今天小编给大家分享一下hadoop如何自定义分区的相关知识点,内容详细,逻辑清晰,相信大部分人都还太了解这方面的知识,所以分享这篇文章给大家参考一下,希望大家阅读完这篇文章后有所收获,下面我们一起来了解一下吧。
分区这个词对很多同学来说并不陌生,比如Java很多中间件中,像kafka的分区,mysql的分区表等,分区存在的意义在于将数据按照业务规则进行合理的划分,方便后续对各个分区数据高效处理
hadoop中的分区,是把不同数据输出到不同reduceTask ,最终到输出不同文件中
hadoop 默认分区规则
hash分区
按照key的hashCode % reduceTask 数量 = 分区号
默认reduceTask 数量为1,当然也可以在driver 端设置
以下是Partition 类中摘取出来的源码,还是很容易懂的

hash分区代码演示
下面是wordcount案例中的driver部分的代码,默认情况下我们不做任何设置,最终输出一个统计单词个数的txt文件,如果我们在这段代码中添加这样一行

再次运行下面的程序后,会出现什么结果呢?
public class DemoJobDriver {
public static void main(String[] args) throws Exception {
//1、获取job
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
//2、设置jar路径
job.setJarByClass(DemoJobDriver.class);
//3、关联mapper 和 Reducer
job.setMapperClass(DemoMapper.class);
job.setReducerClass(DemoReducer.class);
//4、设置 map输出的 key/val 的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5、设置最终输出的key / val 类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6、设置最终的输出路径
String inputPath = "F:\\网盘\\csv\\hello.txt";
String outPath = "F:\\网盘\\csv\\wordcount\\hello_result.txt";
//设置输出文件为2个
job.setNumReduceTasks(2);
FileInputFormat.setInputPaths(job,new Path(inputPath));
FileOutputFormat.setOutputPath(job,new Path(outPath));
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}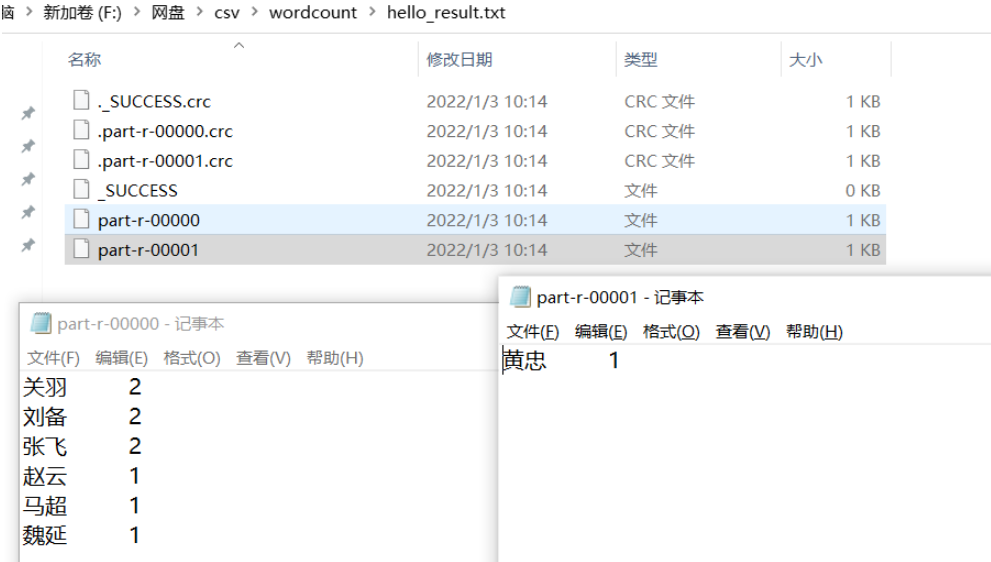
可以看到,最终输出了2个统计结果文件,每个文件中的内容有所不同,这就是默认情况下,当reducer个数设置为多个时,会按照hash分区算法计算结果并输出到不同分区对应的文件中去
自定义类继承Partitioner
重写getPartition方法,并在此方法中根据业务规则控制不同的数据进入到不同分区
在Job的驱动类中,设置自定义的Partitioner类
自定义Partition后,要根据自定义的Partition逻辑设置相应数量的ReduceTask
将下面文件中 的人物名称按照姓氏,“马”姓的放入第一个分区,“李”姓的放入第二个分区,其他的放到其他第三个分区中

自定义分区
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.io.Text;
public class MyPartioner extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text text, IntWritable intWritable, int partion) {
String key = text.toString();
if(StringUtils.isNotEmpty(key.trim())){
if(key.startsWith("马")){
partion = 0;
}else if(key.startsWith("李")){
partion = 1;
}else {
partion = 2;
}
}
return partion;
}
}将自定义分区关联到Driver类中,注意这里的ReduceTasks个数和自定义的分区数量保持一致
job.setNumReduceTasks(3); job.setPartitionerClass(MyPartioner.class);
下面运行Driver类,观察最终的输出结果,也是按照预期,将不同的姓氏数据输出到了不同的文件中

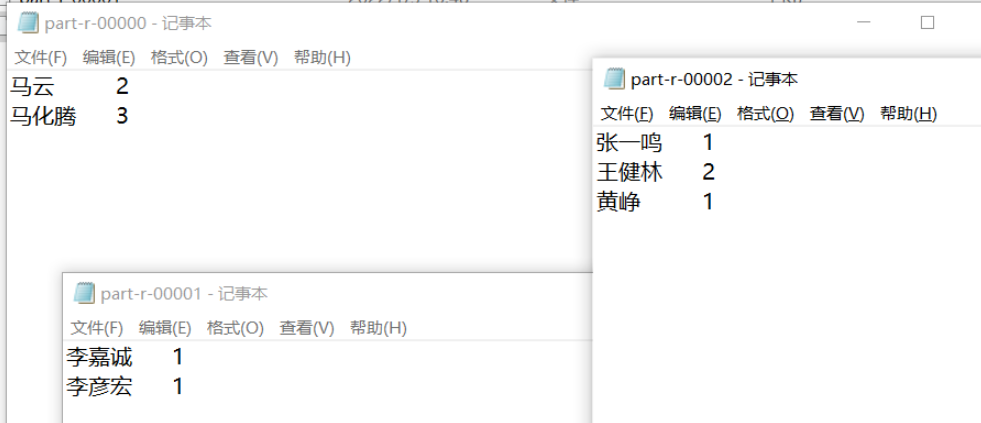
关于自定义分区的总结
如果ReduceTask的数量 > 自定义partion中的分区数量,则会多产生几个空的输出文件
如果 1 < ReduceTask < 自定义partion中的分区数量,有一部分的数据处理过程中无法找到相应的分区文件存储,会抛异常
如果ReduceTask = 1 ,则不管自定义的partion中分区数量为多少个,最终结果都只会交给这一个ReduceTask 处理,最终只会产生一个结果文件
分区号必须从0开始,逐一累加
以上就是“hadoop如何自定义分区”这篇文章的所有内容,感谢各位的阅读!相信大家阅读完这篇文章都有很大的收获,小编每天都会为大家更新不同的知识,如果还想学习更多的知识,请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





