жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңuniqе‘Ҫд»ӨеҰӮдҪ•дҪҝз”ЁвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
uniqе‘Ҫд»Ө жң¬иә«иў«з”ЁдҪңеҺ»йҷӨж–Үжң¬ж–Ү件дёӯзҡ„йҮҚеӨҚиЎҢпјҢдёҺsortе‘Ҫд»ӨзӣёдјјпјҢдҪҶжҳҜе§Ӣз»ҲиҝҳжҳҜжңүеҢәеҲ«зҡ„гҖӮж–Үжң¬ж–Ү件еңЁLinuxдёӯпјҢж—ўеҸҜд»ҘжҳҜtxtпјҢд№ҹеҸҜд»ҘжҳҜе…¶д»–д»»ж„ҸиҮӘе®ҡд№үж јејҸгҖӮ
йҰ–е…ҲпјҢи®©жҲ‘们еҲӣе»әдёҖдёӘеёҰжңүдёҖдәӣйҮҚеӨҚиЎҢзҡ„ж–Ү件пјҡ
vi ostechnix.txt
welcome to ostechnix
welcome to ostechnix
Linus is the creator of Linux.
Linux is secure by default
Linus is the creator of Linux.
Top 500 super computers are powered by Linux жӯЈеҰӮдҪ еңЁдёҠйқўзҡ„ж–Ү件дёӯзңӢеҲ°зҡ„пјҢжҲ‘们жңүдёҖдәӣйҮҚеӨҚзҡ„иЎҢпјҲ第дёҖиЎҢе’Ң第дәҢиЎҢпјҢ第дёүиЎҢе’Ң第дә”иЎҢжҳҜйҮҚеӨҚзҡ„пјүгҖӮ
1гҖҒ дҪҝз”Ё uniq е‘Ҫд»ӨеҲ йҷӨж–Ү件дёӯзҡ„иҝһз»ӯйҮҚеӨҚиЎҢ еҰӮжһңдҪ еңЁдёҚдҪҝз”Ёд»»дҪ•еҸӮж•°зҡ„жғ…еҶөдёӢдҪҝз”Ё uniq е‘Ҫд»ӨпјҢе®ғе°ҶеҲ йҷӨжүҖжңүиҝһз»ӯзҡ„йҮҚеӨҚиЎҢпјҢеҸӘжҳҫзӨәе”ҜдёҖзҡ„иЎҢгҖӮ
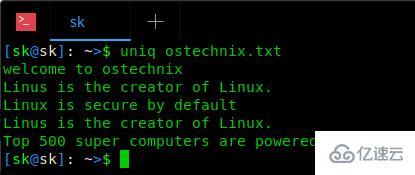
uniq ostechnix.txt зӨәдҫӢиҫ“еҮәпјҡ
еҰӮдҪ жүҖи§ҒпјҢ uniq е‘Ҫд»ӨеҲ йҷӨдәҶз»ҷе®ҡж–Ү件дёӯзҡ„жүҖжңүиҝһз»ӯйҮҚеӨҚиЎҢгҖӮдҪ еҸҜиғҪиҝҳжіЁж„ҸеҲ°пјҢдёҠйқўзҡ„иҫ“еҮәд»Қ然жңү第дәҢиЎҢе’Ң第еӣӣиЎҢйҮҚеӨҚдәҶгҖӮиҝҷжҳҜеӣ дёә uniq е‘Ҫд»ӨеҸӘжңүеңЁзӣёйӮ»зҡ„жғ…еҶөдёӢжүҚдјҡеҲ йҷӨйҮҚеӨҚзҡ„иЎҢпјҢеҪ“然пјҢжҲ‘们д№ҹеҸҜд»ҘеҲ йҷӨйқһиҝһз»ӯзҡ„йҮҚеӨҚиЎҢгҖӮиҜ·зңӢдёӢйқўзҡ„第дәҢдёӘдҫӢеӯҗгҖӮ
2гҖҒ еҲ йҷӨжүҖжңүйҮҚеӨҚзҡ„иЎҢ sort ostechnix.txt | uniq зӨәдҫӢиҫ“еҮәпјҡ
зңӢеҲ°дәҶеҗ—пјҹжІЎжңүйҮҚеӨҚзҡ„иЎҢгҖӮжҚўеҸҘиҜқиҜҙпјҢдёҠйқўзҡ„е‘Ҫд»Өе°ҶжҳҫзӨәеңЁ ostechnix.txt дёӯеҸӘеҮәзҺ°дёҖж¬Ўзҡ„иЎҢгҖӮжҲ‘们дҪҝз”Ё sort е‘Ҫд»ӨдёҺ uniq е‘Ҫд»Өз»“еҗҲпјҢеӣ дёәпјҢе°ұеғҸжҲ‘жҸҗеҲ°зҡ„пјҢйҷӨйқһйҮҚеӨҚиЎҢжҳҜзӣёйӮ»зҡ„пјҢеҗҰеҲҷ uniq дёҚдјҡеҲ йҷӨе®ғ们гҖӮ
3гҖҒ еҸӘжҳҫзӨәж–Ү件дёӯе”ҜдёҖзҡ„дёҖиЎҢ дёәдәҶеҸӘжҳҫзӨәж–Ү件дёӯе”ҜдёҖзҡ„дёҖиЎҢпјҢеҸҜд»Ҙиҝҷж ·еҒҡпјҡ
sort ostechnix.txt | uniq -u зӨәдҫӢиҫ“еҮәпјҡ
Linux is secure by default
Top 500 super computers are powered by Linux еҰӮдҪ жүҖи§ҒпјҢеңЁз»ҷе®ҡзҡ„ж–Ү件дёӯеҸӘжңүдёӨиЎҢжҳҜе”ҜдёҖзҡ„гҖӮ
4гҖҒ еҸӘжҳҫзӨәйҮҚеӨҚзҡ„иЎҢ еҗҢж ·зҡ„пјҢжҲ‘们д№ҹеҸҜд»ҘжҳҫзӨәж–Ү件дёӯйҮҚеӨҚзҡ„иЎҢпјҢе°ұеғҸдёӢйқўиҝҷж ·пјҡ
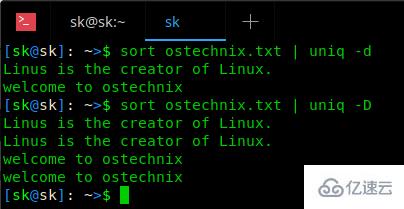
sort ostechnix.txt | uniq -d зӨәдҫӢиҫ“еҮәпјҡ
Linus is the creator of Linux.
welcome to ostechnix иҝҷдёӨиЎҢеңЁ ostechnix.txt ж–Ү件дёӯжҳҜйҮҚеӨҚзҡ„иЎҢгҖӮиҜ·жіЁж„Ҹ -dпјҲе°ҸеҶҷ dпјү е°ҶдјҡеҸӘжү“еҚ°йҮҚеӨҚзҡ„иЎҢпјҢжҜҸз»„жҳҫзӨәдёҖдёӘгҖӮжү“еҚ°жүҖжңүйҮҚеӨҚзҡ„иЎҢпјҢдҪҝз”Ё -DпјҲеӨ§еҶҷ DпјүпјҢеҰӮдёӢжүҖзӨәпјҡ
sort ostechnix.txt | uniq -D еңЁдёӢйқўзҡ„жҲӘеӣҫдёӯзңӢдёӨдёӘйҖүйЎ№зҡ„еҢәеҲ«пјҡ
5гҖҒ жҳҫзӨәж–Ү件дёӯжҜҸдёҖиЎҢзҡ„еҮәзҺ°ж¬Ўж•° з”ұдәҺжҹҗз§ҚеҺҹеӣ пјҢдҪ еҸҜиғҪжғіиҰҒжЈҖжҹҘз»ҷе®ҡж–Ү件дёӯжҜҸдёҖиЎҢйҮҚеӨҚеҮәзҺ°зҡ„ж¬Ўж•°гҖӮиҰҒеҒҡеҲ°иҝҷдёҖзӮ№пјҢдҪҝз”Ё -c йҖүйЎ№пјҢеҰӮдёӢжүҖзӨәпјҡ
sort ostechnix.txt | uniq -c зӨәдҫӢиҫ“еҮәпјҡ
Linus is the creator of Linux.
