这篇文章跟大家分析一下“Linux系统怎样搭建hadoop集群”。内容详细易懂,对“Linux系统怎样搭建hadoop集群”感兴趣的朋友可以跟着小编的思路慢慢深入来阅读一下,希望阅读后能够对大家有所帮助。下面跟着小编一起深入学习“Linux系统怎样搭建hadoop集群”的知识吧。
Hadoop,是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。
简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。该平台使用的是面向对象编程语言Java实现的,具有良好的可移植性。
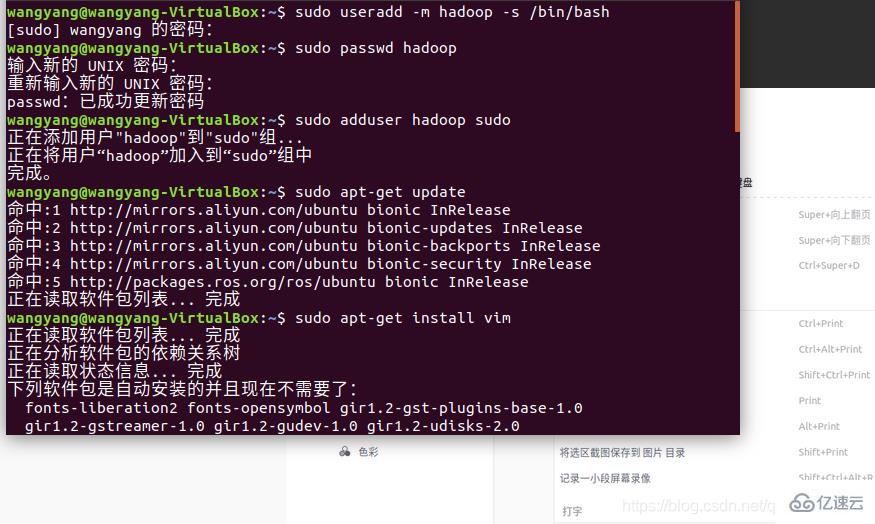
但是在刚开始就遇到了问题:由于我们下载的Hadoop和jdk在Windows下下载的,将文件共享进ubuntu时,只能共享到第一个创建的用户(我也不知道为什么),而且ubuntu下网络很慢,所以,我就没有创建新的用户,在原有的用户上进行的安装(后面运行成功证实是可以的)。
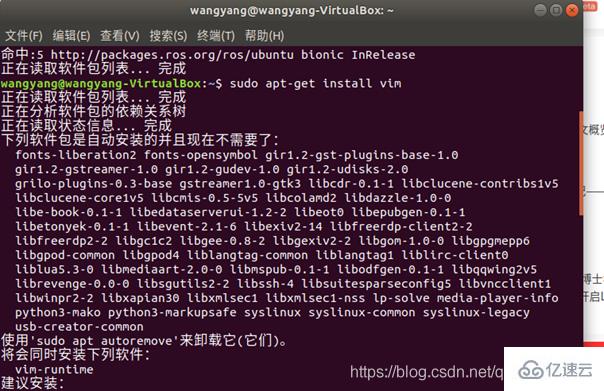
3.安装SSH、配置SSH无密码登陆:(提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了)
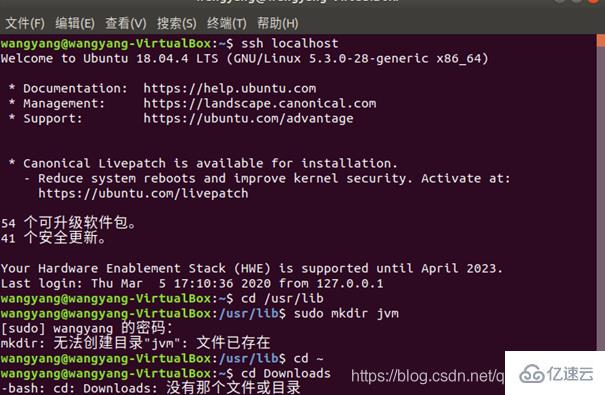
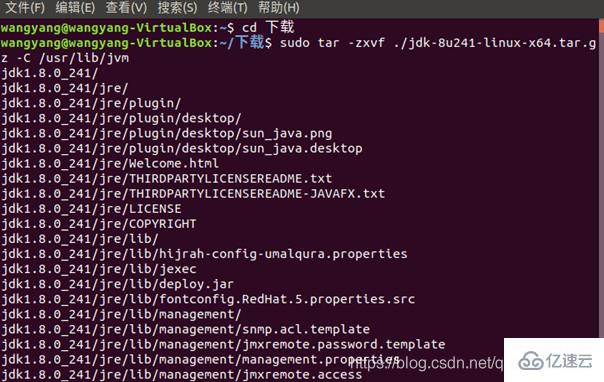
