иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іHTTP/2еҰӮдҪ•е®һзҺ°еӨҙйғЁеҺӢзј©зҡ„еҶ…е®№гҖӮе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢдёҖиө·и·ҹйҡҸе°Ҹзј–иҝҮжқҘзңӢзңӢеҗ§гҖӮ
йҡҸзқҖwebеҠҹиғҪи¶ҠжқҘи¶ҠеӨҚжқӮпјҢиҜ·жұӮж•°йҮҸи¶ҠжқҘи¶ҠеӨҡпјҢйҡҸд№ӢиҖҢжқҘзҡ„е°ұжҳҜеӨҙйғЁзҡ„жөҒйҮҸи¶ҠжқҘи¶ҠеӨҡпјҢ并且еңЁе»әз«ӢеҲқж¬Ўй“ҫжҺҘд№ӢеҗҺзҡ„й“ҫжҺҘд№ҹиҰҒеҸ‘йҖҒuser-agentзӯүдҝЎжҒҜпјҢжҳҜеңЁжҳҜдёҖз§ҚжөӘиҙ№пјҢеӣ жӯӨпјҢhttp2жҸҗеҮәдәҶеҜ№иҜ·жұӮе’Ңе“Қеә”зҡ„еӨҙйғЁиҝӣиЎҢеҺӢзј©пјҢеҚідёҚеҶҚеҸӘжҳҜеҺӢзј©дё»йўҳйғЁеҲҶпјҢиҝҷз§ҚеҺӢзј©ж–№ејҸе°ұжҳҜHAPCKгҖӮ
image-20210818200104438 дёәд»Җд№ҲиҰҒеҺӢзј©
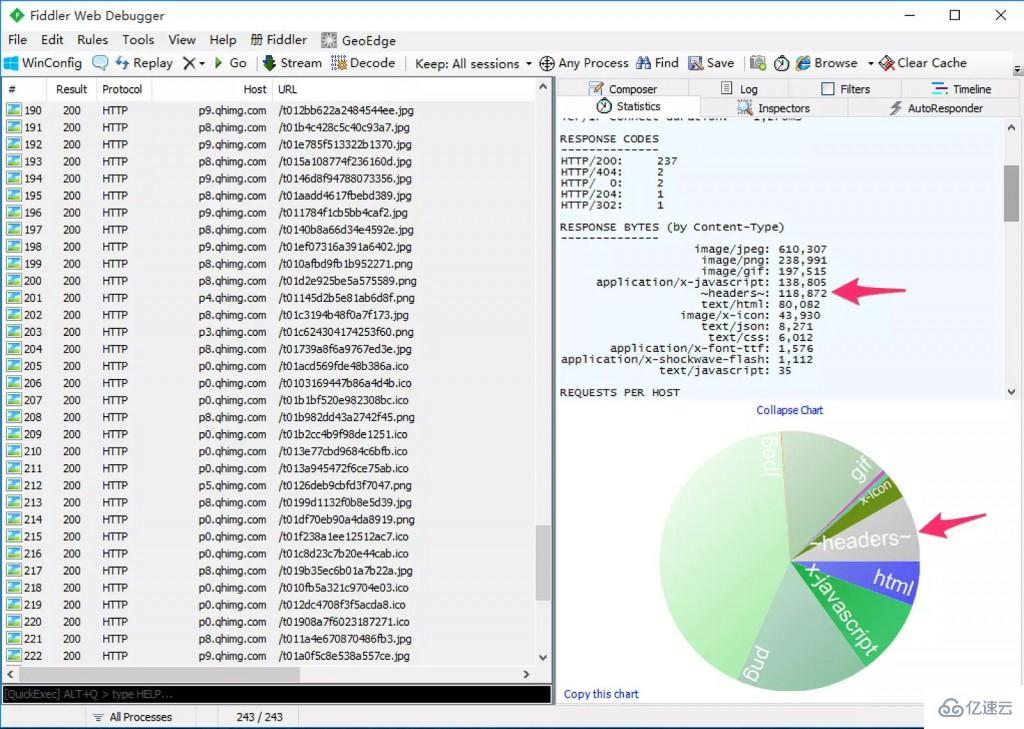
еңЁ HTTP/1 дёӯпјҢHTTP иҜ·жұӮе’Ңе“Қеә”йғҪжҳҜз”ұгҖҢзҠ¶жҖҒиЎҢгҖҒиҜ·жұӮ / е“Қеә”еӨҙйғЁгҖҒж¶ҲжҒҜдё»дҪ“гҖҚдёүйғЁеҲҶз»„жҲҗгҖӮдёҖиҲ¬иҖҢиЁҖпјҢж¶ҲжҒҜдё»дҪ“йғҪдјҡз»ҸиҝҮ gzip еҺӢзј©пјҢжҲ–иҖ…жң¬иә«дј иҫ“зҡ„е°ұжҳҜеҺӢзј©иҝҮеҗҺзҡ„дәҢиҝӣеҲ¶ж–Ү件пјҲдҫӢеҰӮеӣҫзүҮгҖҒйҹійў‘пјүпјҢдҪҶзҠ¶жҖҒиЎҢе’ҢеӨҙйғЁеҚҙжІЎжңүз»ҸиҝҮд»»дҪ•еҺӢзј©пјҢзӣҙжҺҘд»ҘзәҜж–Үжң¬дј иҫ“гҖӮйҡҸзқҖ Web еҠҹиғҪи¶ҠжқҘи¶ҠеӨҚжқӮпјҢжҜҸдёӘйЎөйқўдә§з”ҹзҡ„иҜ·жұӮж•°д№ҹи¶ҠжқҘи¶ҠеӨҡпјҢж №жҚ® HTTP Archive зҡ„з»ҹи®ЎпјҢеҪ“еүҚе№іеқҮжҜҸдёӘйЎөйқўйғҪдјҡдә§з”ҹдёҠзҷҫдёӘиҜ·жұӮгҖӮи¶ҠжқҘи¶ҠеӨҡзҡ„иҜ·жұӮеҜјиҮҙж¶ҲиҖ—еңЁеӨҙйғЁзҡ„жөҒйҮҸи¶ҠжқҘи¶ҠеӨҡпјҢе°Өе…¶жҳҜжҜҸж¬ЎйғҪиҰҒдј иҫ“ UserAgentгҖҒCookie иҝҷзұ»дёҚдјҡйў‘з№ҒеҸҳеҠЁзҡ„еҶ…е®№пјҢе®Ңе…ЁжҳҜдёҖз§ҚжөӘиҙ№гҖӮ
д»ҘдёӢжҳҜжҲ‘йҡҸжүӢжү“ејҖзҡ„дёҖдёӘйЎөйқўзҡ„жҠ“еҢ…з»“жһңгҖӮеҸҜд»ҘзңӢеҲ°пјҢдј иҫ“еӨҙйғЁзҡ„зҪ‘з»ңејҖй”Җи¶…иҝҮ 100kbпјҢжҜ” HTML иҝҳеӨҡпјҡ
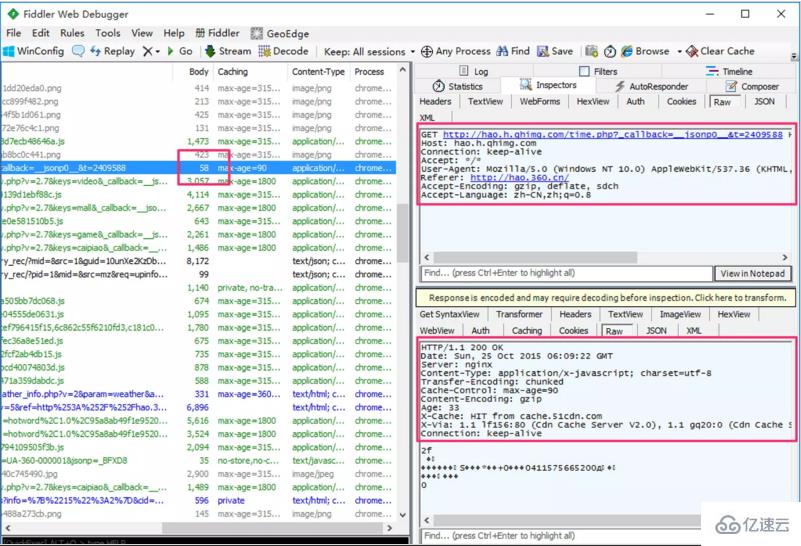
жҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜжҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜ дёӢйқўжҳҜе…¶дёӯдёҖдёӘиҜ·жұӮзҡ„жҳҺз»ҶгҖӮеҸҜд»ҘзңӢеҲ°пјҢдёәдәҶиҺ·еҫ— 58 еӯ—иҠӮзҡ„ж•°жҚ®пјҢеңЁеӨҙйғЁдј иҫ“дёҠиҠұиҙ№дәҶеҘҪеҮ еҖҚзҡ„жөҒйҮҸпјҡ
жҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜжҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜ HTTP/1 ж—¶д»ЈпјҢдёәдәҶеҮҸе°‘еӨҙйғЁж¶ҲиҖ—зҡ„жөҒйҮҸпјҢжңүеҫҲеӨҡдјҳеҢ–ж–№жЎҲеҸҜд»Ҙе°қиҜ•пјҢдҫӢеҰӮеҗҲ并иҜ·жұӮгҖҒеҗҜз”Ё Cookie-Free еҹҹеҗҚзӯүзӯүпјҢдҪҶжҳҜиҝҷдәӣж–№жЎҲжҲ–еӨҡжҲ–е°‘дјҡеј•е…ҘдёҖдәӣж–°зҡ„й—®йўҳпјҢиҝҷйҮҢдёҚеұ•ејҖи®Ёи®әгҖӮ
еҺӢзј©еҗҺзҡ„ж•Ҳжһң
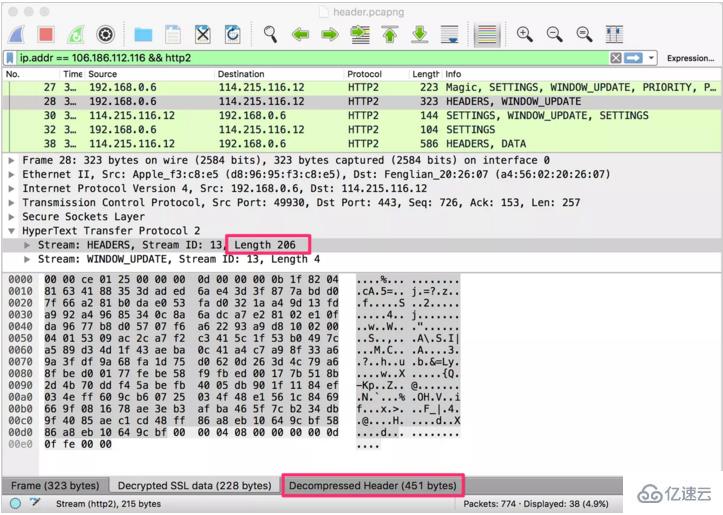
