本文主要以百度首页为例,记录Chrome浏览器中,保存页面的多种方式(涉及一些Chrome的“小技巧”),涉及插件使用请自行尝试,本文仅对不使用插件的情况下保存页面的不同处理方法做简单介绍。
系统环境:Windows10、Chrome 70.0.3538.110(正式版本) (64 位).
说到页面离线保存,首先想到的就是右键保存(Ctrl + S),这样的方式保存会把当前页面的资源保存下来,并放到一个目录下面,大致效果如下:

在想要编辑页面源码等情况下,可以使用此方法,如果只想获取单个离线页面文件用来离线查看,则可以尝试保存当前页面为MHTML文档,可以使用插件(Save As MHT 、Save As MHTML 等) 或Chrome原生支持来完成此功能。
很多浏览器(IE 5.0+、Opera 9.0+、Chrome等)都支持存储MHTML格式页面,大多不支持的浏览器,也有对应的插件可以处理。
在Chrome中,要保存MHTML格式页面,需要在Chrome的实验×××设置中开启。
首先,在Chrome浏览器的地址栏输入 chrome://flags ,可以进入Chrome的实验×××设置页面
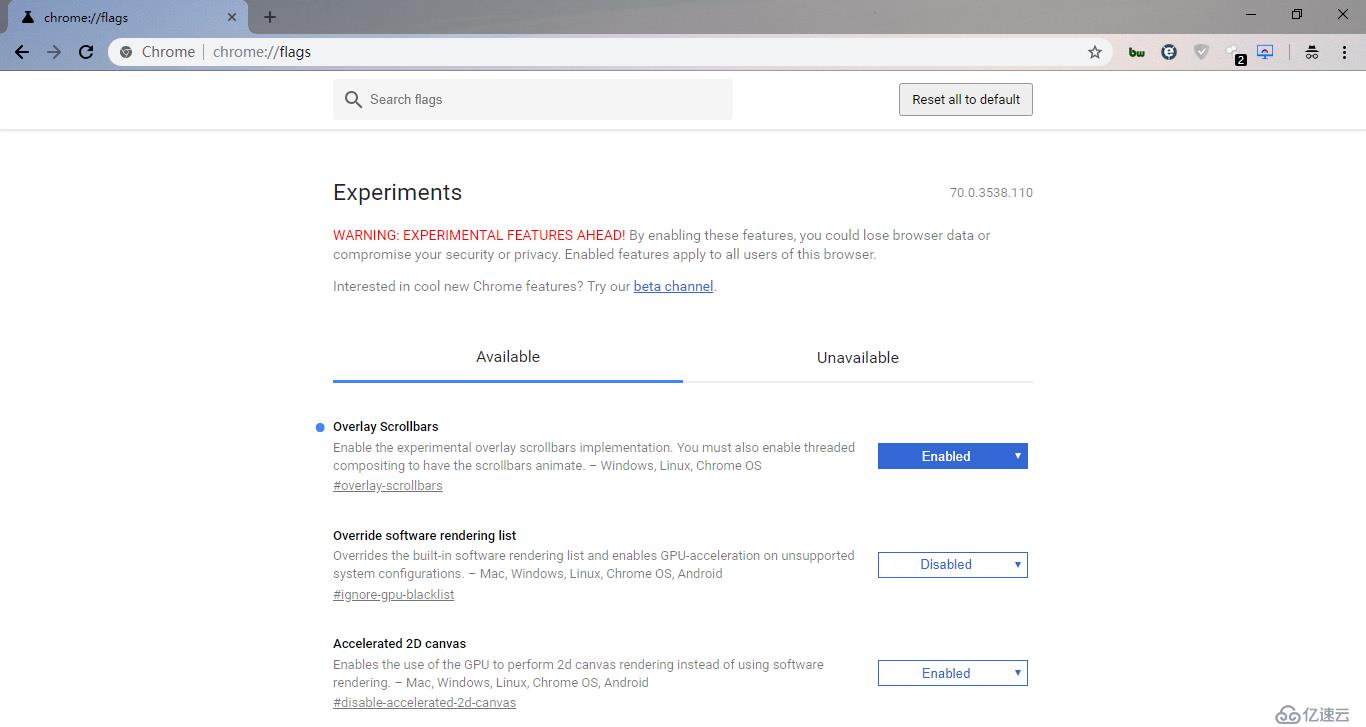
在页面的搜索框内输入 mhtml ,找到 Save Page as MHTML 项(或直接在地址栏输入 chrome://flags/#save-page-as-mhtml),将该项设置为 Enabled ,然后点击底部提示中的 RELAUNCH NOW 按钮重启浏览器,使修改生效。
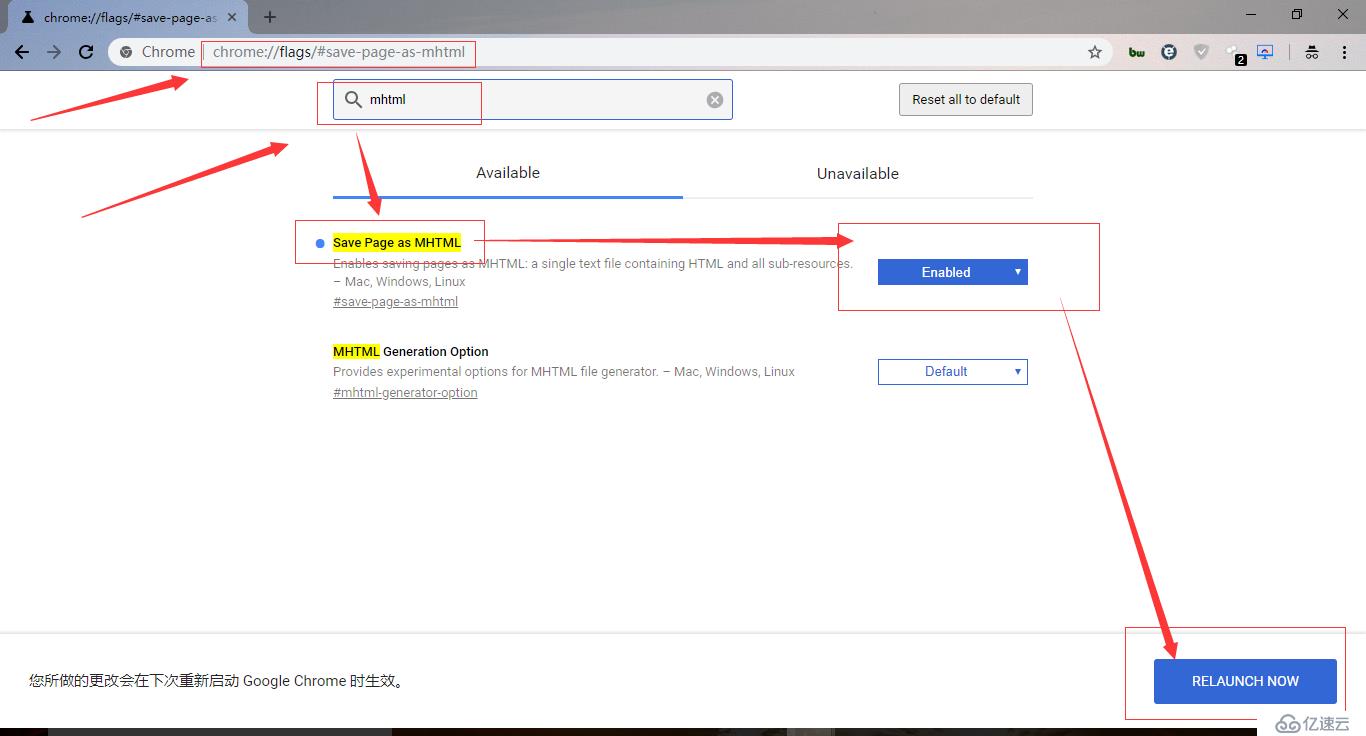
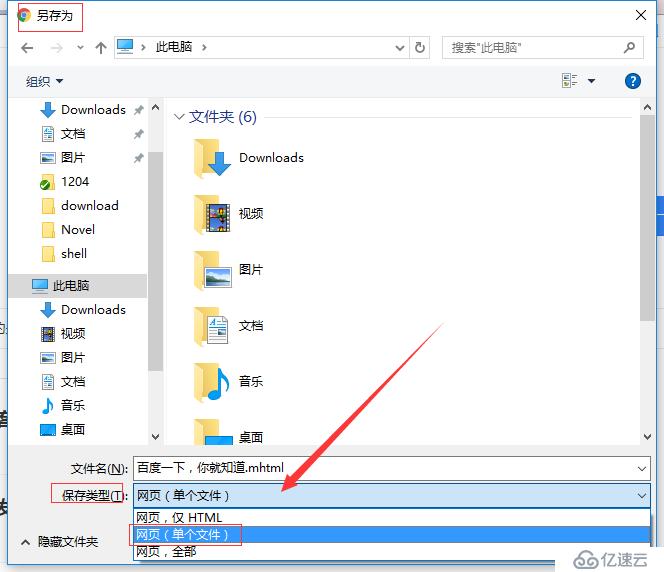
重启浏览器后,在需要保存的页面中,右键,选择另存为(或快捷键 Ctrl + S),弹出的另存为窗口,保存类型选择 网页(单个文件)
MHTML(维基百科 | 百度百科),网页归档,又称单一档案网页或网页封存档案,可以将一个多附件网页保存为单一文档,文档扩展名为 .mht 或 .mhtml。IE浏览器支持保存 .mht 文件,下面做简单介绍。
