);
String altSource = "because " + name + " is deprecated";
for (String n : names) {
getOverlay().setProperty(n, value);
getProps().setProperty(n, value);
updatingResource.put(n, new String[] { altSource });
}
}
}3 Configurable接口
Configurable是一个很简单的接口,也位于org.apache.hadoop.conf包中。类图如下:

在字面理解,Configurable的含义是可配置的,如果是一个类实现了Configurable接口,意味着这个类是可配置的,也就是说,可以通过这类的一个Configuration实例,提供对象需要的一些配置信息。Hadoop的代码中有大量的实现了Coonfigurable接口,如
org.apache.hadoop.mapred.SequenceFileInputFilter.RegexFilter。
Configurable.setConf方法何时被调用呢?一般来说,对象创建以后,就应该使用setConf方法,为对象提供进一步的初始化工作。为了简化创建和调用setConf方法这两个连续的步骤:
org.apache.hadoop.util.ReflectionUtils中提供了静态方法
newInstance方法,该方法利用java反射机制,根据对象类型信息。创建一个新的相应类型的对象,然后调用ReflectionUtils中的另一个静态方法setConf配置对象。
在setConf方法中,如果对象实现了Configurable接口,那么对象的setConf方法会被调用,并根据Configuration 的实例conf进一步初始化对象。
感谢你能够认真阅读完这篇文章,希望小编分享的“Hadoop配置信息怎么处理”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



