这篇文章给大家分享的是有关Python爬虫中urllib库怎么用的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
urllib库是python内置的一个http请求库,requests库就是基于该库开发出来的,虽然requests库使用更方便,但作为最最基本的请求库,了解一下原理和用法还是很有必要的。
urllib.request
请求模块(就像在浏览器输入网址,敲回车一样)
urllib.error
异常处理模块(出现请求错误,可以捕捉这些异常)
urllib.parse
url解析模块
urllib.robotparser
robots.txt解析模块,判断哪个网站可以爬,哪个不可以爬,用的比较少
在python2与python3中有所不同
在python2中:
import urllib2
response = urllib2.urlopen('http://www.baidu.com')在python3中:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')urllib.request.urlopen(url, data=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT,*, cafile=None, capath=None, cadefault=False, context=None)
url参数
from urllib import request
response = request.urlopen('http://www.baidu.com')
print(response.read().decode('utf-8'))data参数
没有data参数时,发送的是一个get请求,加上data参数后,请求就变成了post方式(利用’http://httpbin.org测试网址)
import urllib.request
import urllib.parse
data1= bytes(urllib.parse.urlencode({'word':'hello'}),encoding='utf-8')
response = urllib.request.urlopen('http://httpbin.org/post',data = data1)
print(response.read())data参数需要bytes类型,所以需要使用bytes()函数进行编码,而bytes函数的第一个参数需要时str类型,所以使用urllib.parse.urlencode将字典转化为字符串。
timeout参数
设置一个超时的时间,如果在这个时间内没有响应,便会抛出异常
import urllib.request
try:
response = urllib.request.urlopen('http://www.baidu.com', timeout=0.001)
print(response.read())
except:
print('error') 将超时时间设置为0.001秒,在这个时间内,没有响应,输出error
import urllib
from urllib import request
response = urllib.request.urlopen('http://www.baidu.com')
print(type(response))状态码与响应头
import urllib
from urllib import request
response = urllib.request.urlopen('http://www.baidu.com')
print(response.status)
print(response.getheaders())
print(response.getheader('Server'))read方法
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
print(type(response.read()))
print(response.read().decode('utf-8'))response.read()返回的是bytes形式的数据,所以需要用decode(‘utf-8’)进行解码。
如果我们需要发送复杂的请求,在urllib库中就需要使用一个Request对象
import urllib.request
#直接声明一个Request对象,并把url当作参数直接传递进来
request = urllib.request.Request('http://www.baidu.com')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))声明了一个Request对象,把url当作参数传递给这个对象,然后把这个对昂作为urlopen函数的参数
更复杂的请求,加headers
#利用Request对象实现一个post请求
import urllib.request
url = 'http://httpbin.org/post'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
data = {'word':'hello'}
data = bytes(str(data),encoding='utf-8')
req = urllib.request.Request(url = url,data = data,headers = headers,method = 'POST')
response = urllib.request.urlopen(req)
print(response.read().decode('utf-8'))上面的这个请求包含了请求方式、url,请求头,请求体,逻辑清晰。
Request对象还有一个add_header方法,这样也可以添加多个键值对的header
设置代理
很多网站会检测某一段时间某个IP的访问次数(通过流量统计,系统日志等),如果访问次数多的不像正常人,它会禁止这个IP的访问。ProxyHandler(设置代理的handler),可以变换自己的IP地址。