йҰ–е…ҲзӣҙжҺҘдёҠеӣҫгҖӮдёӢеӣҫйҖүдёӯзҡ„ Stream жҳҜйҰ–ж¬Ўи®ҝй—®жң¬з«ҷпјҢжөҸи§ҲеҷЁеҸ‘еҮәзҡ„иҜ·жұӮеӨҙпјҡ
жҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜжҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜ д»ҺеӣҫзүҮдёӯеҸҜд»ҘзңӢеҲ°иҝҷдёӘ HEADERS жөҒзҡ„й•ҝеәҰжҳҜ 206 дёӘеӯ—иҠӮпјҢиҖҢи§Јз ҒеҗҺзҡ„еӨҙйғЁй•ҝеәҰжңү 451 дёӘеӯ—иҠӮгҖӮз”ұжӯӨеҸҜи§ҒпјҢеҺӢзј©еҗҺзҡ„еӨҙйғЁеӨ§е°ҸеҮҸе°‘дәҶдёҖеҚҠеӨҡгҖӮ
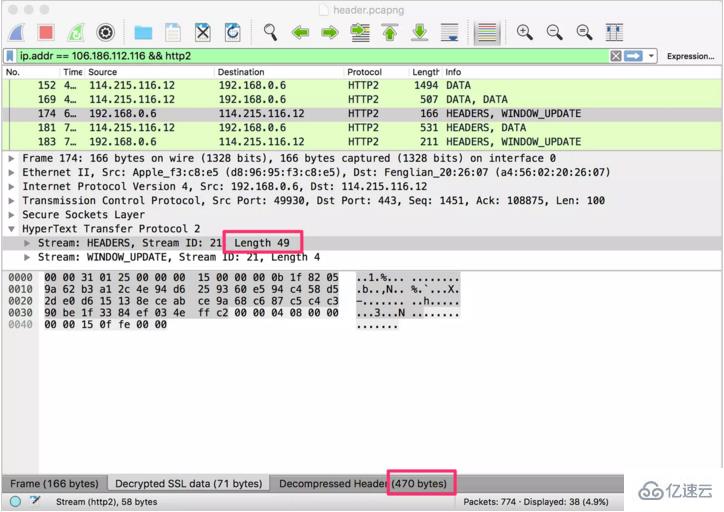
然иҖҢиҝҷе°ұжҳҜе…ЁйғЁеҗ—пјҹеҶҚдёҠдёҖеј еӣҫгҖӮдёӢеӣҫйҖүдёӯзҡ„ Stream жҳҜзӮ№еҮ»жң¬з«ҷй“ҫжҺҘеҗҺпјҢжөҸи§ҲеҷЁеҸ‘еҮәзҡ„иҜ·жұӮеӨҙпјҡ
жҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜжҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜ еҸҜд»ҘзңӢеҲ°иҝҷдёҖж¬ЎпјҢHEADERS жөҒзҡ„й•ҝеәҰеҸӘжңү 49 дёӘеӯ—иҠӮпјҢдҪҶжҳҜи§Јз ҒеҗҺзҡ„еӨҙйғЁй•ҝеәҰеҚҙжңү 470 дёӘеӯ—иҠӮгҖӮиҝҷдёҖж¬ЎпјҢеҺӢзј©еҗҺзҡ„еӨҙйғЁеӨ§е°ҸеҮ д№ҺеҸӘжңүеҺҹе§ӢеӨ§е°Ҹзҡ„ 1/10гҖӮ
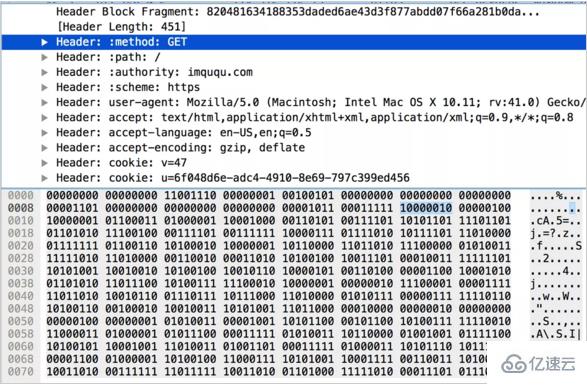
дёәд»Җд№ҲеүҚеҗҺдёӨж¬Ўе·®и·қиҝҷд№ҲеӨ§е‘ўпјҹжҲ‘们жҠҠдёӨж¬Ўзҡ„еӨҙйғЁдҝЎжҒҜеұ•ејҖпјҢжҹҘзңӢеҗҢдёҖдёӘеӯ—ж®өдёӨж¬Ўдј иҫ“жүҖеҚ з”Ёзҡ„еӯ—иҠӮж•°пјҡ
жҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜжҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜ
жҠҖжңҜеҺҹзҗҶ
дёӢйқўиҝҷеј жҲӘеӣҫпјҢеҸ–иҮӘ Google зҡ„жҖ§иғҪ专家 Ilya Grigorik еңЁ Velocity 2015 • SC дјҡи®®дёӯеҲҶдә«зҡ„гҖҢHTTP/2 is here, let’s optimize!гҖҚпјҢйқһеёёзӣҙи§Ӯең°жҸҸиҝ°дәҶ HTTP/2 дёӯеӨҙйғЁеҺӢзј©зҡ„еҺҹзҗҶпјҡ
жҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜжҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜ жҲ‘еҶҚз”ЁйҖҡдҝ—зҡ„иҜӯиЁҖи§ЈйҮҠдёӢпјҢеӨҙйғЁеҺӢзј©йңҖиҰҒеңЁж”ҜжҢҒ HTTP/2 зҡ„жөҸи§ҲеҷЁе’ҢжңҚеҠЎз«Ҝд№Ӣй—ҙпјҡз»ҙжҠӨдёҖд»ҪзӣёеҗҢзҡ„йқҷжҖҒеӯ—е…ёпјҲStatic TableпјүпјҢеҢ…еҗ«еёёи§Ғзҡ„еӨҙйғЁеҗҚз§°пјҢд»ҘеҸҠзү№еҲ«еёёи§Ғзҡ„еӨҙйғЁеҗҚз§°дёҺеҖјзҡ„з»„еҗҲпјӣ
з»ҙжҠӨдёҖд»ҪзӣёеҗҢзҡ„йқҷжҖҒеӯ—е…ёпјҲStatic TableпјүпјҢеҢ…еҗ«еёёи§Ғзҡ„еӨҙйғЁеҗҚз§°пјҢд»ҘеҸҠзү№еҲ«еёёи§Ғзҡ„еӨҙйғЁеҗҚз§°дёҺеҖјзҡ„з»„еҗҲ з»ҙжҠӨдёҖд»ҪзӣёеҗҢзҡ„еҠЁжҖҒеӯ—е…ёпјҲDynamic TableпјүпјҢеҸҜд»ҘеҠЁжҖҒең°ж·»еҠ еҶ…е®№ ж”ҜжҢҒеҹәдәҺйқҷжҖҒе“ҲеӨ«жӣјз ҒиЎЁзҡ„е“ҲеӨ«жӣјзј–з ҒпјҲHuffman Codingпјү йқҷжҖҒеӯ—е…ёзҡ„дҪңз”ЁжңүдёӨдёӘпјҡ1пјүеҜ№дәҺе®Ңе…ЁеҢ№й…Қзҡ„еӨҙйғЁй”®еҖјеҜ№пјҢдҫӢеҰӮ :method: GETпјҢеҸҜд»ҘзӣҙжҺҘдҪҝз”ЁдёҖдёӘеӯ—з¬ҰиЎЁзӨәпјӣ2пјүеҜ№дәҺеӨҙйғЁеҗҚз§°еҸҜд»ҘеҢ№й…Қзҡ„й”®еҖјеҜ№пјҢдҫӢеҰӮ cookie: xxxxxxxпјҢеҸҜд»Ҙе°ҶеҗҚз§°дҪҝз”ЁдёҖдёӘеӯ—з¬ҰиЎЁзӨәгҖӮHTTP/2 дёӯзҡ„йқҷжҖҒеӯ—е…ёеҰӮдёӢ
