这个题目有点大,而且我要严格控制字数,不能像《命题作文:在一棵IPv4地址树中彻底理解IP路由表的各种查找过程》那样扯得那么开了。事实上,这篇作文是上
一篇作文中关于区间查找小节的扩展。
根据IP数据包协议头的若干字段,也叫匹配域,将数据包划分到某个类别,这就是IP数据包分类的核心。
事实上,IP路由查找的过程就是IP数据包分类的一个特例,一个极其简单的特例,此时的匹配域就是目标IP地址,而类别就是路由项或者说更简单一点,下一
跳。此时考虑一下源地址Policy
routing,随即又增加了一个匹配域,即源IP地址,这时整个过程应该怎么做呢?本文关注一种多维区间匹配方案,不谈其它的比如HASH匹配,也不谈
硬件算法。
我希望我写的《HiPAC高性能规则匹配算法之查找过程》以及《玩转高性能超猛防火墙nf-HiPAC》可以带来些帮助,其实,IP数据包分类的过程可以看成是多个匹配域的区间查找的结果的合并。
在HiPAC一般算法中,虽然在执行效率上讲是非常好的,但是却可能浪费大量的内存。可能需要采用Grid of Tries数据结构的优化方式对其存储空间进行优化,去除冗余数据。
虽然我要说的关于IP数据包分类的核心算法到此应该就结束了,但是数据包分类背后的理论,才刚刚开始。后面我会用一个实例来做尽可能明晰的图解,而不是用一个统一的数学推导来说明问题,目的在于提供一个感性的画面。
往往只知道如何在多维连续区间集合里让一个IP数据包是远远不够的,其实不懂这些也没关系。如果确实懂这个,那么就要知其然亦知其所以然。
现在,我假设通过上面提到的两篇关于nf-HiPAC的文章,你已经知道了多维区间匹配的过程,那么我们可以脱离具体场景了,将其抽象成一个一般问题,先
看一下抽象后的示意图,在这个图中,我忽略了区间的大小,忽略了Rule的排列问题(最终我将会回到这个问题):
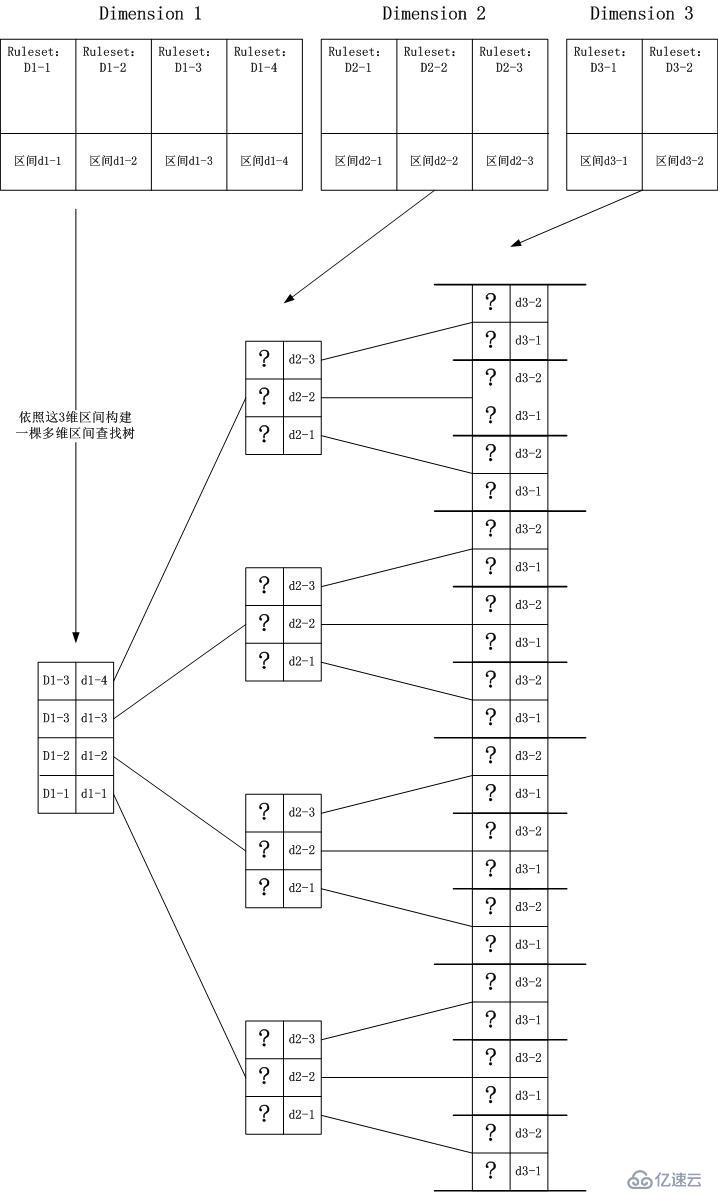
在这个图中,我们看到了很多的“?”号,意思是说,我们此时并不知道和该区间相关的Ruleset是什么?这是为什么呢?
