这篇文章主要介绍了Linux的grep,sed,awk命令怎么用的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇Linux的grep,sed,awk命令怎么用文章都会有所收获,下面我们一起来看看吧。
正则表达式:REGular EXPression, REGEXP 元字符: .: 匹配任意单个字符 []: 匹配指定范围内的任意单个字符 [^]:匹配指定范围外的任意单个字符 字符集合:[:digit:], [:lower:], [:upper:], [:punct:], [:space:], [:alpha:], [:alnum:] 注意:字符集合要用[ ]包含 匹配次数(贪婪模式): *: 匹配其前面的字符任意次 a, b, ab, aab, acb, adb, amnb a*b, a?b a.*b .*: 任意长度的任意字符 \?: 匹配其前面的字符1次或0次 \+:匹配至少一次 \{m,n\}:匹配其前面的字符至少m次,至多n次 \{1,\} \{0,3\} 备注:至少0次,必须要显示的写出来。 位置锚定: ^: 锚定行首,此字符后面的任意内容必须出现在行首 $: 锚定行尾,此字符前面的任意内容必须出现在行尾 ^$: 空白行 \
\>或\b: 锚定词尾,其前面的任意字符必须作为单词的尾部出现 分组: \(\) \(ab\)* 后向引用 \1: 引用第一个左括号以及与之对应的右括号所包括的所有内容 \2: \3:可以看到标准正则表达的使用过程中,许多符号都需要转义,这在工作中带来了一定的不便,因此扩展的正则表达式便出现了。
1. 字符匹配: . [abc]:包含abc任意一个字符 [^abc]:不包含abc任意一个字符 2. 次数匹配(不用再转义): *: ?: +: 匹配其前面的字符至少1次 {m,n} 3. 位置锚定: ^ $ \
\> 4. 分组(不用再转义): ():分组 \1, \2, \3, ... 5. 或者 |: or C|cat: C或cat(表示的是整个部分)可以看到,使用扩展的正则表达式可以省略很多的转义符号,这尤其在写sed语句时极大的提高了代码的可读性。建议优先使用扩展的正则表达式。
grep命令家族由grep, egrep, fgrep 三个子命令组成,适用于不同的场景。具体如下: 命令 描述 grep 原生的grep命令,使用“标准正则表达式”作为匹配标准。 egrep 扩展的grep命令,相当于$(grep -E),使用“扩展正则表达式”作为匹配标准。 fgrep 简化版的grep命令,不支持正则表达式,但搜索速度快,系统资源使用率低。
语法 grep [options] PATTERN [FILE…] options部分 -i:忽略大小写 –color:高亮匹配上的字符串 -v: 显示没有被模式匹配到的行 -o:只显示被模式匹配到的字符串 -E:使用扩展的正则表达式 PATTERN部分 以字符串的方式给定匹配模板,可以使用普通字符串以及正则表达式(标准&扩展)。 FILE部分 需要查找内容的文件。
sed全称是Stream EDitor sed是一个流编辑器、行编辑器
sed [option] ‘script’ [input file]… option部分 -n:不输出模式空间中的内容到stdout -e:可以在sed命令中指定多个script脚本,多点编辑功能 -f:输入sed脚本,脚本中写着编辑命令 -r:支持使用扩展的正则 -i:直接编辑源文件
script部分 地址定界编辑命令(和vim命令相似) 1)空地址:全文编辑 2)单地址:   #:指定某一行,对特定行进行编辑   /pattern/:指定模式匹配到的那一行 3)地址范围:   #,#   #,+#   #,/pattern/   /pattern1/,/pattern2/ 4)步进地址:   1~2:以1为起始行,然后递进2行向下匹配   2~2:所有偶数行 5)编辑命令:   d:删除整行,d放在最后   p:显示模式空间中的内容, 放在最后   a:在匹配的行后面增加文本,使用\n支持多行追加。a放在定界后面   i:在前面加文本。举例:sed ‘3i hello’ xxx   c:替换行为指定的文本。举例:sed ‘3c text’ xxx 把第三行替换成text。sed -i ‘/xyz/c helloworld’ num.txt   w:保存模式空间中匹配的内容到指定位置。举例:sed -n ‘/[#]/w /tmp/demo’ /etc/fstab 将/etc/fstab中非#开头的行保存到/tmp/demo中。   r:读取指定文件的内容添加到当前文件匹配到的行后面,进行文件合并。   !:条件取反。用法:地址定界!编辑命令。   s///:条件替换。 替换标记备注:g(全局替换),p(显示替换成功的行)
替换举例:根据输入查找目录 echo “/var/log/messages” | sed ‘s@/+$/?@@’
