简介
mongodb是很出名的nosql数据库了,属于集合-文档型的特有架构nosql数据库,也是被誉为最像关系型数据库的非关系型数据库,但是不支持事务.
由于mongodb原生就支持分布式架构,所以部署简单,灵活,可伸缩,自动平衡数据结构等优点,继而性能也非常高.所以搭建mongodb来使用的公司,90%都会使用到mongodb集群.
YCSB是Yahoo开发的一个专门用来对新一代数据库进行基准测试的工具。全名是Yahoo! Cloud Serving Benchmark。包括支持的数据库有:cassandra, hbase,mongodb,redis等数据库.YCSB的几大特性:
支持常见的数据库读写操作,如插入,修改,删除及读取
多线程支持。YCSB用Java实现,有很好的多线程支持。
灵活定义场景文件。可以通过参数灵活的指定测试场景,如100%插入, 50%读50%写等等
数据请求分布方式:支持随机,zipfian(只有小部分的数据得到大部分的访问请求)以及最新数据几种请求分布方式
可扩展性:可以通过扩展Workload的方式来修改或者扩展YCSB的功能
安装mongodb
个人建议直接装二进制版本就算了,方便简单,编译版就显得略麻烦了.
现在mongodb最新的正式版本是3.6的,个人觉得太新,这编文章测试用的还是3.2的版本,还请各位知照.
总下载地址:
https://www.mongodb.com/download-center?jmp=nav#community
记得是选择community server的版本,然后选取你的操作系统和系统的版本(我这里是rhel的linux),他只显示最新版的下载地址,你要下旧版就要点下面的All Version Binaries.
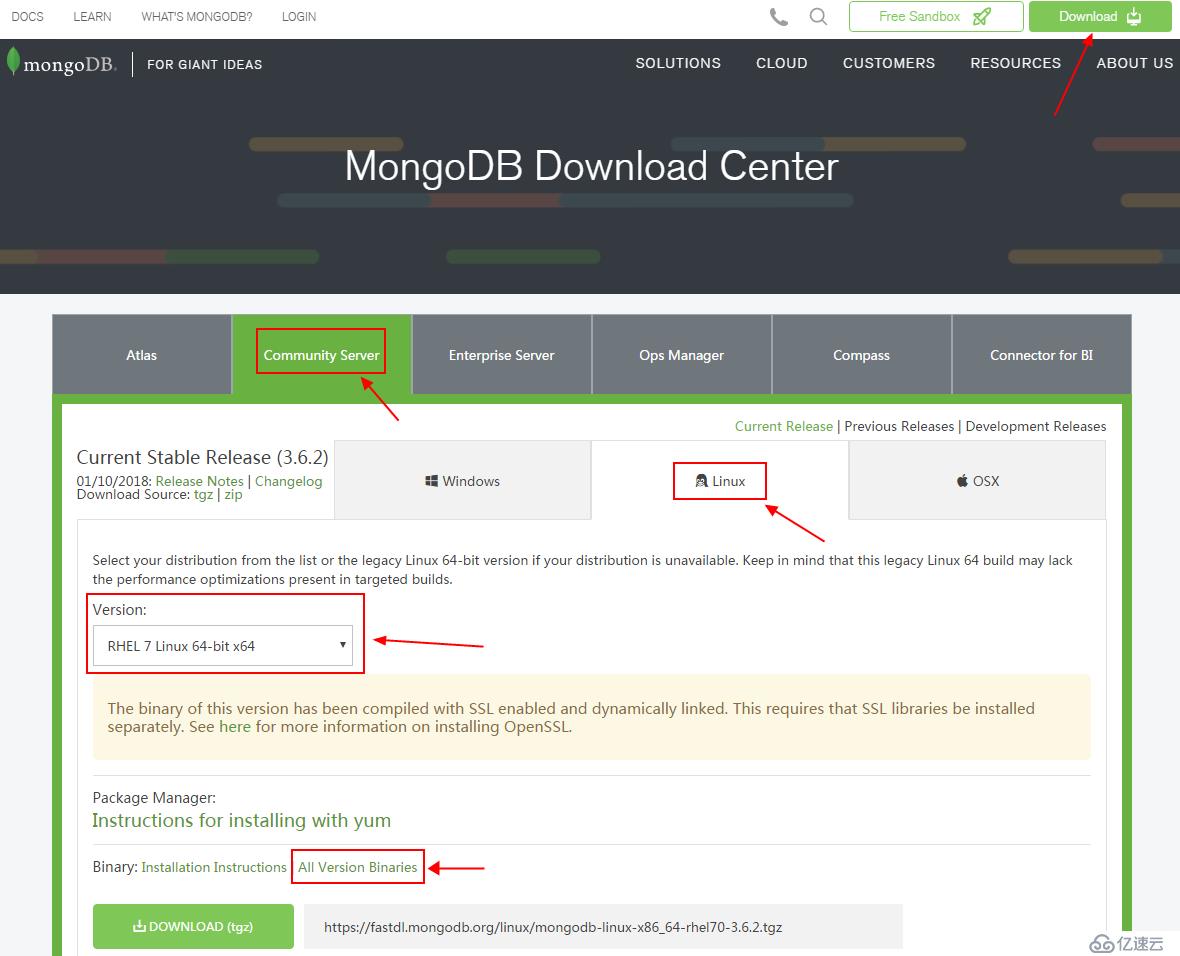
然后就有一堆地址,你自己选择需要的版本吧,例如我要下的是这个地址.
#在linux下用wget下载 wget http://downloads.mongodb.org/linux/mongodb-linux-x86_64-rhel70-3.2.18.tgz?_ga=2.240790083.1507844543.1517391237-2141045386.1517391237
下载完成,就开始安装了,因为是二进制版的,很简单就是了.
#先安装下依赖包,因为他是用c写的,主要就是C的东西了 yum -y install gcc gcc-c++ glibc glibc-devel glib2 glib2-devel #解压压缩包 tar xf mongodb-linux-x86_64-rhel70-3.2.18.tgz #把压缩包放到安装目录 mv mongodb-linux-x86_64-rhel70-3.2.18 /usr/local/ #创建安装目录的软连接 ln -sf /usr/local/mongodb-linux-x86_64-rhel70-3.2.18/ /usr/local/mongodb #创建命令文件的软连接,那就不用加到环境变量了 ln -sf /usr/local/mongodb/bin/* /usr/bin/ #创建用户 useradd mongodb #创建数据目录文件夹 mkdir -p /data/mongodb/data #更改文件夹属主权限 chown -R mongodb:mongodb /data/mongodb/ #修改资源限制参数,添加mongodb相关项 vim /etc/security/limits.conf mongod soft nofile 64000 mongod hard nofile 64000 mongod soft nproc 32000 mongod hard nproc 32000
这就安装完成了,后面就是初始化数据库了,初始化之前,必须先有配置文件,二进制版本安装的程序是不带配置文件模板的,所以就要自己编辑了,配置文件存放的位置可以随意,因为启动是需要指定位置的,例如下面这个:
#编辑配置文件,并指定位置 vim /usr/local/mongodb/mongod_data_40001.conf #数据目录 dbpath=/data/mongodb/data #日志文件 logpath=/data/mongodb/data/mongodb_data.log #日志形式为追加到文件后 logappend=true #端口 port = 40001 #指定访问地址,不指定就是全网,但是在3.6之后必须制定这个参数才能启动.0.0.0.0代表全网匹配 bind_ip = 0.0.0.0 #最大连接数 maxConns = 5000 pidfilepath = /data/mongodb/data/mongo_40001.pid #日志,redo log journal = true #刷写提交机制 journalCommitInterval = 200 #守护进程模式 fork = true #刷写数据到日志的频率 syncdelay = 60 #存储引擎,3.2之后默认就是wiredTiger #storageEngine = wiredTiger #操作日志,单位M oplogSize = 2000 #命名空间的文件大小,默认16M,最大2G。 nssize = 16 unixSocketPrefix = /tmp #指定一个数据库一个文件夹,必须在初始化前配置,在已有数据库上新增这个参数会报错 directoryperdb=true #开启慢查询分析功能,0:关闭,不收集任何数据。1:收集慢查询数据,默认是100毫秒.2:收集所有数据 profile=1 #慢查询的时间,单位ms,超过这个时间将被记录 slowms=200 #是否开启认证模式,不开就不用用户名密码就能登录数据库,测试环境可以不开 #auth = true #关闭认证模式,和上面的冲突 noauth = true #指定集群认证文件,没开认证就不用指定,注释关闭即可,需要用openssl来生成 #keyFile = /data/mongodb/data/keyfile #标识这台mongodb数据库为分片集群使用 #shardsvr = true #副本集名称,这里测的是单台,不设置 #replSet=shard1 #是否config端,做集群的配置端使用,后面详细介绍,这里不需要 #configsvr = true #禁止HTTP状态接口,3.6后不用 nohttpinterface=true #禁止REST接口-在生产环境下建议不要启用MongoDB的REST接口,,3.6后不用 rest=false #打开web监控,和上面相反,这里不开了 #httpinterface=true #rest=true
配置文件有了,就可以初始化启动了,因为我没有开启认证模式,启动就可以使用了.
#开启mongodb的数据端 mongod -f /usr/local/mongodb/mongod_data_40001.conf about to fork child process, waiting until server is ready for connections. forked process: 15808 child process started successfully, parent exiting #来测试一下 mongo --port=40001 MongoDB shell version: 3.2.18 connecting to: 127.0.0.1:40001/test Server has startup warnings: 2018-01-31×××1:12:12.537+0800 I CONTROL [initandlisten] > show dbs local 0.000GB
============分割线开始=============
其实官方是推荐下面这种启动方式,不过我为了方便,就简单化启动了.