Index Header Name Header Value 1 :authority 2 :method GET 3 :method POST 4 :path / 5 :path /index.html 6 :scheme http 7 :scheme https 8 :status 200 … … … 32 cookie … … … 60 via 61 www-authenticate
жҳҫзӨәиҜҰз»ҶдҝЎжҒҜ
еҗҢж—¶пјҢжөҸи§ҲеҷЁеҸҜд»Ҙе‘ҠзҹҘжңҚеҠЎз«ҜпјҢе°Ҷ cookie: xxxxxxx ж·»еҠ еҲ°еҠЁжҖҒеӯ—е…ёдёӯпјҢиҝҷж ·еҗҺз»ӯж•ҙдёӘй”®еҖјеҜ№е°ұеҸҜд»ҘдҪҝз”ЁдёҖдёӘеӯ—з¬ҰиЎЁзӨәдәҶгҖӮзұ»дјјзҡ„пјҢжңҚеҠЎз«Ҝд№ҹеҸҜд»Ҙжӣҙж–°еҜ№ж–№зҡ„еҠЁжҖҒеӯ—е…ёгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеҠЁжҖҒеӯ—е…ёдёҠдёӢж–Үжңүе…іпјҢйңҖиҰҒдёәжҜҸдёӘ HTTP/2 иҝһжҺҘз»ҙжҠӨдёҚеҗҢзҡ„еӯ—е…ё,дҪҝз”Ёеӯ—е…ёеҸҜд»ҘжһҒеӨ§ең°жҸҗеҚҮеҺӢзј©ж•ҲжһңпјҢе…¶дёӯйқҷжҖҒеӯ—е…ёеңЁйҰ–ж¬ЎиҜ·жұӮдёӯе°ұеҸҜд»ҘдҪҝз”ЁгҖӮеҜ№дәҺйқҷжҖҒгҖҒеҠЁжҖҒеӯ—е…ёдёӯдёҚеӯҳеңЁзҡ„еҶ…е®№пјҢиҝҳеҸҜд»ҘдҪҝз”Ёе“ҲеӨ«жӣјзј–з ҒжқҘеҮҸе°ҸдҪ“з§ҜгҖӮHTTP/2 дҪҝз”ЁдәҶдёҖд»ҪйқҷжҖҒе“ҲеӨ«жӣјз ҒиЎЁпјҲиҜҰи§ҒпјүпјҢд№ҹйңҖиҰҒеҶ…зҪ®еңЁе®ўжҲ·з«Ҝе’ҢжңҚеҠЎз«Ҝд№ӢдёӯгҖӮ иҝҷйҮҢйЎәдҫҝиҜҙдёҖдёӢпјҢHTTP/1 зҡ„зҠ¶жҖҒиЎҢдҝЎжҒҜпјҲMethodгҖҒPathгҖҒStatus зӯүпјүпјҢеңЁ HTTP/2 дёӯиў«жӢҶжҲҗй”®еҖјеҜ№ж”ҫе…ҘеӨҙйғЁпјҲеҶ’еҸ·ејҖеӨҙзҡ„йӮЈдәӣпјүпјҢеҗҢж ·еҸҜд»Ҙдә«еҸ—еҲ°еӯ—е…ёе’Ңе“ҲеӨ«жӣјеҺӢзј©гҖӮеҸҰеӨ–пјҢHTTP/2 дёӯжүҖжңүеӨҙйғЁеҗҚз§°еҝ…йЎ»е°ҸеҶҷгҖӮ
е®һзҺ°з»ҶиҠӮ
дәҶи§ЈдәҶ HTTP/2 еӨҙйғЁеҺӢзј©зҡ„еҹәжң¬еҺҹзҗҶпјҢжңҖеҗҺжҲ‘们жқҘзңӢдёҖдёӢе…·дҪ“зҡ„е®һзҺ°з»ҶиҠӮгҖӮHTTP/2 зҡ„еӨҙйғЁй”®еҖјеҜ№жңүд»ҘдёӢиҝҷдәӣжғ…еҶөпјҡ
1пјүж•ҙдёӘеӨҙйғЁй”®еҖјеҜ№йғҪеңЁеӯ—е…ёдёӯ
0 1 2 3 4 5 6 7
+---+---+---+---+---+---+---+---+
| 1 | Index (7+) |
+---+---------------------------+ иҝҷжҳҜжңҖз®ҖеҚ•зҡ„жғ…еҶөпјҢдҪҝз”ЁдёҖдёӘеӯ—иҠӮе°ұеҸҜд»ҘиЎЁзӨәиҝҷдёӘеӨҙйғЁдәҶпјҢжңҖе·ҰдёҖдҪҚеӣәе®ҡдёә 1пјҢд№ӢеҗҺдёғдҪҚеӯҳж”ҫй”®еҖјеҜ№еңЁйқҷжҖҒжҲ–еҠЁжҖҒеӯ—е…ёдёӯзҡ„зҙўеј•гҖӮдҫӢеҰӮдёӢеӣҫдёӯпјҢеӨҙйғЁзҙўеј•еҖјдёә 2пјҲ0000010пјүпјҢеңЁйқҷжҖҒеӯ—е…ёдёӯжҹҘиҜўеҸҜеҫ— :method: GETгҖӮ
жҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜжҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜ 2пјүеӨҙйғЁеҗҚз§°еңЁеӯ—е…ёдёӯпјҢжӣҙж–°еҠЁжҖҒеӯ—е…ё
0 1 2 3 4 5 6 7
+---+---+---+---+---+---+---+---+
| 0 | 1 | Index (6+) |
+---+---+-----------------------+
