接上篇《 初探IBM大数据处理平台BigInsights(1) 》,本篇讲述Hadoop的一些基础命令及利用MapReduce运行一个简单的WordCount程序
1,在HDFS文件系统上创建test目录
hadoop fs -mkdir /user/biadmin/test
2,将文件copy到test目录下
hadoop fs -put /var/adm/ibmvmcoc-postinstall/BIlicense_en.txt /user/biadmin/test
3,查看test目录下是否多了这个文件
biadmin@bivm:/etc/ibmvmcoc-postinstall> hadoop fs -ls /user/biadmin/test
Found 1 items
-rw-r--r-- 1 biadmin biadmin 62949 2016-01-01 22:34 /user/biadmin/test/BIlicense_en.txt
4,运行一个简单的MapReduce程序
WordCount是用JAVA写的针对Hadoop MapReduce的一个小程序,用于统计文本中每个单词的出现次数,关于WordCount更多内容请参考-http://wiki.apache.org/hadoop/WordCount
执行程序是hadoop-example.jar,内容是在刚刚创建的test目录下,输出到WordCount_outpt子目录中。如果没有此目录,会自动创建。
biadmin@bivm:/etc/ibmvmcoc-postinstall> hadoop jar /opt/ibm/biginsights/IHC/hadoop-example.jar wordcount /user/biadmin/test WordCount_output
16/01/01 22:36:08 INFO input.FileInputFormat: Total input paths to process : 1
16/01/01 22:36:18 INFO mapred.JobClient: Running job: job_201601012120_0001
16/01/01 22:36:19 INFO mapred.JobClient: map 0% reduce 0%
16/01/01 22:37:58 INFO mapred.JobClient: map 100% reduce 0%
16/01/01 22:39:07 INFO mapred.JobClient: map 100% reduce 100%
16/01/01 22:39:14 INFO mapred.JobClient: Job complete: job_201601012120_0001
16/01/01 22:39:15 INFO mapred.JobClient: Counters: 29
16/01/01 22:39:15 INFO mapred.JobClient: File System Counters
16/01/01 22:39:15 INFO mapred.JobClient: FILE: BYTES_READ=33219
16/01/01 22:39:15 INFO mapred.JobClient: FILE: BYTES_WRITTEN=419738
16/01/01 22:39:15 INFO mapred.JobClient: HDFS: BYTES_READ=63073
16/01/01 22:39:15 INFO mapred.JobClient: HDFS: BYTES_WRITTEN=24073