模式空间与保持空间 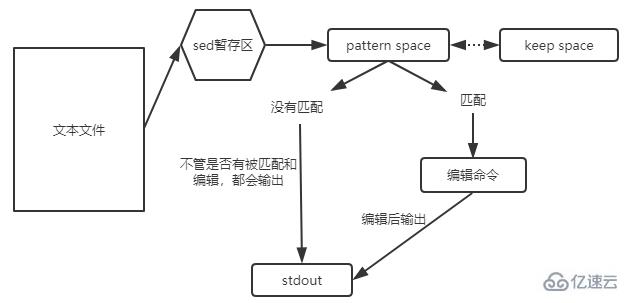
在模式空间中,完成匹配的操作。当没有匹配上的时候,文本行内容会默认输出stdout;当匹配上文本行的时候,会执行编辑命令,执行结果输出到stdout中。 保持空间可以理解为一个暂存区,只是用于完成额外的动作。
参数 h:把模式空间中的内容覆盖至保持空间中; H:把模式空间中的内容追加至保持空间中; g:把保持空间中的内容覆盖至模式空间中; G:把保持空间中的内容追加至模式空间中; x:把模式空间中的内容与保持空间中的内容互换; n:覆盖读取匹配到的行的下一行(改变指向)至模式空间中; N:追加读取匹配到的行的下一行(改变指向)至模式空间中; d:删除模式空间中的行; D:删除多行模式空间中的所有行;
3. 举例 sed -n 'n;p' FILE:显示偶数行; sed '1!G;h;$!d' FILE:逆序显示文件的内容; sed '$!d' FILE:取出最后一行; sed '\$!N;$!D' FILE:取出文件后两行; sed '/^$/d;G' FILE:删除原有的所有空白行,而后为所有的非空白行后添加一个空白行; sed 'n;d' FILE:显示奇数行; sed 'G' FILE:在原有的每行后方添加一个空白行;举例:提取字符串
/bin/bash info="hellozimskyshenzhen" echo $info | sed 's/hello\(\w\+\)shenzhen/\1/g'备注:
sed中不支持\d,如果要用数字用[0-9],但是支持\w。
sed中的()要转义,+要转义,大于小于号要转义。
举例:判断是否存在指定格式的字符串
#!/bin/bash # 判断输入是否为整数 if [ -n "$(echo $1 | sed -n '/^[0-9]\+$/p')" ] ; then echo 'yes' else echo 'no' fiawk是发明该工具三个作者姓名的首字母简称,awk是一个报表生成器,主要用于格式化输出。格式化文本输出器。
1. 语法 gawk [option] ‘program’ FILE 其中program: PATTERN{ACTION STATEMENTS} {动作指令}可以理解成为命令,最常用的是print、printf
2. awk读取文档过程 按照行来读取文档,根据输入分隔符切分成小部分(用內建变量来表示1,用来处理。0表示显示整行。
3. 选项option -F:指名输入字段的分隔符; -v:用来实现自定义变量var=value;
4. PATTERN(用于定界)  空:表示处理文件的每一行  /pattern/:使用正则匹配需要处理的行  !/pattern/:上面取反  关系表达式:结果为真假,结果为真的处理,假的不处理。非0非空字符串为真,其余为假。  行定界:不支持直接给出数字的格式(1,2{…})。见举例。  BEGIN/END模式:BEGIN{}表示仅在开始处理文件中的文本之前执行一次的程序,例如打印表头。END{}表示文本处理完成之后执行一次,例如汇总数据。
举例: awk -F: '$NF=="/bin/bash" {print $1, $NF}' /etc/passwd awk -F: '$NF!"/bash/$"{print $1,$NF}' passwd awk -F: '$3
awk -F; '(NR>=2&&NR
awk -F: '{printf "%-15s %10s\n", $1, $2}' /etc/passwd5. 变量
內建变量(在引用变量时不用加::输入字段分隔符,默认空白字符。使用指定。:输出字段分隔符。使用指定。:输入时的换行符:输出时的换行符:每一行的字段数量。加上NF表示最后一列。 NR:number of record 文件的行数,打印出来是打印行号 FNR:多个文件中的行数分别计数 FILENAME:当前文件的文件名 ARGC:参数命令行中参数的个数 ARGV**:返回数组,命令行中的每个参数 举例:awk ‘BEGIN {print ARGV[0]}’ /etc/fstab /etc/issue 在这里ARGV[0]是awk,固定为第0个参数。ARGV[1]是/etc/fstab,ARGV[2]是/etc/issue 举例:awk -v FS=’:’ ‘{print $1}’ -v OFS=’:’ /etc/passwd 指名冒号作为输入的分隔符。同awk -F: …
自定义变量 方法1:-v var=value (区分字符的大小写) 方法2:在program中定义
举例:awk -v test=’hello’ ‘BEGIN {print test}’ awk ‘BEGIN {test=’hello’ print test}’
6. 常用的ACTION命令
print 输出格式:print item1,item2 … 备注:使用逗号作为分隔符;输出item可以是字符串、內建变量、awk表达式;若省略item,则显示$0整行;
