PythonдёӯдәӨеҸүйӘҢиҜҒзҡ„ж–№жі•жңүе“Әдәӣ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңPythonдёӯдәӨеҸүйӘҢиҜҒзҡ„ж–№жі•жңүе“ӘдәӣвҖқзҡ„зӣёе…ізҹҘиҜҶпјҢе°Ҹзј–йҖҡиҝҮе®һйҷ…жЎҲдҫӢеҗ‘еӨ§е®¶еұ•зӨәж“ҚдҪңиҝҮзЁӢпјҢж“ҚдҪңж–№жі•з®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәпјҢеёҢжңӣиҝҷзҜҮвҖңPythonдёӯдәӨеҸүйӘҢиҜҒзҡ„ж–№жі•жңүе“ӘдәӣвҖқж–Үз« иғҪеё®еҠ©еӨ§е®¶и§ЈеҶій—®йўҳгҖӮ
дёҖгҖҒд»Җд№ҲжҳҜдәӨеҸүйӘҢиҜҒпјҹ
дәӨеҸүйӘҢиҜҒжҳҜдёҖз§Қз”ЁдәҺдј°и®ЎжңәеҷЁеӯҰд№ жЁЎеһӢжҖ§иғҪзҡ„з»ҹи®Ўж–№жі•пјҢе®ғжҳҜдёҖз§ҚиҜ„дј°з»ҹи®ЎеҲҶжһҗз»“жһңеҰӮдҪ•жҺЁе№ҝеҲ°зӢ¬з«Ӣж•°жҚ®йӣҶзҡ„ж–№жі•гҖӮ
дәҢгҖҒе®ғжҳҜеҰӮдҪ•и§ЈеҶіиҝҮжӢҹеҗҲй—®йўҳзҡ„пјҹ
еңЁдәӨеҸүйӘҢиҜҒдёӯпјҢжҲ‘们е°Ҷи®ӯз»ғж•°жҚ®з”ҹжҲҗеӨҡдёӘе°Ҹзҡ„и®ӯз»ғжөӢиҜ•еҲҶеүІпјҢдҪҝз”ЁиҝҷдәӣжӢҶеҲҶжқҘи°ғж•ҙжӮЁзҡ„жЁЎеһӢгҖӮ дҫӢеҰӮпјҢеңЁж ҮеҮҶзҡ„ k жҠҳдәӨеҸүйӘҢиҜҒдёӯпјҢжҲ‘们е°Ҷж•°жҚ®еҲ’еҲҶдёә k дёӘеӯҗйӣҶгҖӮ 然еҗҺпјҢжҲ‘们еңЁ k-1 дёӘеӯҗйӣҶдёҠиҝӯд»Ји®ӯз»ғз®—жі•пјҢеҗҢж—¶дҪҝз”Ёеү©дҪҷзҡ„еӯҗйӣҶдҪңдёәжөӢиҜ•йӣҶгҖӮ йҖҡиҝҮиҝҷз§Қж–№ејҸпјҢжҲ‘们еҸҜд»ҘеңЁжңӘеҸӮдёҺи®ӯз»ғзҡ„ж•°жҚ®дёҠжөӢиҜ•жҲ‘们зҡ„жЁЎеһӢгҖӮ
еңЁжң¬ж–ҮдёӯпјҢжҲ‘е°ҶеҲҶдә« 7 з§ҚжңҖеёёз”Ёзҡ„дәӨеҸүйӘҢиҜҒжҠҖжңҜеҸҠе…¶дјҳзјәзӮ№пјҢжҲ‘иҝҳжҸҗдҫӣдәҶжҜҸз§ҚжҠҖжңҜзҡ„д»Јз ҒзүҮж®өгҖӮ
дёӢйқўеҲ—еҮәдәҶиҝҷдәӣжҠҖжңҜж–№жі•пјҡ
HoldOut дәӨеҸүйӘҢиҜҒ
K-Fold дәӨеҸүйӘҢиҜҒ
еҲҶеұӮ K-FoldдәӨеҸүйӘҢиҜҒ
Leave P Out дәӨеҸүйӘҢиҜҒ
з•ҷдёҖдәӨеҸүйӘҢиҜҒ
и’ҷзү№еҚЎжҙӣ (Shuffle-Split)
ж—¶й—ҙеәҸеҲ—пјҲж»ҡеҠЁдәӨеҸүйӘҢиҜҒпјү
1гҖҒHoldOut дәӨеҸүйӘҢиҜҒ
