requests.gPython用requests.get获取网页内容为空的问题怎么解决,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
下面先来看一个例子:
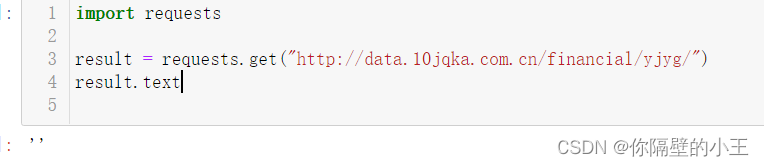
import requests
result=requests.get("http://data.10jqka.com.cn/financial/yjyg/")
result输出结果:
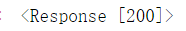
表示成功处理了请求,一般情况下都是返回此状态码; 报200代表没问题
继续运行,发现返回空值,在请求网页爬取的时候,输出的text信息中会出现抱歉,无法访问等字眼,这就是禁止爬取,需要通过反爬机制去解决这个问题。headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据。对反爬虫网页,可以设置一些headers信息,模拟成浏览器取访问网站 。
拿两个常用的浏览器举例:
界面 F12

点击network 键入 CTRL+R

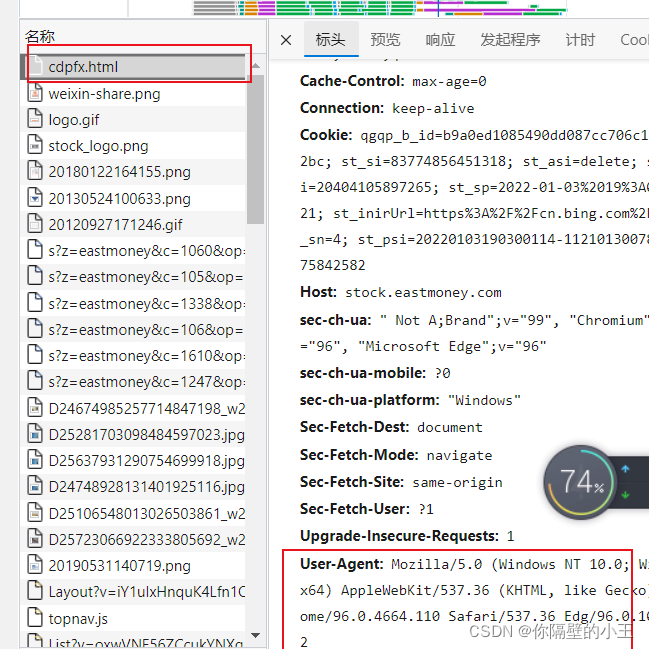
单击第一个 最下边就是我门需要的 把他设置成headers解决问题
同样 F12 打开开发者工具
点击网络,CTRL+R
前文代码修改:
import requests
ur="http://data.10jqka.com.cn/financial/yjyg/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3880.400 QQBrowser/10.8.4554.400 '}
result = requests.get(ur, headers=headers)
result.text成功解决不能爬取问题。
关于requests.gPython用requests.get获取网页内容为空的问题怎么解决问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