16/01/01 22:39:15 INFO mapred.JobClient: org.apache.hadoop.mapreduce.JobCounter
16/01/01 22:39:15 INFO mapred.JobClient: TOTAL_LAUNCHED_MAPS=1
16/01/01 22:39:15 INFO mapred.JobClient: TOTAL_LAUNCHED_REDUCES=1
16/01/01 22:39:15 INFO mapred.JobClient: DATA_LOCAL_MAPS=1
16/01/01 22:39:15 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=95300
16/01/01 22:39:15 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=50249
16/01/01 22:39:15 INFO mapred.JobClient: FALLOW_SLOTS_MILLIS_MAPS=0
16/01/01 22:39:15 INFO mapred.JobClient: FALLOW_SLOTS_MILLIS_REDUCES=0
16/01/01 22:39:15 INFO mapred.JobClient: org.apache.hadoop.mapreduce.TaskCounter
16/01/01 22:39:15 INFO mapred.JobClient: MAP_INPUT_RECORDS=755
16/01/01 22:39:15 INFO mapred.JobClient: MAP_OUTPUT_RECORDS=9865
16/01/01 22:39:15 INFO mapred.JobClient: MAP_OUTPUT_BYTES=102036
16/01/01 22:39:15 INFO mapred.JobClient: MAP_OUTPUT_MATERIALIZED_BYTES=33219
16/01/01 22:39:15 INFO mapred.JobClient: SPLIT_RAW_BYTES=124
16/01/01 22:39:15 INFO mapred.JobClient: COMBINE_INPUT_RECORDS=9865
16/01/01 22:39:15 INFO mapred.JobClient: COMBINE_OUTPUT_RECORDS=2322
16/01/01 22:39:15 INFO mapred.JobClient: REDUCE_INPUT_GROUPS=2322
16/01/01 22:39:15 INFO mapred.JobClient: REDUCE_SHUFFLE_BYTES=33219
16/01/01 22:39:15 INFO mapred.JobClient: REDUCE_INPUT_RECORDS=2322
16/01/01 22:39:15 INFO mapred.JobClient: REDUCE_OUTPUT_RECORDS=2322
16/01/01 22:39:15 INFO mapred.JobClient: SPILLED_RECORDS=4644
16/01/01 22:39:15 INFO mapred.JobClient: CPU_MILLISECONDS=22130
16/01/01 22:39:15 INFO mapred.JobClient: PHYSICAL_MEMORY_BYTES=538050560