| H | Value Length (7+) |
+---+---------------------------+
| Value String (Length octets) |
+-------------------------------+ еҜ№дәҺиҝҷз§Қжғ…еҶөпјҢйҰ–е…ҲйңҖиҰҒдҪҝз”ЁдёҖдёӘеӯ—иҠӮиЎЁзӨәеӨҙйғЁеҗҚз§°пјҡе·ҰдёӨдҪҚеӣәе®ҡдёә 01пјҢд№ӢеҗҺе…ӯдҪҚеӯҳж”ҫеӨҙйғЁеҗҚз§°еңЁйқҷжҖҒжҲ–еҠЁжҖҒеӯ—е…ёдёӯзҡ„зҙўеј•гҖӮжҺҘдёӢжқҘзҡ„дёҖдёӘеӯ—иҠӮ第дёҖдҪҚ H иЎЁзӨәеӨҙйғЁеҖјжҳҜеҗҰдҪҝз”ЁдәҶе“ҲеӨ«жӣјзј–з ҒпјҢеү©дҪҷдёғдҪҚиЎЁзӨәеӨҙйғЁеҖјзҡ„й•ҝеәҰ LпјҢеҗҺз»ӯ L дёӘеӯ—иҠӮе°ұжҳҜеӨҙйғЁеҖјзҡ„е…·дҪ“еҶ…е®№дәҶгҖӮдҫӢеҰӮдёӢеӣҫдёӯзҙўеј•еҖјдёә 32пјҲ100000пјүпјҢеңЁйқҷжҖҒеӯ—е…ёдёӯжҹҘиҜўеҸҜеҫ— cookieпјӣеӨҙйғЁеҖјдҪҝз”ЁдәҶе“ҲеӨ«жӣјзј–з ҒпјҲ1пјүпјҢй•ҝеәҰжҳҜ 28пјҲ0011100пјүпјӣжҺҘдёӢжқҘзҡ„ 28 дёӘеӯ—иҠӮжҳҜ cookie зҡ„еҖјпјҢе°Ҷе…¶иҝӣиЎҢе“ҲеӨ«жӣји§Јз Ғе°ұиғҪеҫ—еҲ°е…·дҪ“еҶ…е®№гҖӮ
жҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜжҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜ е®ўжҲ·з«ҜжҲ–жңҚеҠЎз«ҜзңӢеҲ°иҝҷз§Қж јејҸзҡ„еӨҙйғЁй”®еҖјеҜ№пјҢдјҡе°Ҷе…¶ж·»еҠ еҲ°иҮӘе·ұзҡ„еҠЁжҖҒеӯ—е…ёдёӯгҖӮеҗҺз»ӯдј иҫ“иҝҷж ·зҡ„еҶ…е®№пјҢе°ұз¬ҰеҗҲ第 1 з§Қжғ…еҶөдәҶгҖӮ
3пјүеӨҙйғЁеҗҚз§°дёҚеңЁеӯ—е…ёдёӯпјҢжӣҙж–°еҠЁжҖҒеӯ—е…ё
0 1 2 3 4 5 6 7
+---+---+---+---+---+---+---+---+
| 0 | 1 | 0 |
+---+---+-----------------------+
| H | Name Length (7+) |
+---+---------------------------+
| Name String (Length octets) |
+---+---------------------------+
| H | Value Length (7+) |
+---+---------------------------+
| Value String (Length octets) |
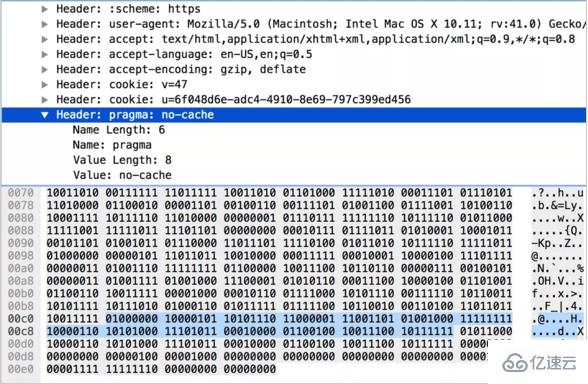
+-------------------------------+ иҝҷз§Қжғ…еҶөдёҺ第 2 з§Қжғ…еҶөзұ»дјјпјҢеҸӘжҳҜз”ұдәҺеӨҙйғЁеҗҚз§°дёҚеңЁеӯ—е…ёдёӯпјҢжүҖд»Ҙ第дёҖдёӘеӯ—иҠӮеӣәе®ҡдёә 01000000пјӣжҺҘзқҖз”іжҳҺеҗҚз§°жҳҜеҗҰдҪҝз”Ёе“ҲеӨ«жӣјзј–з ҒеҸҠй•ҝеәҰпјҢ并ж”ҫдёҠеҗҚз§°зҡ„е…·дҪ“еҶ…е®№пјӣеҶҚз”іжҳҺеҖјжҳҜеҗҰдҪҝз”Ёе“ҲеӨ«жӣјзј–з ҒеҸҠй•ҝеәҰпјҢжңҖеҗҺж”ҫдёҠеҖјзҡ„е…·дҪ“еҶ…е®№гҖӮдҫӢеҰӮдёӢеӣҫдёӯеҗҚз§°зҡ„й•ҝеәҰжҳҜ 5пјҲ0000101пјүпјҢеҖјзҡ„й•ҝеәҰжҳҜ 6пјҲ0000110пјүгҖӮеҜ№е…¶е…·дҪ“еҶ…е®№иҝӣиЎҢе“ҲеӨ«жӣји§Јз ҒеҗҺпјҢеҸҜеҫ— pragma: no-cacheгҖӮ
жҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜжҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜ е®ўжҲ·з«ҜжҲ–жңҚеҠЎз«ҜзңӢеҲ°иҝҷз§Қж јејҸзҡ„еӨҙйғЁй”®еҖјеҜ№пјҢдјҡе°Ҷе…¶ж·»еҠ еҲ°иҮӘе·ұзҡ„еҠЁжҖҒеӯ—е…ёдёӯгҖӮеҗҺз»ӯдј иҫ“иҝҷж ·зҡ„еҶ…е®№пјҢе°ұз¬ҰеҗҲ第 1 з§Қжғ…еҶөдәҶгҖӮ
