应了一个国内某电信运营商集群恢复的事,集群故障很严重,做了HA的集群Namenode挂掉了。具体过程不详,但是从受害者的只言片语中大概回顾一下历史的片段。
Active的namenode元数据硬盘满了,满了,满了...上来第一句话就如雷贯耳。
运维人员发现硬盘满了以后执行了对active namenode的元数据日志执行了 echo "" > edit_xxxx-xxxx...第二句话如五雷轰顶。
然后发现standby没法切换,切换也没用,因为standby的元数据和日志是5月份的...这个结果让人无法直视。
因为周末要去外地讲课,所以无法去在外地的现场,七夕加七八两天用qq远程协助的方式上去看了一下。几个大问题累积下来,导致了最终悲剧的发生。
Namenode的元数据只保存在一个硬盘mount里,且该盘空间很小。又有N多人往里面塞了各种乱七八糟的文件,什么jar包,tar包,shell脚本。
按照描述,standby元数据只有到5月份,说明standby要么挂了,要么压根就没启动。
没有做ZKFC,就是失效自动恢复,应该是采用的手动恢复方式(而且实际是没有JournalNode的,后面再说)。
至于raid0, lvm这种问题就完全忽略了,虽然这也是很大的问题。
然后他们自己折腾了一天,没任何结果,实在起不来了,最好的结果是启动两台standby namenode,无法切换active。通过关系找到了我,希望采用有偿服务的方式让我帮忙进行恢复。我一开始以为比较简单,就答应了。结果上去一看,故障的复杂程度远超想象,堪称目前遇到的最难的集群数据恢复挑战。由于无法确切获知他们自己操作后都发生了什么,他们自己也说不清楚,也或者迫于压力不敢说,我只能按现有的数据资料尝试进行恢复。
第一次尝试恢复,我太小看他们的破坏力了,以至于第一次恢复是不成功的,七夕下班抛家舍业的开搞。在这次尝试中,发现HA是没有用ZKFC做自动恢复的,完全是手动恢复,于是顺带帮他们安装配置了ZKFC。然后首先初始化shareEdits,发现他们压根没有做shareEdits,那就意味着,其实原来的JournalNode可能根本就没起作用。然后启动zookeeper,接着启动journalnode,然后启动两个NN,两个NN的状态就是standby,然后启动ZKFC,自动切换失败。根据日志判断,是两个NN中的元数据不一致导致了脑裂。于是使用haadmin里面的隐藏命令强行指定了一个NN。启动了一台NN,而另一台则在做脑裂后的元数据自动恢复。自动恢复log日志如下
INFO org.apache.hadoop.hdfs.server.namenode.FSEditLogLoader: replaying edit log: xxxx/xxxx transactions completed. (77%)
经过漫长的等待,SNN元数据恢复了。但是一直没有脱离safemode状态,因为太晚了,就没有继续进行,只是告诉他们,等到safemode脱离了,就可以了,如果一直没有脱离,就强行使用safemode leave脱离。但是,我把一切看的太简单了。
第二天,打电话说集群仍然不能用。我上去一看,还是处于safemode。于是强行脱离safemode,但是只有active脱离了,standby仍未脱离,HDFS也无法写入数据,这时看hdfs的web ui,active和standby的数据块上报远未达到需要的数量,意识到元数据有丢失。但对方坚称元数据是故障后立刻备份的,而且当时的误操作只是针对edits日志,fsp_w_picpath没有动。说实话,我倒宁可他们把fsp_w_picpath清空了,也不要吧edits清空了。fsp_w_picpath可以从edits恢复,而edits清空了,就真没辙了。
于是,第二天再次停止NN和Standby NN,停止ZKFC,停止JournalNode,结果NN又起不来了,报
The namenode has no resources availible
一看,恢复时产生的log太多,元数据的硬盘又满了。只好跟对方合计,把元数据换到另外一个比较空的硬盘里处理。我也不知道为什么他们要找那么小的一块盘存元数据,跟操作系统存一起了。挪动元数据文件夹,然后改配置,然后启动ZK,Jounal, NN, StandbyNN,使用bootStrapStandby手工切换主从。再启动ZKFC,HDFS恢复,然后强制脱离safemode。touchz和rm测试HDFS可以增删文件,没有问题了。
第二次尝试恢复,这时实际上HDFS已经可以正常访问,算是恢复了,但是元数据有丢失,这个确实没办法了。于是,跟他们商量,采取第二种办法,尝试通过日志恢复元数据。他们同意尝试恢复。于是将他们自己备份的editslog和fsp_w_picpath从他们自己备份的文件夹拷到元数据文件夹,使用recover命令进行editslog到元数据的恢复。经过一段时间等待,恢复,再重启NN和Standby NN,结果发现日志里恢复出来的数据比之前恢复的还要旧,于是再按第一种方案的下半段方法恢复成以前的元数据。下面说为什么。
