spark快的原因
1.内存计算
2.DAG
spark shell已经初始化好了SparkContext,直接用sc调用即可

lineage 血统
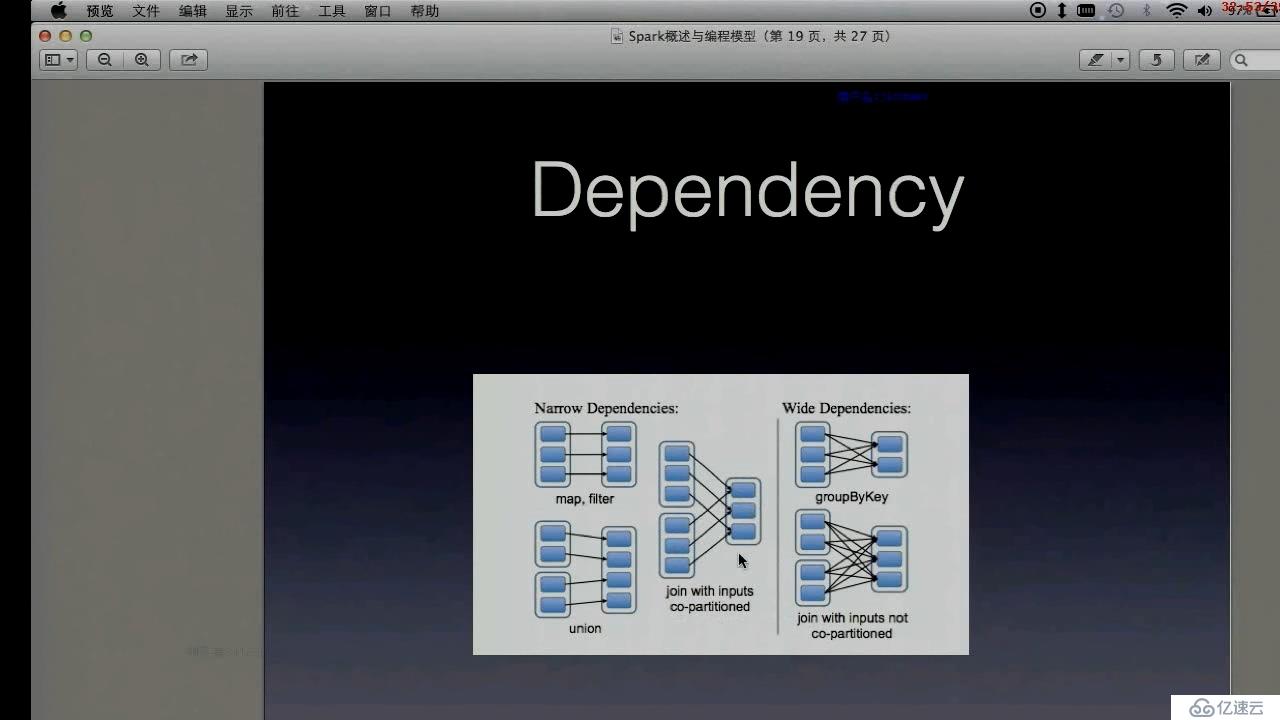
RDD wide and narrow dependencies
窄依赖每个 RDD partition最多被一个子RDD partirion依赖
/sbin(system binary)放的都是涉及系统管理的命令。
有些系统里面,普通用户没有执行这些命令的权限。
有些系统里面,普通用户的PATH不包括/sbin
data.cache 数据放到内存中
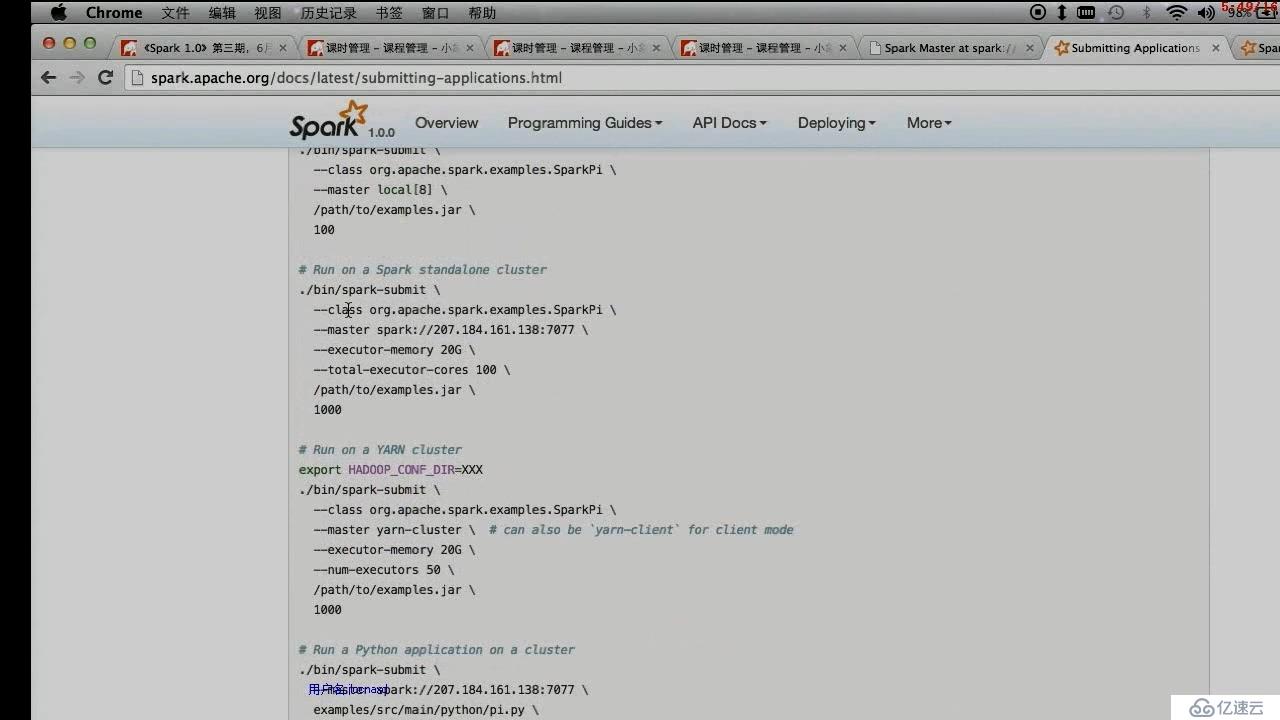
spark-submit提交任务
scala代码
package cn.chinahadoop.spark
import org.apache.spark.{SparkContext, SparkConf}
import scala.collection.mutable.ListBuffer
import org.apache.spark.SparkContext._
/**
* Created by chenchao on 14-3-1.
*/
class Analysis {
}
object Analysis{
def main(args : Array[String]){
if(args.length != 2){
println("Usage : java -jar code.jar file_location save_location")
System.exit(0)
}
val conf = new SparkConf()
conf.setSparkHome("/data/software/crazyjvm/spark")
val sc = new SparkContext(conf)
val data = sc.textFile(args(0))
data.cache
println(data.count)
data.filter(_.split(' ').length == 3).map(_.split(' ')(1)).map((_,1)).reduceByKey(_+_)
.map(x => (x._2, x._1)).sortByKey(false).map( x => (x._2, x._1)).saveAsTextFile(args(1))
}
}亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