еңЁиҝҷз§ҚдәӨеҸүйӘҢиҜҒжҠҖжңҜдёӯпјҢж•ҙдёӘж•°жҚ®йӣҶиў«йҡҸжңәеҲ’еҲҶдёәи®ӯз»ғйӣҶе’ҢйӘҢиҜҒйӣҶгҖӮ ж №жҚ®з»ҸйӘҢпјҢж•ҙдёӘж•°жҚ®йӣҶзҡ„иҝ‘ 70% з”ЁдҪңи®ӯз»ғйӣҶпјҢе…¶дҪҷ 30% з”ЁдҪңйӘҢиҜҒйӣҶгҖӮ

дјҳзӮ№пјҡ
1.еҝ«йҖҹжү§иЎҢпјҡеӣ дёәжҲ‘们еҝ…йЎ»е°Ҷж•°жҚ®йӣҶжӢҶеҲҶдёәи®ӯз»ғйӣҶе’ҢйӘҢиҜҒйӣҶдёҖж¬ЎпјҢ并且模еһӢе°ҶеңЁи®ӯз»ғйӣҶдёҠд»…жһ„е»әдёҖж¬ЎпјҢеӣ жӯӨеҸҜд»Ҙеҝ«йҖҹжү§иЎҢгҖӮ
зјәзӮ№пјҡ
дёҚйҖӮеҗҲдёҚе№іиЎЎж•°жҚ®йӣҶпјҡеҒҮи®ҫжҲ‘们жңүдёҖдёӘдёҚе№іиЎЎж•°жҚ®йӣҶпјҢе®ғе…·жңүвҖң0вҖқзұ»е’ҢвҖң1вҖқзұ»гҖӮ еҒҮи®ҫ 80% зҡ„ж•°жҚ®еұһдәҺвҖң0вҖқзұ»пјҢе…¶дҪҷ 20% зҡ„ж•°жҚ®еұһдәҺвҖң1вҖқзұ»гҖӮеңЁи®ӯз»ғйӣҶеӨ§е°Ҹдёә 80%пјҢжөӢиҜ•ж•°жҚ®еӨ§е°Ҹдёәж•°жҚ®йӣҶзҡ„ 20% зҡ„жғ…еҶөдёӢиҝӣиЎҢи®ӯз»ғ-жөӢиҜ•еҲҶеүІгҖӮ еҸҜиғҪдјҡеҸ‘з”ҹвҖң0вҖқзұ»зҡ„жүҖжңү 80% ж•°жҚ®йғҪеңЁи®ӯз»ғйӣҶдёӯпјҢиҖҢвҖң1вҖқзұ»зҡ„жүҖжңүж•°жҚ®йғҪеңЁжөӢиҜ•йӣҶдёӯгҖӮ жүҖд»ҘжҲ‘们зҡ„жЁЎеһӢдёҚиғҪеҫҲеҘҪең°жҰӮжӢ¬жҲ‘们зҡ„жөӢиҜ•ж•°жҚ®пјҢеӣ дёәе®ғд№ӢеүҚжІЎжңүзңӢеҲ°иҝҮвҖң1вҖқзұ»зҡ„ж•°жҚ®гҖӮ
еӨ§йҮҸж•°жҚ®ж— жі•и®ӯз»ғжЁЎеһӢгҖӮ
еңЁе°Ҹж•°жҚ®йӣҶзҡ„жғ…еҶөдёӢпјҢе°Ҷдҝқз•ҷдёҖйғЁеҲҶз”ЁдәҺжөӢиҜ•жЁЎеһӢпјҢе…¶дёӯеҸҜиғҪе…·жңүжҲ‘们зҡ„жЁЎеһӢеҸҜиғҪдјҡй”ҷиҝҮзҡ„йҮҚиҰҒзү№еҫҒпјҢеӣ дёәе®ғжІЎжңүеҜ№иҜҘж•°жҚ®иҝӣиЎҢи®ӯз»ғгҖӮ
д»Јз ҒзүҮж®ө
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
iris=load_iris()
X=iris.data
Y=iris.target
print("Size of Dataset {}".format(len(X)))
logreg=LogisticRegression()
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.3,random_state=42)
logreg.fit(x_train,y_train)
predict=logreg.predict(x_test)
print("Accuracy score on training set is {}".format(accuracy_score(logreg.predict(x_train),y_train)))