我们来看第二层,也就是Dimension 2的那一层,该层中有4个节点,对应Dimension
1分裂出来的4个区间,如果想让匹配继续下去,即继续匹配Dimension
3那一层的节点,对应的Ruleset中必须要有交集才可以,因此我们得到了下面这个更加清晰的图示,虽然,它有点乱。。。。在写这个文章时,我不知怎么
想起了哈尔滨,想哭...:
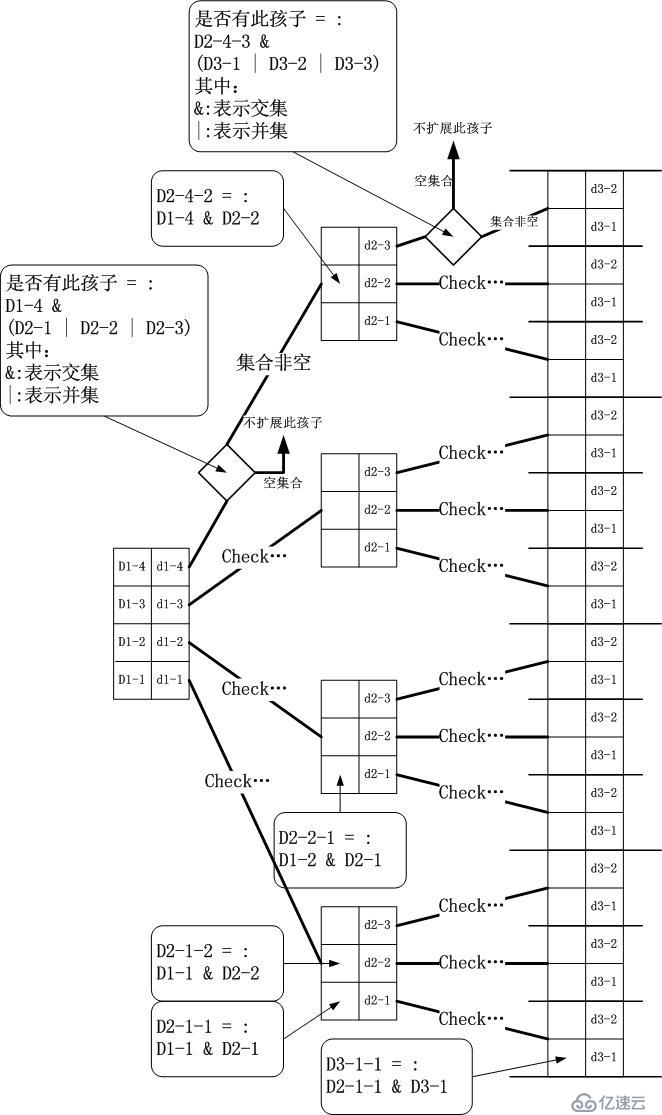
我们依照这个图,发现了下面重要的三个关键点:
当
前区间的Ruleset与下一个维度的各个区间的Ruleset并集取交集,该结果集合不为空时才会扩展该分支成一个孩子节点。我加入了一些与场景相关的
约束,比如每一个区间起码要有一个Default
Rule,因此所有的取交集的结果均不会为空,所以上面的这句话应该是,如果结果集合的元素个数为1,且该元素为Default
Rule的话,则该当前区间对应的下一个匹配维度孩子扩展为叶子节点。这意味着,下下一个维度将不会再扩展该子树,也就是说匹配没有必要继续下去了,直接
取Default Rule即可。
如关键操作所示,只要匹配会继续进行下去,即相关的当前
区间剩余的Ruleset中Rule数量不为1或者为1但是不是Default
Rule,那么我们就不能确定最终结果,因此,这意味着快速成功是不可能的。但是我们却可以很快确定什么情况下会失败,即当前区间的Ruleset中只剩
下了1个Default Rule。这就是快速失败。
通过上面的图示可以看出,由于
Ruleset是取交集,Dimension
1/2/3谁在前谁在后其实最终并不影响结果,但是这个排序的不同却可以影响空间的占用,从上图可以看出,只要Ruleset有交集,就要在下层创建一个
孩子节点,其实就是创建一个区间查找树,而我们在快速失败中知道,所有的子树可能由于Ruleset布局的不同而导致其高度并不相同。问题是,我们如何来
排列维度的查找顺序?
