жҖҺд№ҲдҪҝз”ЁSQLе®һзҺ°иҪҰжөҒйҮҸзҡ„и®Ўз®—
иҝҷзҜҮж–Үз« дё»иҰҒдёәеӨ§е®¶еұ•зӨәдәҶвҖңжҖҺд№ҲдҪҝз”ЁSQLе®һзҺ°иҪҰжөҒйҮҸзҡ„и®Ўз®—вҖқпјҢеҶ…е®№з®ҖиҖҢжҳ“жҮӮпјҢжқЎзҗҶжё…жҷ°пјҢеёҢжңӣиғҪеӨҹеё®еҠ©еӨ§е®¶и§ЈеҶіз–‘жғ‘пјҢдёӢйқўи®©е°Ҹзј–еёҰйўҶеӨ§е®¶дёҖиө·з ”究并еӯҰд№ дёҖдёӢвҖңжҖҺд№ҲдҪҝз”ЁSQLе®һзҺ°иҪҰжөҒйҮҸзҡ„и®Ўз®—вҖқиҝҷзҜҮж–Үз« еҗ§гҖӮ
еҚЎеҸЈиҪ¬жҚўзҺҮ
е°Ҷж•°жҚ®еҜје…ҘhiveпјҢйҖҡиҝҮSparkSqlзј–еҶҷsql,е®һзҺ°дёҚеҗҢдёҡеҠЎзҡ„ж•°жҚ®и®Ўз®—е®һзҺ°пјҢдё»иҰҒи®Іиҝ°иҪҰиҫҶеҚЎеҸЈиҪ¬жҚўзҺҮпјҢеҚЎеҸЈиҪ¬еҢ–зҺҮпјҡдё»иҰҒи®Ўз®—дёҚеҗҢеҚЎеҸЈдёӢиҪҰиҫҶд№Ӣй—ҙзҡ„жөҒеҗ‘пјҢжұӮеҮәд№Ӣй—ҙзҡ„иҪ¬жҚўзҺҮгҖӮ
1гҖҒжҹҘеҮәжҜҸдёӘең°еҢәдёӢжҜҸдёӘи·Ҝж®өдёӢзҡ„иҪҰжөҒйҮҸ
select
car,
monitor_id,
action_time,
ROW_NUMBER () OVER (PARTITION by car
ORDER by
