此次发布的2.7版本在进一步优化产品底层数据处理逻辑的同时更加注重提升用户在数据融合任务的日常管理、运行监控及资源分配等管理方面的功能增强与优化,力求帮助大家更为直观、便捷、稳定地管理数据融合任务,提升系统的易用性与稳定性。
一、新增功能
对于大多数数据工程师而言,每天需要配置、管理、监控的任务数以百计,任务的重要程度、时效性要求与性能要求也都千差万别,其中既包括为线上产品提供实时计算数据的任务,也有数据备份等优先级较低的任务。同时,为了应对不停变化的市场与业务需求,新的数据融合任务需求也会连续不断地涌现,数据工程师在保证现有任务稳定运行的同时,还需不断地新增数据任务。
功能详情:
(1)重要任务
工作事务通常带有自身的优先级属性,数据同步任务亦如此。针对重要任务,DataPipeline提供星标设置,于主页优先展示。用户可实时关注重要任务状态,保证重要任务稳定运行。
集中展示出现故障的任务,保障问题不被遗漏,任务故障处理全面有序。
(3)非激活状态
集中展示处于非激活状态的任务,明确列示需要进一步完善配置或需要修改配置的任务,保证数据工程师的任务配置工作全面有序。
(4)性能关注

2. 可按照项目对任务进行分组管理
(1)支持通过自定义创建项目,对任务进行分组;
(2)支持通过勾选任务,改变多个任务的任务分组。
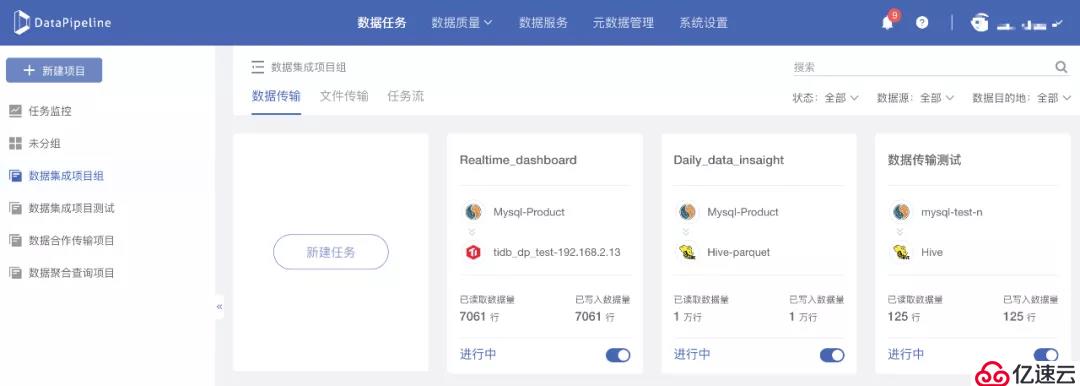
3. 可以为任务配置特定资源组