不要指望在上面的那棵树上作什么平衡操作,因为影响其子树高度以及宽度的因素是相互关联的,它们是Rule的数量,每一个维度的区间数量,Ruleset的内部布局等。这棵树的任意“旋转”将会导致其称为一团乱麻,它不是三角架。
由于根本就没有好的办法去计算如何最优化排列这些维度匹配顺序,倒不如按照统计的意义,寻找一种“让这棵树”更加平衡的方式。
到
此为止,我们一直觉得所谓的多维区间匹配就是一个M叉树,其中M是每层由该层,即该维度所被划分的区间数量。通过以上的分析,我们发现在一个如此胖的且每
个分支的高度还不确定的树中寻找一种最佳的构建方式是一件困难的事情,因为变量太多了,Ruleset中Rule的数量是一个变参,区间数量也是一个变
参,各个维度的每一个区间的Ruleset都要取并集,这涉及到一个笛卡尔积的问题。这里面涉及太多的数学计算,又没有一个简单的公式。
难道多维区间匹配树一开始就必须如此构造成M叉树吗?
在继续之前,我来用一种更加直观的方式展示上述的多维匹配问题,然后从0开始,直到我们遇到KD树为止,剩下的内容,数据结构,算法相关的书上就都有了。
幸亏我以三维域匹配为例,要不然我真不知道四维立方体怎么画出来。
我把上面的三维域匹配问题以一个立方体来描述:
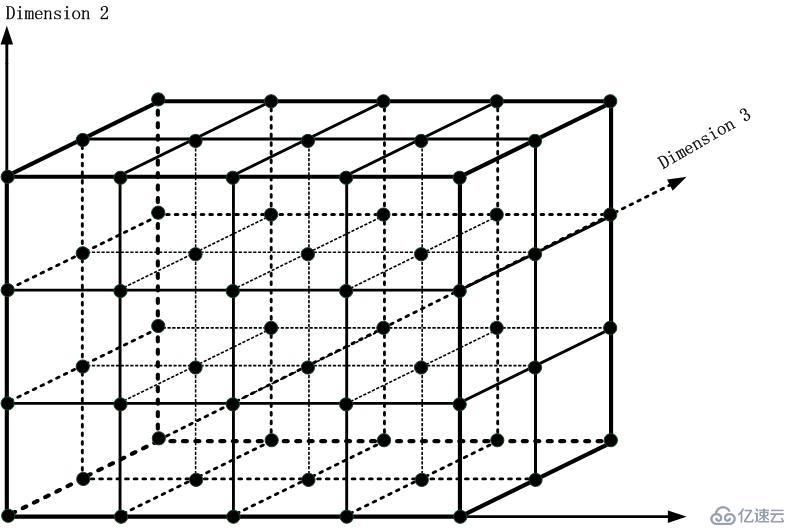
注
意到,每一个黑色的点沿着坐标轴连接成的线段进而由这些线段形成的面将这个立方体分割成了4*3*2个子立方体,我们的问题就是,最终匹配完成后,我们会
落入一个子立方体中,而这个子立方体里面当前的Ruleset就是结果集,我们取优先级最大的,就是最终结果,值得注意的是,这些子立方体中的
Ruleset是在构造这个立方体的时候放进去的,和那篇讲路由查找的命题作文一样,我并不考虑相对稀有的数据结构构造事件的时间复杂度。因此,我将
Ruleset示意图放入子立方体,如下图所示:
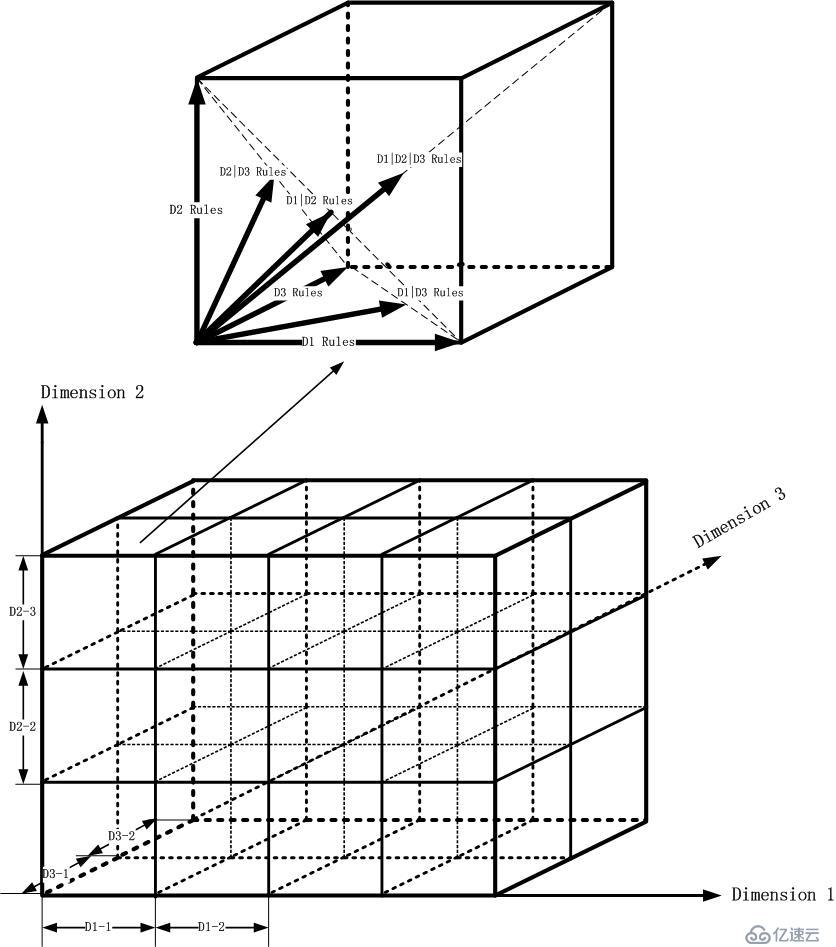