#启动之前,要先把文件夹权限确保一下 chown mongodb:mongodb -R /data/mongodb/data/* #然后关闭numa并使用mongodb用户启动 su - mongodb -s /bin/bash -c "numactl --interleave=all /usr/local/mongodb/bin/mongod -f /usr/local/mongodb/mongod_data_40001.conf"
这种启动方式好处是显然的,对于数据库来说,最怕就是被***提权,然后控制整台机器,所以限制数据库的启动用户是很有意义的.
而numa这个功能,对于大内存应用是很不友好的,会变成性能瓶颈,所以无论是sql还是nosql都最好是关闭了这个功能,那性能就更好一些了.
===========分割线结束==============
然后,这个mongodb数据库就可以正常使用的了,当然,我们不是只使用单台mongodb.
开头也说了,90%的公司使用mongodb都是会使用到集群,在3.4版本之前,一般就用上面的配置就可以搭建集群,但是在3.4之后,如果不在启动的时候指定这是分片端,则分片集群就不能被正常使用.
#标识这台mongodb数据库为分片集群使用 shardsvr = true
只有开启了这个参数,分片集群才会正常使用.
如果,需要加载到服务启动项,就添加以下脚本:
vim /etc/init.d/mongod
#!/bin/sh
#
#mongod - Startup script for mongod
#
# chkconfig: - 85 15
# description: Mongodb database.
# processname: mongod
# Source function library
. /etc/rc.d/init.d/functions
mongod="/usr/local/mongodb/bin/mongod"
configfile=" -f /etc/mongod.conf"
lockfile=/var/lock/subsys/mongod
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent_hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo never > /sys/kernel/mm/transparent_hugepage/defrag
fi
ulimit -f unlimited
ulimit -t unlimited
ulimit -v unlimited
ulimit -n 64000
ulimit -m unlimited
ulimit -u 64000
ulimit -l unlimited
start()
{
echo -n $"Starting mongod: "
daemon --user mongod "$mongod $configfile"
retval=$?
echo
[ $retval -eq 0 ] && touch $lockfile
}
stop()
{
echo -n $"Stopping mongod: "
$mongod --shutdown $configfile
retval=$?
echo
[ $retval -eq 0 ] && rm -f $lockfile
}
restart () {
stop
start
}
case "$1" in
start)
start
;;
stop)
stop
;;
restart|reload|force-reload)
restart
;;
condrestart)
[ -f $lockfile ] && restart || :
;;
status)
status $mongod
retval=$?
;;
*)
echo "Usage: $0 {start|stop|status|restart|reload|force-reload|condrestart}"
retval=1
esac
exit $retval这样就可以chkconfig或者systemd了
搭建mongodb分片集群
先来介绍一下架构,需要三个角色,
配置服务器,config端,需要1台或3台,不能是双数,保存集群和分片的元数据,即各分片包含了哪些数据的信息,配置文件指定configsvr选项.
路由服务器,router端,随便多少台都行,本身不保存数据,在启动时从配置服务器加载集群信息,开启mongos进程需要知道配置服务器的地址,指定configdb选项.也可以理解为代理端
分片服务器,sharding端,保存真实数据信息,可以是一个副本集也可以是单独的一台服务器,支持主从故障切换.也可以叫数据端.
总共有8台机器,配置是8核16G的虚拟机.
10.21.1.205 config端(1)+router端(1)
10.21.1.206 sharding端(1)
10.21.1.207 sharding端(1)
10.21.1.208 sharding端(1)
10.21.1.209 sharding端(1)
10.21.1.210 sharding端(1)
10.21.1.211 sharding端(1)
10.21.1.212 sharding端(1)
由于是测试环境,不想纠结太复杂,config端和router端都是一台,当启动router端的时候会抛出一个警告,"只有一台config端的集群建议只用来测试",是的,我就是用来做测试.
sharding端我不打算详细说了,就按照上面安装mongodb的方式去操作并启动就ok,不需要额外的配置,只需要等配置端把他们地址加载就可以,然后就会自动连接并分配数据块起来,暂时也不需要研究其他东西.就是需要一台台去装就比较麻烦一点,各位自行操作.
1.配置并启动config端:
配置服务器也是一个mongod进程,其实也可以按照上面的配置文件来,配置服务器必须开启1个或则3个,开启2个则会报错,
BadValue need either 1 or 3 configdbs
所以要注意数量,这里我就设一个就算了.
#也和上面一样,没有模板,只能自己编辑 vim /usr/local/mongodb/mongod_config_20000.conf #数据目录,目录名字区分于数据节点 dbpath=/data/mongodb/config/ #日志文件 logpath=/data/mongodb/mongodb_config.log #日志追加 logappend=true #端口 port = 20000 #绑定ip,可以限制IP登录,例如bind_ip=10.21.1.208,3.2默认是允许所有ip登入,之后是允许127.0.0.1,只有配置0.0.0.0才是允许所有 bind_ip = 0.0.0.0 #最大连接数 maxConns = 5000 pidfilepath = /data/mongodb/mongo_20000.pid #日志,redo log journal = true #刷写提交机制 journalCommitInterval = 200 #守护进程模式 fork = true #刷写数据到日志的频率 syncdelay = 60 #存储引擎 #storageEngine = wiredTiger #操作日志,单位M oplogSize = 2000 #命名空间的文件大小,默认16M,最大2G。 nssize = 16 #套接字存放位置 unixSocketPrefix = /tmp #指定一个数据库一个文件夹,必须在初始化前配置,在已有数据库上新增这个参数会报错 directoryperdb=true #关闭认证模式,config端可以不需要,也视乎你的需求 noauth = true #是否config端,这里当然是了 configsvr = true #副本集名称,3.4之前可以不做集群,之后都需要设置config集群才可以使用 replSet=configs
其实和上面只是多了最后一行,标记是config端而已,然后启动.
#启动config端 mongod -f /usr/local/mongodb/mongod_config_20000.conf about to fork child process, waiting until server is ready for connections. forked process: 18535 child process started successfully, parent exiting
这里就不需要测试了,因为不需要在这里控制config端,然后看router端.
注意:3.4之后的版本使用分片集群,config端必须使用副本集,不然router端无法启动.
2.配置并启动router端:
路由服务器本身不保存数据,把日志记录一下即可,他都是直接调用config端来使用.而所有客户端程序想要连接mongodb集群,其实就是连接这个router端的端口来使用,并不是连接config端和sharding端,所以也说是类似于代理的形式.
#也和上面一样,没有模板,只能自己编辑 vim /usr/local/mongodb/mongos_route_30000.conf #日志文件 logpath=/data/mongodb/mongodb_route.log #日志追加 logappend=true #端口 port = 30000 #绑定ip,可以限制IP登录,例如bind_ip=10.21.1.208,3.2默认是允许所有ip登入,之后是允许127.0.0.1,只有配置0.0.0.0才是允许所有 bind_ip = 0.0.0.0 #最大连接数 maxConns = 5000 pidfilepath = /data/mongodb/mongo_30000.pid #指定config端地址,不能使用127.0.0.1,会报错,3.4后config必须是集群, #还必须在地址前面带上副本集名称,3.0和3.2可以点,例如:configdb=172.25.33.98:20000,单会提示警告 configdb=configs/172.25.33.98:20000,172.25.33.99:20000,172.25.33.101:20000 #守护进程模式 fork = true
最重要的参数是configdb,指定config端的地址,可以1个或3个,但是不能在其后面带的配置服务器的地址写成localhost或则127.0.0.1,需要设置成其他分片也能访问的地址,即10.21.1.205:20000/20001/20002。否则在添加分片地址的时候会报错.
然后是启动:
#启动方式略有不同,要使用mongos mongos -f /usr/local/mongodb/mongos_route_30000.conf 2018-02-01×××0:27:26.604+0800 W SHARDING [main] Running a sharded cluster with fewer than 3 config servers should only be done for testing purposes and is not recommended for production. about to fork child process, waiting until server is ready for connections. forked process: 6355 child process started successfully, parent exiting
启动完成后会看到个警告,不过这里可以忽略,就是我开头说的,提示你只有一台config的话只建议用来测试.原因就是这台config存储的是各分片的数据块信息,假如这台config挂了,那么各分片之间的数据块就不知道怎么关联了,是一个非常大的安全隐患,所以生产环境一定要保证有3台,最好还是错开在不同的服务器上面,提高安全性.
3.添加和配置分片信息
按上面的步骤启动完毕,那就可以开始配置分片了,当然,前提就是那些sharding端都已经全部部署启动完毕.然后,就登录进去操作了:
#使用客户端像一般登录mongodb那样操作,这里没有认证
mongo --port=30000 --host=10.21.1.205
MongoDB shell version: 3.2.18
connecting to: 10.21.1.205:30000/test
Server has startup warnings:
2018-02-01×××0:27:26.619+0800 I CONTROL [main]
mongos>
#看看现在的状态,现在当然是什么也没有
mongos>sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("5a69925ee61d3e7c0519035a")
}
shards:
active mongoses:
"3.2.18" : 1
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 0
Migration Results for the last 24 hours:
No recent migrations
databases:然后,我们来添加分片,sh.addShard("IP:Port")
#添加分片,如此类推
mongos> sh.addShard("10.21.1.206:40001")
{ "shardAdded" : "shard0000", "ok" : 1 }
mongos> sh.addShard("10.21.1.207:40001")
{ "shardAdded" : "shard0001", "ok" : 1 }
mongos> sh.addShard("10.21.1.208:40001")
{ "shardAdded" : "shard0002", "ok" : 1 }
.
.
.