16/01/01 22:39:15 INFO mapred.JobClient: VIRTUAL_MEMORY_BYTES=3549384704
16/01/01 22:39:15 INFO mapred.JobClient: COMMITTED_HEAP_BYTES=2097152000
16/01/01 22:39:15 INFO mapred.JobClient: File Input Format Counters
16/01/01 22:39:15 INFO mapred.JobClient: Bytes Read=62949
16/01/01 22:39:15 INFO mapred.JobClient: org.apache.hadoop.mapreduce.lib.output.FileOutputFormat$Counter
16/01/01 22:39:15 INFO mapred.JobClient: BYTES_WRITTEN=24073
会自动创建WordCount_output目录
biadmin@bivm:/etc/ibmvmcoc-postinstall> hadoop fs -ls WordCount_output
Found 3 items
-rw-r--r-- 1 biadmin biadmin 0 2016-01-01 22:39 WordCount_output/_SUCCESS
drwx--x--x - biadmin biadmin 0 2016-01-01 22:36 WordCount_output/_logs
-rw-r--r-- 1 biadmin biadmin 24073 2016-01-01 22:39 WordCount_output/part-r-00000
biadmin@bivm:~> hadoop fs -cat WordCount_output/*00
names, 1
national 1
nature 1
necessary 4
negligence 5
negligence, 4
negligence. 1
negligence; 2
neither 3
net 1
上面是用命令行方式来MapReduce,除此之外,IBM BigInsights还提供了基于Web界面的方式,打开Applications子选项,切换到Manage,可以看到预先定义的一些应用。在Test下面,有个WordCount应用,点开后选择“Deploy”

然切换到Run,可以看到已经有了WordCount这个应用,
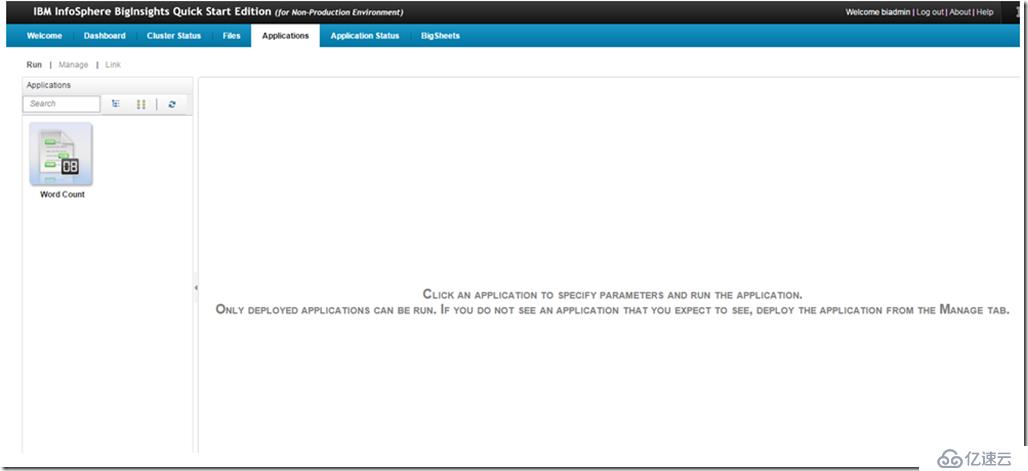
选中WordCount,输入要统计文件所在的目录及输出目录,点击Run开始运行
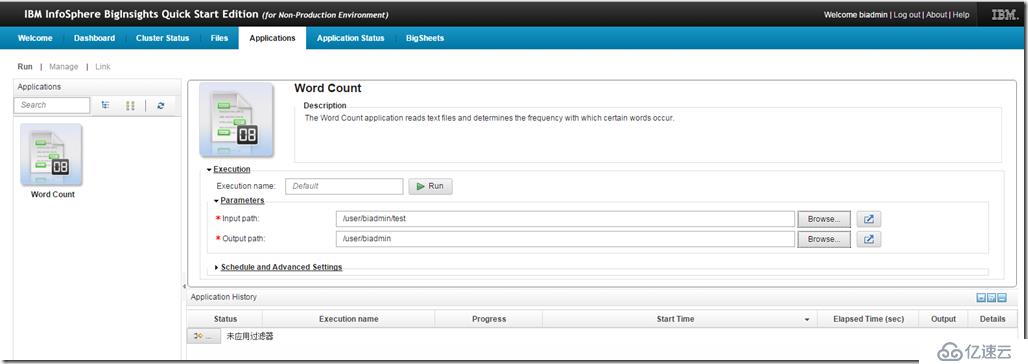
同样地,也可以通过Web界面来操作HDFS文件系统,包括创建、删除、修改目录或者文件
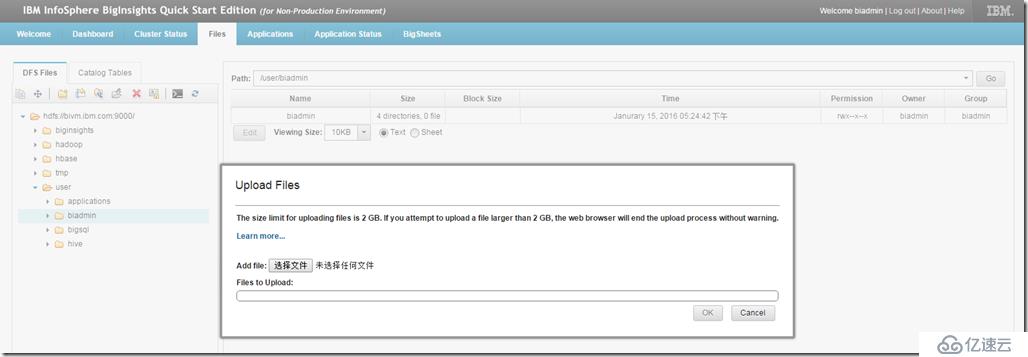
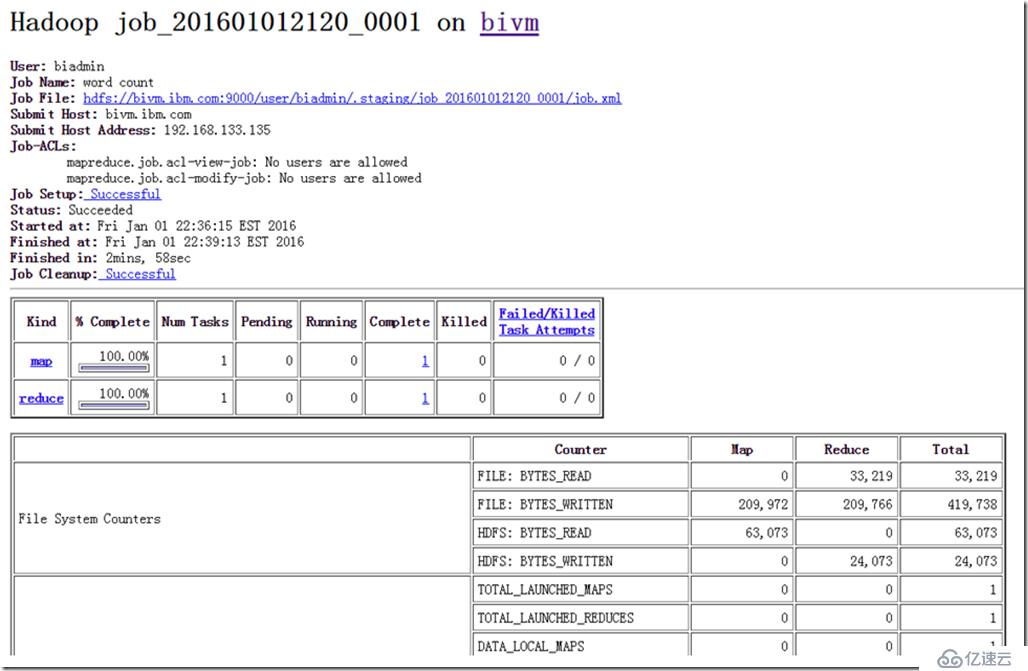
用浏览器打开JobTracker(http://192.168.133.135:50030/jobtracker.jsp),显示出最近运行的MapReduce任务,点开JobID能看到更多详细信息。
所谓的JobTracker是一个master服务,Hadoop启动之后JobTracker接收Job,负责调度Job的每一个子任务task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行它。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