4пјүеӨҙйғЁеҗҚз§°еңЁеӯ—е…ёдёӯпјҢдёҚе…Ғи®ёжӣҙж–°еҠЁжҖҒеӯ—е…ё
0 1 2 3 4 5 6 7
+---+---+---+---+---+---+---+---+
| 0 | 0 | 0 | 1 | Index (4+) |
+---+---+-----------------------+
| H | Value Length (7+) |
+---+---------------------------+
| Value String (Length octets) |
+-------------------------------+ иҝҷз§Қжғ…еҶөдёҺ第 2 з§Қжғ…еҶөйқһеёёзұ»дјјпјҢе”ҜдёҖдёҚеҗҢд№ӢеӨ„жҳҜпјҡ第дёҖдёӘеӯ—иҠӮе·ҰеӣӣдҪҚеӣәе®ҡдёә 0001пјҢеҸӘеү©дёӢеӣӣдҪҚжқҘеӯҳж”ҫзҙўеј•дәҶпјҢеҰӮдёӢеӣҫпјҡ
жҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜжҸӯз§ҳ HTTP/2 еӨҙйғЁеҺӢзј©жҠҖжңҜ иҝҷйҮҢйңҖиҰҒд»Ӣз»ҚеҸҰеӨ–дёҖдёӘзҹҘиҜҶзӮ№пјҡеҜ№ж•ҙж•°зҡ„и§Јз ҒгҖӮдёҠеӣҫдёӯ第дёҖдёӘеӯ—иҠӮдёә 00011111пјҢ并дёҚд»ЈиЎЁеӨҙйғЁеҗҚз§°зҡ„зҙўеј•дёә 15пјҲ1111пјүгҖӮ第дёҖдёӘеӯ—иҠӮеҺ»жҺүеӣәе®ҡзҡ„ 0001пјҢеҸӘеү©еӣӣдҪҚеҸҜз”ЁпјҢе°ҶдҪҚж•°з”Ё N иЎЁзӨәпјҢе®ғеҸӘиғҪз”ЁжқҘиЎЁзӨәе°ҸдәҺгҖҢ2 ^ N – 1 = 15гҖҚзҡ„ж•ҙж•° IгҖӮеҜ№дәҺ IпјҢйңҖиҰҒжҢүз…§д»ҘдёӢ规еҲҷжұӮеҖјпјҲRFC 7541 дёӯзҡ„дјӘд»Јз ҒпјҢviaпјүпјҡ
if I return I # I е°ҸдәҺ 2 ^ N - 1 ж—¶пјҢзӣҙжҺҘиҝ”еӣһelse M = 0
repeat
B = next octet # и®© B зӯүдәҺдёӢдёҖдёӘе…«дҪҚ I = I + (B & 127) * 2 ^ M # I = I + (B дҪҺдёғдҪҚ * 2 ^ M) M = M + 7
while B & 128 == 128 # B жңҖй«ҳдҪҚ = 1 时继з»ӯпјҢеҗҰеҲҷиҝ”еӣһ I return I еҜ№дәҺдёҠеӣҫдёӯзҡ„ж•°жҚ®пјҢжҢүз…§иҝҷдёӘ规еҲҷз®—еҮәзҙўеј•еҖјдёә 32пјҲ00011111 00010001пјҢ15 + 17пјүпјҢд»ЈиЎЁ cookieгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеҚҸи®®дёӯжүҖжңүеҶҷжҲҗпјҲN+пјүзҡ„ж•°еӯ—пјҢдҫӢеҰӮ Index (4+)гҖҒName Length (7+)пјҢйғҪйңҖиҰҒжҢүз…§иҝҷдёӘ规еҲҷжқҘзј–з Ғе’Ңи§Јз ҒгҖӮ
иҝҷз§Қж јејҸзҡ„еӨҙйғЁй”®еҖјеҜ№пјҢдёҚе…Ғи®ёиў«ж·»еҠ еҲ°еҠЁжҖҒеӯ—е…ёдёӯпјҲдҪҶеҸҜд»ҘдҪҝз”Ёе“ҲеӨ«жӣјзј–з ҒпјүгҖӮеҜ№дәҺдёҖдәӣйқһеёёж•Ҹж„ҹзҡ„еӨҙйғЁпјҢжҜ”еҰӮз”ЁжқҘи®ӨиҜҒзҡ„ CookieпјҢиҝҷд№ҲеҒҡеҸҜд»ҘжҸҗй«ҳе®үе…ЁжҖ§гҖӮ
5пјүеӨҙйғЁеҗҚз§°дёҚеңЁеӯ—е…ёдёӯпјҢдёҚе…Ғи®ёжӣҙж–°еҠЁжҖҒеӯ—е…ё
0 1 2 3 4 5 6 7
+---+---+---+---+---+---+---+---+
| 0 | 0 | 0 | 1 | 0 |
+---+---+-----------------------+
| H | Name Length (7+) |
+---+---------------------------+
| Name String (Length octets) |
+---+---------------------------+
| H | Value Length (7+) |
+---+---------------------------+
| Value String (Length octets) |