#全部加完了,看看状态,
mongos>sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("5a69925ee61d3e7c0519035a")
}
shards:
{ "_id" : "shard0000", "host" : "10.21.1.206:40001" }
{ "_id" : "shard0001", "host" : "10.21.1.207:40001" }
{ "_id" : "shard0002", "host" : "10.21.1.208:40001" }
{ "_id" : "shard0003", "host" : "10.21.1.209:40001" }
{ "_id" : "shard0004", "host" : "10.21.1.210:40001" }
{ "_id" : "shard0005", "host" : "10.21.1.211:40001" }
{ "_id" : "shard0006", "host" : "10.21.1.212:40001" }
active mongoses:
"3.2.18" : 1
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 0
Migration Results for the last 24 hours:
No recent migrations
databases:这个时候,7个分片都添加完毕,不过,现在还没有数据库,所以还要创建数据库和数据库的片键.创建数据库应该还能理解,片键是什么,下面来简单解析一下:
片键必须是一个索引,数据根据这个片键进行拆分分散。通过sh.shardCollection加会自动创建索引。一个自增的片键对写入和数据均匀分布就不是很好,因为自增的片键总会在一个分片上写入,后续达到某个阀值可能会写到别的分片。但是按照片键查询会非常高效。随机片键对数据的均匀分布效果很好。注意尽量避免在多个分片上进行查询。在所有分片上查询,mongos会对结果进行归并排序。也可以说是分片的规则字段了.
=============分割线开始==================
需要特别注意的一点是,有些mongodb是用root启动的,所以数据库的文件权限也是root,这样就可能会造成一种奇葩现象,连接不正常,数据异常等,所以我们要确保数据库文件权限是mongodb的.
#关闭mongodb killall mongod #删掉锁文件 rm -rf /data/mongodb/data/*.lock #更改文件夹权限 chown mongodb:mongodb -R /data/mongodb/* #启动 mongod -f /usr/local/mongodb/mongod_data_40001.conf
当然是包括config端的了.
=============分割线结束===================
然后,我们就创建数据库并开启分片功能,一条命令就可以,最后再添加个片键就可以用了,命令是sh.enableSharding("库名")、sh.shardCollection("库名.集合名",{"key":1})
#创建一个ycsb的数据库,并启动他的分片功能
mongos>sh.enableSharding("ycsb")
{ "ok" : 1 }
#添加这个数据库的片键为_id,规则是hash
mongos>sh.shardCollection("ycsb.usertable", {_id:"hashed"})
{ "collectionsharded" : "ycsb.usertable", "ok" : 1 }
###########################################
#假如你已经创建了一个,现在需要重建,那就要先删除旧的数据库了
#mongos> use ycsb
#switched to db ycsb
#mongos> db.dropDatabase()
#{ "dropped" : "ycsb", "ok" : 1 }
#mongos> show dbs
#config 0.013GB
###########################################==============分割线开始==================
在mongodb单纯创建数据库和表,并不需要另外的create命令操作,只需要直接插入一条数据就好了,也就代表创建成功
#当前没有新的数据库
> show dbs
admin 0.000GB
local 0.000GB
#单纯切换到数据库,也算是新建数据库的了
> use foo
switched to db foo
> db
foo
#但是这个时候,你还是看不到的
> show dbs
admin 0.000GB
local 0.000GB
#插入一条数据,createtmp是要新建的表名,
> db.createtmp.insert({"name":"create database"})
WriteResult({ "nInserted" : 1 })
#你就能看到了
> show dbs
foo 0.000GB
admin 0.000GB
local 0.000GB
#而且你的表也创建好了
> show collections
createtmp不过,我们如果做分片的话,一开始有表是不合适的,因为要做片键,所以才在这里另外来说这个问题.
==============分割线结束==================
这样添加的原因是后面的ycsb测试工具的需要,他会生成一个名为ycsb的数据库,里面有一个usertable集合(表),然后其中有_id这个列,至于hash规则我想就不解析了.然后,在看看状态:
#看看现在的状态,很长
mongos>sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("5a69925ee61d3e7c0519035a")
}
shards:
{ "_id" : "shard0000", "host" : "10.21.1.206:40001" }
{ "_id" : "shard0001", "host" : "10.21.1.207:40001" }
{ "_id" : "shard0002", "host" : "10.21.1.208:40001" }
{ "_id" : "shard0003", "host" : "10.21.1.209:40001" }
{ "_id" : "shard0004", "host" : "10.21.1.210:40001" }
{ "_id" : "shard0005", "host" : "10.21.1.211:40001" }
{ "_id" : "shard0006", "host" : "10.21.1.212:40001" }
active mongoses:
"3.2.18" : 1
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 5
Last reported error: Connection refused
Time of Reported error: Thu Feb 01 2018 14:26:07 GMT+0800 (CST)
Migration Results for the last 24 hours:
databases:
{ "_id" : "ycsb", "primary" : "shard0000", "partitioned" : true }
ycsb.usertable
shard key: { "_id" : "hashed" }
unique: false
balancing: true
chunks:
shard0000 2
shard0001 2
shard0002 2
shard0003 2
shard0004 2
shard0005 2
shard0006 2
{ "_id" : { "$minKey" : 1 } } -->> { "_id" : NumberLong("-7905747460161236400") } on : shard0000 Timestamp(7, 2)
{ "_id" : NumberLong("-7905747460161236400") } -->> { "_id" : NumberLong("-6588122883467697000") } on : shard0000 Timestamp(7, 3)
{ "_id" : NumberLong("-6588122883467697000") } -->> { "_id" : NumberLong("-5270498306774157600") } on : shard0001 Timestamp(7, 4)
{ "_id" : NumberLong("-5270498306774157600") } -->> { "_id" : NumberLong("-3952873730080618200") } on : shard0001 Timestamp(7, 5)
{ "_id" : NumberLong("-3952873730080618200") } -->> { "_id" : NumberLong("-2635249153387078800") } on : shard0002 Timestamp(7, 6)
{ "_id" : NumberLong("-2635249153387078800") } -->> { "_id" : NumberLong("-1317624576693539400") } on : shard0002 Timestamp(7, 7)
{ "_id" : NumberLong("-1317624576693539400") } -->> { "_id" : NumberLong(0) } on : shard0003 Timestamp(7, 8)
{ "_id" : NumberLong(0) } -->> { "_id" : NumberLong("1317624576693539400") } on : shard0003 Timestamp(7, 9)
{ "_id" : NumberLong("1317624576693539400") } -->> { "_id" : NumberLong("2635249153387078800") } on : shard0004 Timestamp(7, 10)
{ "_id" : NumberLong("2635249153387078800") } -->> { "_id" : NumberLong("3952873730080618200") } on : shard0004 Timestamp(7, 11)
{ "_id" : NumberLong("3952873730080618200") } -->> { "_id" : NumberLong("5270498306774157600") } on : shard0005 Timestamp(7, 12)
{ "_id" : NumberLong("5270498306774157600") } -->> { "_id" : NumberLong("6588122883467697000") } on : shard0005 Timestamp(7, 13)
{ "_id" : NumberLong("6588122883467697000") } -->> { "_id" : NumberLong("7905747460161236400") } on : shard0006 Timestamp(7, 14)
{ "_id" : NumberLong("7905747460161236400") } -->> { "_id" : { "$maxKey" : 1 } } on : shard0006 Timestamp(7, 15)
#看看有什么数据库
mongos> show dbs
config 0.007GB
ycsb 0.000GB
#登进目标数据库
mongos> use ycsb
switched to db ycsb
#查看数据库的状态
mongos> db.stats()
{
"raw" : {
"10.21.1.206:40001" : {
"db" : "ycsb",
"collections" : 1,
"objects" : 0,
"avgObjSize" : 0,
"dataSize" : 0,
"storageSize" : 4096,
"numExtents" : 0,
"indexes" : 2,
"indexSize" : 8192,
"ok" : 1
},
"10.21.1.207:40001" : {
"db" : "ycsb",
"collections" : 1,
"objects" : 0,
"avgObjSize" : 0,
"dataSize" : 0,
"storageSize" : 4096,
"numExtents" : 0,
"indexes" : 2,
"indexSize" : 8192,
"ok" : 1
},
"10.21.1.208:40001" : {
"db" : "ycsb",
"collections" : 1,
"objects" : 0,
"avgObjSize" : 0,
"dataSize" : 0,
"storageSize" : 4096,
"numExtents" : 0,
"indexes" : 2,
"indexSize" : 8192,
"ok" : 1
},
"10.21.1.209:40001" : {
"db" : "ycsb",
"collections" : 1,
"objects" : 0,
"avgObjSize" : 0,
"dataSize" : 0,
"storageSize" : 4096,
"numExtents" : 0,
"indexes" : 2,
"indexSize" : 8192,
"ok" : 1
},
"10.21.1.210:40001" : {
"db" : "ycsb",
"collections" : 1,
"objects" : 0,
"avgObjSize" : 0,
"dataSize" : 0,
"storageSize" : 4096,
"numExtents" : 0,
"indexes" : 2,
"indexSize" : 8192,
"ok" : 1
},
"10.21.1.211:40001" : {
"db" : "ycsb",
"collections" : 1,
"objects" : 0,
"avgObjSize" : 0,
"dataSize" : 0,
"storageSize" : 4096,
"numExtents" : 0,
"indexes" : 2,
"indexSize" : 8192,
"ok" : 1
},
"10.21.1.212:40001" : {
"db" : "ycsb",
"collections" : 1,
"objects" : 0,
"avgObjSize" : 0,
"dataSize" : 0,
"storageSize" : 4096,
"numExtents" : 0,
"indexes" : 2,
"indexSize" : 8192,
"ok" : 1
}
},
"objects" : 0,
"avgObjSize" : 0,
"dataSize" : 0,
"storageSize" : 28672,
"numExtents" : 0,
"indexes" : 14,
"indexSize" : 57344,
"fileSize" : 0,
"extentFreeList" : {
"num" : 0,
"totalSize" : 0
},
"ok" : 1
}好了,至此,mongodb的分片集群已经搭建好,暂时还没有数据,objects显示是0就是没数据了,各分片也没有数据.