action_time) as n1
FROM
traffic.hive_flow_action
жӯӨз»“жһңеҒҡдёәиЎЁ1пјҢж–№дҫҝеҗҺйқўй”ҷдҪҚиҝһжҺҘдҪҝз”Ё
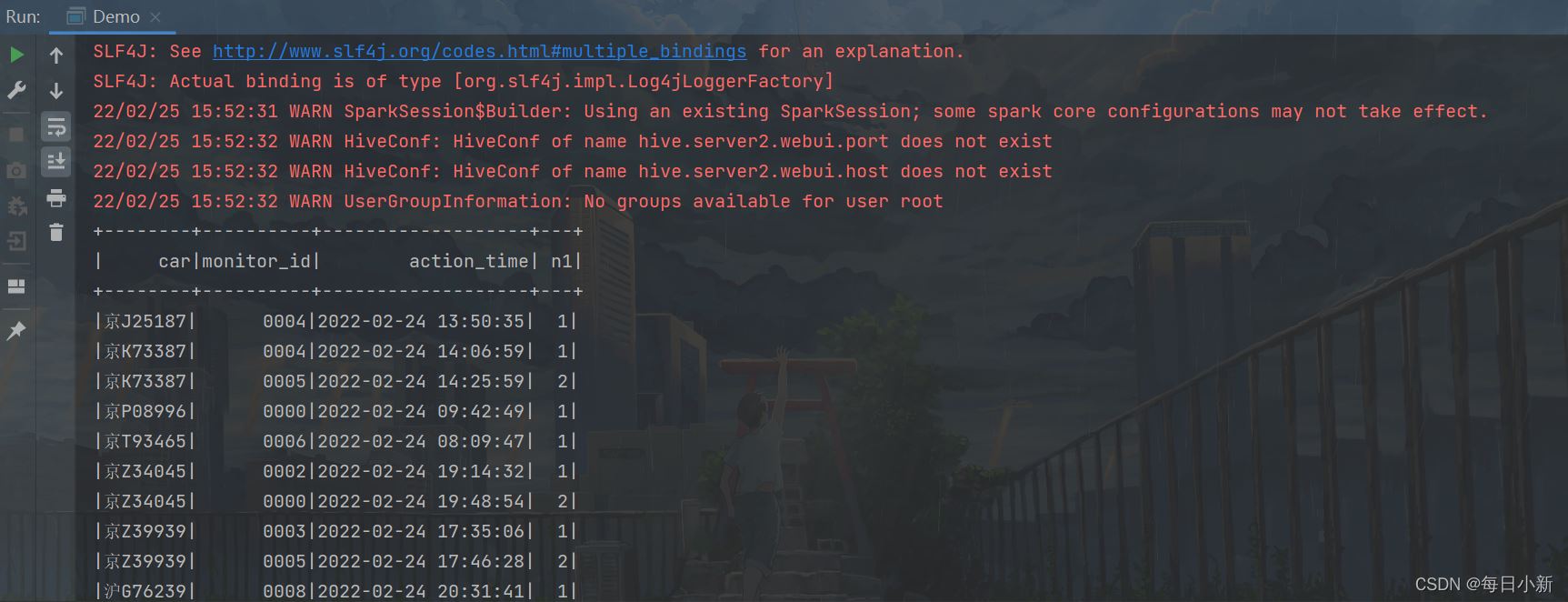
2гҖҒйҖҡиҝҮй”ҷдҪҚиҝһжҺҘиҺ·еҸ–жҜҸиҫҶиҪҰзҡ„иЎҢиҪҰи®°еҪ•
йҖҡиҝҮиЎЁ1зҡ„з»“жһңпјҢдёҺиҮӘиә«иҝӣиЎҢй”ҷдҪҚй“ҫжҺҘпјҢ并д»ҘиҪҰзүҢдёәеҲҶеҢәпјҢжӢјжҺҘз»ҸиҝҮеҚЎеҸЈзҡ„иҝҮзЁӢ
(select
t1.car,
t1.monitor_id,
concat(t1.monitor_id,
"->",
t2.monitor_id) as way
from
(
select
car,
monitor_id,
action_time,
ROW_NUMBER () OVER (PARTITION by car
ORDER by
action_time) as n1
FROM
traffic.hive_flow_action) t1
left join (
select
car,
monitor_id,
action_time,
ROW_NUMBER () OVER (PARTITION by car
ORDER by
action_time) as n1
FROM
traffic.hive_flow_action) t2 on
t1.car = t2.car