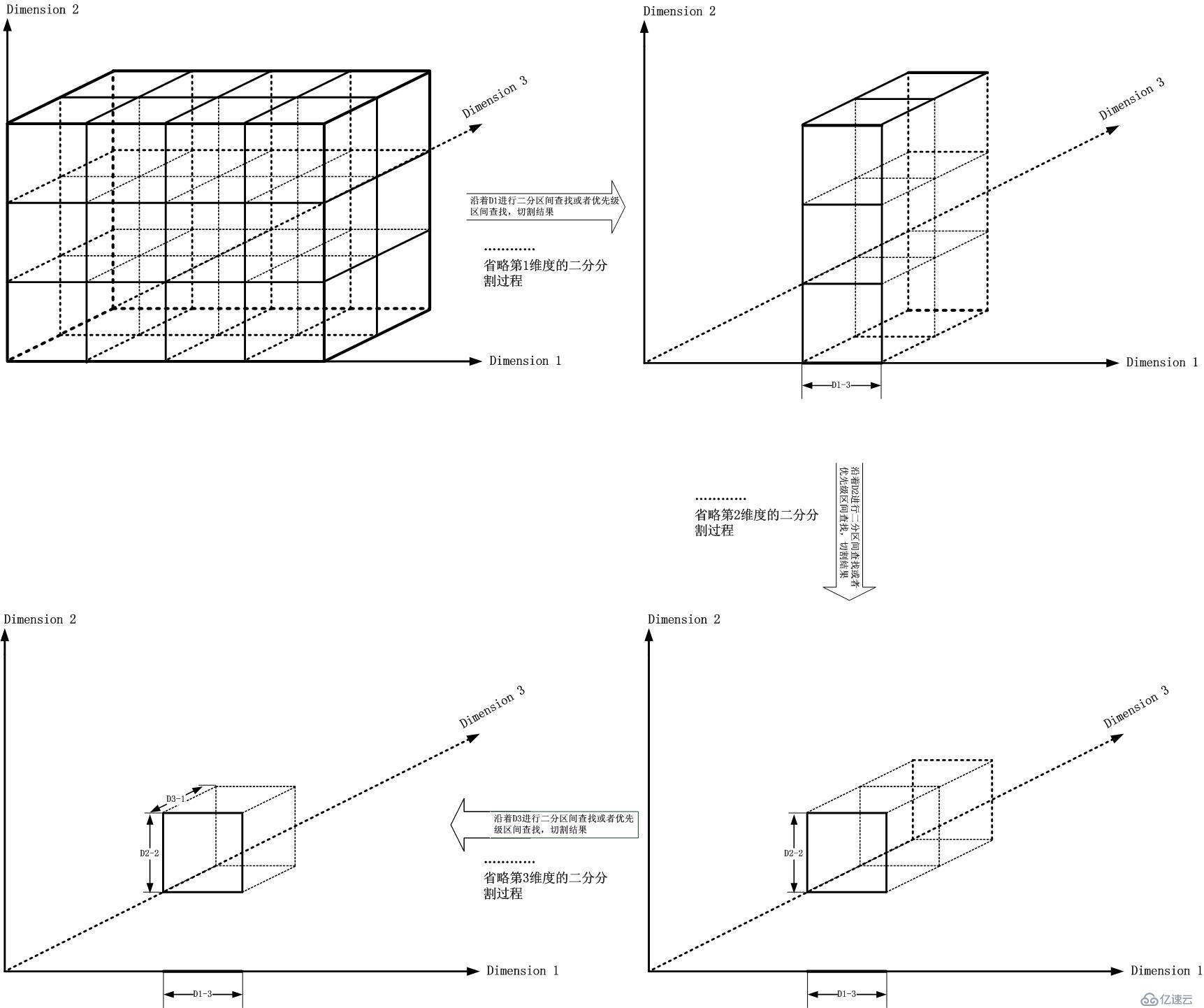
那么现在问题来了。我要怎么切割这个立方体,然后最后得到那个期望的子立方体呢?第一刀怎么切?沿着D1轴?D2轴?D3轴?如果确定了D1轴,那么第二刀呢?继续D1轴?还是换一个方向切?...
这不禁让人想到切西瓜,但是事实上却完全不同,这个和你用一大块木头块取中心的小块比较类似。你有两种方式,先把它削成片,再把它削成棍,最后把棍剁成小块;还有一种方式比较类似机床×××那般,始终不断变换方向切割。对于多维匹配问题,我们面临了同样的选择。
这种方式类似片-棍-块的方式,如下图所示:
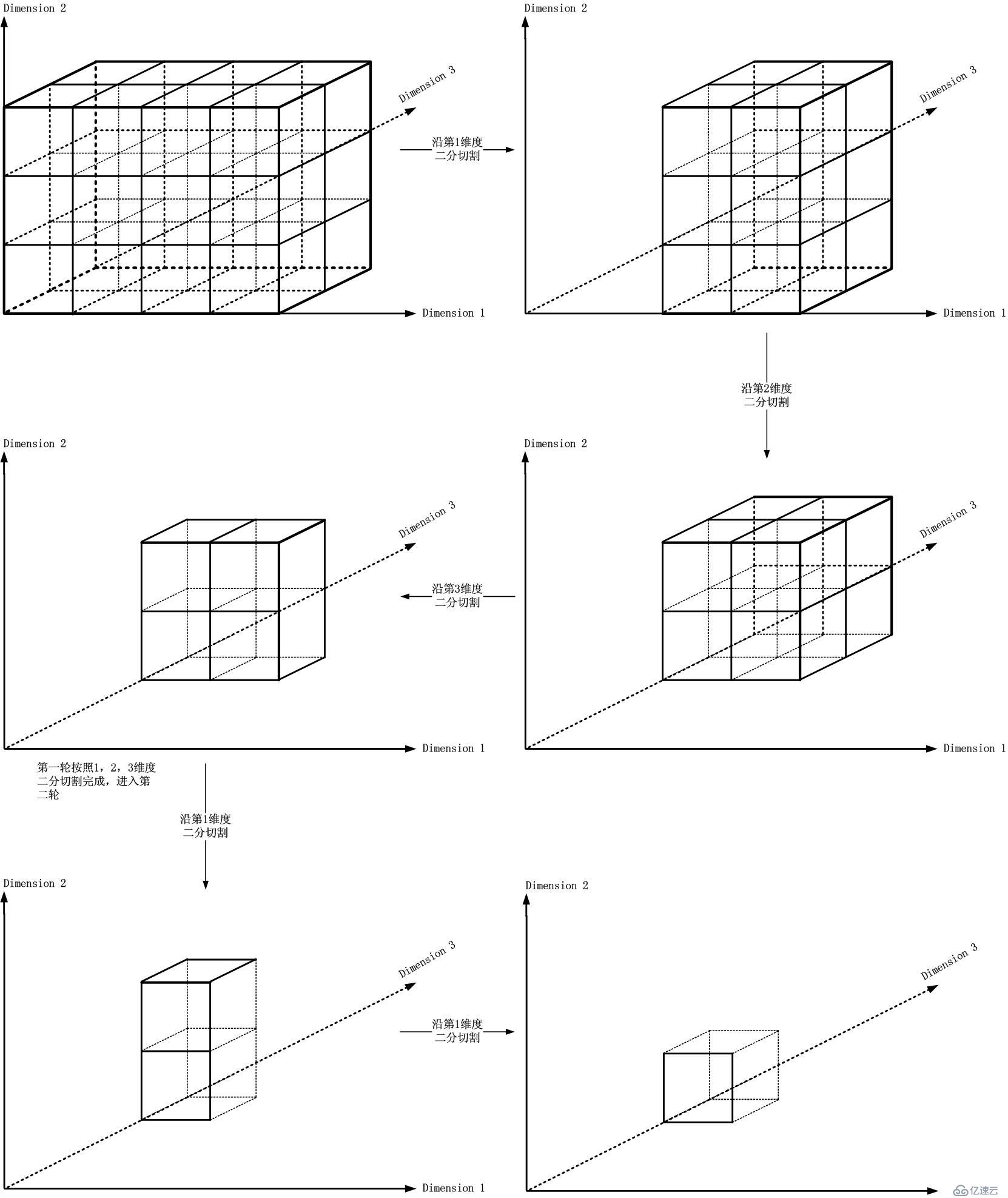
这个比较类似机器加工的方式,如下图所示:
那么,是时候给出数据结构了。我在讲路由查找的作文中的区间查找小节给出了区间二叉查找树的结构以及构造方式,本文中对此前提作了基本假设。
深度优先的查找树结构如下:
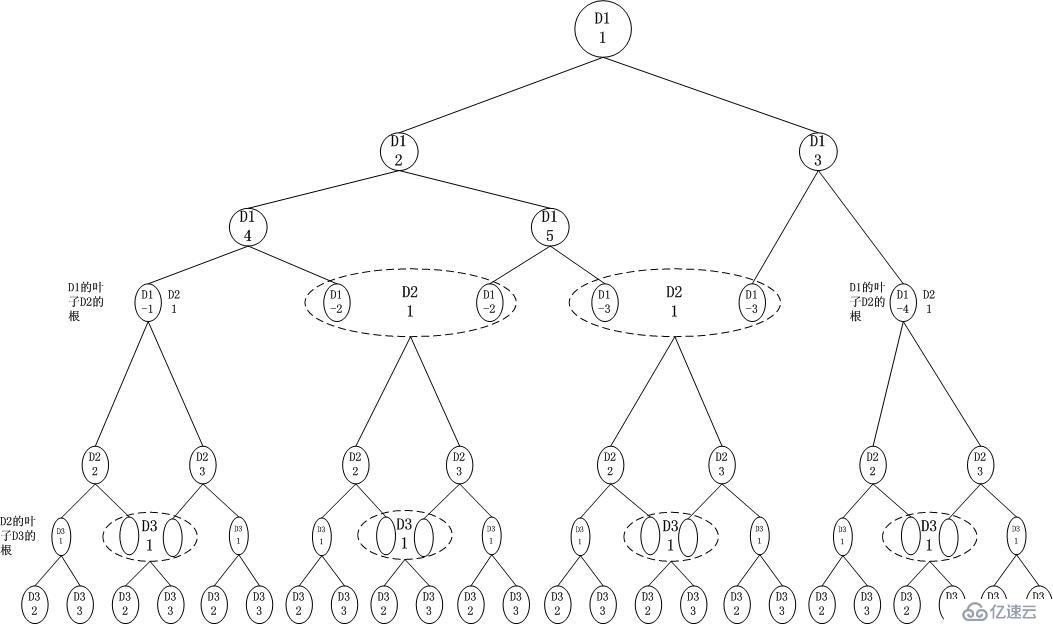
可见,这是一种直接的方式,特别适合精确匹配。以下我提到Dimension Tree或者Dimtree的时候,指的就是这棵树。
广度优先的查找树结构如下:
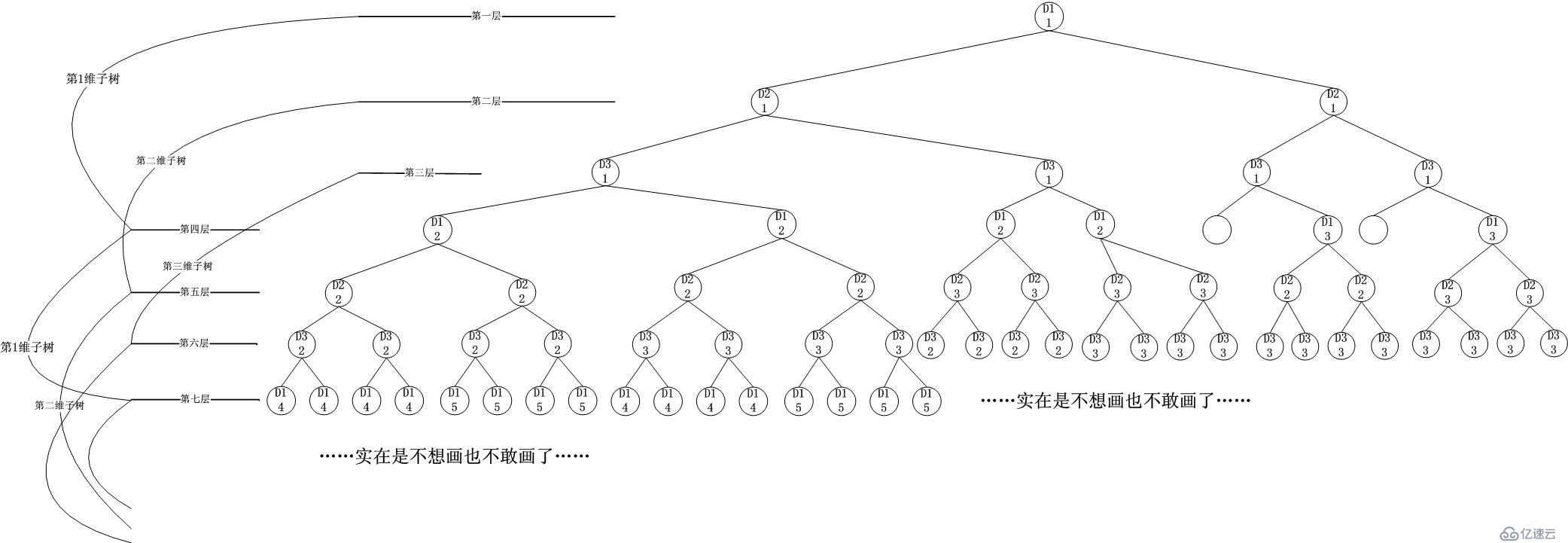
可
见,这是一种碰运气的方式,在各个维度上逐步(以尽可能细的粒度,小心翼翼地)接近最终要落到的子立方体空间。当然这种方式其实就是Dimension
Tree的逐层旋转后展开的结果,最终也可以得到答案,碰到某个维度的叶子节点后,将其中的Ruleset压入一个栈中,最终在这棵树游历结束后,将栈里
面的Ruleset取出后求交集,然后取最佳的即可。当然,也可以用快速失败来剪掉枝干,比如到达了一个只包含Default
Rule的叶子节点。但是,第一次发现叶子节点的时刻要等多久呢?如果第一个维度的查找树有3层,第二维度有2层,第三维度有2层,那么广度优先树的层则
为:第一维度-第二维度-第三维度-第一维度-第二维度(首次碰到叶子)-第三维度(叶子节点)-第一维度....不管怎么说,即便从第二维度开始切割,
也不可能在第二层碰到叶子...这就说明,即便是快速失败的检测,也要比深度优先延后。
对于数据包精确匹配分类来
讲,深度优先的方式好于广度优先的方式,这不仅仅是在说如果没有精确区间匹配,那么再接近的匹配也不算(比如精确匹配192.168.1.18,那么
192.168.1.19显然是不符合要求的,虽然它很接近),还包括这种方式可以最大限度的利用系统Cache。
注意,不要认为数据包的掩码匹配就不是精确匹配,本文是严格基于区间来匹配的,掩码将一个域划分成了多个精确的区间,而最终的目的是定位一个数据包的某个域精确落到了哪个区间中,注意,这是一种精确匹配。
KD树,即k-dimension树就采用了上述逐维度广度优先的匹配方式。然而它的维度排序思想可以被借鉴,从而用于深度优先匹配,最终目标是构建一棵“若不匹配则快速失败”的树!
看起来,这像极了一棵B-树,但它不是!
KD树的资料网上实在太多。我要说的是它的递归构建中是如何使用方差的。现在让我们回答第一刀从哪里切割的问题。
我将区间长度作为基准,那么每个维度均可以计算出一个区间长度的方差数值,即:
取这个值最大的维度为第一维度,然后使用朴素的二分构建,取该维度区间全集中最接近中点的那个点作为根,开始递归构建二叉树。每一层都要计算该子域的方差,从而根据这个最大方差原则选出子树的二分根。通过上面的广度优先匹配可以看出,那个图应该就是一棵朴素的KD树。
采用最小方差的思想的目的是,让这棵树平衡一些,方差比较大说明这个维度上的区间分布比较均匀,标示点并没有集中在平均值附近,这样切割的时候就不会一下
子切掉一大块,从而错过了可能比较接近最终答案的那些区域(最终结果的逼近原则:切割粒度尽可能小,一定要小心翼翼,类似削梨或者削铅笔那样的)。注
意,KD树的目标并不是精确匹配,而是模糊最佳匹配,比如经典的寻找K个最接近的点。
由
于深度优先匹配并不是递归构建的,因此不需要每一步都去计算方差从而确定切割的维度,对于深度优先匹配而言,只要确定了某个维度,那么将在这个维度上直接
切割完毕,对于三维情况而言,就是直接切成一个片,对于二维而言就是切成一根棍...对于接下来的切割就不需要再考虑这个维度了,因为在这个维度,它已经
精确到达它的区间了。因此,我们只需要找出一个维度序列就可以了。
还是像KD树一样基于方差吗?不一定。此时我们希望的是,让Rule在各个区间分布最不平均的维度作为第一维,依次类推。这是因为,Rule分布不平均在
和下一维的Ruleset并集取交集的时候,对应区间在经过取交集计算后,出现唯一Default
Rule从而导致快速失败的可能性比较大,这就会减少孩子节点的数量,对于一棵M叉树而言,越是剪掉靠近根的节点的孩子,越能抑制下层节点的疯长。我们判
断是否扩展该孩子的公式为:
当前维度区间Ruleset & (next维度各个Ruleset的并集)
我们不好控制next
维度的各个区间Ruleset的并集,我们甚至不知道next维度是哪个,但是我们可以找到当前维度的Ruleset分布情况。举一个最简单的例子,有一
个维度划分了4个区间,第一个区间的Ruleset中有10条,后三个区间中均是2条,那么仅有2条Rule的区间和别人取交集时很可能是空,这就为我们
找到了一个计算的依据,很显然,我们这次不用KD树的方差,而是将权值表示成一个区间数量,区间Rule的分布情况(这个变量可以用方差也可以不用)的函
数,从而算出最终的排序。最朴素的计算还是使用方差,计算每个维度区间中Rule数量的方差,取最小值为最高权值,这说明Rule在某个区间的分布比其它
区间更加集中,从而有更高的可能切掉孩子的脐带导致“快速失败”!
这是个问题吗?不是问题。
本文中,我们以区间为基准,因此就可以把Ruleset进行拆分。举一个最简单的例子,设置Rule1,2的区间192.168.1.0/24被设置Rule1,3区间192.168.0.0/16覆盖,但是这不是问题,解决如下图所示:

不要在一棵树上吊死!
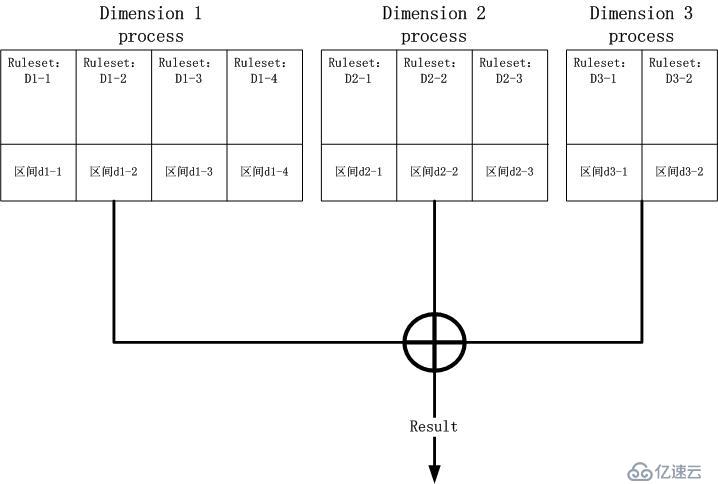
我们非要将整个匹配数据结构塞到一棵树中吗?如果非要这么做,我们就失去了并行操作的可能性,因为一棵树的从根到叶子的路径只有一条路径,鉴于下层分支巨
量,瞎猜只是掰扯,你几乎不可能猜对分支。那么怎么办呢?由于最终的结果是N个维度(在我们的例子中,N为3)的匹配区间Ruleset取交集,那么就好
办了,N个维度分别构建N棵树,N个处理进程同时运算,最终取交集。让我们回到最初的那幅图,点一下题:
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