不过,有时候会因为信息太长而导致显示不全,并提示
too many chunks to print, use verbose if you want to force print
那么我们就要用下列命令来显示了,三个都可以,然后就显示全部了,但是更长.
mongos> sh.status({"verbose":1})
mongos> db.printShardingStatus("vvvv")
mongos> printShardingStatus(db.getSisterDB("config"),1)4.删除分片信息
最后来看删除分片,有添加,就当然有删除了,虽然不是这里的重点, db.runCommand({"removeshard":"mmm"})
#登进管理数据库admin,3.2隐藏了,不过确实存在.
mongos> use admin
switched to db admin
mongos> db
admin
#删除刚才添加的一个分片,注意state状态,是准备删除,将不会有新数据进入该分片
mongos> db.runCommand({"removeshard":"shard0006"})
{
"msg" : "draining started successfully",
"state" : "started",
"shard" : "shard0006",
"note" : "you need to drop or movePrimary these databases",
"dbsToMove" : [ ],
"ok" : 1
}
#这个时候,状态已经改变成draining,但是还没有删除,只是新数据不再写入进去
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("5a69925ee61d3e7c0519035a")
}
shards:
{ "_id" : "shard0000", "host" : "10.21.1.206:40001" }
{ "_id" : "shard0001", "host" : "10.21.1.207:40001" }
{ "_id" : "shard0002", "host" : "10.21.1.208:40001" }
{ "_id" : "shard0003", "host" : "10.21.1.209:40001" }
{ "_id" : "shard0004", "host" : "10.21.1.210:40001" }
{ "_id" : "shard0005", "host" : "10.21.1.211:40001" }
{ "_id" : "shard0006", "host" : "10.21.1.212:40001", "draining" : true }
active mongoses:
"3.2.18" : 1
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 0
Migration Results for the last 24 hours:
.
.
.
#再操作一次,这次将会完全删除,
#如果里面没数据,会显示state状态为completed,
mongos> db.runCommand({"removeshard":"shard0006"})
{
"msg" : "removeshard completed successfully",
"state" : "completed",
"shard" : "shard0006",
"ok" : 1
}
#如果有数据,则会等到迁移完才会执行通过,取决于数据量多不多,显示state状态为ongoing
mongos> db.runCommand({"removeshard":"shard0006"})
{
"msg" : "draining ongoing",
"state" : "ongoing",
"remaining" : {
"chunks" : NumberLong(2128),
"dbs" : NumberLong(0)
},
"note" : "you need to drop or movePrimary these databases",
"dbsToMove" : [ ],
"ok" : 1
}
#删除完毕后,再次查看,id为shard0006的分片已经被删除,
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("5a69925ee61d3e7c0519035a")
}
shards:
{ "_id" : "shard0000", "host" : "10.21.1.206:40001" }
{ "_id" : "shard0001", "host" : "10.21.1.207:40001" }
{ "_id" : "shard0002", "host" : "10.21.1.208:40001" }
{ "_id" : "shard0003", "host" : "10.21.1.209:40001" }
{ "_id" : "shard0004", "host" : "10.21.1.210:40001" }
{ "_id" : "shard0005", "host" : "10.21.1.211:40001" }
active mongoses:
"3.2.18" : 1
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 0
Migration Results for the last 24 hours:
.
.
.
#这里显示也没有了该分片地址了
mongos> db.runCommand({ listshards : 1 })
{
"shards" : [
{
"_id" : "shard0000",
"host" : "10.21.1.206:40001"
},
{
"_id" : "shard0001",
"host" : "10.21.1.207:40001"
},
{
"_id" : "shard0002",
"host" : "10.21.1.208:40001"
},
{
"_id" : "shard0003",
"host" : "10.21.1.209:40001"
},
{
"_id" : "shard0004",
"host" : "10.21.1.210:40001"
},
{
"_id" : "shard0005",
"host" : "10.21.1.211:40001"
}
],
"ok" : 1
}需要注意的是,不能同时删除两个或以上的分片,只有删除完一个后,另一个才可以开始删除.
另外,分片还有迁移功能,可以是整个迁移或迁移某一个块chunks(sh.moveChunk("db.collection",{块地址},"新片名称")),这里不打算展开来说,日常使用中,这种操作也基本上很少涉及,基本上都让均衡器balancer自己去跑就算了.
需要特别注意的是删除主分片,则需要先迁移走数据库到别的分片,
db.adminCommand({"movePrimary":"ycsb","to":"shard0001"})这样才能删主分片.
安装删除都完成了,后面来看ycsb要怎么使用了.
搭建ycsb环境
ycsb程序本身是python+java的结合体,是不是很奇怪?主要测试的对象是nosql系列数据库:cassandra, hbase,mongodb,redis这些.程序本身也是二进制版,python其实yum一下也行了,主要就是java了.
由于java的下载地址经常变,包的容量也不少,所以就只给个官方总地址了,去下java se的包就可以了,虽然已经出了9,但是我还是觉得用8就算了.
http://www.oracle.com/technetwork/java/javase/downloads
#安装python环境 yum install -y python python-devel #安装java tar xf jdk-8u144-linux-x64.tar.gz mv jdk1.8.0_144/ /usr/local/ ln -sf /usr/local/jdk1.8.0_144/ /usr/local/jdk #创建java环境变量 vim /etc/profile.d/java.sh export JAVA_HOME=/usr/local/jdk export JRE_HOME=/usr/local/jdk/jre export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib export PATH=$PATH:$JAVA_HOME/bin #重载环境变量 source /etc/profile #测试一下 java -version java version "1.8.0_144" Java(TM) SE Runtime Environment (build 1.8.0_144-b01) Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
前置的环境安装完毕,就来看怎么安装ycsb了,和java有点像,而且还不用做环境变量,其实我觉得也不能叫安装,直接解压就能用了,现在最新版本是ycsb-0.12.0
#下载ycsb wget https://github.com/brianfrankcooper/YCSB/releases/download/0.12.0/ycsb-0.12.0.tar.gz #解压 tar xf ycsb-0.12.0.tar.gz #查看目录结构 ll ycsb-0.12.0 total 12 drwxr-xr-x. 4 root root 46 Jan 30 11:23 accumulo-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 aerospike-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 arangodb-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 asynchbase-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 azuretablestorage-binding drwxr-xr-x. 2 root root 76 Feb 1 18:01 bin drwxr-xr-x. 3 root root 34 Jan 30 11:23 cassandra-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 couchbase2-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 couchbase-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 dynamodb-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 elasticsearch-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 geode-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 googlebigtable-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 googledatastore-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 hbase094-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 hbase098-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 hbase10-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 hypertable-binding drwxr-xr-x. 4 root root 46 Jan 30 11:23 infinispan-binding drwxr-xr-x. 4 root root 46 Jan 30 11:23 jdbc-binding drwxr-xr-x. 4 root root 46 Jan 30 11:23 kudu-binding drwxr-xr-x. 2 root root 170 Jan 30 11:23 lib -rw-r--r--. 1 501 games 8082 Jan 21 2015 LICENSE.txt drwxr-xr-x. 3 root root 34 Jan 30 11:23 memcached-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 mongodb-binding drwxr-xr-x. 4 root root 46 Jan 30 11:23 nosqldb-binding -rw-r--r--. 1 501 games 615 Sep 27 2016 NOTICE.txt drwxr-xr-x. 3 root root 34 Jan 30 11:23 orientdb-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 rados-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 redis-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 rest-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 riak-binding drwxr-xr-x. 4 root root 46 Jan 30 11:23 s3-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 solr6-binding drwxr-xr-x. 3 root root 34 Jan 30 11:23 solr-binding drwxr-xr-x. 4 root root 46 Jan 30 11:23 tarantool-binding drwxr-xr-x. 2 501 games 183 Feb 2 11:19 workloads #和一般程序差不多,bin目录就是命令目录了 ll /opt/ycsb-0.12.0/bin/ total 36 -rw-r--r--. 1 501 games 2672 Nov 1 2016 bindings.properties -rwxr-xr-x. 1 501 games 12572 Nov 1 2016 ycsb -rwxr-xr-x. 1 501 games 6431 Sep 30 2016 ycsb.bat -rwxr-xr-x. 1 501 games 7458 Sep 30 2016 ycsb.sh
其他目录暂时就不研究,不过从字面意思可以理解一些,其实就是各种数据库的驱动.后面来看怎么使用了.
使用ycsb
1.使用简介
使用前,我们要先了解他的命令结构,我们才能知道怎么做才能达到效果.有点类似于测试mysql数据库的sysbench
bin/ycsb load/run/shell mongodb/hbase10/basic.. mongodb.url="mongodb://user:pwd@server1.example.com:9999" -P workloads/workloada -s
第一项,bin/ycsb,就不用解析了,就是命令本身.
第二项,load/run/shell,指定这个命令的作用,加载数据/运行测试/交互界面,类似sysbench
第三项,mongodb/hbase10/basic..指定这次测试使用的驱动,也就是这次究竟测的是什么数据库,有很多选项,可以ycsb --help看到所有
第四项,mongodb.url,指定测试的数据库的认证信息,地址端口和用户密码,这里拿的是mongodb的来做演示
第五项,-P workloads/workloada,指定测试的参数文件,默认有6种测试模板,加一个大模板,都可以vim打开来看,大致为:
workloada:读写均衡型,50%/50%,Reads/Writes
workloadb:读多写少型,95%/5%,Reads/Writes
workloadc:只读型,100%,Reads
workloadd:读最近写入记录型,95%/5%,Reads/insert
workloade:扫描小区间型,95%/5%,scan/insert
workloadf:读写入记录均衡型,50%/50%,Reads/insert
workload_template:参数列表模板
第六项,-s,每10秒打印报告一次到屏幕,可以ycsb --help看到
2.测试参数解析
看了上面的解析,就可以看出来,问题的重点是第五项,-P workloads/workloada,这里编辑好,那压测效果才会出来,那么里面有些什么呢,西面来看看:
#打开这个文件来看
vim workloads/workloada
#YCSB load(加载元数据)命令的参数,表示加载的记录条数,也就是可用于测试的总记录数。
recordcount=1000000
#YCSB run(运行压力测试)命令的参数,测试的总次数。和maxexecutiontime参数有冲突,谁先完成就中断测试退出,结合下面的增改读扫参数,按比例来操作.
#operationcount=1000000
#测试的总时长,单位为秒,和operationcount参数有冲突,谁先完成就中断测试退出,这里3600秒就代表一小时,也是结合下面的增改读扫参数,按比例来操作.
maxexecutiontime=3600
#java相关参数,指定了workload的实现类为 com.yahoo.ycsb.workloads.CoreWorkload
workload=com.yahoo.ycsb.workloads.CoreWorkload
#表示查询时是否读取记录的所有字段
readallfields=true
#表示读操作的比例,该场景为0.54,即54%
readproportion=0.54
#表示更新操作的比例,该场景为0.2,即20%
updateproportion=0.2
#表示扫描操作的比例,即1%,通常是用来模拟没有索引的查询
scanproportion=0.01
#表示插入操作的比例,即25%
insertproportion=0.25
#表示请求的分布模式,YCSB提供uniform(随机均衡读写),zipfian(偏重读写少量热数据),latest(偏重读写最新数据)三种分布模式
requestdistribution=uniform
#插入文档的顺序方式:哈希(hashed)/随机 (insertorder)
insertorder=hashed
#测试数据的每一个字段的长度,单位字节
fieldlength=2000
#测试数据的每条记录的字段数,也就是说一条记录的总长度是2000*10=20000字节
fieldcount=10
#####################以下是不自带的参数#############################
#把数据库连接地址写到这里,那么输命令的时候就不用输地址了,我这里没有设用户名密码,当然是不需要了
mongodb.url=mongodb://10.21.1.205:30000/ycsb?w=0
#如果你是有很多个mongos的话,就要这样写
#mongodb.url=mongodb://172.25.31.101:30000,172.25.31.102:30000,172.25.31.103:30000/ycsb?w=0
#如果是有用户名密码的话,就要这样写,还记得上面一开始的模板嘛,mongodb://user:pwd@server1.example.com:9999
#mongodb.url=mongodb://ycsbtest:ycsbtest@10.21.1.205:30000/ycsb?w=0
#写安全设置,Unacknowledged(不返回用户是否写入成功{w:0}),Acknowledged(写入到主节点内存就返回写入成功{w:1}),Journaled(写入到主节点journal log才返回写入成功{w:1,j:true}),Replica Acknowledged(写入到所有副本集内存和主节点journal log才返回写入成功{w:2}),Available Write Concern(写入到所有节点journal log才返回写入成功{w:2,j:true}),选项越往后,安全性越高,但是性能越差.
mongodb.writeConcern=acknowledged
#线程数,也就是说100个并发,既然是压测,怎么可能是单线程
threadcount=100还有一些参数没列出,然后我们得出自己需要的参数文件,这个是100%纯插入1亿条记录的参数文件,如下所示:
#100%纯插入的参数文件 vim workloads/mongotest_in_only #定个小目标,比如1个亿,插入1亿条文档数据 recordcount=100000000 operationcount=100000000 workload=com.yahoo.ycsb.workloads.CoreWorkload readallfields=true readproportion=0 updateproportion=0 scanproportion=0 #只有插入的操作,1就是100% insertproportion=1 requestdistribution=uniform insertorder=hashed fieldlength=250 fieldcount=8 mongodb.url=mongodb://10.21.1.205:30000/ycsb?w=0 mongodb.writeConcern=acknowledged threadcount=100
每个文档大小大约2KB(fieldlength x fieldcount),数据总大小大概是200G+12G的索引,数量还是比较多,如果是单点,估计是比较难撑,查询也超级慢.但是做了分片的话,程序会自动分配,把他们平均分配到每一个分片中,那么压力就减轻很多了,分布式架构的优势出来了.
3.执行纯插入测试
上面我自己写的配置文件,就是为了做插入测试,总共7个分片,插入1亿条数据,花了两个多小时,看来时间还是要预足够.
#执行下面命令进行插入测试 bin/ycsb load mongodb -P workloads/mongotest_in_only -s > /home/logs/mongo_ycsb20180131-1.log & /usr/local/jdk/bin/java -cp /opt/ycsb-0.12.0/mongodb-binding/conf:/opt/ycsb-0.12.0/conf:/opt/ycsb-0.12.0/lib/core-0.12.0.jar:/opt/ycsb-0.12.0/lib/htrace-core4-4.1.0-incubating.jar:/opt/ycsb-0.12.0/lib/jackson-mapper-asl-1.9.4.jar:/opt/ycsb-0.12.0/lib/jackson-core-asl-1.9.4.jar:/opt/ycsb-0.12.0/lib/HdrHistogram-2.1.4.jar:/opt/ycsb-0.12.0/mongodb-binding/lib/logback-classic-1.1.2.jar:/opt/ycsb-0.12.0/mongodb-binding/lib/logback-core-1.1.2.jar:/opt/ycsb-0.12.0/mongodb-binding/lib/mongo-java-driver-3.0.3.jar:/opt/ycsb-0.12.0/mongodb-binding/lib/mongodb-async-driver-2.0.1.jar:/opt/ycsb-0.12.0/mongodb-binding/lib/slf4j-api-1.6.4.jar:/opt/ycsb-0.12.0/mongodb-binding/lib/mongodb-binding-0.12.0.jar com.yahoo.ycsb.Client -db com.yahoo.ycsb.db.MongoDbClient -P workloads/mongotest_in_only -s -load YCSB Client 0.12.0 Command line: -db com.yahoo.ycsb.db.MongoDbClient -P workloads/mongotest_in_only -s -load Loading workload... Starting test. 2018-02-02 11:19:40:314 0 sec: 0 operations; est completion in 0 seconds 2018-02-02 11:19:50:233 10 sec: 57123 operations; 5703.74 current ops/sec; est completion in 4 hours 52 minutes [INSERT: Count=57144, Max=1724415, Min=150, Avg=12858.59, 90=621, 99=416511, 99.9=1072127, 99.99=1367039] 2018-02-02 11:20:00:218 20 sec: 188182 operations; 13125.59 current ops/sec; est completion in 2 hours 56 minutes [INSERT: Count=131051, Max=2009087, Min=35, Avg=6348.01, 90=206, 99=140159, 99.9=1202175, 99.99=1803263] 2018-02-02 11:20:11:036 30 sec: 370000 operations; 18181.8 current ops/sec; est completion in 2 hours 14 minutes [INSERT: Count=181818, Max=2965503, Min=30, Avg=5638.81, 90=122, 99=371, 99.9=1506303, 99.99=2301951] 2018-02-02 11:20:20:223 40 sec: 576572 operations; 20646.88 current ops/sec; est completion in 1 hours 54 minutes [INSERT: Count=206574, Max=4304895, Min=27, Avg=3766.68, 90=109, 99=276, 99.9=1126399, 99.99=1978367] 2018-02-02 11:20:31:659 51 sec: 747015 operations; 14904.07 current ops/sec; est completion in 1 hours 53 minutes [INSERT: Count=170445, Max=5423103, Min=27, Avg=6511.35, 90=107, 99=276, 99.9=2037759, 99.99=3981311] . . . 2018-02-02 13:10:50:218 6670 sec: 99794282 operations; 17292.1 current ops/sec; est completion in 14 seconds [CLEANUP: Count=12, Max=3, Min=2, Avg=2.58, 90=3, 99=3, 99.9=3, 99.99=3] [INSERT: Count=172921, Max=1833983, Min=18, Avg=1729.1, 90=50, 99=202, 99.9=783871, 99.99=1312767] 2018-02-02 13:11:00:218 6680 sec: ×××5363 operations; 13108.1 current ops/sec; est completion in 5 seconds [CLEANUP: Count=16, Max=4, Min=2, Avg=3, 90=4, 99=4, 99.9=4, 99.99=4] [INSERT: Count=131081, Max=1249279, Min=19, Avg=1336.59, 90=54, 99=152, 99.9=607231, 99.99=1011711] 2018-02-02 13:11:10:218 6690 sec: 99972913 operations; 4755 current ops/sec; est completion in 2 seconds [CLEANUP: Count=5, Max=5, Min=4, Avg=4.2, 90=5, 99=5, 99.9=5, 99.99=5] [INSERT: Count=47550, Max=898559, Min=21, Avg=1097.42, 90=78, 99=136, 99.9=512511, 99.99=825855] 2018-02-02 13:11:20:218 6700 sec: 99995467 operations; 2255.4 current ops/sec; est completion in 1 seconds [CLEANUP: Count=2, Max=4, Min=4, Avg=4, 90=4, 99=4, 99.9=4, 99.99=4] [INSERT: Count=22554, Max=752127, Min=24, Avg=850.14, 90=68, 99=106, 99.9=500223, 99.99=642559] 2018-02-02 13:11:23:489 6703 sec: 100000000 operations; 1385.39 current ops/sec; [CLEANUP: Count=1, Max=5411, Min=5408, Avg=5410, 90=5411, 99=5411, 99.9=5411, 99.99=5411] [INSERT: Count=4533, Max=527871, Min=20, Avg=821.06, 90=61, 99=90, 99.9=466175, 99.99=527871]
中间很多行暂时先忽略,因为是会一致输出到运行完毕为止,来看运行解读,每一个项都用分号;来隔开,直接拿例子来说说.这是第二行的数据:
第一个分号前的数值:2018-02-02 11:20:00:218 20 sec: 188182 operations;
表示"当前的时间,已运行的时间,运行的数据量"三个值,而-s参数默认是每10秒输出一次,直到这1亿数据写完就停止.
第二个分号前的数值:13125.59 current ops/sec;
表示吞吐量信息,也就是常说的ops值(每秒操作次数),可以用他来做趋势图,看看这个集群的趋势.
后面的所有:est completion in 2 hours 56 minutes [INSERT: Count=131051, Max=2009087, Min=35, Avg=6348.01, 90=206, 99=140159, 99.9=1202175, 99.99=1803263]
表示预估执行时间,进行了什么操作(这里只有insert),总共操作了多少数据,操作的时间和延时等数据,意义不大,只做参考.
4.执行纯读测试
配置文件和上面可以保持大体一致即可,只修改下面这里
#只读,1即100 readproportion=1 updateproportion=0 scanproportion=0 insertproportion=0
然后就可以执行了
#执行下面命令进行只读测试 bin/ycsb run mongodb -P workloads/mongotest_re_only -s > /home/logs/mongo_ycsb20180201-1.log & /usr/local/jdk/bin/java -cp /opt/ycsb-0.12.0/mongodb-binding/conf:/opt/ycsb-0.12.0/conf:/opt/ycsb-0.12.0/lib/core-0.12.0.jar:/opt/ycsb-0.12.0/lib/htrace-core4-4.1.0-incubating.jar:/opt/ycsb-0.12.0/lib/jackson-mapper-asl-1.9.4.jar:/opt/ycsb-0.12.0/lib/jackson-core-asl-1.9.4.jar:/opt/ycsb-0.12.0/lib/HdrHistogram-2.1.4.jar:/opt/ycsb-0.12.0/mongodb-binding/lib/logback-classic-1.1.2.jar:/opt/ycsb-0.12.0/mongodb-binding/lib/logback-core-1.1.2.jar:/opt/ycsb-0.12.0/mongodb-binding/lib/mongo-java-driver-3.0.3.jar:/opt/ycsb-0.12.0/mongodb-binding/lib/mongodb-async-driver-2.0.1.jar:/opt/ycsb-0.12.0/mongodb-binding/lib/slf4j-api-1.6.4.jar:/opt/ycsb-0.12.0/mongodb-binding/lib/mongodb-binding-0.12.0.jar com.yahoo.ycsb.Client -db com.yahoo.ycsb.db.MongoDbClient -P workloads/mongotest_re_only -s -t YCSB Client 0.12.0 Command line: -db com.yahoo.ycsb.db.MongoDbClient -P workloads/mongotest_re_only -s -t Loading workload... Starting test. 2018-02-02 14:14:03:394 0 sec: 0 operations; est completion in 0 seconds 2018-02-02 14:14:13:316 10 sec: 52718 operations; 5271.8 current ops/sec; est completion in 5 hours 15 minutes [READ: Count=52726, Max=515839, Min=886, Avg=17807.9, 90=32959, 99=84223, 99.9=215551, 99.99=422655] 2018-02-02 14:14:23:315 20 sec: 136267 operations; 8354.9 current ops/sec; est completion in 4 hours 4 minutes [READ: Count=83543, Max=71231, Min=740, Avg=11962.2, 90=22063, 99=39167, 99.9=52863, 99.99=65919] 2018-02-02 14:14:33:315 30 sec: 227979 operations; 9171.2 current ops/sec; est completion in 3 hours 38 minutes [READ: Count=91710, Max=60479, Min=969, Avg=10899.01, 90=18143, 99=29439, 99.9=45055, 99.99=55839] 2018-02-02 14:14:43:315 40 sec: 319725 operations; 9174.6 current ops/sec; est completion in 3 hours 27 minutes [READ: Count=91747, Max=57215, Min=1036, Avg=10890.33, 90=17919, 99=27007, 99.9=36031, 99.99=49023] 2018-02-02 14:14:53:318 50 sec: 411156 operations; 9141.27 current ops/sec; est completion in 3 hours 21 minutes [READ: Count=91439, Max=51039, Min=1052, Avg=10932.95, 90=17983, 99=27887, 99.9=37375, 99.99=44639] . . . 2018-02-02 17:18:53:315 11090 sec: 99690172 operations; 8923 current ops/sec; est completion in 35 seconds [READ: Count=89229, Max=59263, Min=920, Avg=11199.31, 90=18879, 99=30383, 99.9=43423, 99.99=53631] 2018-02-02 17:19:03:315 11100 sec: 99779154 operations; 8898.2 current ops/sec; est completion in 25 seconds [READ: Count=88982, Max=69119, Min=914, Avg=11232.26, 90=18959, 99=30303, 99.9=42975, 99.99=54751] 2018-02-02 17:19:13:315 11110 sec: 99868510 operations; 8935.6 current ops/sec; est completion in 15 seconds [READ: Count=89356, Max=72895, Min=720, Avg=11122.55, 90=18591, 99=29871, 99.9=41215, 99.99=48831] [CLEANUP: Count=2, Max=19, Min=5, Avg=12, 90=19, 99=19, 99.9=19, 99.99=19] 2018-02-02 17:19:23:316 11120 sec: 99956583 operations; 8806.42 current ops/sec; est completion in 5 seconds [READ: Count=88074, Max=67007, Min=886, Avg=9859.62, 90=16527, 99=27039, 99.9=38911, 99.99=51519] [CLEANUP: Count=35, Max=15, Min=4, Avg=5.49, 90=7, 99=15, 99.9=15, 99.99=15] 2018-02-02 17:19:30:066 11126 sec: 100000000 operations; 6432.15 current ops/sec; [READ: Count=43416, Max=42047, Min=705, Avg=4970.02, 90=8567, 99=16719, 99.9=27343, 99.99=37055] [CLEANUP: Count=63, Max=9311, Min=2, Avg=153.7, 90=6, 99=53, 99.9=9311, 99.99=9311]
和上面差不多,
第一个分号前的数值:2018-02-02 14:14:23:315 20 sec: 136267 operations;
表示"当前的时间,已运行的时间,运行的数据量"三个值,而-s参数默认是每10秒输出一次,直到这1亿数据写完就停止.
第二个分号前的数值:8354.9 current ops/sec;
表示吞吐量信息,也就是常说的ops值(每秒操作次数),可以用他来做趋势图,看看这个集群的趋势.
后面的所有:est completion in 4 hours 4 minutes [READ: Count=83543, Max=71231, Min=740, Avg=11962.2, 90=22063, 99=39167, 99.9=52863, 99.99=65919]
表示预估执行时间,进行了什么操作(这里只有read),总共操作了多少数据,操作的时间和延时等数据,意义不大,只做参考.
其他测试就不一一细说了,各位自己按实际情况配置这个比例即可.
5.结果解读
上面介绍的其实只是-s输出的结果,当然那些结果还是很有参考价值的,但是真正的结果其实是下面这些,
#打开结果文件 vim mongo_ycsb20180202-1.log mongo client connection created with mongodb://10.21.1.205:30000/ycsb?w=0 [OVERALL], RunTime(ms), 1.112675E7 [OVERALL], Throughput(ops/sec), 8987.350304446492 [TOTAL_GCS_PS_Scavenge], Count, 18117.0 [TOTAL_GC_TIME_PS_Scavenge], Time(ms), 99198.0 [TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.891527175500483 [TOTAL_GCS_PS_MarkSweep], Count, 8.0 [TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 254.0 [TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.002282786977329409 [TOTAL_GCs], Count, 18125.0 [TOTAL_GC_TIME], Time(ms), 99452.0 [TOTAL_GC_TIME_%], Time(%), 0.8938099624778125 [READ], Operations, 1.0E8 [READ], AverageLatency(us), 11114.24612337 [READ], MinLatency(us), 672.0 [READ], MaxLatency(us), 515839.0 [READ], 95thPercentileLatency(us), 21871.0 [READ], 99thPercentileLatency(us), 29615.0 [READ], Return=OK, 100000000 [CLEANUP], Operations, 100.0 [CLEANUP], AverageLatency(us), 98.99 [CLEANUP], MinLatency(us), 2.0 [CLEANUP], MaxLatency(us), 9311.0 [CLEANUP], 95thPercentileLatency(us), 10.0 [CLEANUP], 99thPercentileLatency(us), 53.0
关注几个信息:
RunTime(ms): 数据加载所用时间,单位毫秒(ms)
Throughput(ops/sec): 吞吐量,即ops(每秒操作次数)
Operations: 操作的总次数
AverageLatency(us): 平均响应延时,单位是微秒(us)
MinLatency(us): 最小响应时间,单位是微秒(us)
MaxLatency(us): 最大响应时间,单位是微秒(us)
95thPercentileLatency(us): 95%的操作延时,单位是微秒(us)
99thPercentileLatency(us): 99%的操作延时,单位是微秒(us)
Return=OK: 成功返回数,这个值不符合测试要求,则证明测试失败.
[READ]开头的代表只读的操作记录,其他还有例如上面的[insert],[UPDATE]等,
其他可以理解的就是字面意思,不能理解也不需要太过关注.