Linux is secure by default
Top 500 super computers are powered by Linux
welcome to ostechnix жҲ‘们иҝҳеҸҜд»ҘжҢүз…§жҜҸдёҖиЎҢзҡ„еҮәзҺ°ж¬Ўж•°иҝӣиЎҢжҺ’еәҸпјҢ然еҗҺжҳҫзӨәпјҢеҰӮдёӢжүҖзӨәпјҡ
sort ostechnix.txt | uniq -c | sort -nr зӨәдҫӢиҫ“еҮәпјҡ
welcome to ostechnix
Linus is the creator of Linux.
Top 500 super computers are powered by Linux
Linux is secure by default 6гҖҒ е°ҶжҜ”иҫғйҷҗеҲ¶дёә N дёӘеӯ—з¬Ұ жҲ‘们еҸҜд»ҘдҪҝз”Ё -w йҖүйЎ№жқҘйҷҗеҲ¶еҜ№ж–Ү件дёӯзү№е®ҡж•°йҮҸеӯ—з¬Ұзҡ„жҜ”иҫғгҖӮдҫӢеҰӮпјҢи®©жҲ‘们жҜ”иҫғж–Ү件дёӯзҡ„еүҚеӣӣдёӘеӯ—з¬ҰпјҢ并жҳҫзӨәйҮҚеӨҚиЎҢпјҢеҰӮдёӢжүҖзӨәпјҡ
uniq -d -w 4 ostechnix.txt 7гҖҒ еҝҪз•ҘжҜ”иҫғжҢҮе®ҡзҡ„ N дёӘеӯ—з¬Ұ еғҸеҜ№ж–Ү件дёӯиЎҢзҡ„еүҚ N дёӘеӯ—з¬ҰиҝӣиЎҢйҷҗеҲ¶жҜ”иҫғдёҖж ·пјҢжҲ‘们д№ҹеҸҜд»ҘдҪҝз”Ё -s йҖүйЎ№жқҘеҝҪз•ҘжҜ”иҫғеүҚ N дёӘеӯ—з¬ҰгҖӮ
дёӢйқўзҡ„е‘Ҫд»Өе°ҶеҝҪз•ҘеңЁж–Ү件дёӯжҜҸиЎҢзҡ„еүҚеӣӣдёӘеӯ—з¬ҰиҝӣиЎҢжҜ”иҫғпјҡ
uniq -d -s 4 ostechnix.txt дёәдәҶеҝҪз•ҘжҜ”иҫғеүҚ N дёӘеӯ—ж®өпјҲLCTT иҜ‘жіЁпјҡеҚіеүҚеҮ еҲ—пјүиҖҢдёҚжҳҜеӯ—з¬ҰпјҢеңЁдёҠйқўзҡ„е‘Ҫд»ӨдёӯдҪҝз”Ё -f йҖүйЎ№гҖӮ
ж¬ІдәҶи§ЈжӣҙеӨҡиҜҰжғ…пјҢиҜ·еҸӮиҖғеё®еҠ©йғЁеҲҶпјҡ
uniq --help д№ҹеҸҜд»ҘдҪҝз”Ё man е‘Ҫд»ӨжҹҘзңӢпјҡ
man uniq вҖңuniqе‘Ҫд»ӨеҰӮдҪ•дҪҝз”ЁвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