жң¬зҜҮеҶ…е®№дё»иҰҒи®Іи§ЈвҖңLogstashејҖжәҗж—Ҙеҝ—з®ЎзҗҶж–№жі•жҳҜд»Җд№ҲвҖқпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢдёҚеҰЁжқҘзңӢзңӢгҖӮжң¬ж–Үд»Ӣз»Қзҡ„ж–№жі•ж“ҚдҪңз®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәгҖӮдёӢйқўе°ұи®©е°Ҹзј–жқҘеёҰеӨ§е®¶еӯҰд№ вҖңLogstashејҖжәҗж—Ҙеҝ—з®ЎзҗҶж–№жі•жҳҜд»Җд№ҲвҖқеҗ§!
LogstashжҳҜе…·жңүе®һж—¶жөҒж°ҙзәҝиғҪеҠӣзҡ„ејҖжәҗзҡ„ж•°жҚ®ж”¶йӣҶеј•ж“ҺгҖӮLogstashеҸҜд»ҘеҠЁжҖҒз»ҹдёҖдёҚеҗҢжқҘжәҗзҡ„ж•°жҚ®пјҢ并е°Ҷж•°жҚ®ж ҮеҮҶеҢ–еҲ°жӮЁйҖүжӢ©зҡ„зӣ®ж Үиҫ“еҮәгҖӮе®ғжҸҗдҫӣдәҶеӨ§йҮҸжҸ’件пјҢеҸҜеё®еҠ©жҲ‘们解жһҗпјҢдё°еҜҢпјҢиҪ¬жҚўе’Ңзј“еҶІд»»дҪ•зұ»еһӢзҡ„ж•°жҚ®гҖӮ

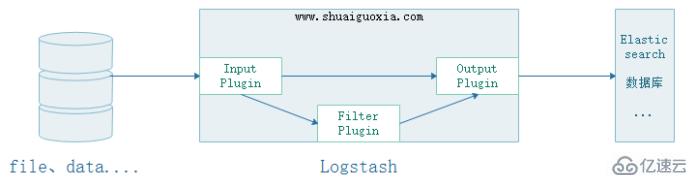
дёҖгҖҒеҺҹзҗҶ
Input
еҸҜд»Ҙд»Һж–Ү件дёӯгҖҒеӯҳеӮЁдёӯгҖҒж•°жҚ®еә“дёӯжҠҪеҸ–ж•°жҚ®пјҢInputжңүдёӨз§ҚйҖүжӢ©дёҖдёӘжҳҜдәӨз»ҷFilterиҝӣиЎҢиҝҮж»ӨгҖҒдҝ®еүӘгҖӮеҸҰдёҖдёӘжҳҜзӣҙжҺҘдәӨз»ҷOutput
Filter
иғҪеӨҹеҠЁжҖҒең°иҪ¬жҚўе’Ңи§Јжһҗж•°жҚ®гҖӮеҸҜд»ҘйҖҡиҝҮиҮӘе®ҡд№үзҡ„ж–№ејҸеҜ№ж•°жҚ®дҝЎжҒҜиҝҮж»ӨгҖҒдҝ®еүӘ
Output
жҸҗдҫӣдј—еӨҡиҫ“еҮәйҖүжӢ©пјҢжӮЁеҸҜд»Ҙе°Ҷж•°жҚ®еҸ‘йҖҒеҲ°жӮЁиҰҒжҢҮе®ҡзҡ„ең°ж–№пјҢ并且иғҪеӨҹзҒөжҙ»ең°и§Јй”Ғдј—еӨҡдёӢжёёз”ЁдҫӢгҖӮ
дәҢгҖҒе®үиЈ…дҪҝз”Ё
1.е®үиЈ…
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.0.1.rpm
yum install -y ./logstash-6.0.1.rpm
2.Logstashй…ҚзҪ®ж–Ү件
vim /etc/logstash/logstash.yml
path.data: /var/lib/logstash # ж•°жҚ®еӯҳж”ҫи·Ҝеҫ„path.config: /etc/logstash/conf.d/*.conf # е…¶д»–жҸ’件зҡ„й…ҚзҪ®ж–Ү件пјҢиҫ“е…Ҙиҫ“еҮәиҝҮж»Өзӯүзӯүpath.logs: /var/log/logstash # ж—Ҙеҝ—еӯҳж”ҫи·Ҝеҫ„
3.Logstashдёӯзҡ„JVMй…ҚзҪ®ж–Ү件
LogstashжҳҜдёҖдёӘеҹәдәҺJavaејҖеҸ‘зҡ„зЁӢеәҸпјҢйңҖиҰҒиҝҗиЎҢеңЁJVMдёӯпјҢеҸҜд»ҘйҖҡиҝҮй…ҚзҪ®jvm.optionsжқҘй’ҲеҜ№JVMиҝӣиЎҢи®ҫе®ҡгҖӮжҜ”еҰӮеҶ…еӯҳзҡ„жңҖеӨ§жңҖе°ҸгҖҒеһғеңҫжё…зҗҶжңәеҲ¶зӯүзӯүгҖӮиҝҷйҮҢд»…д»…еҲ—дёҫжңҖеёёз”Ёзҡ„дёӨдёӘгҖӮ
JVMзҡ„еҶ…еӯҳеҲҶй…ҚдёҚиғҪеӨӘеӨ§дёҚиғҪеӨӘе°ҸпјҢеӨӘеӨ§дјҡжӢ–ж…ўж“ҚдҪңзі»з»ҹгҖӮеӨӘе°ҸеҜјиҮҙж— жі•еҗҜеҠЁгҖӮ
vim /etc/logstash/jvm.options # logstashжңүе…іJVMзҡ„й…ҚзҪ®-Xms256m # logstashжңҖеӨ§жңҖе°ҸдҪҝз”ЁеҶ…еӯҳ-Xmx1g
4.жңҖз®ҖеҚ•зҡ„ж—Ҙеҝ—收йӣҶй…ҚзҪ®
е®үиЈ…дёҖдёӘhttpdз”ЁдәҺжөӢиҜ•пјҢй…ҚзҪ®Logstash收йӣҶApacheзҡ„accless.logж—Ҙеҝ—ж–Ү件
yum install httpdecho "Hello world" > /var/www/html/index.html # е®үиЈ…httpdпјҢеҲӣе»әйҰ–йЎөз”ЁдәҺжөӢиҜ•vim /etc/logstash/conf.d/test.conf
input {
file { # дҪҝз”ЁfileдҪңдёәж•°жҚ®иҫ“е…Ҙ path => ['/var/log/httpd/access_log'] # и®ҫе®ҡиҜ»е…Ҙж•°жҚ®зҡ„и·Ҝеҫ„ start_position => beginning # д»Һж–Ү件зҡ„ејҖе§ӢеӨ„иҜ»еҸ–пјҢendд»Һж–Ү件жң«е°ҫејҖе§ӢиҜ»еҸ– }
}
output { # и®ҫе®ҡиҫ“еҮәзҡ„дҪҚзҪ® stdout {
codec => rubydebug # иҫ“еҮәиҮіеұҸ幕 }
}5.жөӢиҜ•й…ҚзҪ®ж–Ү件
logstashжҳҜиҮӘеёҰзҡ„е‘Ҫд»ӨдҪҶжҳҜжІЎжңүеҶҚзҺҜеўғеҸҳйҮҸдёӯпјҢжүҖд»ҘеҸӘиғҪдҪҝз”Ёз»қеҜ№и·Ҝеҫ„жқҘдҪҝз”ЁжӯӨе‘Ҫд»ӨгҖӮ
/usr/share/logstash/bin/logstash -t -f /etc/logstash/conf.d/test.conf # жөӢиҜ•жү§иЎҢй…ҚзҪ®ж–Ү件пјҢ-tиҰҒеңЁ-fеүҚйқўConfiguration OK # иЎЁзӨәжөӢиҜ•OK
6.еҗҜеҠЁlogstash
еңЁеҪ“еүҚдјҡиҜқиҝҗиЎҢlogstashеҗҺдёҚиҰҒе…ій—ӯиҝҷдёӘдјҡиҜқжҡӮж—¶з§°е…¶дёәдјҡиҜқ1пјҢеҶҚжү“ејҖдёҖдёӘж–°зҡ„зӘ—еҸЈдёәдјҡиҜқ2
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/test.conf
еҗҜеҠЁд»ҘеҗҺеңЁдјҡиҜқ2дёӯдҪҝз”Ёcurlе‘Ҫд»ӨиҝӣиЎҢжөӢиҜ•
curl 172.18.68.14
然еҗҺеңЁеӣһеҲ°д№ӢеүҚзҡ„дјҡиҜқ1еҸҜд»ҘзңӢеҲ°иҫ“еҮәзҡ„дҝЎжҒҜ
{
"@version" => "1",
"host" => "logstash.shuaiguoxia.com",
"path" => "/var/log/httpd/access_log",
"@timestamp" => 2017-12-10T14:07:07.682Z,
"message" => "172.18.68.14 - - [10/Dec/2017:22:04:44 +0800] \"GET / HTTP/1.1\" 200 12 \"-\" \"curl/7.29.0\""}иҮіжӯӨжңҖз®ҖеҚ•зҡ„Logstashй…ҚзҪ®е°ұе·Із»Ҹе®ҢжҲҗдәҶпјҢиҝҷйҮҢд»…д»…жҳҜе°Ҷ收йӣҶеҲ°зҡ„зӣҙжҺҘиҫ“еҮәжІЎжңүиҝӣиЎҢиҝҮж»ӨжҲ–иҖ…дҝ®еүӘгҖӮ
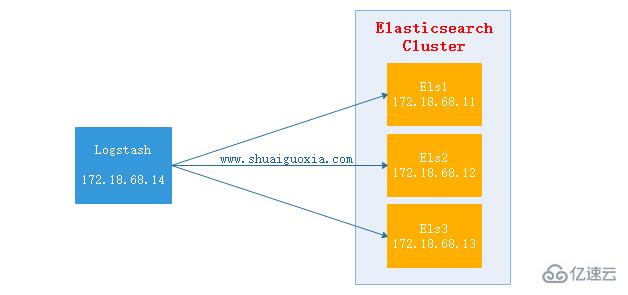
дёүгҖҒElasticsearchдёҺLogstash
дёҠйқўзҡ„й…ҚзҪ®ж—¶Logsatshд»Һж—Ҙеҝ—ж–Ү件дёӯжҠҪеҸ–ж•°жҚ®пјҢ然еҗҺиҫ“еҮәиҮіеұҸ幕гҖӮйӮЈд№ҲеңЁз”ҹдә§дёӯеҫҖеҫҖжҳҜе°ҶжҠҪеҸ–зҡ„ж•°жҚ®иҝҮж»ӨеҗҺиҫ“еҮәеҲ°ElasticsearchдёӯгҖӮдёӢйқўи®Іи§ЈElasticsearchз»“еҗҲLogstash
LogstashжҠҪеҸ–httpdзҡ„access.logж–Ү件пјҢ然еҗҺз»ҸиҝҮиҝҮж»ӨпјҲз»“жһ„еҢ–пјүд№ӢеҗҺиҫ“еҮәз»ҷElasticsearch ClusterпјҢеңЁдҪҝз”ЁHeadжҸ’件е°ұеҸҜд»ҘзңӢеҲ°жҠҪеҸ–еҲ°зҡ„ж•°жҚ®гҖӮпјҲElasticsearch ClusterдёҺHeadжҸ’件жҗӯе»әиҜ·жҹҘзңӢеүҚдёӨзҜҮж–Үз« пјү
й…ҚзҪ®Logstash
vim /etc/logstash/conf.d/test.conf
input {
file {
path => ['/var/log/httpd/access_log']
start_position => "beginning" }
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}" }
remove_field => "message"
}
}
output {
elasticsearch {
hosts => ["http://172.18.68.11:9200","http://172.18.68.12:9200","http://172.18.68.13:9200"]
index => "logstash-%{+YYYY.MM.dd}" action => "index" document_type => "apache_logs" }
}еҗҜеҠЁLogstash
/usr/share/logstash/bin/logstash -t -f /etc/logstash/conf.d/test.conf # жөӢиҜ•й…ҚзҪ®ж–Ү件 Configuration OK
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/test.conf # еҗҜеҠЁLogstash
жөӢиҜ•
жҜҸдёӘжү§иЎҢ10ж¬Ў172.18.68.14пјҢдҪҚLogstashзҡ„ең°еқҖ
curl 127.0.0.1
curl 172.18.68.14
йӘҢиҜҒж•°жҚ®
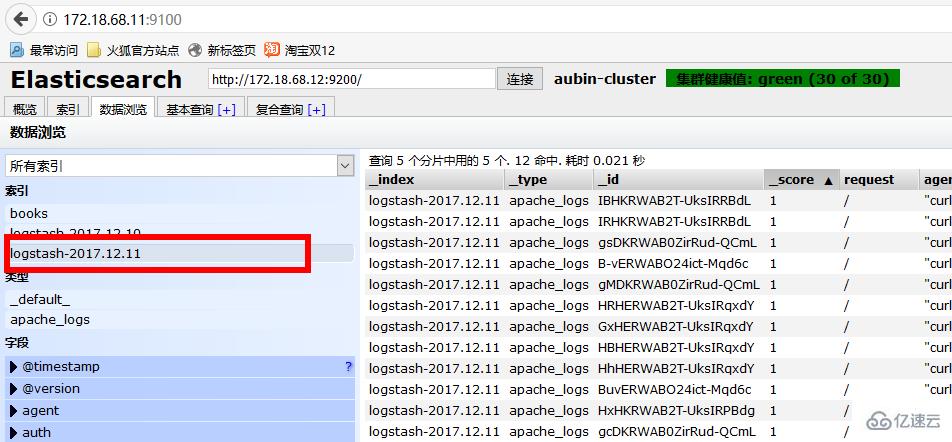
дҪҝз”ЁжөҸи§ҲеҷЁи®ҝй—®172.18.68.11:9100пјҲElastisearch е®үиЈ…Headең°еқҖпјҢеүҚйқўж–Үз« жңүи®Іпјү
йҖүжӢ©д»ҠеӨ©зҡ„ж—ҘжңҹпјҢе°ұиғҪзңӢеҲ°дёҖеӨ©еҶ…и®ҝй—®зҡ„жүҖжңүж•°жҚ®гҖӮ
еӣӣгҖҒзӣ‘жҺ§е…¶д»–
зӣ‘жҺ§Nginxж—Ҙеҝ—
д»…д»…еҲ—дәҶfilterй…ҚзҪ®еқ—пјҢinputдёҺoutputеҸӮиҖғдёҠдёҖдёӘй…ҚзҪ®
filter {
grok {
match => {
"message" => "%{HTTPD_COMBINEDLOG} \"%{DATA:realclient}\"" }
remove_field => "message" }
date {
match => ["timestamp","dd/MMM/YYYY:H:m:s Z"]
remove_field => "timestamp" }
}зӣ‘жҺ§Tomcat
д»…д»…еҲ—дәҶfilterй…ҚзҪ®еқ—пјҢinputдёҺoutputеҸӮиҖғдёҠдёҖдёӘй…ҚзҪ®
filter {
grok {
match => {
"message" => "%{HTTPD_COMMONLOG}" }
remove_field => "message" }
date {
match => ["timestamp","dd/MMM/YYYY:H:m:s Z"]
remove_field => "timestamp" }
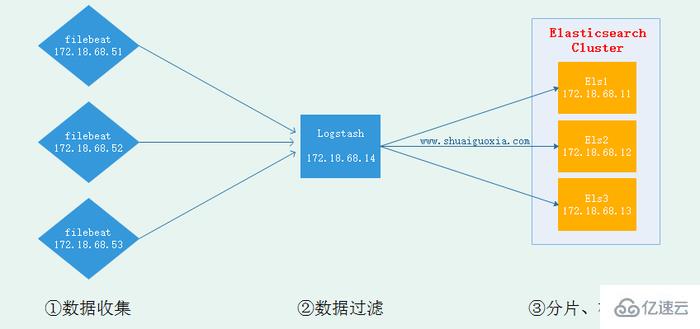
}дә”гҖҒFilebeat
зҺ°еңЁе·Із»Ҹжҗӯе»әжҲҗеңЁиҠӮзӮ№е®үиЈ…Logstash并еҸ‘йҖҒеҲ°ElasticsearchдёӯеҺ»пјҢдҪҶжҳҜLogstashжҳҜеҹәдәҺJavaејҖеҸ‘йңҖиҰҒиҝҗиЎҢеңЁJVMдёӯпјҢжүҖд»ҘжҳҜдёҖдёӘйҮҚйҮҸзә§йҮҮйӣҶе·Ҙе…·пјҢд»…д»…еҜ№дәҺдёҖдёӘж—Ҙеҝ—йҮҮйӣҶиҠӮзӮ№жқҘиҜҙдҪҝз”ЁLogstashеӨӘиҝҮйҮҚйҮҸзә§пјҢйӮЈд№Ҳе°ұеҸҜд»ҘдҪҝз”ЁдёҖдёӘиҪ»йҮҸзә§ж—Ҙеҝ—收йӣҶе·Ҙе…·FilebeatжқҘ收йӣҶж—Ҙеҝ—дҝЎжҒҜпјҢFilebeatеҗҢдёҖдәӨз»ҷLogstashиҝӣиЎҢиҝҮж»ӨеҗҺеҶҚElasticsearchгҖӮиҝҷдәӣеңЁжҺҘдёӢжқҘзҡ„ж–Үз« еңЁиҝӣиЎҢи®Іи§ЈпјҢе…Ҳж”ҫдёҖеј жһ¶жһ„еӣҫеҗ§гҖӮ
еҲ°жӯӨпјҢзӣёдҝЎеӨ§е®¶еҜ№вҖңLogstashејҖжәҗж—Ҙеҝ—з®ЎзҗҶж–№жі•жҳҜд»Җд№ҲвҖқжңүдәҶжӣҙж·ұзҡ„дәҶи§ЈпјҢдёҚеҰЁжқҘе®һйҷ…ж“ҚдҪңдёҖз•Әеҗ§пјҒиҝҷйҮҢжҳҜдәҝйҖҹдә‘зҪ‘з«ҷпјҢжӣҙеӨҡзӣёе…іеҶ…е®№еҸҜд»Ҙиҝӣе…Ҙзӣёе…ійў‘йҒ“иҝӣиЎҢжҹҘиҜўпјҢе…іжіЁжҲ‘们пјҢ继з»ӯеӯҰд№ пјҒ