和其他测试软件一样,这个只能说是基准值,并不是标准值,和真实环境不能全部模拟,所以测试的思维要结合别的测试软件的方法来做.
测试总结
经过对5分片/7分片的1亿/3亿数据的测试来看,其实mongodb的OPS并没有明显提升,但是可以看到cpu负载长期属于低状态,而磁盘压力也没有跑满,内存剩余还算多,所以分片的真正意义是提高了并发能力.
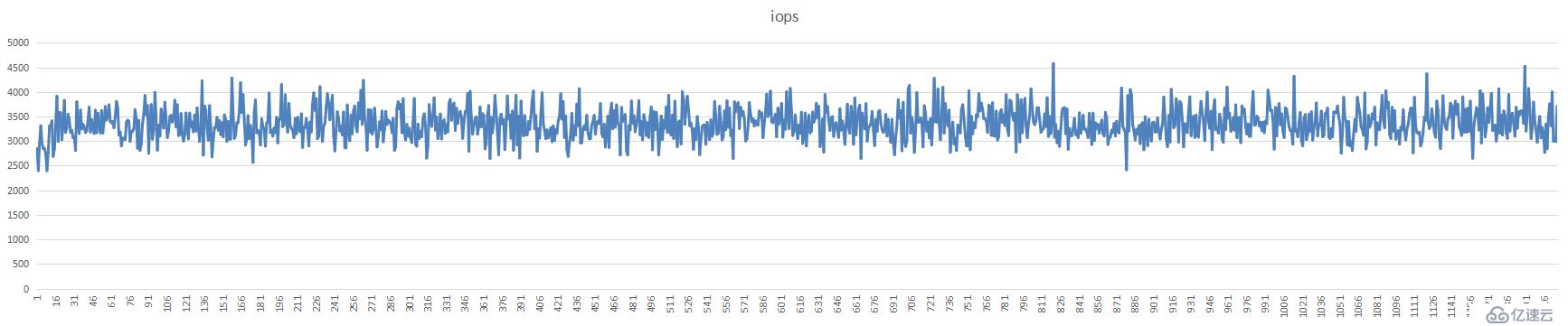
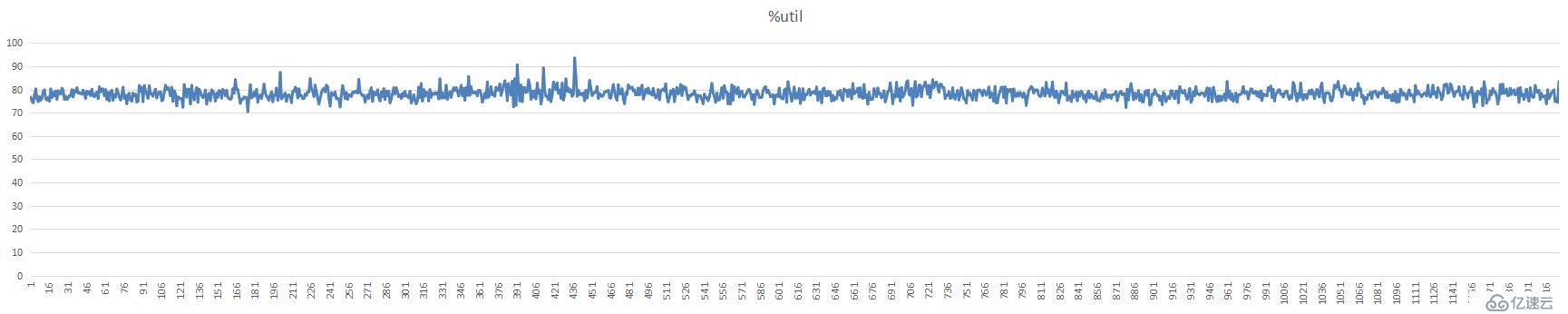
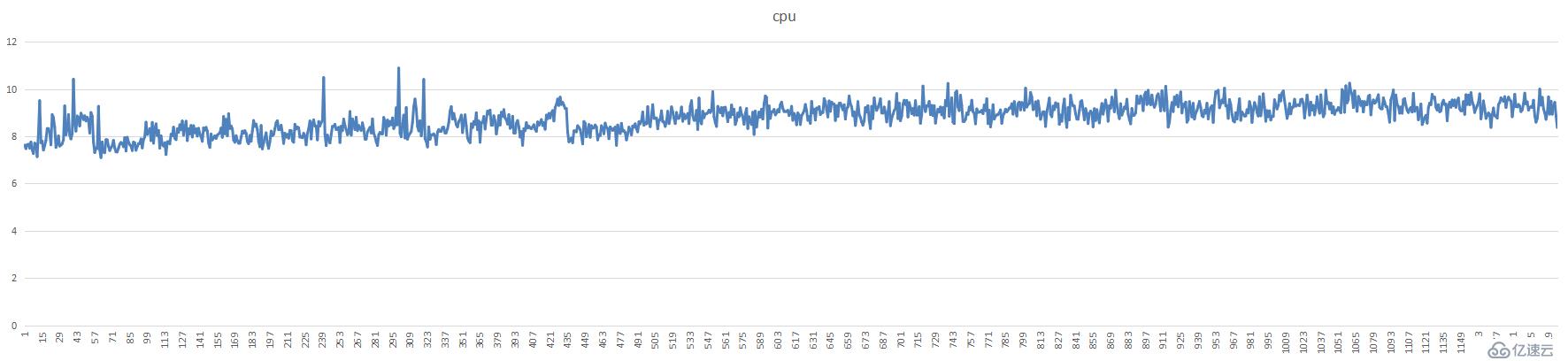
5分片1亿只读数据图表:
单台分片的iops值,
单台分片磁盘利用率,
单台分片cpu使用率,
测试集群ops值,
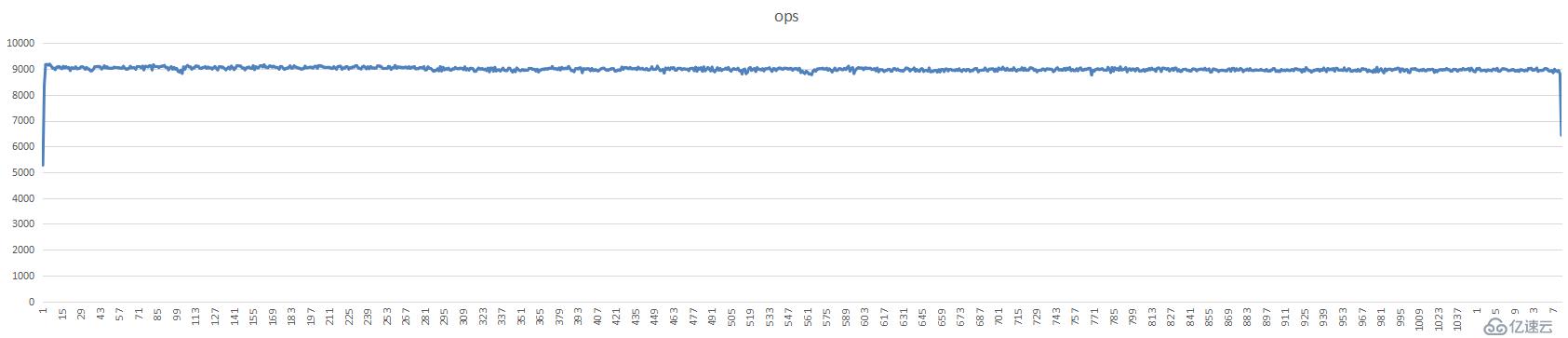
测试集群平均延时,单位是微秒(us)
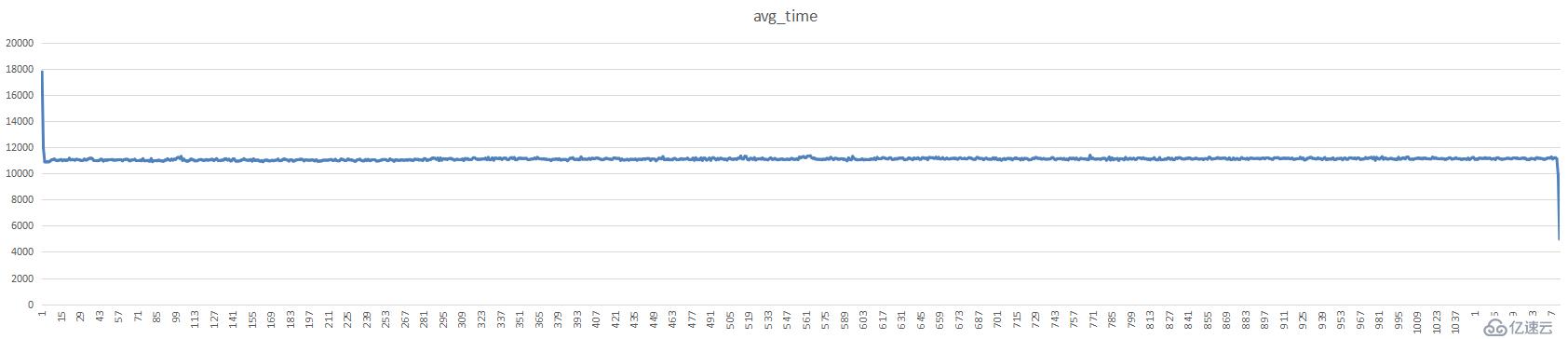
7分片1亿只读数据图表:
单台分片的iops值,
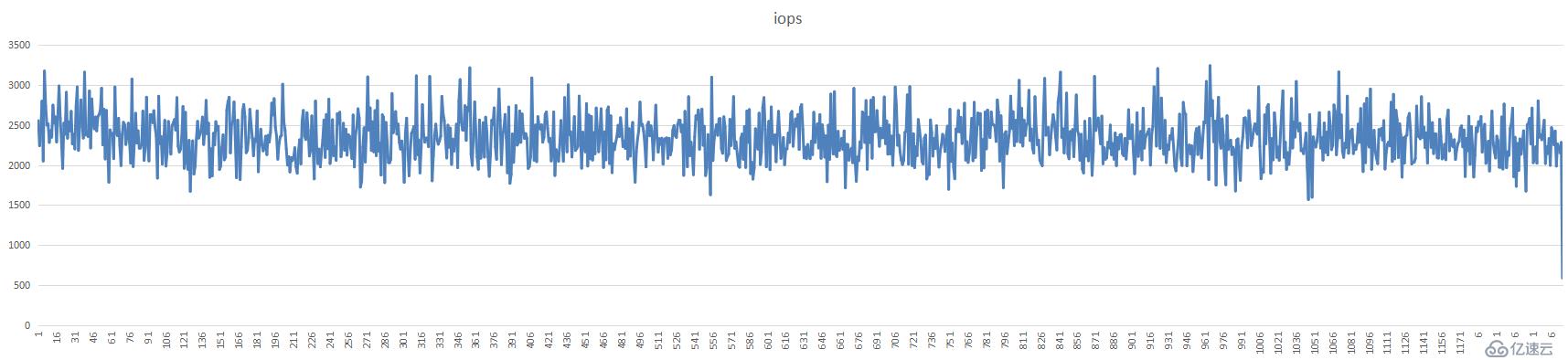
单台分片磁盘利用率,

单台分片cpu使用率,

测试集群ops值,

测试集群平均延时,单位是微秒(us)

7分片3亿只读数据图表:
单台分片的iops值,

单台分片磁盘利用率,
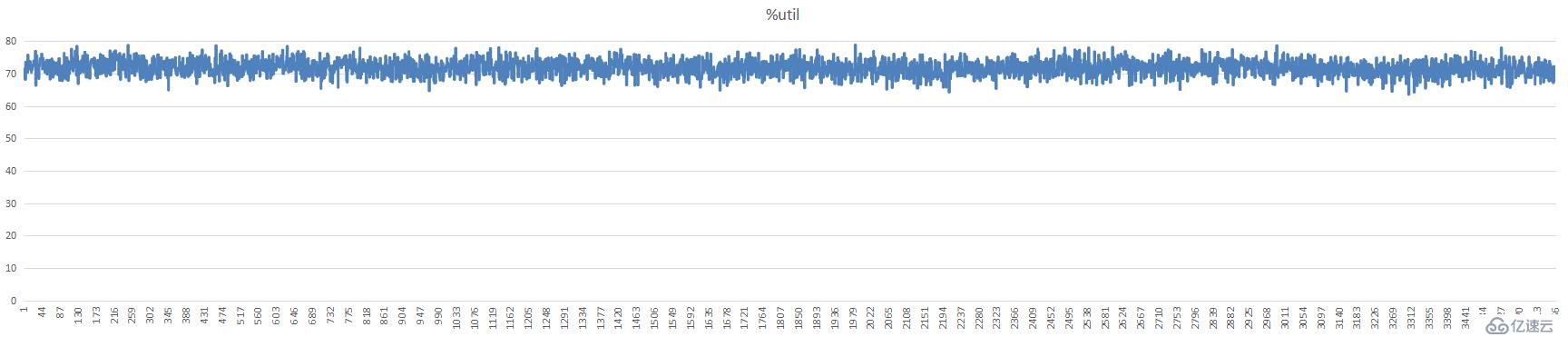
单台分片cpu使用率,

测试集群ops值,
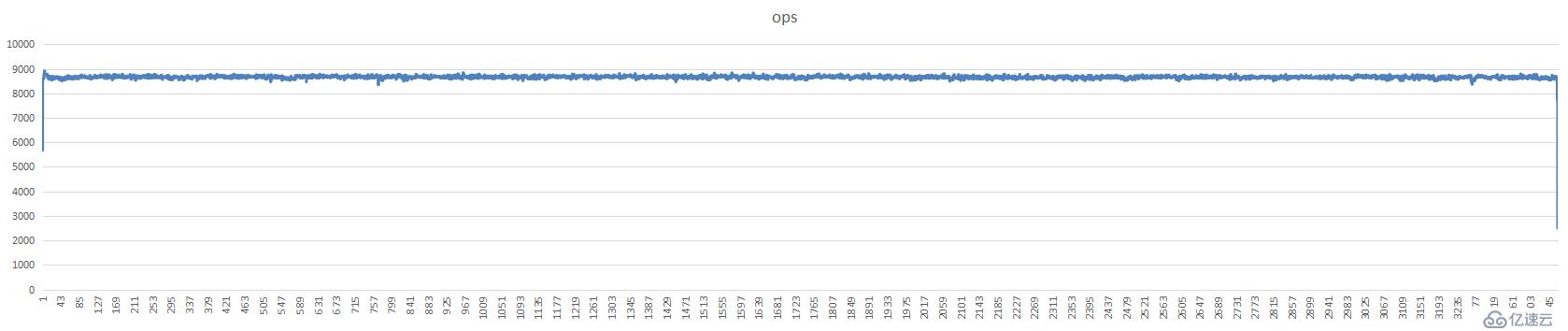
测试集群平均延时,单位是微秒(us)

补充信息
1.创建副本集
config端的副本集:
一个架构稳定的分片集群,应该需要多个节点副本集,防止一挂全挂现象,这是对数据安全的基本要求.而上面我们也谈到一点,在3.4版本之后,mongos的启动已经强制使用config端的副本集模式,如果没有副本集,你也是启动不起来的,所以这里特别补充一下.
首先,说说在3.4情况下,我们的config端必须要建立副本集,所以要在config端设置,就是上面强调的一个参数replSet
#打开config的配置文件 vim /usr/local/mongodb/mongod_config_20000.conf . . . #开启副本集功能,并指定副本集名称为configs replSet=configs
当然,上面也说了,至少要1个或3个config端,那么我们需要开启三个config端,具体配置不详细解析,也不要吐槽为什么放一起,只是测试而已.
#看一下有多少个配置文件
ll /usr/local/mongodb/
drwxr-xr-x. 2 root root 248 Mar 14 10:21 bin
-rw-r--r--. 1 root root 34520 Feb 23 03:53 GNU-AGPL-3.0
-rw-r--r--. 1 root root 622 Mar 14 14:26 mongod_config_20000.conf
-rw-r--r--. 1 root root 622 Mar 14 14:28 mongod_config_20001.conf
-rw-r--r--. 1 root root 622 Mar 14 14:35 mongod_config_20002.conf
-rw-r--r--. 1 root root 419 Mar 14 14:41 mongos_route_30000.conf
#看一下运行的mongo进程
ps aux |grep mongo
root 17211 1.1 0.7 1718800 60916 ? Sl 14:36 1:57 mongod -f /usr/local/mongodb/mongod_config_20000.conf