print("Accuracy score on test set is {}".format(accuracy_score(predict,y_test)))
2гҖҒK жҠҳдәӨеҸүйӘҢиҜҒ
еңЁиҝҷз§Қ K жҠҳдәӨеҸүйӘҢиҜҒжҠҖжңҜдёӯпјҢж•ҙдёӘж•°жҚ®йӣҶиў«еҲ’еҲҶдёә K дёӘзӣёзӯүеӨ§е°Ҹзҡ„йғЁеҲҶгҖӮ жҜҸдёӘеҲҶеҢәз§°дёәдёҖдёӘвҖңжҠҳеҸ вҖқгҖӮеӣ жӯӨпјҢеӣ дёәжҲ‘们жңү K дёӘйғЁеҲҶпјҢжүҖд»ҘжҲ‘们称д№Ӣдёә K жҠҳеҸ гҖӮ дёҖжҠҳз”ЁдҪңйӘҢиҜҒйӣҶпјҢе…¶дҪҷ K-1 жҠҳз”ЁдҪңи®ӯз»ғйӣҶгҖӮ
иҜҘжҠҖжңҜйҮҚеӨҚ K ж¬ЎпјҢзӣҙеҲ°жҜҸдёӘжҠҳеҸ з”ЁдҪңйӘҢиҜҒйӣҶпјҢе…¶дҪҷжҠҳеҸ з”ЁдҪңи®ӯз»ғйӣҶгҖӮ
жЁЎеһӢзҡ„жңҖз»ҲзІҫеәҰжҳҜйҖҡиҝҮеҸ–k-models йӘҢиҜҒж•°жҚ®зҡ„е№іеқҮзІҫеәҰжқҘи®Ўз®—зҡ„гҖӮ

дјҳзӮ№пјҡ
зјәзӮ№пјҡ
дёҚз”ЁдәҺдёҚе№іиЎЎзҡ„ж•°жҚ®йӣҶпјҡжӯЈеҰӮеңЁ HoldOut дәӨеҸүйӘҢиҜҒзҡ„жғ…еҶөдёӢжүҖи®Ёи®әзҡ„пјҢеңЁ K-Fold йӘҢиҜҒзҡ„жғ…еҶөдёӢд№ҹеҸҜиғҪеҸ‘з”ҹи®ӯз»ғйӣҶзҡ„жүҖжңүж ·жң¬йғҪжІЎжңүж ·жң¬еҪўејҸзұ»вҖң1вҖқпјҢ并且еҸӘжңү зұ»вҖң0вҖқгҖӮйӘҢиҜҒйӣҶе°ҶжңүдёҖдёӘзұ»вҖң1вҖқзҡ„ж ·жң¬гҖӮ
дёҚйҖӮеҗҲж—¶й—ҙеәҸеҲ—ж•°жҚ®пјҡеҜ№дәҺж—¶й—ҙеәҸеҲ—ж•°жҚ®пјҢж ·жң¬зҡ„йЎәеәҸеҫҲйҮҚиҰҒгҖӮ дҪҶжҳҜеңЁ K жҠҳдәӨеҸүйӘҢиҜҒдёӯпјҢж ·жң¬жҳҜжҢүйҡҸжңәйЎәеәҸйҖүжӢ©зҡ„гҖӮ
д»Јз ҒзүҮж®өпјҡ
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score,KFold
from sklearn.linear_model import LogisticRegression
iris=load_iris()
X=iris.data
Y=iris.target
logreg=LogisticRegression()
kf=KFold(n_splits=5)
score=cross_val_score(logreg,X,Y,cv=kf)
print("Cross Validation Scores are {}".format(score))
print("Average Cross Validation score :{}".format(score.mean()))
3гҖҒеҲҶеұӮ K жҠҳдәӨеҸүйӘҢиҜҒ