and t1.n1 = t2.n1-1
where
t2.action_time is not null)
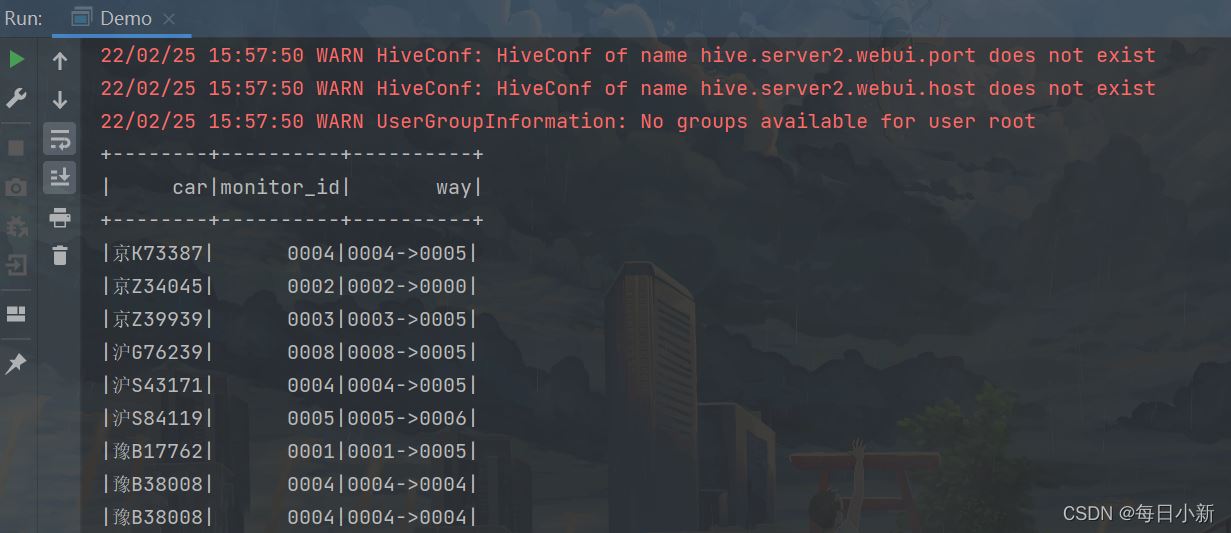
иҺ·еҸ–еҲ°жҜҸиҫҶиҪҰзҡ„дёҖдёӘиЎҢиҪҰи®°еҪ•пјҢз»ҸиҝҮзҡ„еҚЎеҸЈ
3гҖҒиҺ·еҸ–иЎҢиҪҰиҝҮзЁӢдёӯзҡ„иҪҰиҫҶж•°
иҺ·еҸ–еҚЎеҸЈ1~еҚЎеҸЈ2пјҢ…зӯүзҡ„иҪҰиҫҶж•°жңүе“Әдәӣ,еҚіжӢҝдёҠйқўзҡ„иЎҢиҪҰи®°еҪ•еӯ—ж®өиҝӣиЎҢеҲҶеҢәеңЁиҝӣиЎҢз»ҹи®Ў
(select
s1.way,
COUNT(1) sumCar
from
--иЎҢиҪҰиҝҮзЁӢ
(select
t1.car,
t1.monitor_id,
concat(t1.monitor_id,
"->",
t2.monitor_id) as way
from
(
select
car,
monitor_id,
action_time,
ROW_NUMBER () OVER (PARTITION by car
ORDER by
action_time) as n1
FROM
traffic.hive_flow_action) t1
left join (
select
car,
monitor_id,
action_time,
ROW_NUMBER () OVER (PARTITION by car
ORDER by
action_time) as n1