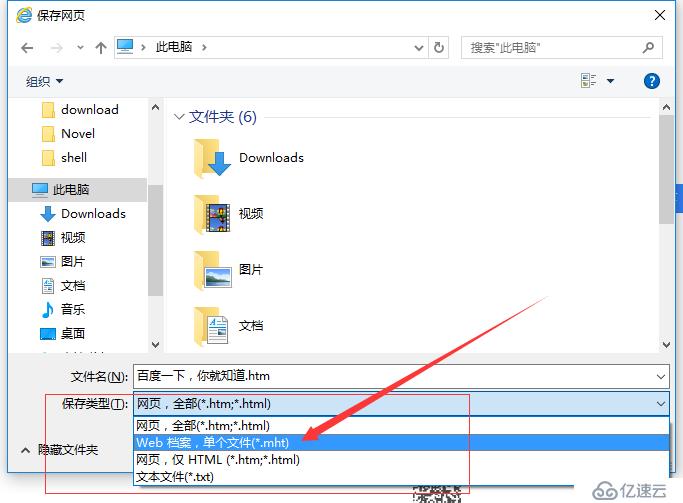
IE浏览器中打开需要保存的百度首页页面链接,然后右键保存(Ctrl + S),出现的保存窗口中,选择保存类型 *.mht
此时可以看到一个百度的MHT文件,文本编辑器打开后,可以看到类似下面的代码:
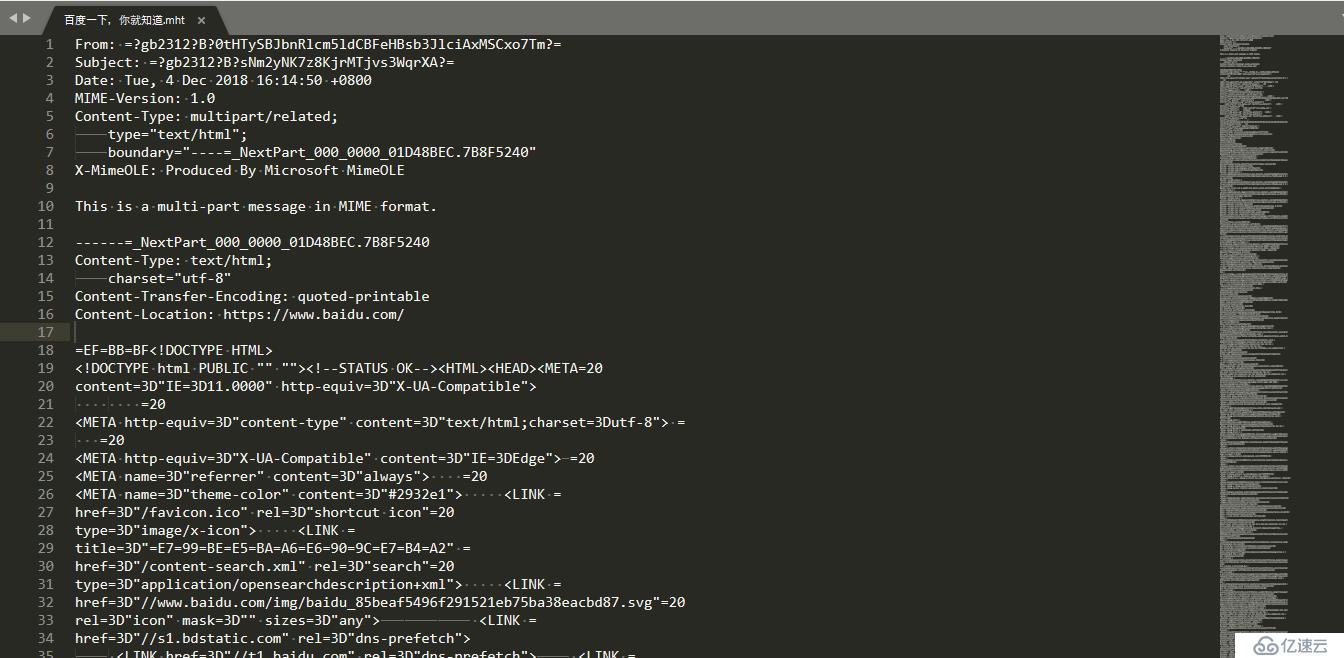
这里可以看到MHTML文档是基于超文本标记语言的,里面可以看到经过处理的页面代码。
Chrome中PDF格式页面保存,可以通过 PrintFriendly & PDF (有Chrome插件)等在线处理服务或使用Chrome插件(Save As PDF)实现,也可以通过打印来实现。
在想保存的页面中,快捷键 Ctrl + P (或右键菜单 -> 打印(p)...),打开页面的打印浏览界面
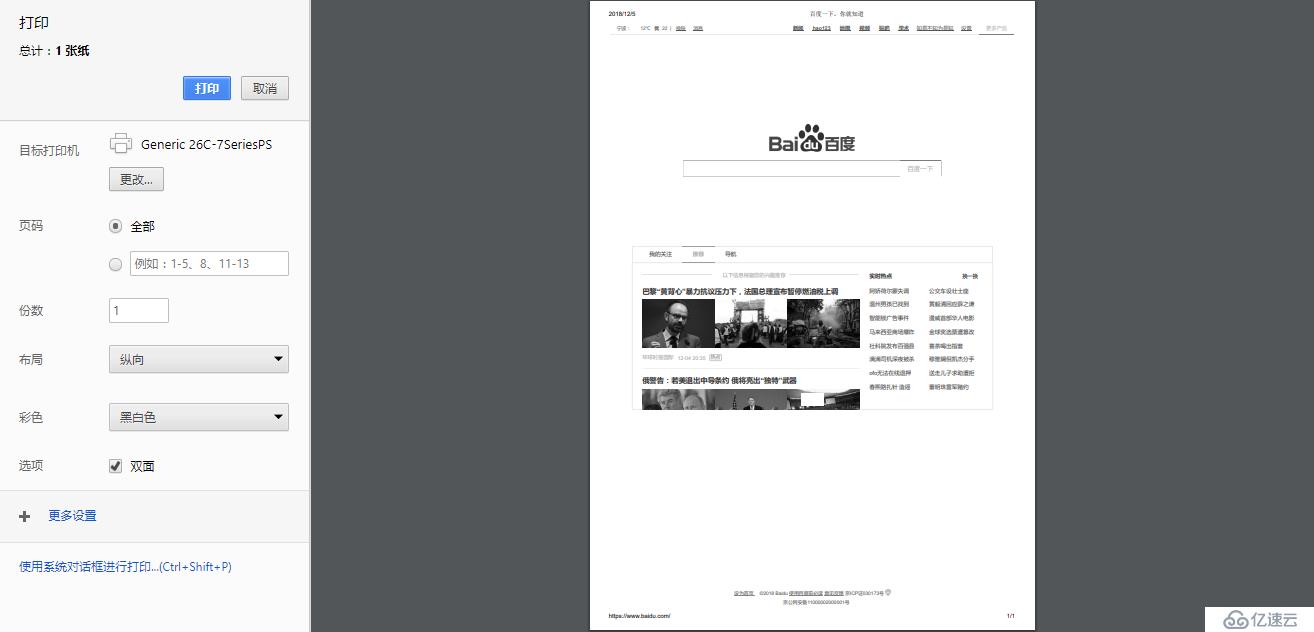
此时可以看到站点的打印预览效果(默认黑白显示),在左侧选项中找到 目标打印机 -> 更改... ,在弹出的选择界面中,找到 另存为 PDF ,双击即可
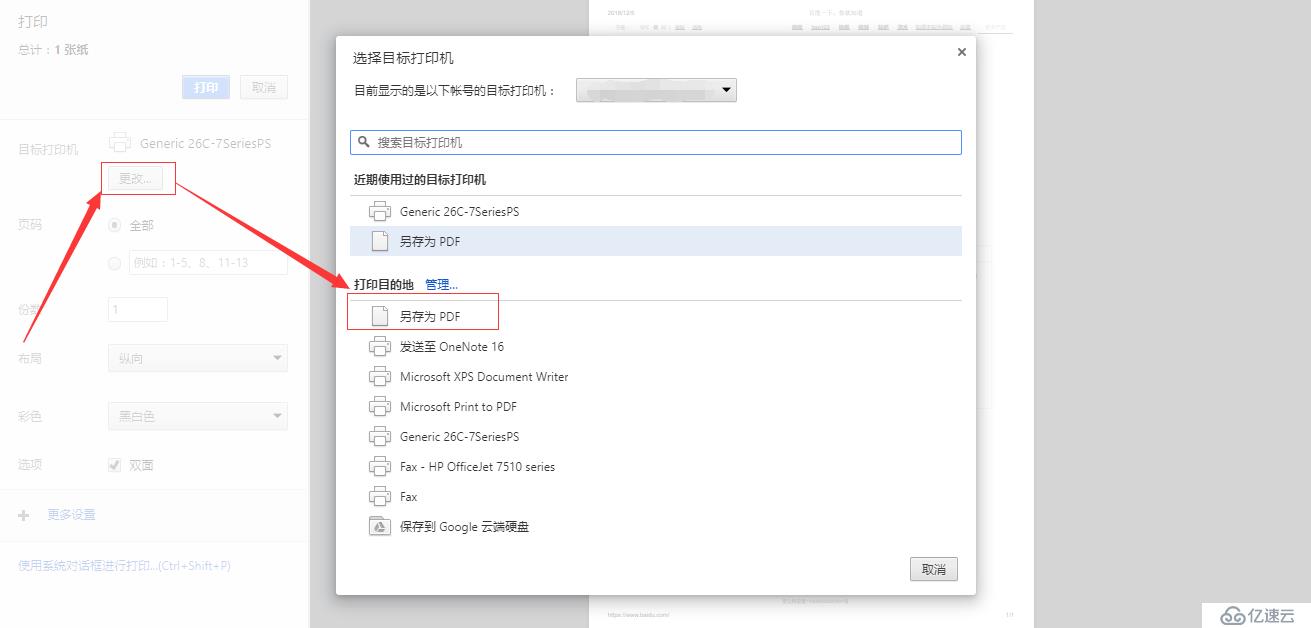
此时就可以看到站点的彩色版预览效果,点击左侧的 保存 按钮即可将站点存储为PDF格式。
部分情况下,可能会需要截取页面,有时仅需要截取部分内容,这通过普通的截图工具即可完成,如QQ截取、微信截图、Windows自带截图工具等等;而有时可能需要截取页面长图,这也可以通过工具来实现,如FastStone Capture、Chrome插件(FireShot、Full Page Screen Capture)等。这里简单介绍 FastStone Capture 和Chrome截图方法,其他方式不赘述。
打开工具 FastStone Capture ,选择 捕捉滚动窗口 按钮,则可以进入长图截图窗口

FastStone Capture的捕捉滚动窗口,可以支持自动滚动窗口及自定义滚动窗口,可以根据需要选择,以达到截取所需内容的目的(自定义滚动截图不太好使,不容易把控结束时间,截取的图片可能需要再次编辑)
在Chrome浏览器的开发者工具中(devtools),也提供了类似主流编辑器(Sublime Text, Atom, Visual Studio Code等)中的命令行菜单,通常使用 Ctrl + Shift + P ( Mac 上是 Cmd + Shift + P) 。如Sublime Text的命令行菜单:
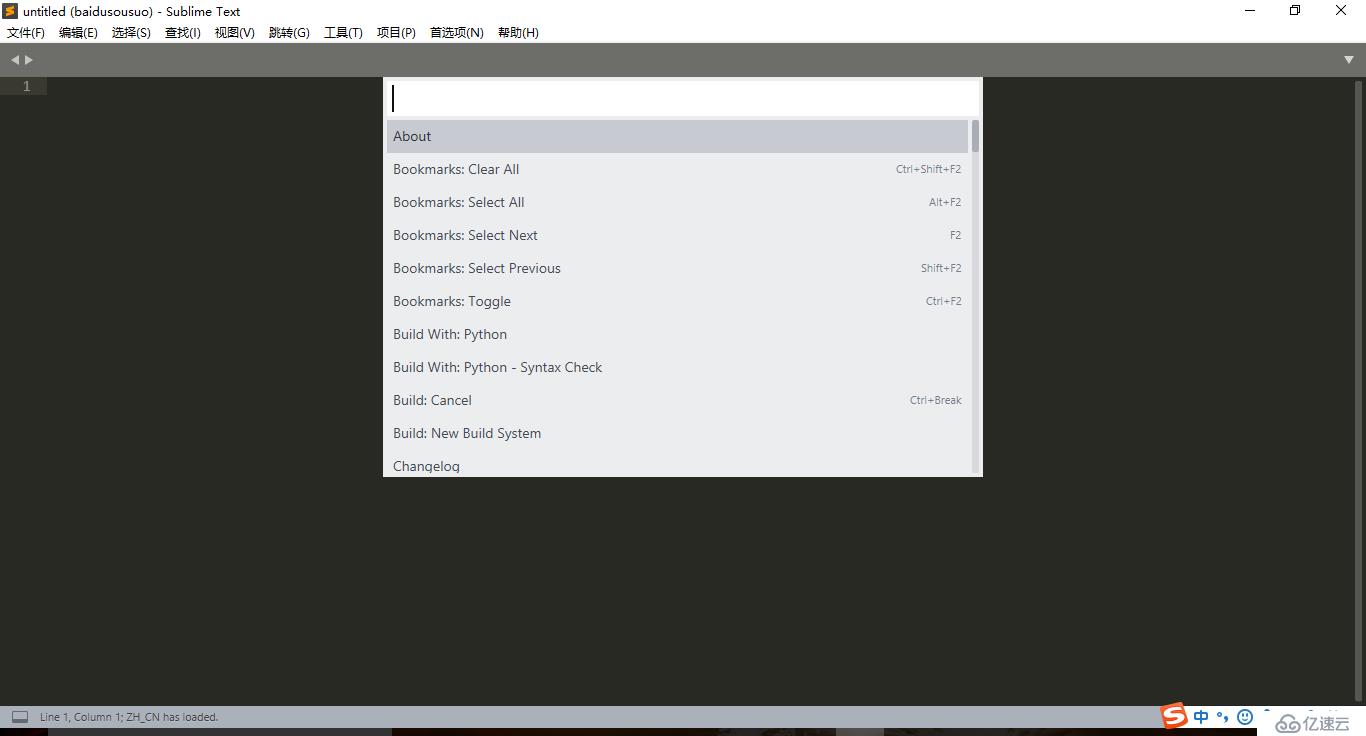
使用Sublime Text的朋友应该很熟悉这个了,而命令行菜单带来的遍历是不言而喻的。
在Chrome浏览器中,首先 F12 打开 DevTools 开发者工具,然后在DevTools中使用快捷键 Ctrl + Shift + P ,就可以打开Chrome的命令行菜单:
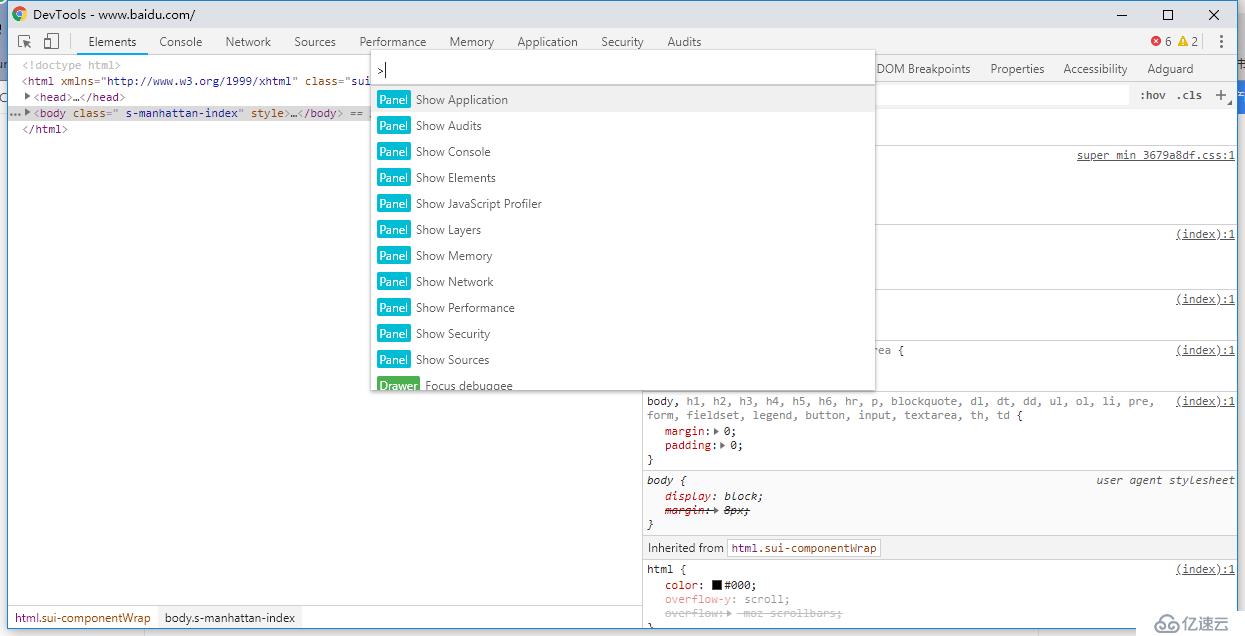
在命令行菜单中,输入 capture 就可以看到有如下选项
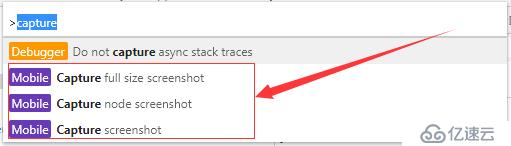
这里可以看到,Chrome命令行菜单提供了三个用于界面捕获的命令
在命令行内输入对应的命令,即可完成截图。
上面介绍了截取站点方法,这里额外说下,想截取站点在不同像素显示下响应显示时,截取类似移动端长图的方法。
同样在Chrome浏览器中,打开DevTools,然后点击按钮,点击 toggle device toolbar(切换设备工具栏) ,可以看到类似如下效果:
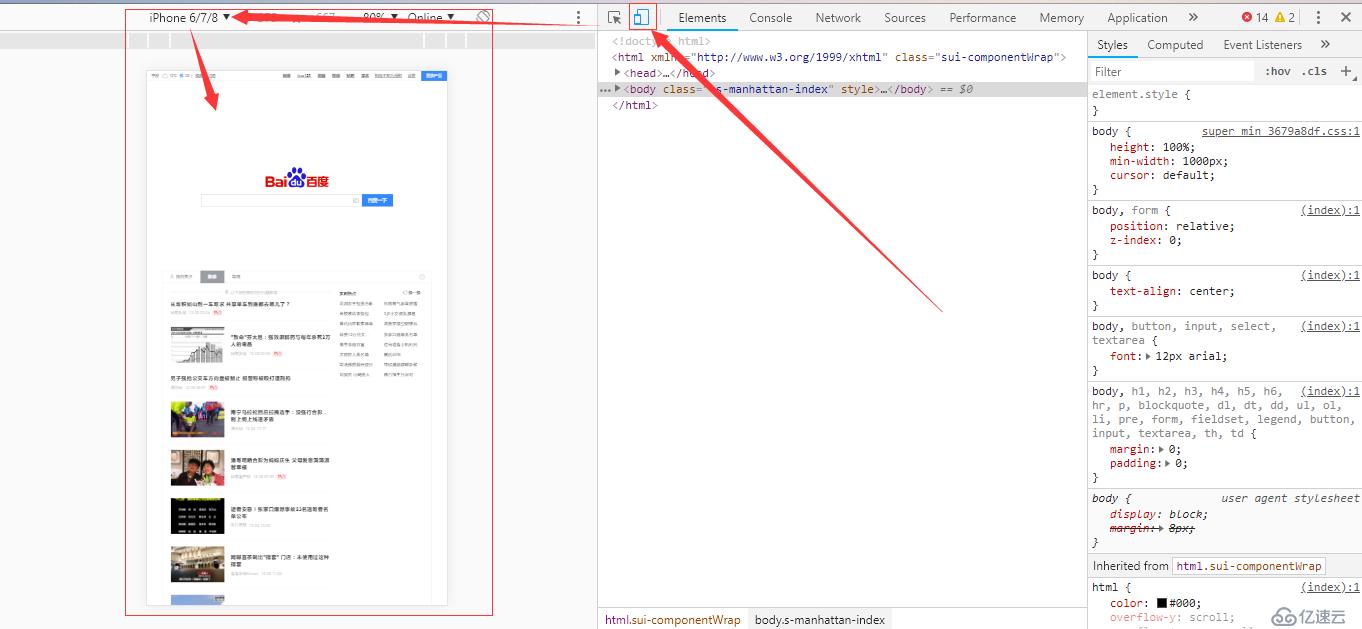
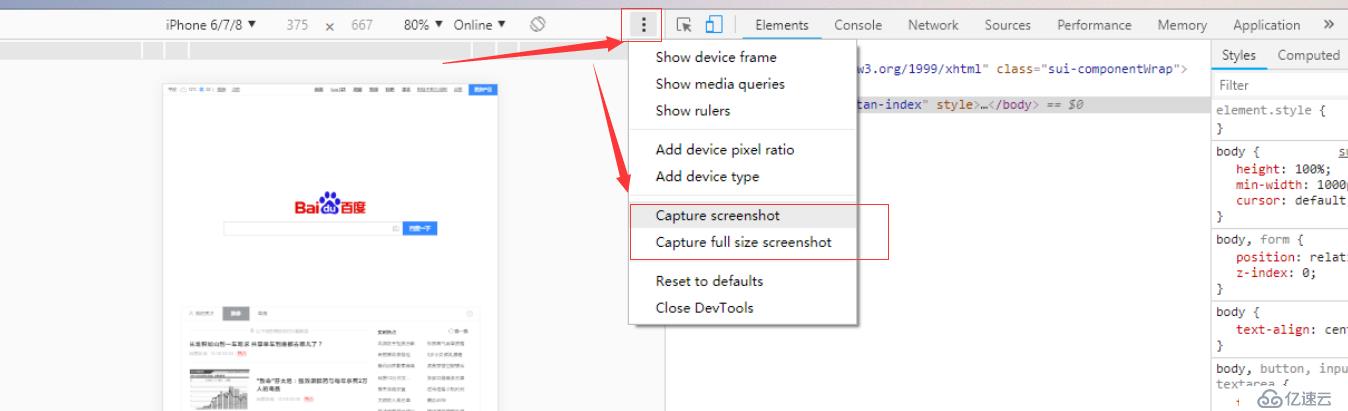
在这个工具栏中,可以通过切换不同的设备(不同的分辨率),来查看站点在不同的分辨率下的显示情况,可以很好的辅助站点的响应式开发工作。在这个视图中,可以通过点击顶部菜单项最右边的三个点,来打开菜单,里面有截取屏幕的选项,如下:
Headless Chrome is shipping in Chrome 59. It's a way to run the Chrome browser in a headless environment. Essentially, running Chrome without chrome! It brings all modern web platform features provided by Chromium and the Blink rendering engine to the command line.
Chrome 59以上版本支持Headless Chrome,Headless Chrome是可以命令行模式运行Chromium和Blink渲染引擎提供功能。可以在无UI窗口的情况下,完成很多浏览器的操作,是自动测试和服务器环境的绝佳工具。更多内容参看官方说明。
管理员模式运行命令行窗口,使用 cd 命令进入Chrome浏览器安装目录,输入类似如下命令:
chrome --headless --disable-gpu --dump-dom https://www.baidu.com测试了下,好像没有效果,具体原因不清楚。。。有知道的朋友,希望可以不吝赐教!!!