root 17244 1.0 0.7 1551432 58216 ? Sl 14:36 1:41 mongod -f /usr/local/mongodb/mongod_config_20001.conf
root 17277 1.0 0.7 1551432 57920 ? Sl 14:36 1:40 mongod -f /usr/local/mongodb/mongod_config_20002.conf
#看一下当前端口情况
ss -ntplu |grep mongo
tcp LISTEN 0 128 *:20000 *:* users:(("mongod",pid=17211,fd=11))
tcp LISTEN 0 128 *:20001 *:* users:(("mongod",pid=17244,fd=11))
tcp LISTEN 0 128 *:20002 *:* users:(("mongod",pid=17277,fd=11))三台都可以用了,但是也只是创建了而已,关联关系还是要做初始化,就像mysql的change master的意思一样.
#连接其中一台config端
mongo --port 20000
#输入命令,添加关联关系
>config = {_id:"configs",members:[{_id:0, host:"10.21.1.205:20000" },{_id:1, host:"10.21.1.205:20001" },{_id:2, host:"10.21.1.205:20002" }]}
#初始化副本集
rs.initiate(config)要注意出现 "ok" : 1, 那才是成功初始化,不成功就需要看看哪里出了问题,包括权限.
chown -R mongodb:mongodb /data/mongodb/
然后再次启动,就ok了,那就可以用了,愉快的使用mongos启动router端吧.
节点分片的副本集:
如果是节点分片的副本集则有点不一样,参数是一样要加的.
#编辑配置文件 vim /usr/local/mongodb/mongod_data_40001.conf . . . #开启副本集功能,并指定副本集名称为shard1 replSet=shard1
这里倒没有强制你用多少个副本集,两个三个十个都可以,只要你觉得有必要,这里也就不详细描述了.但是关联关系,那当然是必须的.
#连接其中一台节点
mongo --port 40001
#进入管理数据库admin
>use admin
#输入命令,添加关联关系,和上面不同的点也是这里,
>config = { _id : "shard1", members : [ {_id : 0, host : "10.21.1.208:40001" }, {_id : 1, host : "10.21.1.208:40002" }, {_id : 2, host : "10.21.1.208:40003" , arbiterOnly: true } ]}
#初始化副本集,这里是一样的
rs.initiate(config)不同的点就是arbiterOnly参数,表示这个成员为仲裁节点,不接收数据.使用他的原因是当副本集发生故障时,需要一个仲裁机制来决定谁顶上来接收新的数据,属于故障切换机制,还是比较严密的.
节点副本集添加分片:
另外,由于创建了副本集,分片添加有点不一样了,删除倒是一样的,按分片名字就好了.
#副本集模式添加分片的方式
sh.addShard("shard1/10.21.1.208:40001,10.21.1.208:40002,10.21.1.208:40003")免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