еҲҶеұӮ K-Fold жҳҜ K-Fold дәӨеҸүйӘҢиҜҒзҡ„еўһејәзүҲжң¬пјҢдё»иҰҒз”ЁдәҺдёҚе№іиЎЎзҡ„ж•°жҚ®йӣҶгҖӮ е°ұеғҸ K-fold дёҖж ·пјҢж•ҙдёӘж•°жҚ®йӣҶиў«еҲҶжҲҗеӨ§е°Ҹзӣёзӯүзҡ„ K-foldгҖӮ
дҪҶжҳҜеңЁиҝҷз§ҚжҠҖжңҜдёӯпјҢжҜҸдёӘжҠҳеҸ е°Ҷе…·жңүдёҺж•ҙдёӘж•°жҚ®йӣҶдёӯзӣёеҗҢзҡ„зӣ®ж ҮеҸҳйҮҸе®һдҫӢжҜ”зҺҮгҖӮ
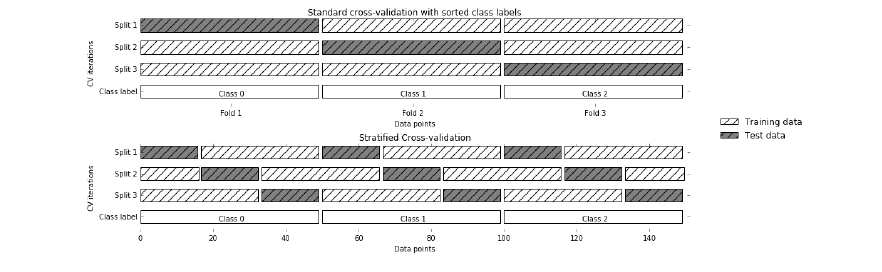
дјҳзӮ№пјҡ
зјәзӮ№пјҡ
д»Јз ҒзүҮж®өпјҡ
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score,StratifiedKFold
from sklearn.linear_model import LogisticRegression
iris=load_iris()
X=iris.data
Y=iris.target
logreg=LogisticRegression()
stratifiedkf=StratifiedKFold(n_splits=5)
score=cross_val_score(logreg,X,Y,cv=stratifiedkf)
print("Cross Validation Scores are {}".format(score))
print("Average Cross Validation score :{}".format(score.mean()))
4гҖҒLeave P Out дәӨеҸүйӘҢиҜҒ
Leave P Out дәӨеҸүйӘҢиҜҒжҳҜдёҖз§ҚиҜҰе°Ҫзҡ„дәӨеҸүйӘҢиҜҒжҠҖжңҜпјҢе…¶дёӯ p ж ·жң¬з”ЁдҪңйӘҢиҜҒйӣҶпјҢеү©дҪҷзҡ„ np ж ·жң¬з”ЁдҪңи®ӯз»ғйӣҶгҖӮ
еҒҮи®ҫжҲ‘们еңЁж•°жҚ®йӣҶдёӯжңү 100 дёӘж ·жң¬гҖӮ еҰӮжһңжҲ‘们дҪҝз”Ё p=10пјҢйӮЈд№ҲеңЁжҜҸж¬Ўиҝӯд»ЈдёӯпјҢ10 дёӘеҖје°Ҷз”ЁдҪңйӘҢиҜҒйӣҶпјҢе…¶дҪҷ 90 дёӘж ·жң¬е°Ҷз”ЁдҪңи®ӯз»ғйӣҶгҖӮ
йҮҚеӨҚиҝҷдёӘиҝҮзЁӢпјҢзӣҙеҲ°ж•ҙдёӘж•°жҚ®йӣҶеңЁ p-ж ·жң¬е’Ң n-p и®ӯз»ғж ·жң¬зҡ„йӘҢиҜҒйӣҶдёҠиў«еҲ’еҲҶгҖӮ
дјҳзӮ№пјҡ
зјәзӮ№пјҡ
и®Ўз®—ж—¶й—ҙй•ҝпјҡз”ұдәҺдёҠиҝ°жҠҖжңҜдјҡдёҚж–ӯйҮҚеӨҚпјҢзӣҙеҲ°жүҖжңүж ·жң¬йғҪз”ЁдҪңйӘҢиҜҒйӣҶпјҢеӣ жӯӨи®Ўз®—ж—¶й—ҙдјҡжӣҙй•ҝгҖӮ
дёҚйҖӮеҗҲдёҚе№іиЎЎж•°жҚ®йӣҶпјҡдёҺ K жҠҳдәӨеҸүйӘҢиҜҒзӣёеҗҢпјҢеҰӮжһңеңЁи®ӯз»ғйӣҶдёӯжҲ‘们еҸӘжңү 1 дёӘзұ»зҡ„ж ·жң¬пјҢйӮЈд№ҲжҲ‘们зҡ„жЁЎеһӢе°Ҷж— жі•жҺЁе№ҝеҲ°йӘҢиҜҒйӣҶгҖӮ
д»Јз ҒзүҮж®ө
from sklearn.model_selection import LeavePOut,cross_val_score
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
iris=load_iris()
X=iris.data
Y=iris.target
lpo=LeavePOut(p=2)
lpo.get_n_splits(X)
tree=RandomForestClassifier(n_estimators=10,max_depth=5,n_jobs=-1)
score=cross_val_score(tree,X,Y,cv=lpo)
print("Cross Validation Scores are {}".format(score))
print("Average Cross Validation score :{}".format(score.mean()))
5гҖҒз•ҷдёҖдәӨеҸүйӘҢиҜҒ
з•ҷдёҖдәӨеҸүйӘҢиҜҒжҳҜдёҖз§ҚиҜҰе°Ҫзҡ„дәӨеҸүйӘҢиҜҒжҠҖжңҜпјҢе…¶дёӯ 1 дёӘж ·жң¬зӮ№з”ЁдҪңйӘҢиҜҒйӣҶпјҢе…¶дҪҷ n-1 дёӘж ·жң¬з”ЁдҪңи®ӯз»ғйӣҶгҖӮ
еҒҮи®ҫжҲ‘们еңЁж•°жҚ®йӣҶдёӯжңү 100 дёӘж ·жң¬гҖӮ 然еҗҺеңЁжҜҸж¬Ўиҝӯд»ЈдёӯпјҢ1 дёӘеҖје°Ҷз”ЁдҪңйӘҢиҜҒйӣҶпјҢе…¶дҪҷ 99 дёӘж ·жң¬дҪңдёәи®ӯз»ғйӣҶгҖӮ еӣ жӯӨпјҢйҮҚеӨҚиҜҘиҝҮзЁӢпјҢзӣҙеҲ°ж•°жҚ®йӣҶзҡ„жҜҸдёӘж ·жң¬йғҪз”ЁдҪңйӘҢиҜҒзӮ№гҖӮ
е®ғдёҺдҪҝз”Ё p=1 зҡ„ LeavePOut дәӨеҸүйӘҢиҜҒзӣёеҗҢгҖӮ
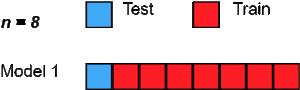
д»Јз ҒзүҮж®өпјҡ
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import LeaveOneOut,cross_val_score
iris=load_iris()
X=iris.data
Y=iris.target
loo=LeaveOneOut()
tree=RandomForestClassifier(n_estimators=10,max_depth=5,n_jobs=-1)
score=cross_val_score(tree,X,Y,cv=loo)
print("Cross Validation Scores are {}".format(score))
print("Average Cross Validation score :{}".format(score.mean()))
6гҖҒи’ҷзү№еҚЎзҪ—дәӨеҸүйӘҢиҜҒпјҲShuffle Splitпјү
и’ҷзү№еҚЎзҪ—дәӨеҸүйӘҢиҜҒпјҢд№ҹз§°дёәShuffle SplitдәӨеҸүйӘҢиҜҒпјҢжҳҜдёҖз§ҚйқһеёёзҒөжҙ»зҡ„дәӨеҸүйӘҢиҜҒзӯ–з•ҘгҖӮ еңЁиҝҷз§ҚжҠҖжңҜдёӯпјҢж•°жҚ®йӣҶиў«йҡҸжңәеҲ’еҲҶдёәи®ӯз»ғйӣҶе’ҢйӘҢиҜҒйӣҶгҖӮ
жҲ‘们已з»ҸеҶіе®ҡдәҶиҰҒз”ЁдҪңи®ӯз»ғйӣҶзҡ„ж•°жҚ®йӣҶзҡ„зҷҫеҲҶжҜ”е’Ңз”ЁдҪңйӘҢиҜҒйӣҶзҡ„зҷҫеҲҶжҜ”гҖӮ еҰӮжһңи®ӯз»ғйӣҶе’ҢйӘҢиҜҒйӣҶеӨ§е°Ҹзҡ„еўһеҠ зҷҫеҲҶжҜ”жҖ»е’ҢдёҚжҳҜ 100пјҢеҲҷеү©дҪҷзҡ„ж•°жҚ®йӣҶдёҚдјҡз”ЁдәҺи®ӯз»ғйӣҶжҲ–йӘҢиҜҒйӣҶгҖӮ
еҒҮи®ҫжҲ‘们жңү 100 дёӘж ·жң¬пјҢе…¶дёӯ 60% зҡ„ж ·жң¬з”ЁдҪңи®ӯз»ғйӣҶпјҢ20% зҡ„ж ·жң¬з”ЁдҪңйӘҢиҜҒйӣҶпјҢйӮЈд№Ҳеү©дёӢзҡ„ 20%( 100-(60+20)) е°ҶдёҚиў«дҪҝз”ЁгҖӮ
иҝҷз§ҚжӢҶеҲҶе°ҶйҮҚеӨҚжҲ‘们еҝ…йЎ»жҢҮе®ҡзҡ„вҖңnвҖқж¬ЎгҖӮ

дјҳзӮ№пјҡ
зјәзӮ№пјҡ
еҸҜиғҪдёҚдјҡдёәи®ӯз»ғйӣҶжҲ–йӘҢиҜҒйӣҶйҖүжӢ©еҫҲе°‘зҡ„ж ·жң¬гҖӮ
дёҚйҖӮеҗҲдёҚе№іиЎЎзҡ„ж•°жҚ®йӣҶпјҡеңЁжҲ‘们е®ҡд№үдәҶи®ӯз»ғйӣҶе’ҢйӘҢиҜҒйӣҶзҡ„еӨ§е°ҸеҗҺпјҢжүҖжңүзҡ„ж ·жң¬йғҪжҳҜйҡҸжңәйҖүжӢ©зҡ„пјҢжүҖд»Ҙи®ӯз»ғйӣҶеҸҜиғҪжІЎжңүжөӢиҜ•дёӯзҡ„ж•°жҚ®зұ»еҲ« и®ҫзҪ®пјҢ并且иҜҘжЁЎеһӢе°Ҷж— жі•жҰӮжӢ¬дёәзңӢдёҚи§Ғзҡ„ж•°жҚ®гҖӮ
д»Јз ҒзүҮж®өпјҡ
from sklearn.model_selection import ShuffleSplit,cross_val_score
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
logreg=LogisticRegression()
shuffle_split=ShuffleSplit(test_size=0.3,train_size=0.5,n_splits=10)
scores=cross_val_score(logreg,iris.data,iris.target,cv=shuffle_split)
print("cross Validation scores:n {}".format(scores))
print("Average Cross Validation score :{}".format(scores.mean()))
7гҖҒж—¶й—ҙеәҸеҲ—дәӨеҸүйӘҢиҜҒ
д»Җд№ҲжҳҜж—¶й—ҙеәҸеҲ—ж•°жҚ®пјҹ