解压过程:
JDK文件解压缩以后,可以执行如下命令到/usr/lib/jvm目录查看一下:
继续执行如下命令,设置环境变量:

下面命令使用vim编辑器打开了hadoop这个用户的环境变量配置文件,在这个文件的开头位置,添加如下几行内容(注意自己的jdk 版本号):
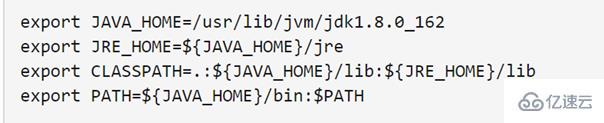
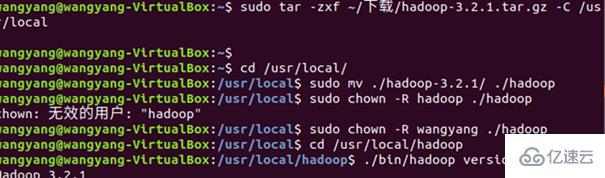
总体的命令:

运行例子:
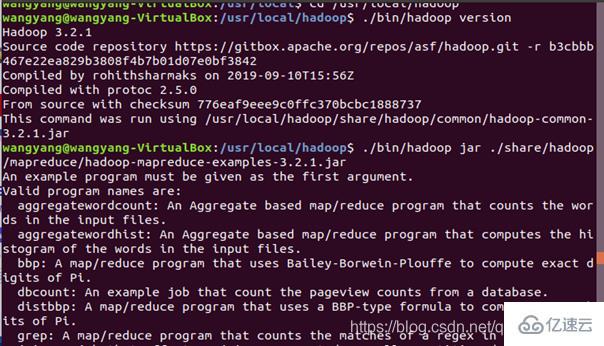
在此我们选择运行 grep 例子,我们将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中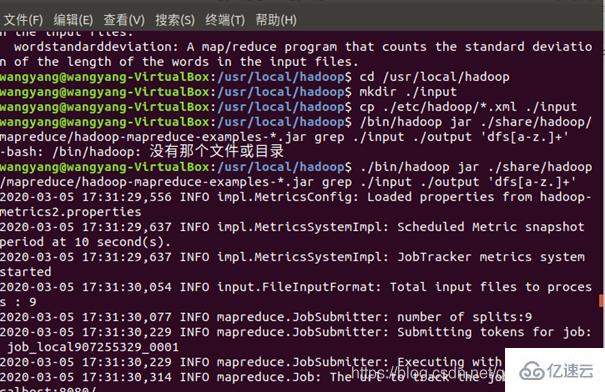
最后的结果与教程相符合:
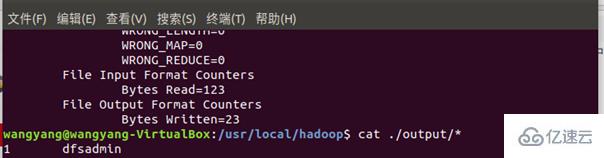
将 ./output 删除
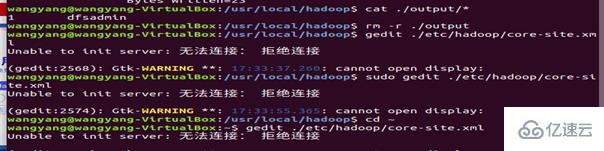
修改配置文件 core-site.xml (通过 gedit 编辑会比较方便: gedit ./etc/hadoop/core-site.xml),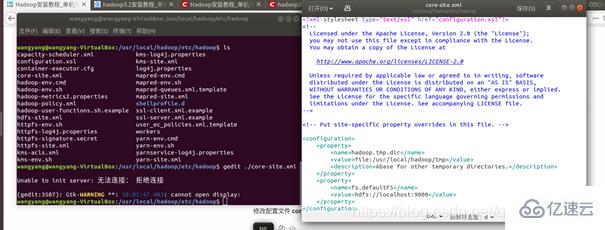
修改为:
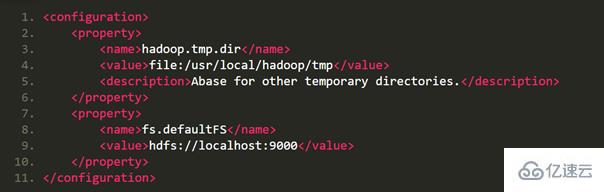