printf 格式化输出:printf FORMAT, item1, item2…按位放在format中。 注意事项:format必须要给出;如需换行,必须要显示写出;format中需要为后面每个item指定格式符;
Expressions
Control statements:控制语句if,while if(condition){statement} if(condition){statement} else {statements} while(condition) {statements} do {statements} while(condition) for(expr1;expr2;expr3) {statements} break continue delete array[index] delete array删除整个数组 exit 退出语句
Compound statements:组合语句
Input statements:输入语句
Output statements:输出语句 格式符:  %c:显示字符的ASCII值  %d:显示十进制整数  %e:科学计数法数值显示  %f:显示为浮点数  %g:以科学计数法显示浮点数  %s:显示字符串  %u:显示无符号整数  %%:显示%自身 修饰符:  #[.#]:第一个数字用于控制显示字符的宽度,第二个数字表示小数的精度(对于浮点数而言);输出默认右对齐%15s,左对齐:%-15s;+:表示带正负符号; 操作符:  算数操作符:+-/* ; +x把字符串转换成数值;-x改成负数;  字符串操作符:字符串连接(没有操作符)  复制操作符:=,+=,-=,/=,++,–  比较操作符:>, 模式匹配符:  ~:左侧的字符串是否被模式匹配  !~:左侧的字符串是否不能被模式匹配 逻辑操作符:  &&:与  ||:或  !:非 函数调用:  function_name(arg1, arg2, …) 条件表达式:  selector?true_exp:false_exp 和三目运算符一样
操作例子
# 一般来说, 打印无状态内容放在BEGIN和END块中 awk -v begin="hello" -v end="ok" -F: 'BEGIN{print begin}; {print $1, $NF}; END{print end}' /etc/passwdawk常用内置变量
$1:表示第一列 $NF:表示最后一列 $NR:表示行号常用条件表示
1) /指定内容/
这种方式可以匹配到含有“指定内容”的行,在条件中不添加$#所带的项,建议不使用正则,有异常情况。
awk -F: '/nologin/{print $0}' /etc/passwd #匹配到含有nologin关键字的行 seq 100 | awk '/1/{print $1}'2) $#=/指定内容/
这种方式指定第#列匹配指定内容
awk -F: '$1=/bin/{print $0}' /etc/passwd3) $#~/指定内容/
这种方式用于指定列模糊匹配(正则匹配)指定内容,并获取该行。
awk -F: '$1~/dae/{print $1}' /etc/passwd #正向选择 awk -F: '$1!~/dae/{print $1}' /etc/passwd #反向选择4) 值判断
使用>,=,
awk -F: '$3>=10{print $1}' /etc/passwd5) 逻辑判断
使用&&,||来进行逻辑判断。
awk -F: '$3>=5 && $36) if条件判断
awk -F: '{if ($NF~/nologin$/){i++}else{j++}}; END{print i, j}' /etc/passwd #注意if-else条件判断是放在{}中的7) 字典使用
在awk中可以定义数组类型,用于统计。
awk '{ip[$1]++}; END{for (i in ip) {print i, ip[i]}}' access.log #解析: 将第一列ip设置为字典的key,当出现一次相同的ip时自增1,用于统计所有的ip计数。 #for循环中取到每个字典对应的key,再使用print块打印出来。注意花括号的隔离。 #QQ号 等级 时长 #统计等级(30
#1234 12 23 #1234 10 122 #1233 92 4212 #1233 42 4252 #1239 87 2313 #1233 56 1121 #1231 19 45 #1235 45 679 cat data | awk '$2>=30&&$2关于“Linux的grep,sed,awk命令怎么用”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“Linux的grep,sed,awk命令怎么用”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