ж—¶й—ҙеәҸеҲ—ж•°жҚ®жҳҜеңЁдёҚеҗҢж—¶й—ҙзӮ№ж”¶йӣҶзҡ„ж•°жҚ®гҖӮз”ұдәҺж•°жҚ®зӮ№жҳҜеңЁзӣёйӮ»ж—¶й—ҙж®ө收йӣҶзҡ„пјҢеӣ жӯӨи§ӮжөӢеҖјд№Ӣй—ҙеҸҜиғҪеӯҳеңЁзӣёе…іжҖ§гҖӮиҝҷжҳҜеҢәеҲҶж—¶й—ҙеәҸеҲ—ж•°жҚ®дёҺжЁӘжҲӘйқўж•°жҚ®зҡ„зү№еҫҒд№ӢдёҖгҖӮ
еңЁж—¶й—ҙеәҸеҲ—ж•°жҚ®зҡ„жғ…еҶөдёӢеҰӮдҪ•иҝӣиЎҢдәӨеҸүйӘҢиҜҒпјҹ
еңЁж—¶й—ҙеәҸеҲ—ж•°жҚ®зҡ„жғ…еҶөдёӢпјҢжҲ‘们дёҚиғҪйҖүжӢ©йҡҸжңәж ·жң¬е№¶е°Ҷе®ғ们еҲҶй…Қз»ҷи®ӯз»ғйӣҶжҲ–йӘҢиҜҒйӣҶпјҢеӣ дёәдҪҝз”ЁжңӘжқҘж•°жҚ®дёӯзҡ„еҖјжқҘйў„жөӢиҝҮеҺ»ж•°жҚ®зҡ„еҖјжҳҜжІЎжңүж„Ҹд№үзҡ„гҖӮ
з”ұдәҺж•°жҚ®зҡ„йЎәеәҸеҜ№дәҺж—¶й—ҙеәҸеҲ—зӣёе…ій—®йўҳйқһеёёйҮҚиҰҒпјҢжүҖд»ҘжҲ‘д»¬ж №жҚ®ж—¶й—ҙе°Ҷж•°жҚ®жӢҶеҲҶдёәи®ӯз»ғйӣҶе’ҢйӘҢиҜҒйӣҶпјҢд№ҹз§°дёәвҖңеүҚеҗ‘й“ҫвҖқж–№жі•жҲ–ж»ҡеҠЁдәӨеҸүйӘҢиҜҒгҖӮ
жҲ‘们д»ҺдёҖе°ҸйғЁеҲҶж•°жҚ®дҪңдёәи®ӯз»ғйӣҶејҖе§ӢгҖӮеҹәдәҺиҜҘйӣҶеҗҲпјҢжҲ‘们预жөӢзЁҚеҗҺзҡ„ж•°жҚ®зӮ№пјҢ然еҗҺжЈҖжҹҘеҮҶзЎ®жҖ§гҖӮ
然еҗҺе°Ҷйў„жөӢж ·жң¬дҪңдёәдёӢдёҖдёӘи®ӯз»ғж•°жҚ®йӣҶзҡ„дёҖйғЁеҲҶеҢ…жӢ¬еңЁеҶ…пјҢ并еҜ№еҗҺз»ӯж ·жң¬иҝӣиЎҢйў„жөӢгҖӮ

дјҳзӮ№пјҡ
зјәзӮ№пјҡ
д»Јз ҒзүҮж®өпјҡ
import numpy as np
from sklearn.model_selection import TimeSeriesSplit
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4, 5, 6])
time_series = TimeSeriesSplit()
print(time_series)
for train_index, test_index in time_series.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]е…ідәҺвҖңPythonдёӯдәӨеҸүйӘҢиҜҒзҡ„ж–№жі•жңүе“ӘдәӣвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶпјҢеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢе°Ҹзј–жҜҸеӨ©йғҪдјҡдёәеӨ§е®¶жӣҙж–°дёҚеҗҢзҡ„зҹҘиҜҶзӮ№гҖӮ