FROM
traffic.hive_flow_action) t2 on
t1.car = t2.car
and t1.n1 = t2.n1-1
where
t2.action_time is not null)s1
group by way)
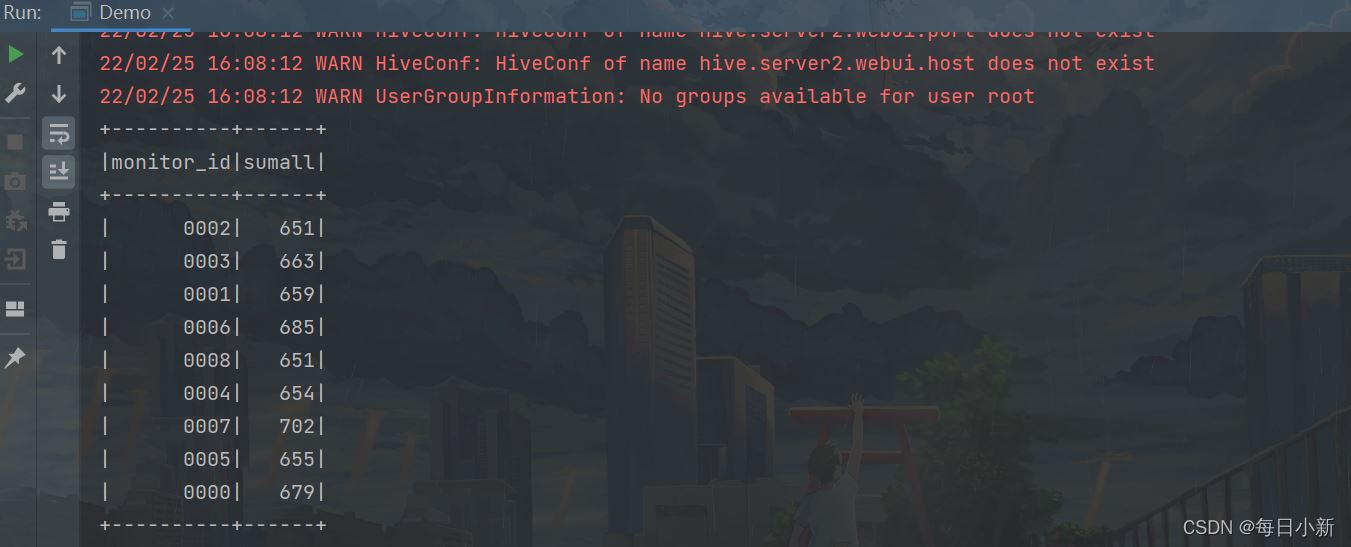
4гҖҒиҺ·еҸ–жҜҸдёӘеҚЎеҸЈзҡ„жҖ»иҪҰиҫҶж•°
иҺ·еҸ–жҜҸдёӘеҚЎеҸЈжңҖеҲқзҡ„иҪҰиҫҶж•°пјҢж–№дҫҝеҗҺйқўжӢҝиЎҢиҪҰиҪЁиҝ№иҪҰиҫҶж•°/жҖ»иҪҰиҫҶж•°пјҢеҫ—еҮәеҚЎеҸЈд№Ӣй—ҙзҡ„иҪ¬жҚўзҺҮ
select
monitor_id ,
COUNT(1) sumall
from
traffic.hive_flow_action
group by
monitor_id
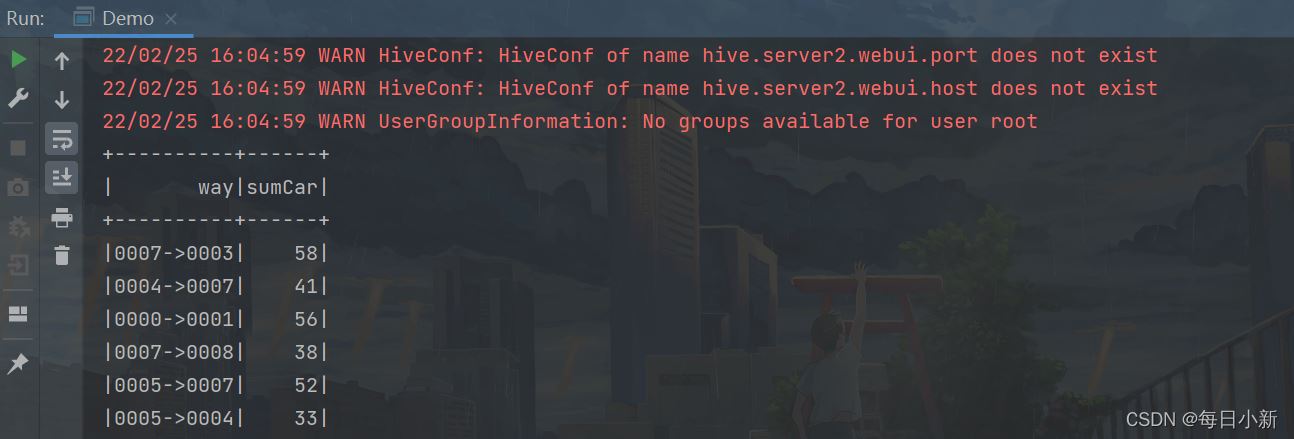
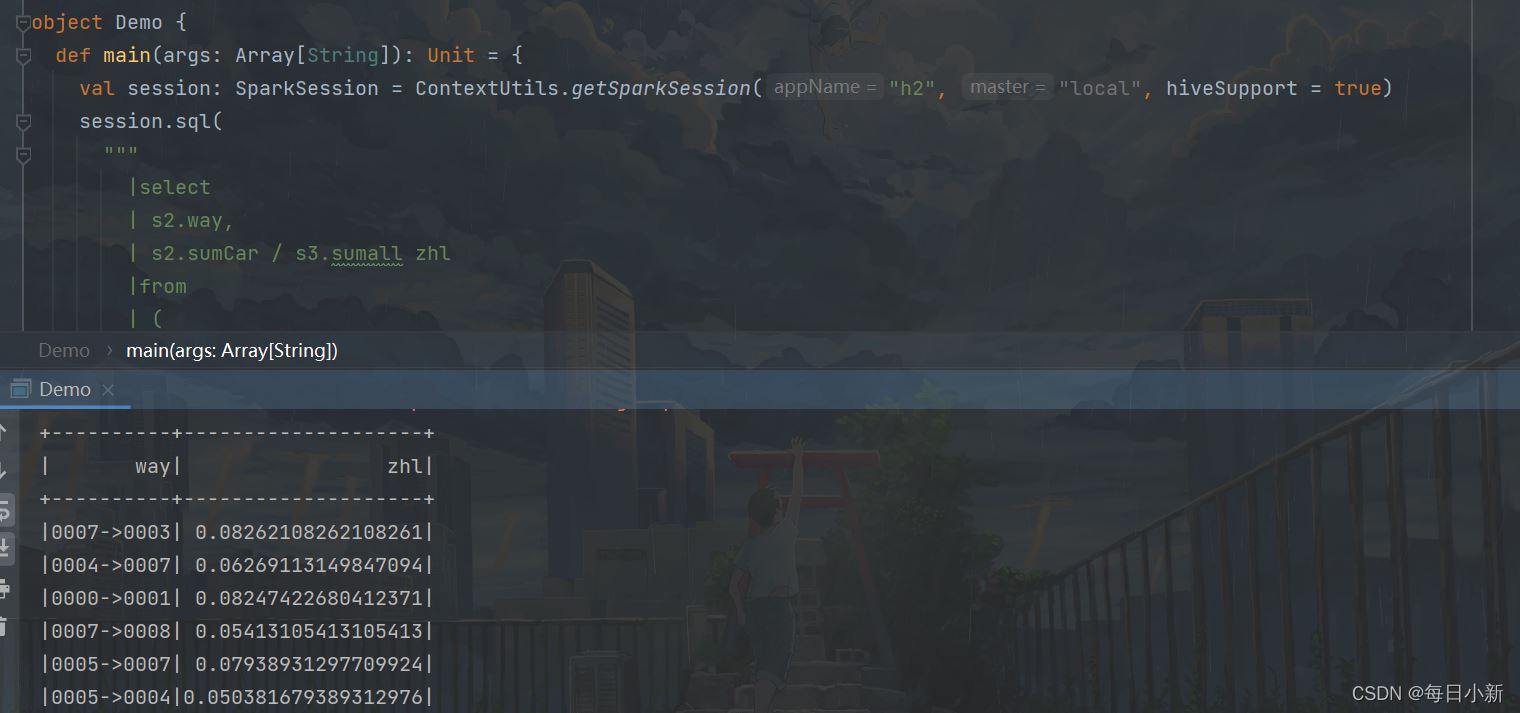
5гҖҒжұӮеҮәеҚЎеҸЈд№Ӣй—ҙзҡ„иҪ¬жҚўзҺҮ
select
s2.way,
s2.sumCar / s3.sumall zhl
from
(
select
s1.way,
COUNT(1) sumCar
from
--иЎҢиҪҰиҝҮзЁӢ
(
select
t1.car,
t1.monitor_id,
concat(t1.monitor_id,
"->",
t2.monitor_id) as way
from
(
select
car,
monitor_id,
action_time,
ROW_NUMBER () OVER (PARTITION by car
ORDER by
action_time) as n1
FROM
traffic.hive_flow_action) t1
left join (
select
car,
monitor_id,
action_time,
ROW_NUMBER () OVER (PARTITION by car
ORDER by
action_time) as n1
FROM
traffic.hive_flow_action) t2 on
t1.car = t2.car
and t1.n1 = t2.n1-1
where
t2.action_time is not null)s1
group by
way)s2
left join
--жҜҸдёӘеҚЎеҸЈжҖ»иҪҰж•°
(
select
monitor_id ,
COUNT(1) sumall
from
traffic.hive_flow_action
group by
monitor_id) s3 on
split(s2.way,
"->")[0]= s3.monitor_id
д»ҘдёҠжҳҜвҖңжҖҺд№ҲдҪҝз”ЁSQLе®һзҺ°иҪҰжөҒйҮҸзҡ„и®Ўз®—вҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ





