这篇文章主要介绍如何使用Python爬虫实现抓取电影网站信息并入库,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
访问 Python官网下载地址:https://www.python.org/downloads/
下载适合自己系统的安装包:

我用的是 Windows 环境,所以直接下的 exe 包进行安装。
下载后,双击下载包,进入 Python 安装向导,安装非常简单,你只需要使用默认的设置一直点击"下一步"直到安装完成即可。

右键点击"计算机",点击"属性";
然后点击"高级系统设置"-“环境变量”;
选择"系统变量"窗口下面的 “Path” ,添加 python 安装路径;
设置成功以后,在cmd命令行,输入命令"python",有显示则说明配置成功。
我们的爬取程序需要安装的依赖模块包括 requests,lxml,pymysql ,步骤如下:
进入python安装目录下的Scripts目录,点击地址栏输入“cmd” 打开命令行工具:
在这个路径下安装对应的 requests,lxml,pymysql 依赖:

需要输入的命令:
// 安装requests依赖
pip install requests
// 安装lxml依赖
pip install lxml
// 安装pymysql依赖
pip install pymysql开发 collectMovies.py
#!/user/bin env python
# 获取电影天堂详细信息
import requests
import time
from lxml import etree
import pymysql
requests.adapters.DEFAULT_RETRIES = 5
# 伪装浏览器
HEADERS ={
'User-Agent':'Mozilla/5.(Windows NT 10.0; WOW64) AppleWebKit/537.3(KHTML, like Gecko) Chrome/63.0.3239.13Safari/537.36',
'Host':'www.dy2018.com'
}
# 定义全局变量
BASE_DOMAIN = 'https://www.dy2018.com/'
# 获取首页网页信息并解析
def getUrlText(url,coding):
s = requests.session()
#print("获取首页网页信息并解析:", url)
respons = s.get(url,headers=HEADERS)
print("请求URL:", url)
if(coding=='c'):
urlText = respons.content.decode('gbk')
html = etree.HTML(urlText) # 使用lxml解析网页
else:
urlText = respons.text
html = etree.HTML(urlText) # 使用lxml解析网页
s.keep_alive = False
return html
# 获取电影详情页的href,text解析
def getHref(url):
html = getUrlText(url,'t')
aHref = html.xpath('//table[@class="tbspan"]//a/@href')
print("获取电影详情页的href,text解析```")
htmlAll = map(lambda url:BASE_DOMAIN+url,aHref) # 给每个href补充BASE_DOMAIN
return htmlAll
# 使用content解析电影详情页,并获取详细信息数据
def getPage(url):
html = getUrlText(url,'c')
moveInfo = {} # 定义电影信息
mName = html.xpath('//div[@class="title_all"]//h2/text()')[0]
moveInfo['movie_name'] = mName
mDiv = html.xpath('//div[@id="Zoom"]')[0]
mImgSrc = mDiv.xpath('.//img/@src')
moveInfo['image_path'] = mImgSrc[0] # 获取海报src地址
if len(mImgSrc) >= 2:
moveInfo['screenshot'] = mImgSrc[1] # 获取电影截图src地址
mContnent = mDiv.xpath('.//text()')
def pares_info(info,rule):
'''
:param info: 字符串
:param rule: 替换字串
:return: 指定字符串替换为空,并剔除左右空格
'''
return info.replace(rule,'').strip()
for index,t in enumerate(mContnent):
if t.startswith('◎译 名'):
name = pares_info(t,'◎译 名')
moveInfo['translation']=name
elif t.startswith('◎片 名'):
name = pares_info(t,'◎片 名')
moveInfo['movie_title']=name
elif t.startswith('◎年 代'):
name = pares_info(t,'◎年 代')
moveInfo['movie_age']=name
elif t.startswith('◎产 地'):
name = pares_info(t,'◎产 地')
moveInfo['movie_place']=name
elif t.startswith('◎类 别'):
name = pares_info(t,'◎类 别')
moveInfo['category']=name
elif t.startswith('◎语 言'):
name = pares_info(t,'◎语 言')
moveInfo['language']=name
elif t.startswith('◎字 幕'):
name = pares_info(t,'◎字 幕')
moveInfo['subtitle']=name
elif t.startswith('◎上映日期'):
name = pares_info(t,'◎上映日期')
moveInfo['release_date']=name
elif t.startswith('◎豆瓣评分'):
name = pares_info(t,'◎豆瓣评分')
moveInfo['douban_score']=name
elif t.startswith('◎片 长'):
name = pares_info(t,'◎片 长')
moveInfo['file_length']=name
elif t.startswith('◎导 演'):
name = pares_info(t,'◎导 演')
moveInfo['director']=name
elif t.startswith('◎编 剧'):
name = pares_info(t, '◎编 剧')
writers = [name]
for i in range(index + 1, len(mContnent)):
writer = mContnent[i].strip()
if writer.startswith('◎'):
break
writers.append(writer)
moveInfo['screenwriter'] = writers
elif t.startswith('◎主 演'):
name = pares_info(t, '◎主 演')
actors = [name]
for i in range(index+1,len(mContnent)):
actor = mContnent[i].strip()
if actor.startswith('◎'):
break
actors.append(actor)
moveInfo['stars'] = " ".join(actors)
elif t.startswith('◎标 签'):
name = pares_info(t,'◎标 签')
moveInfo['tags']=name
elif t.startswith('◎简 介'):
name = pares_info(t,'◎简 介')
profiles = []
for i in range(index + 1, len(mContnent)):
profile = mContnent[i].strip()
if profile.startswith('◎获奖情况') or '【下载地址】' in profile:
break
profiles.append(profile)
moveInfo['introduction']=" ".join(profiles)
elif t.startswith('◎获奖情况'):
name = pares_info(t,'◎获奖情况')
awards = []
for i in range(index + 1, len(mContnent)):
award = mContnent[i].strip()
if '【下载地址】' in award:
break
awards.append(award)
moveInfo['awards']=" ".join(awards)
moveInfo['movie_url'] = url
return moveInfo
# 获取前n页所有电影的详情页href
def spider():
#连接数据库
base_url = 'https://www.dy2018.com/html/gndy/dyzz/index_{}.html'
moves = []
m = int(input('请输入您要获取的开始页:'))
n = int(input('请输入您要获取的结束页:'))
print('即将写入第{}页到第{}页的电影信息,请稍后...'.format(m, n))
for i in range(m,n+1):
print('******* 第{}页电影 正在写入 ********'.format(i))
if i == 1:
url = "https://www.dy2018.com/html/gndy/dyzz/"
else:
url = base_url.format(i)
moveHref = getHref(url)
print("休息2s后再进行操作")
time.sleep(2)
for index,mhref in enumerate(moveHref):
print('---- 正在处理第{}部电影----'.format(index+1))
move = getPage(mhref)
moves.append(move)
# 将电影信息写入数据库
db = pymysql.connect(host='127.0.0.1',user='root', password='123456', port=3306, db='你的数据库名称')
table = 'movies'
i = 1
for data in moves:
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'INSERT INTO {table}(id,{keys}) VALUES (null,{values})'.format(table=table, keys=keys, values=values)
try:
cursor = db.cursor()
cursor.execute(sql, tuple(data.values()))
print('本条数据成功执行!')
if i%10==0:
db.commit()
except Exception as e:
print('将电影信息写入数据库发生异常!',repr(e))
db.rollback()
cursor.close()
i = i + 1
db.commit()
db.close()
print('写入数据库完成!')
if __name__ == '__main__':
spider()CREATE TABLE `movies` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`movie_name` varchar(255) DEFAULT NULL,
`image_path` varchar(255) DEFAULT NULL,
`screenshot` varchar(255) DEFAULT NULL,
`translation` varchar(255) DEFAULT NULL,
`movie_title` varchar(255) DEFAULT NULL,
`movie_age` varchar(50) DEFAULT NULL,
`movie_place` varchar(50) DEFAULT NULL,
`category` varchar(100) DEFAULT NULL,
`language` varchar(100) DEFAULT NULL,
`subtitle` varchar(100) DEFAULT NULL,
`release_date` varchar(50) DEFAULT NULL,
`douban_score` varchar(50) DEFAULT NULL,
`file_length` varchar(255) DEFAULT NULL,
`director` varchar(100) DEFAULT NULL,
`screenwriter` varchar(100) DEFAULT NULL,
`stars` mediumtext,
`tags` varchar(255) DEFAULT NULL,
`introduction` mediumtext,
`awards` text,
`movie_url` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;打开 collectMovies.py 所在目录,输入命令运行:
python collectMovies.py
运行结果如下:
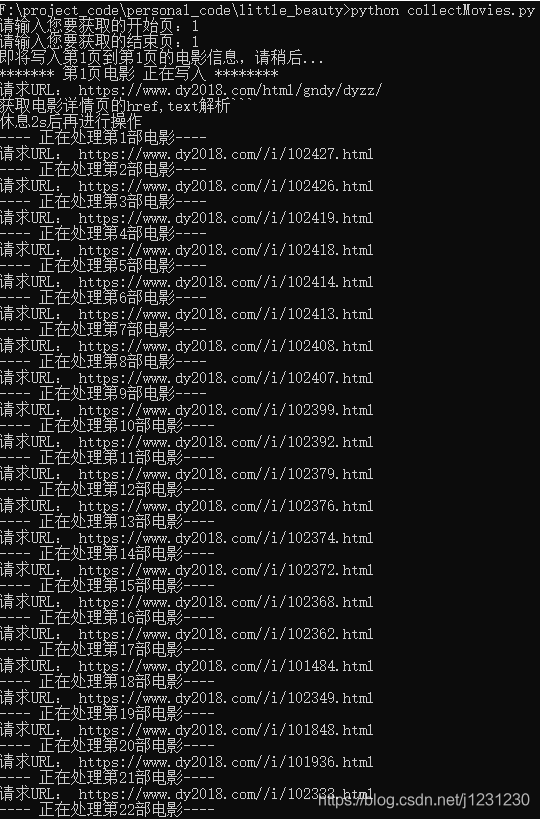
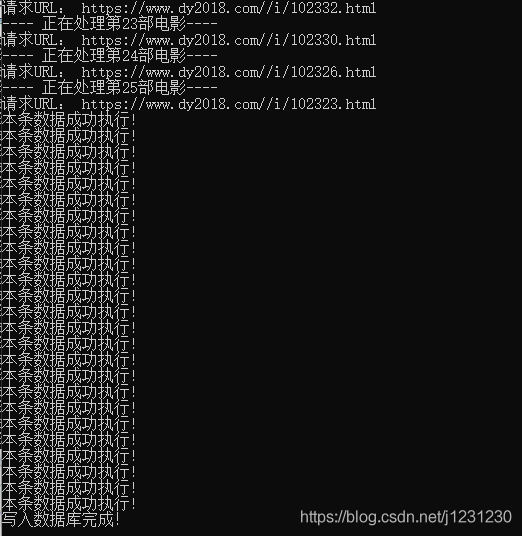
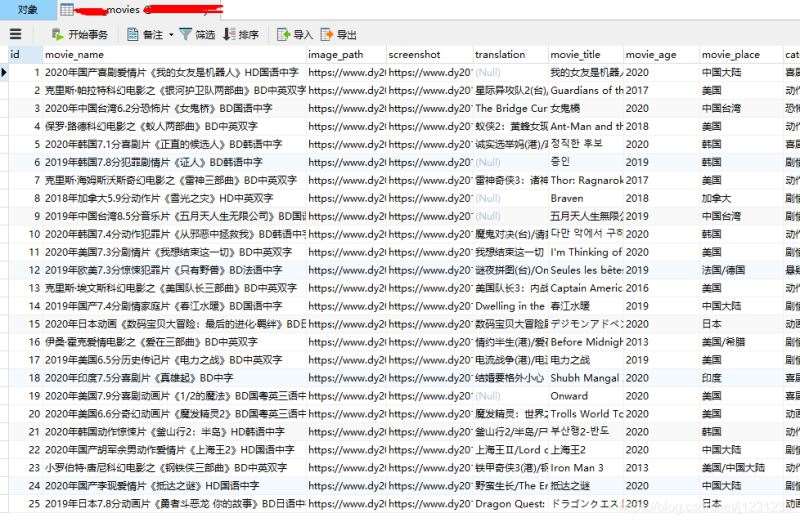
查看数据库表,数据已成功插入:
第一次使用 Python,不太熟悉它的规则,空格和Tab混用,运行会报如下错:
unindent does not match any outer indentation level解决方法
下载 Notepad++,选择 “编辑” – “空白字符操作” – "空格转 Tab (行首)"即可。
修改好格式之后再次运行,反反复复的报请求的错,报错信息主要包括以下内容:
ssl.SSLEOFError: EOF occurred in violation of protocol
······
Max retries exceeded with url解决方法
本来以为是请求设置出了问题,各种百度,还安装了 pip install incremental ,但是依然没有奏效。
后来把请求的网址换成百度网就不报错了,这样可以定位到是原网址的访问出了问题,更换了采集源路径,该问题解决。
以上是“如何使用Python爬虫实现抓取电影网站信息并入库”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



