安装JDK 1.7以上 Hadoop 2.7.0不支持JDK1.6,Spark 1.5.0开始不支持JDK 1.6
安装Scala 2.10.4
安装 Hadoop 2.x 至少HDFS
spark-env.sh
export JAVA_HOME=
export SCALA_HOME=
export HADOOP_CONF_DIR=/opt/modules/hadoop-2.2.0/etc/hadoop //运行在yarn上必须要指定
export SPARK_MASTER_IP=server1
export SPARK_MASTER_PORT=8888
export SPARK_MASTER_WEBUI_PORT=8080
export SPARK_WORKER_CORES=
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=26g
export SPARK_WORKER_PORT=7078
export SPARK_WORKER_WEBUI_PORT=8081
export SPARK_JAVA_OPTS="-verbose:gc -XX:-PrintGCDetails -XX:PrintGCTimeStamps"slaves指定worker节点
xx.xx.xx.2 xx.xx.xx.3 xx.xx.xx.4 xx.xx.xx.5
运行spark-submit时默认的属性从spark-defaults.conf文件读取
spark-defaults.conf
spark.master=spark://hadoop-spark.dargon.org:7077启动集群
start-master.sh
start-salves.shspark-shell命令其实也是执行spark-submit命令
spark-submit --help
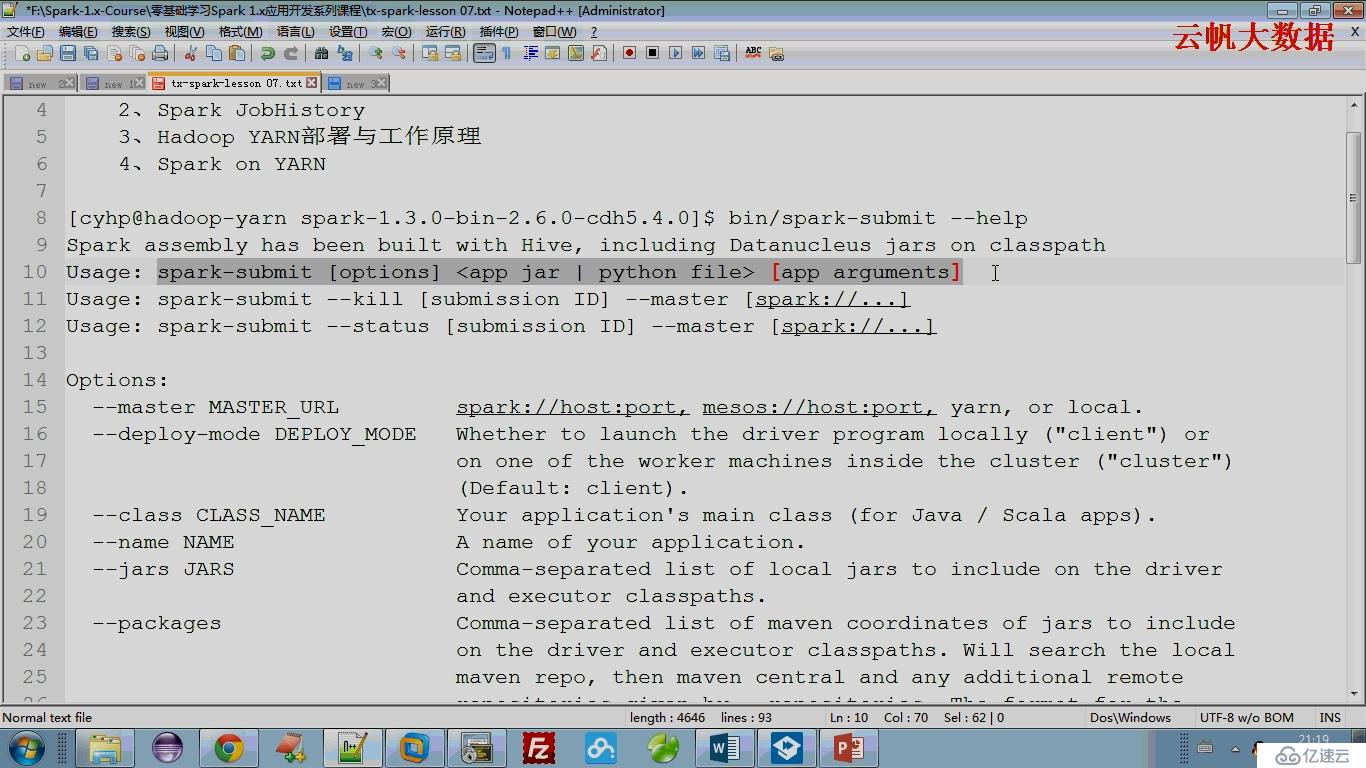
deploy-mode针对driver program(SparkContext)的client(本地)、cluster(集群)
默认是client的,SparkContext运行在本地,如果改成cluster则SparkContext运行在集群上
hadoop on yarn的部署模式就是cluster,SparkContext运行在Application Master
spark-shell quick-start链接
http://spark.apache.org/docs/latest/quick-start.html
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