+-------------------------------+ иҝҷз§Қжғ…еҶөдёҺ第 3 з§Қжғ…еҶөйқһеёёзұ»дјјпјҢе”ҜдёҖдёҚеҗҢд№ӢеӨ„жҳҜпјҡ第дёҖдёӘеӯ—иҠӮеӣәе®ҡдёә 00010000гҖӮиҝҷз§Қжғ…еҶөжҜ”иҫғе°‘и§ҒпјҢжІЎжңүжҲӘеӣҫпјҢеҗ„дҪҚеҸҜд»Ҙи„‘иЎҘгҖӮеҗҢж ·пјҢиҝҷз§Қж јејҸзҡ„еӨҙйғЁй”®еҖјеҜ№пјҢд№ҹдёҚе…Ғи®ёиў«ж·»еҠ еҲ°еҠЁжҖҒеӯ—е…ёдёӯпјҢеҸӘиғҪдҪҝз”Ёе“ҲеӨ«жӣјзј–з ҒжқҘеҮҸе°‘дҪ“з§ҜгҖӮ
е®һйҷ…дёҠпјҢеҚҸи®®дёӯиҝҳ规е®ҡдәҶдёҺ 4гҖҒ5 йқһеёёзұ»дјјзҡ„еҸҰеӨ–дёӨз§Қж јејҸпјҡе°Ҷ 4гҖҒ5 ж јејҸдёӯзҡ„第дёҖдёӘеӯ—иҠӮ第еӣӣдҪҚз”ұ 1 ж”№дёә 0 еҚіеҸҜгҖӮе®ғиЎЁзӨәгҖҢжң¬ж¬ЎдёҚжӣҙж–°еҠЁжҖҒиҜҚе…ёгҖҚпјҢиҖҢ 4гҖҒ5 иЎЁзӨәгҖҢз»қеҜ№дёҚе…Ғи®ёжӣҙж–°еҠЁжҖҒиҜҚе…ёгҖҚгҖӮеҢәеҲ«дёҚжҳҜеҫҲеӨ§пјҢиҝҷйҮҢз•ҘиҝҮгҖӮ
жҳҺзҷҪдәҶеӨҙйғЁеҺӢзј©зҡ„жҠҖжңҜз»ҶиҠӮпјҢзҗҶи®әдёҠеҸҜд»ҘеҫҲиҪ»жқҫеҶҷеҮә HTTP/2 еӨҙйғЁи§Јз Ғе·Ҙе…·дәҶгҖӮжҲ‘жҜ”иҫғжҮ’пјҢзӣҙжҺҘжүҫжқҘ node-http2 дёӯзҡ„ compressor.js йӘҢиҜҒдёҖдёӢпјҡ
var Decompressor = require('./compressor').Decompressor;
var testLog = require('bunyan').createLogger({name: 'test'});
var decompressor = new Decompressor(testLog, 'REQUEST');
var buffer = new Buffer('820481634188353daded6ae43d3f877abdd07f66a281b0dae053fad0321aa49d13fda992a49685340c8a6adca7e28102e10fda9677b8d05707f6a62293a9d810020004015309ac2ca7f2c3415c1f53b0497ca589d34d1f43aeba0c41a4c7a98f33a69a3fdf9a68fa1d75d0620d263d4c79a68fbed00177febe58f9fbed00177b518b2d4b70ddf45abefb4005db901f1184ef034eff609cb60725034f48e1561c8469669f081678ae3eb3afba465f7cb234db9f4085aec1cd48ff86a8eb10649cbf', 'hex');
console.log(decompressor.decompress(buffer));
decompressor._table.forEach(function(row, index) {
console.log(index + 1, row[0], row[1]);
}); еӨҙйғЁеҺҹе§Ӣж•°жҚ®жқҘиҮӘдәҺжң¬ж–Ү第дёүеј жҲӘеӣҫпјҢиҝҗиЎҢз»“жһңеҰӮдёӢпјҲйқҷжҖҒеӯ—е…ёеҸӘжҲӘеҸ–дәҶдёҖйғЁеҲҶпјүпјҡ
{ ':method': 'GET',
':path': '/',
':authority': 'imququ.com',
':scheme': 'https',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:41.0) Gecko/20100101 Firefox/41.0',
accept: 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'accept-language': 'en-US,en;q=0.5',
'accept-encoding': 'gzip, deflate',
cookie: 'v=47; u=6f048d6e-adc4-4910-8e69-797c399ed456',
pragma: 'no-cache' }
1 ':authority' ''2 ':method' 'GET'3 ':method' 'POST'4 ':path' '/'5 ':path' '/index.html'6 ':scheme' 'http'7 ':scheme' 'https'8 ':status' '200'... ...
32 'cookie' ''... ...
60 'via' ''61 'www-authenticate' ''62 'pragma' 'no-cache'63 'cookie' 'u=6f048d6e-adc4-4910-8e69-797c399ed456'64 'accept-language' 'en-US,en;q=0.5'65 'accept' 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'66 'user-agent' 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:41.0) Gecko/20100101 Firefox/41.0'67 ':authority' 'imququ.com' еҸҜд»ҘзңӢеҲ°пјҢиҝҷж®өд»Һ Wireshark жӢ·еҮәжқҘзҡ„еӨҙйғЁж•°жҚ®еҸҜд»ҘжӯЈеёёи§Јз ҒпјҢеҠЁжҖҒеӯ—е…ёд№ҹеҫ—еҲ°дәҶжӣҙж–°пјҲ62 – 67пјүгҖӮ
жҖ»з»“
еңЁиҝӣиЎҢ HTTP/2 зҪ‘з«ҷжҖ§иғҪдјҳеҢ–ж—¶еҫҲйҮҚиҰҒдёҖзӮ№жҳҜгҖҢдҪҝз”Ёе°ҪеҸҜиғҪе°‘зҡ„иҝһжҺҘж•°гҖҚпјҢжң¬ж–ҮжҸҗеҲ°зҡ„еӨҙйғЁеҺӢзј©жҳҜе…¶дёӯдёҖдёӘеҫҲйҮҚиҰҒзҡ„еҺҹеӣ пјҡеҗҢдёҖдёӘиҝһжҺҘдёҠдә§з”ҹзҡ„иҜ·жұӮе’Ңе“Қеә”и¶ҠеӨҡпјҢеҠЁжҖҒеӯ—е…ёз§ҜзҙҜеҫ—и¶Ҡе…ЁпјҢеӨҙйғЁеҺӢзј©ж•Ҳжһңд№ҹе°ұи¶ҠеҘҪгҖӮжүҖд»ҘпјҢй’ҲеҜ№ HTTP/2 зҪ‘з«ҷпјҢжңҖдҪіе®һи·өжҳҜдёҚиҰҒеҗҲ并иө„жәҗпјҢдёҚиҰҒж•ЈеҲ—еҹҹеҗҚгҖӮ
й»ҳи®Өжғ…еҶөдёӢпјҢжөҸи§ҲеҷЁдјҡй’ҲеҜ№иҝҷдәӣжғ…еҶөдҪҝз”ЁеҗҢдёҖдёӘиҝһжҺҘпјҡ
еҗҢдёҖеҹҹеҗҚдёӢзҡ„иө„жәҗпјӣ дёҚеҗҢеҹҹеҗҚдёӢзҡ„иө„жәҗпјҢдҪҶжҳҜж»Ўи¶ідёӨдёӘжқЎд»¶пјҡ1пјүи§ЈжһҗеҲ°еҗҢдёҖдёӘ IPпјӣ2пјүдҪҝз”ЁеҗҢдёҖдёӘиҜҒд№Ұпјӣ дёҠйқўз¬¬дёҖзӮ№е®№жҳ“зҗҶи§ЈпјҢ第дәҢзӮ№еҲҷеҫҲе®№жҳ“иў«еҝҪз•ҘгҖӮе®һйҷ…дёҠ Google е·Із»Ҹиҝҷд№ҲеҒҡдәҶпјҢGoogle дёҖзі»еҲ—зҪ‘з«ҷйғҪе…ұз”ЁдәҶеҗҢдёҖдёӘиҜҒд№ҰпјҢеҸҜд»Ҙиҝҷж ·йӘҢиҜҒпјҡ
$ openssl s_client -connect google.com:443 |openssl x509 -noout -text | grep DNS
depth=2 C = US, O = GeoTrust Inc., CN = GeoTrust Global CA
verify error:num=20:unable to get local issuer certificate
verify return:0
DNS:*.google.com, DNS:*.android.com, DNS:*.appengine.google.com, DNS:*.cloud.google.com, DNS:*.google-analytics.com, DNS:*.google.ca, DNS:*.google.cl, DNS:*.google.co.in, DNS:*.google.co.jp, DNS:*.google.co.uk, DNS:*.google.com.ar, DNS:*.google.com.au, DNS:*.google.com.br, DNS:*.google.com.co, DNS:*.google.com.mx, DNS:*.google.com.tr, DNS:*.google.com.vn, DNS:*.google.de, DNS:*.google.es, DNS:*.google.fr, DNS:*.google.hu, DNS:*.google.it, DNS:*.google.nl, DNS:*.google.pl, DNS:*.google.pt, DNS:*.googleadapis.com, DNS:*.googleapis.cn, DNS:*.googlecommerce.com, DNS:*.googlevideo.com, DNS:*.gstatic.cn, DNS:*.gstatic.com, DNS:*.gvt1.com, DNS:*.gvt2.com, DNS:*.metric.gstatic.com, DNS:*.urchin.com, DNS:*.url.google.com, DNS:*.youtube-nocookie.com, DNS:*.youtube.com, DNS:*.youtubeeducation.com, DNS:*.ytimg.com, DNS:android.com, DNS:g.co, DNS:goo.gl, DNS:google-analytics.com, DNS:google.com, DNS:googlecommerce.com, DNS:urchin.com, DNS:youtu.be, DNS:youtube.com, DNS:youtubeeducation.com дҪҝз”ЁеӨҡеҹҹеҗҚеҠ дёҠзӣёеҗҢзҡ„ IP е’ҢиҜҒд№ҰйғЁзҪІ Web жңҚеҠЎжңүзү№ж®Ҡзҡ„ж„Ҹд№үпјҡи®©ж”ҜжҢҒ HTTP/2 зҡ„з»Ҳз«ҜеҸӘе»әз«ӢдёҖдёӘиҝһжҺҘпјҢз”ЁдёҠ HTTP/2 еҚҸи®®еёҰжқҘзҡ„еҗ„з§ҚеҘҪеӨ„пјӣиҖҢеҸӘж”ҜжҢҒ HTTP/1.1 зҡ„з»Ҳз«ҜеҲҷдјҡе»әз«ӢеӨҡдёӘиҝһжҺҘпјҢиҫҫеҲ°еҗҢж—¶жӣҙеӨҡ并еҸ‘иҜ·жұӮзҡ„зӣ®зҡ„гҖӮиҝҷеңЁ HTTP/2 е®Ңе…Ёжҷ®еҸҠеүҚд№ҹжҳҜдёҖдёӘдёҚй”ҷзҡ„йҖүжӢ©гҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒе…ідәҺвҖңHTTP/2еҰӮдҪ•е®һзҺ°еӨҙйғЁеҺӢзј©вҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢи®©еӨ§е®¶еҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°еҗ§пјҒ




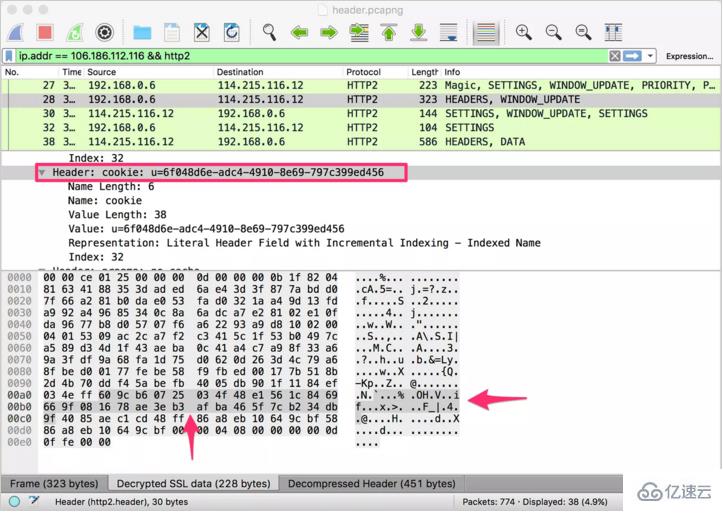
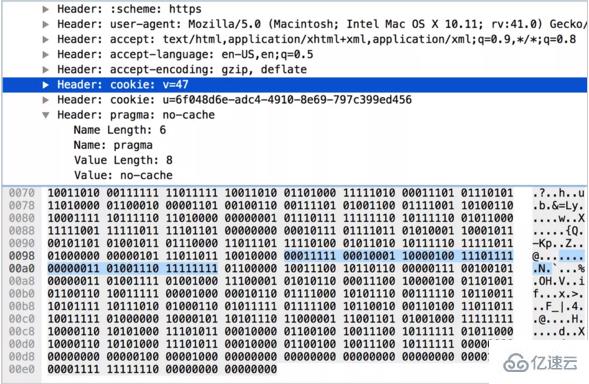
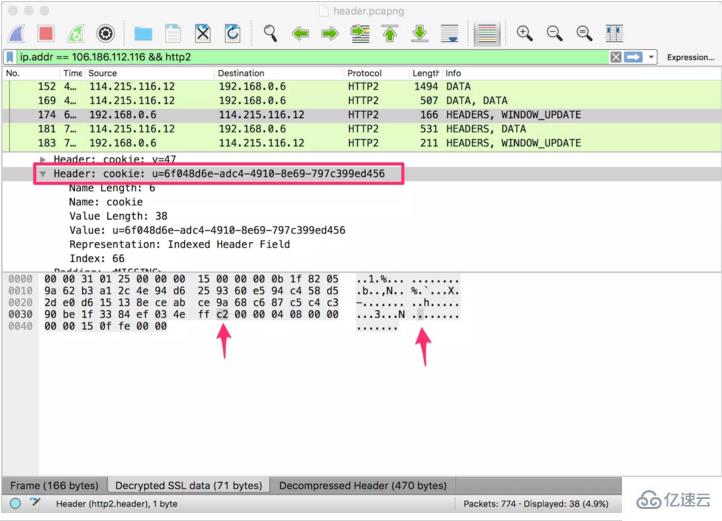 еҜ№жҜ”еҗҺеҸҜд»ҘеҸ‘зҺ°пјҢ第дәҢж¬Ўзҡ„иҜ·жұӮеӨҙйғЁд№ӢжүҖд»Ҙйқһеёёе°ҸпјҢжҳҜеӣ дёәеӨ§йғЁеҲҶй”®еҖјеҜ№еҸӘеҚ з”ЁдәҶдёҖдёӘеӯ—иҠӮгҖӮе°Өе…¶жҳҜ UserAgentгҖҒCookie иҝҷж ·зҡ„еӨҙйғЁпјҢйҰ–ж¬ЎиҜ·жұӮдёӯйңҖиҰҒеҚ з”ЁеҫҲеӨҡеӯ—иҠӮпјҢеҗҺз»ӯиҜ·жұӮдёӯйғҪеҸӘйңҖиҰҒдёҖдёӘеӯ—иҠӮгҖӮ
еҜ№жҜ”еҗҺеҸҜд»ҘеҸ‘зҺ°пјҢ第дәҢж¬Ўзҡ„иҜ·жұӮеӨҙйғЁд№ӢжүҖд»Ҙйқһеёёе°ҸпјҢжҳҜеӣ дёәеӨ§йғЁеҲҶй”®еҖјеҜ№еҸӘеҚ з”ЁдәҶдёҖдёӘеӯ—иҠӮгҖӮе°Өе…¶жҳҜ UserAgentгҖҒCookie иҝҷж ·зҡ„еӨҙйғЁпјҢйҰ–ж¬ЎиҜ·жұӮдёӯйңҖиҰҒеҚ з”ЁеҫҲеӨҡеӯ—иҠӮпјҢеҗҺз»ӯиҜ·жұӮдёӯйғҪеҸӘйңҖиҰҒдёҖдёӘеӯ—иҠӮгҖӮ