from urllib import request # 导入request模块
url = 'http://httpbin.org' # url地址
handler = request.ProxyHandler({'http': '122.193.244.243:9999'}) # 使用request模块ProxyHandler类创建代理
#handler = request.ProxyHandler({"http":"账号:密码@'122.193.244.243:9999'"})
#付费代理模式
opener = request.build_opener(handler) # 用handler创建opener
resp = opener.open(url) # 使用opener.open()发送请求
print(resp.read()) # 打印返回结果cookie
import urllib.request
import urllib.parse
url = 'https://weibo.cn/5273088553/info'
# 正常的方式进行访问
# headers = {
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36'
# }
#携带cookie进行访问
headers = {
'GET https': '//weibo.cn/5273088553/info HTTP/1.1',
'Host': ' weibo.cn',
'Connection': ' keep-alive',
'Upgrade-Insecure-Requests': ' 1',
'User-Agent': ' Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
'Accept': ' text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
# 'Referer: https':'//weibo.cn/',
'Accept-Language': ' zh-CN,zh;q=0.9',
'Cookie': ' _T_WM=c1913301844388de10cba9d0bb7bbf1e; SUB=_2A253Wy_dDeRhGeNM7FER-CbJzj-IHXVUp7GVrDV6PUJbkdANLXPdkW1NSesPJZ6v1GA5MyW2HEUb9ytQW3NYy19U; SUHB=0bt8SpepeGz439; SCF=Aua-HpSw5-z78-02NmUv8CTwXZCMN4XJ91qYSHkDXH4W9W0fCBpEI6Hy5E6vObeDqTXtfqobcD2D32r0O_5jSRk.; SSOLoginState=1516199821',
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
# 输出所有
# print(response.read().decode('gbk'))
# 将内容写入文件中
with open('weibo.html', 'wb') as fp:
fp.write(response.read())可以捕获三种异常:URLError,HTTPError(是URLError类的一个子类),ContentTooShortError
URLError只有一个reason属性
HTTPError有三个属性:code,reason,headers
import urllib.request
from urllib import error
try:
response = urllib.request.urlopen('http://123.com')
except error.URLError as e:
print(e.reason)import urllib
from urllib import request
from urllib import error
#先捕捉http异常,再捕捉url异常
try:
response = urllib.request.urlopen('http://123.com')
except error.HTTPError as e:
print(e.reason, e.code, e.headers)
except error.URLError as e:
print(e.reason)
else:
print('RequestSucess!')urlparse函数
该函数是对传入的url进行分割,分割成几部分,并对每部分进行赋值
import urllib
from urllib import parse
result = urllib.parse.urlparse('http://www,baidu.com/index.html;user?id=5#comment')
print(type(result))
print(result)结果方便的拆分了url
<class 'urllib.parse.ParseResult'> ParseResult(scheme='http', netloc='www,baidu.com', path='/index.html', params='user', query='id=5', fragment='comment') Process finished with exit code 0
从输出结果可以看出,这几部分包括:协议类型、域名、路径、参数、query、fragment
urlparse有几个参数:url,scheme,allow_fragments
在使用urlparse时,可以通过参数scheme = 'http’的方式来指定默认的协议类型,如果url有协议类型,scheme参数就不会生效了
urlunparse函数
与urlparse函数作用相反,是对url进行拼接的

urljoin函数
用来拼接url

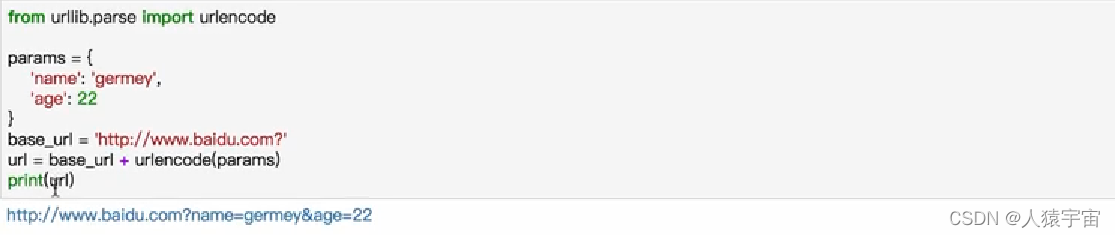
urlencode函数
可以把一个字典转化为get请求参数
感谢各位的阅读!关于“Python爬虫中urllib库怎么用”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