管理员模式运行命令行窗口,使用 cd 命令进入Chrome浏览器安装目录,输入类似如下命令:
chrome --headless --disable-gpu --print-to-pdf='存储路径\文件名称' https://www.baidu.com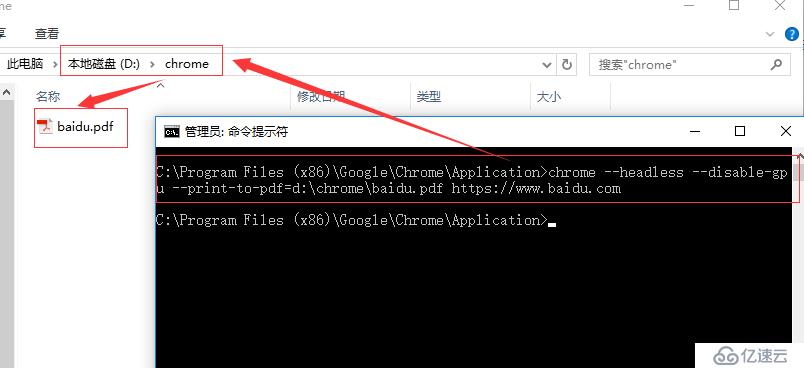
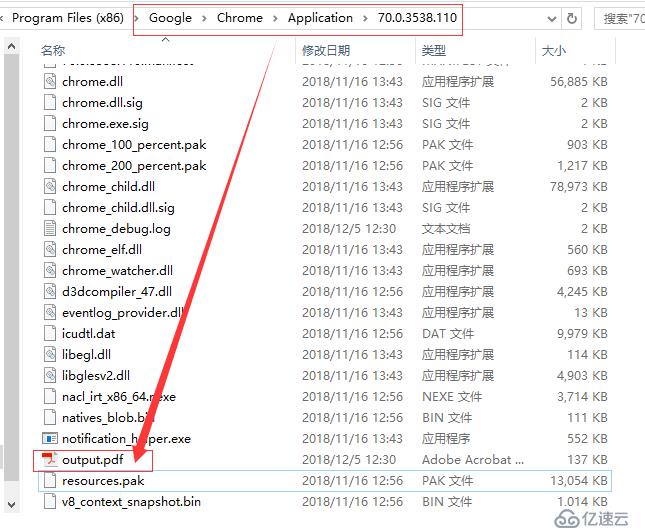
注意,此处如果不给存储路径和文件名称,则保存的pdf可以在Chrome浏览器安装目录下对应版本号的目录文件下,文件名称为 output.pdf
管理员模式运行命令行窗口,使用 cd 命令进入Chrome浏览器安装目录,输入类似如下命令:
chrome --headless --disable-gpu --screenshot='存储路径\文件名称' https://www.baidu.com
## 设置图片大小(尺寸大小好像没有用,具体作用自行研究)
chrome --headless --disable-gpu --screenshot='存储路径\文件名称' --window-size=宽,高 https://www.baidu.com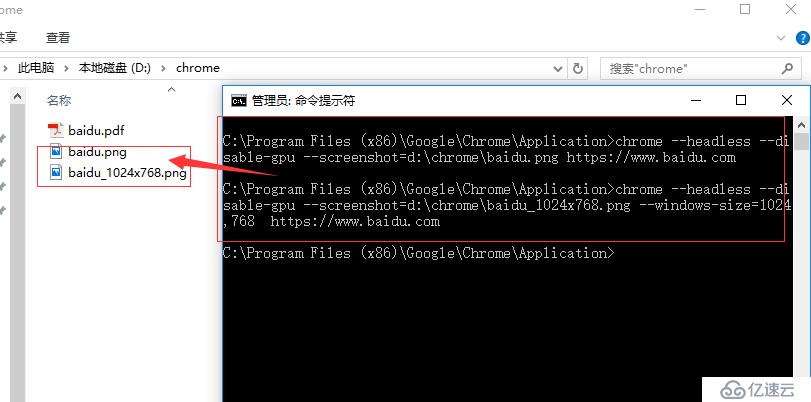
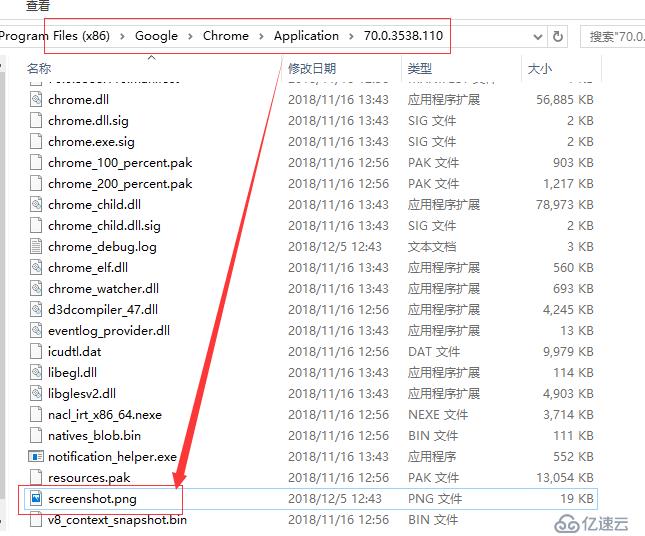
注意,此处如果不给存储路径和文件名称,则保存的pdf可以在Chrome浏览器安装目录下对应版本号的目录文件下,文件名称为 output.pdf
Chrome官方推出的Puppeteer(封装了Headless Chrome的Node库),可以完成浏览器中手动执行的大多数操作:
测试Chrome扩展程序。
该库具体功能详见 此处 | Github地址。
类似的还可以尝试PhantomJS -- 可编写脚本的无头浏览器
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