同样的,修改配置文件 hdfs-site.xml:
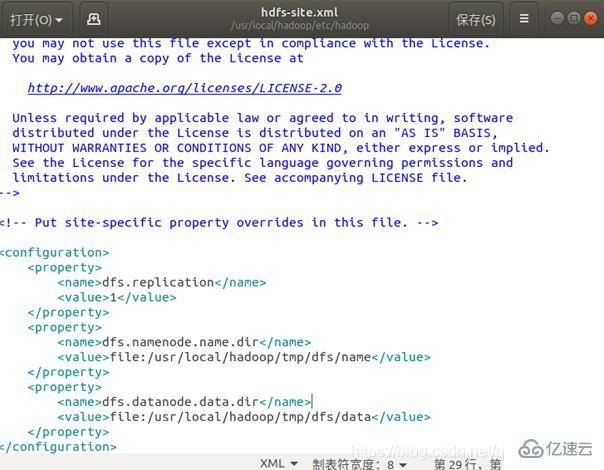
配置完成后,执行 NameNode 的格式化:
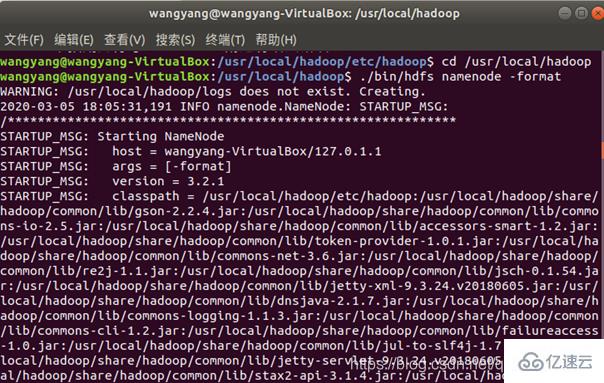
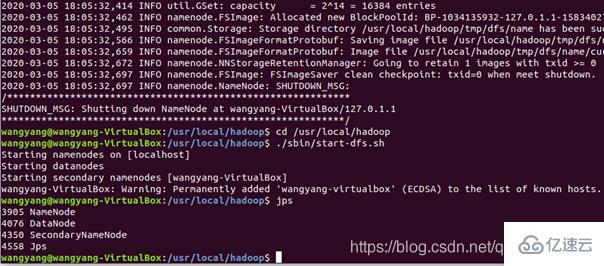
开启 NameNode 和 DataNode 守护进程:
还好没有教程中的错误:

网页面中打开9870端口:
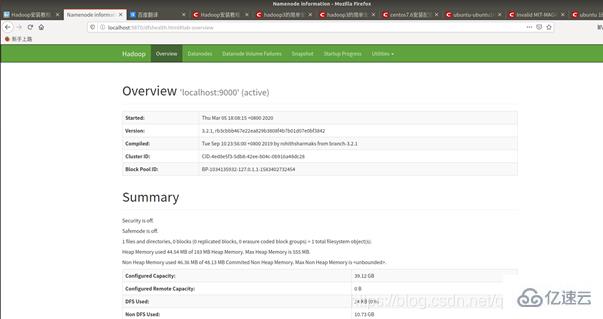
到这里表明已经成功!
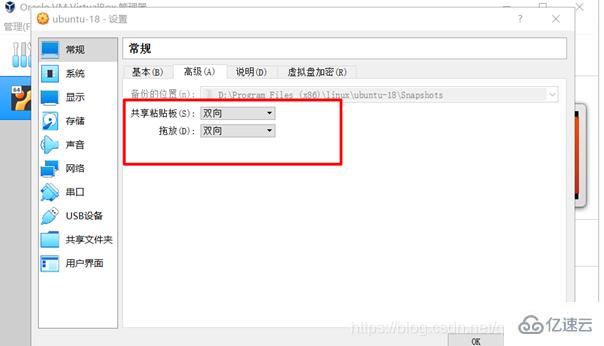
问题一:Ubuntu和Windows之间的文件传输,拖拽,共享粘贴板。解决办法:安装VBox的增强功能,以及设置如下的地方(自行百度):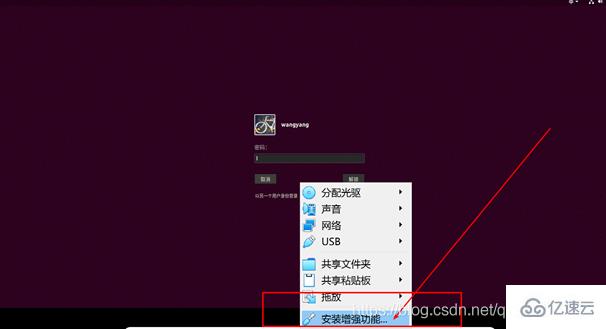
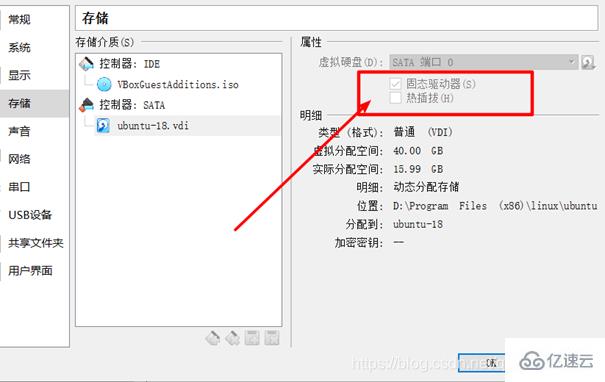
问题二:新用户下,不能拖拽文件(就算是管理员也不行)没有解决,因此没有在新用户hadoop下安装,但是最后仍然是成功的
关于Linux系统怎样搭建hadoop集群就分享到这里啦,希望上述内容能够让大家有所提升。如果想要学习更多知识,请大家多多留意小编的更新。谢谢大家关注一下亿速云网站!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