虽然DataPipeline数据融合产品基于并行计算框架,从基础架构层面支持任务级高可用,但在资源组管理方面一直未对用户开放,用户在使用之前版本的DataPipeline时,所有数据任务均在一个默认资源组中运行,无法根据任务的重要程度来分配任务运行资源。
例如,当前系统资源为一台16C64G的服务器,在无法分配资源组时任务运行状态如下:
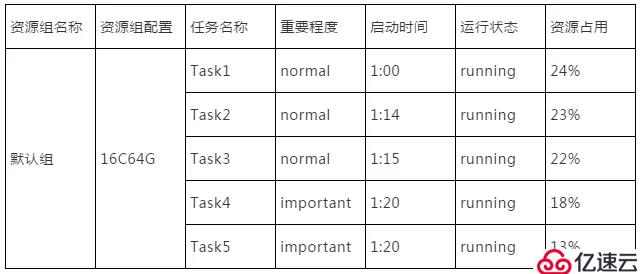
资源组配置开放以后,用户可以配置一个重要任务资源组和一个一般任务资源组,任务运行状态如下:
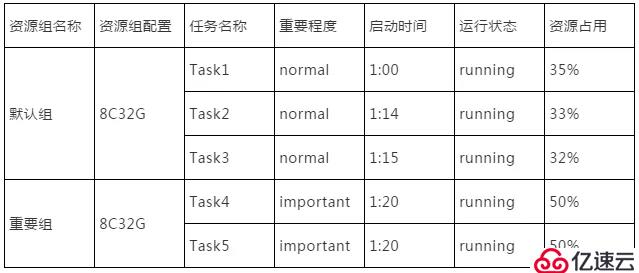
重要任务相较于其他普通任务虽然启动时间较晚。但由于被分配在独立的资源组中,仍然可以保证有足够的资源保障任务平稳运行。
(1)资源组配置
在部署DataPipeline时,通过修改配置文件,可以将数据源端/目的地端的服务器资源划分为多个资源组,实现业务资源组解耦。
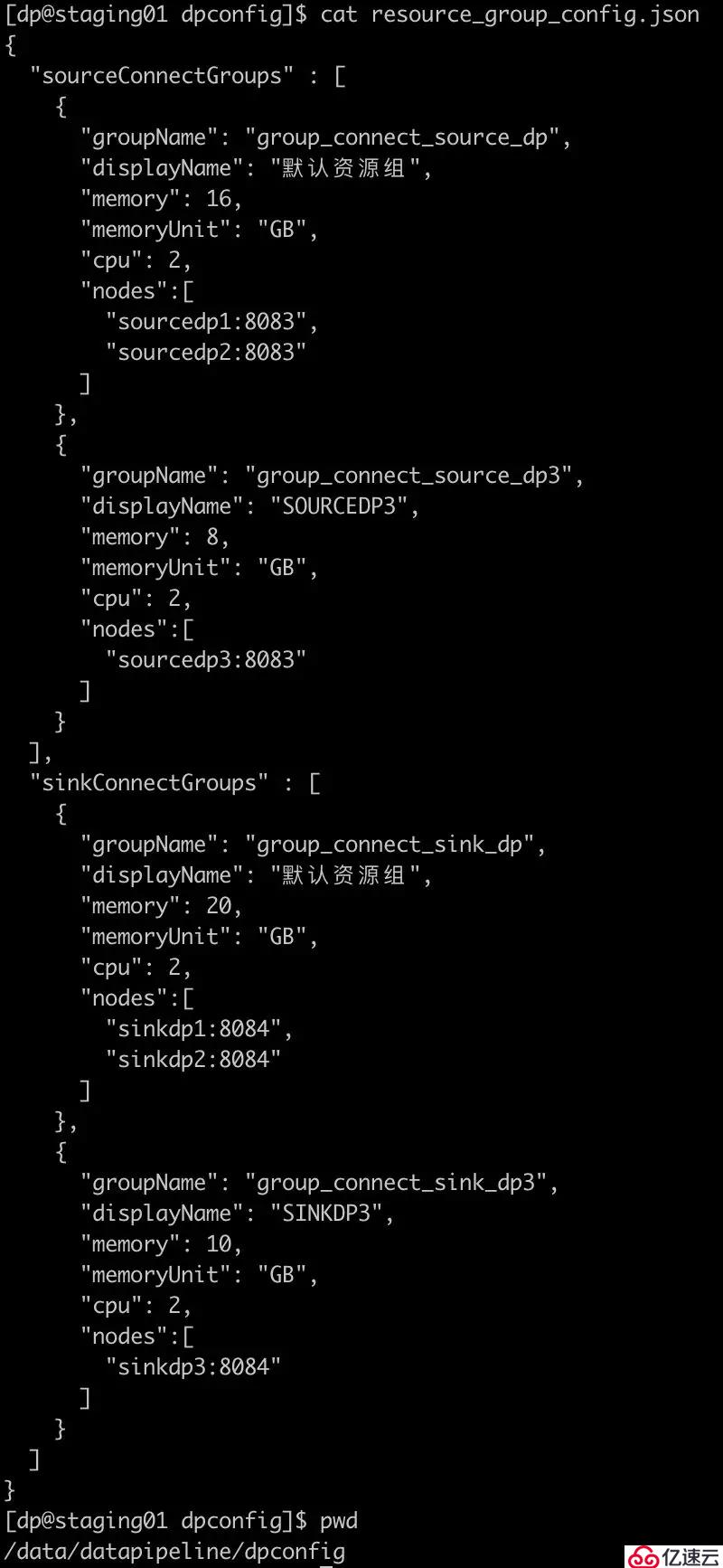
配置详细说明如下:
注:修改配置文件后需要重启服务使资源组配置生效
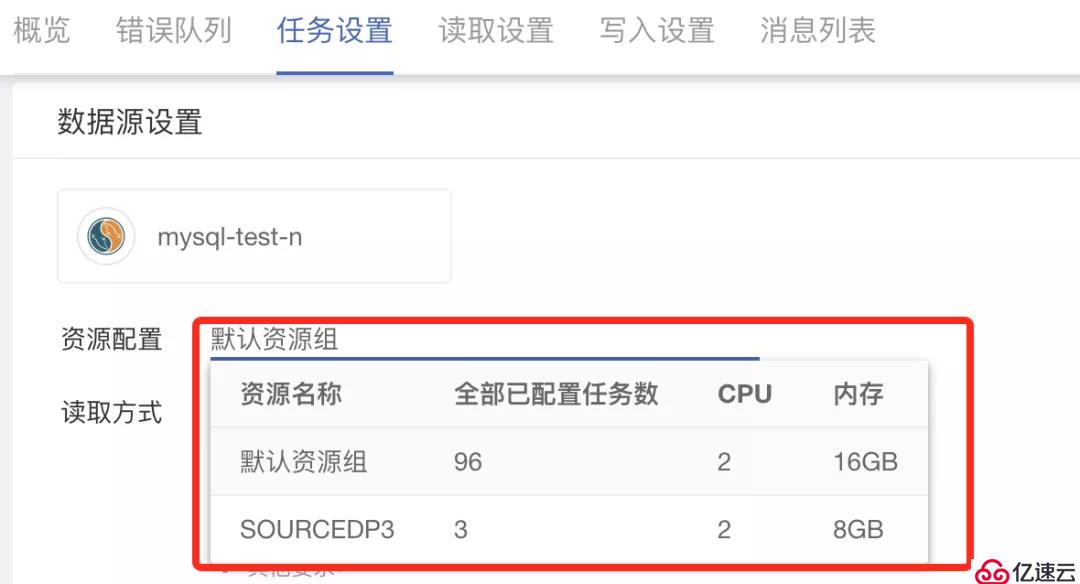
(2)为任务的读取与写入分配资源组
用户在任务设置过程中可以针对每个任务的数据读取和数据写入分别选择支撑任务运行的资源组。
二、优化功能
1. 数据传输消息队列粒度拆分优化
DataPipeline为更好地支持高效数据融合任务,对数据传输消息队列粒度进行了进一步的拆分优化。
功能详情:
首先,我们来看一下数据在DataPipeline是如何流转的:

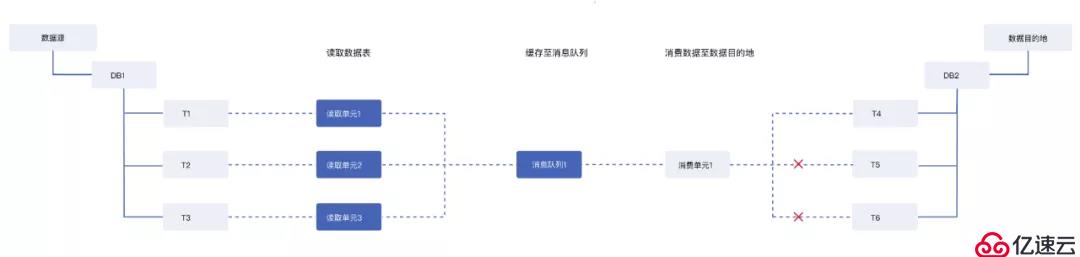
图1
该缓存机制可以很好地支持T4的数据同步,由于数据进入了1个消息队列,所以在同步T5、T6的数据时需要将缓存中的T1、T2、T3数据进行拆分,处理效率较低。
DataPipeline针对数据传输中消息队列缓存粒度进行了拆分优化(如图2),按照数据源数据表的粒度,进行消息队列拆分,即将数据源T1、T2、T3的数据分别写入三个消息队列进行缓存。
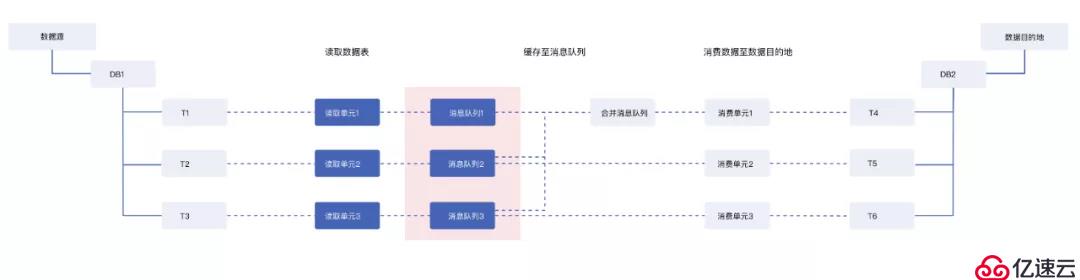
图2
同步至T4的数据会读取T1、T2、T3分别对应的消息队列,进行合并后写入合并消息队列,再供T4对应的消费单元进行消费,同步至T5、T6的任务可以分别读取T2与T3对应的消息队列进行数据写入。
三、其他功能增强与问题修复
除上述功能之外,DataPipeline还分别从以下几方面对产品进行了功能增强与问题修复:
1. 支持对用户注册信息中邮箱的修改
2. 为数据任务页面复制、编辑、删除等按钮添加文字注释
3. 优化线程实时任务心跳,支撑运维监控
4. 优化元数据查询SQL和相关逻辑,修复索引查询
5. Hive数据源重构优化
6. Hive Kerberos的验证优化
7. 优化由于JDBC连接造成的任务卡顿问题
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