最终恢复出来的元数据所记录的数据有580TB多一些,丢失部分数据。
原activeNN的日志已经被清空, 这上面的fsp_w_picpath是否被动过不知道,之前他们自己操作了什么我不得而知。由于这上面磁盘已满,所以这上的fsp_w_picpath实际是不可信的。
JournalNode没有做initializeShareEdits,也没有做ZKformat,所以Journalnode实际上没有起作用。jn文件夹下无可用做恢复的日志。方案二中的恢复是用StandbyNN的日志进行恢复的,由于standby根本没有起作用,所以通过日志只能恢复到做所谓的HA之前的元数据。
原standby NN虽然启动了,也是手工置为standby,但是由于没有Journalnode起作用,所以虽然DN会上报操作给standby NN,但是无日志记录,元数据也是旧的。最后的日志也就是记录到5月份,而且已然脑裂。下图对理解NNHA作用机理非常重要,特别是所有箭头的指向方向。
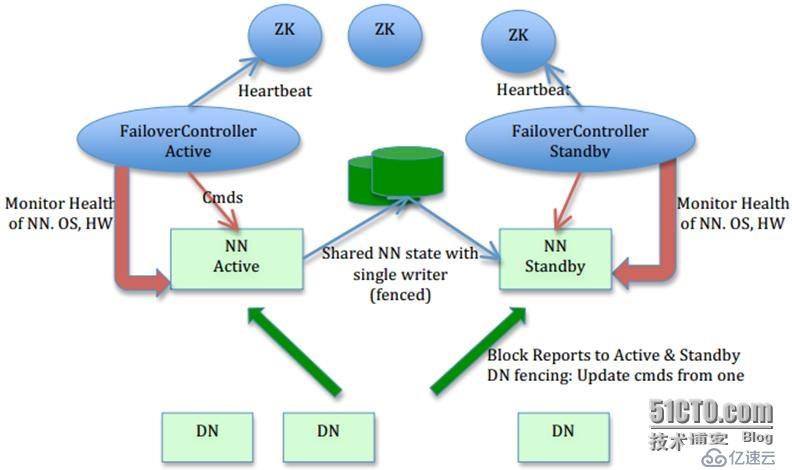
那么,最后总结整个问题发生和分析解决的流程。
先做名词定义
ANN = Active NameNode
SNN = Standby NameNode
JN = JournalNode
ZKFC = ZooKeeper Failover Controller
问题的发生:
ANN元数据放在了一块很小的硬盘上,而且只保存了一份,该硬盘满,操作人员在ANN上执行了 echo "" > edits....文件的操作。
当初自己做HA,没有做initializeShareEdits和formatZK,所以JN虽启动,但实际未起作用,而SNN也实际未起作用。只是假装当了一个standby?所以JN上无实际可用edits日志。
操作人员在问题发生后最后备份的实际是SNN的日志和元数据,因为ANN editlog已清空,而且ANN硬盘满,即便有备份,实际也是不可信的。
问题的恢复:
恢复备份的fsp_w_picpath,或通过editslog恢复fsp_w_picpath。
将fsp_w_picpath进行恢复并重启NN,JN等相关进程,在safemode下,Hadoop会自行尝试进行脑裂的修复,以当前Acitve的元数据为准。
如遇到元数据和edits双丢失,请找上帝解决。这个故障案例麻烦就麻烦在,如果你是rm editslog,在ext4或ext3文件系统下,立刻停止文件系统读写,还有找回的可能,但是是echo "" > edits,这就完全没辙了。而且所有最糟糕的极端的情况全凑在一起了,ANN硬盘满,日志删,元数据丢,SNN压根没起作用,JN没起作用。
问题的总结:
作为金主的甲方完全不懂什么是Hadoop,或者说听过这词,至于具体的运行细节完全不了解。
承接项目的乙方比甲方懂得多一点点,但是很有限,对于运行细节了解一些,但仅限于能跑起来的程度,对于运维和优化几乎无概念。
乙方上层领导认为,Hadoop是可以在使用过程中加强学习和理解的。殊不知,Hadoop如果前期搭建没有做好系统有序的规划,后期带来的麻烦会极其严重。况且,实际上,乙方每个人都在加班加点给甲方开发数据分析的任务,对于系统如何正常运行和维护基本没时间去了解和学习。否则,绝对不会有人会执行清空edit的操作,而且据乙方沟通人员描述,以前也这么干过,只是命好,没这次这么严重(所以我怀疑在清空了日志之后肯定还做了其他的致命性操作,但是他们不告诉我)。
Hadoop生产集群在初期软硬件搭建上的规划细节非常之多,横跨网络,服务器,操作系统多个领域的综合知识,哪一块的细节有缺漏,未来都可能出现大问题。比如raid0或lvm,其实是个大问题,但N多人都不会去关注这个事。Yahoo benchmark表明,JBOD比RAID性能高出30%~50%,且不会无限放大单一磁盘故障的问题,但我发现很少有人关注类似的细节,很多生产集群都做了RAID0或RAID50。
很多培训也是鱼龙混杂,居然有培训告诉说map和reduce槽位数配置没用,这要不是赤裸裸的骗人,就是故意要坑人。
这是一次非常困难的集群数据恢复的挑战,最终的实际结果是恢复了大约580TB数据的元数据,并且修复了脑裂的问题。整个过程没有使用特殊的命令,全部是hadoop命令行能看到的haadmin, dfsadmin里面的一些命令。整个恢复过程中需要每个服务器多开一个CRT,观察所有进程log的动态。以便随时调整恢复策略和方法。最后特别提醒一下,seen_txid文件非常重要。
整个过程通过qq远程方式完成,中间断网无数次,在北京操作两天,在上海操作一天。为保护当事人隐私,以金主和事主代替。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





