Javaй”ҒеңЁе·ҘдҪңдёӯдҪҝз”ЁеңәжҷҜе®һдҫӢеҲҶжһҗ
д»ҠеӨ©е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢJavaй”ҒеңЁе·ҘдҪңдёӯдҪҝз”ЁеңәжҷҜе®һдҫӢеҲҶжһҗзҡ„зӣёе…ізҹҘиҜҶзӮ№пјҢеҶ…е®№иҜҰз»ҶпјҢйҖ»иҫ‘жё…жҷ°пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳеӨӘдәҶи§Јиҝҷж–№йқўзҡ„зҹҘиҜҶпјҢжүҖд»ҘеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘдәҶи§ЈдёҖдёӢеҗ§гҖӮ
1гҖҒsynchronized
synchronized жҳҜеҸҜйҮҚе…Ҙзҡ„жҺ’е®ғй”ҒпјҢе’Ң ReentrantLock й”ҒеҠҹиғҪзӣёдјјпјҢд»»дҪ•дҪҝз”Ё synchronized зҡ„ең°ж–№пјҢеҮ д№ҺйғҪеҸҜд»ҘдҪҝз”Ё ReentrantLock жқҘд»ЈжӣҝпјҢдёӨиҖ…жңҖеӨ§зҡ„зӣёдјјзӮ№е°ұжҳҜпјҡеҸҜйҮҚе…Ҙ + жҺ’е®ғй”ҒпјҢдёӨиҖ…зҡ„еҢәеҲ«дё»иҰҒжңүиҝҷдәӣпјҡ
ReentrantLock зҡ„еҠҹиғҪжӣҙеҠ дё°еҜҢпјҢжҜ”еҰӮжҸҗдҫӣдәҶ ConditionпјҢеҸҜд»Ҙжү“ж–ӯзҡ„еҠ й”Ғ APIгҖҒиғҪж»Ўи¶ій”Ғ + йҳҹеҲ—зҡ„еӨҚжқӮеңәжҷҜзӯүзӯүпјӣ
ReentrantLock жңүе…¬е№ій”Ғе’Ңйқһе…¬е№ій”Ғд№ӢеҲҶпјҢиҖҢ synchronized йғҪжҳҜйқһе…¬е№ій”Ғпјӣ
дёӨиҖ…зҡ„дҪҝз”Ёе§ҝеҠҝд№ҹдёҚеҗҢпјҢReentrantLock йңҖиҰҒз”іжҳҺпјҢжңүеҠ й”Ғе’ҢйҮҠж”ҫй”Ғзҡ„ APIпјҢиҖҢ synchronized дјҡиҮӘеҠЁеҜ№д»Јз Ғеқ—иҝӣиЎҢеҠ й”ҒйҮҠж”ҫй”Ғзҡ„ж“ҚдҪңпјҢsynchronized дҪҝз”Ёиө·жқҘжӣҙеҠ ж–№дҫҝгҖӮ
synchronized е’Ң ReentrantLock еҠҹиғҪзӣёиҝ‘пјҢжүҖд»ҘжҲ‘们е°ұд»Ҙ synchronized дёҫдҫӢгҖӮ
1.1гҖҒе…ұдә«иө„жәҗеҲқе§ӢеҢ–
еңЁеҲҶеёғејҸзҡ„зі»з»ҹдёӯпјҢжҲ‘们е–ңж¬ўжҠҠдёҖдәӣжӯ»зҡ„й…ҚзҪ®иө„жәҗеңЁйЎ№зӣ®еҗҜеҠЁзҡ„ж—¶еҖҷеҠ й”ҒеҲ° JVM еҶ…еӯҳйҮҢйқўеҺ»пјҢиҝҷж ·иҜ·жұӮеңЁжӢҝиҝҷдәӣе…ұдә«й…ҚзҪ®иө„жәҗж—¶пјҢе°ұеҸҜзӣҙжҺҘд»ҺеҶ…еӯҳйҮҢйқўжӢҝпјҢдёҚеҝ…жҜҸж¬ЎйғҪд»Һж•°жҚ®еә“дёӯжӢҝпјҢеҮҸе°‘дәҶж—¶й—ҙејҖй”ҖгҖӮ
дёҖиҲ¬иҝҷж ·зҡ„е…ұдә«иө„жәҗжңүпјҡжӯ»зҡ„дёҡеҠЎжөҒзЁӢй…ҚзҪ® + жӯ»зҡ„дёҡеҠЎи§„еҲҷй…ҚзҪ®гҖӮ
е…ұдә«иө„жәҗеҲқе§ӢеҢ–зҡ„жӯҘйӘӨдёҖиҲ¬дёәпјҡйЎ№зӣ®еҗҜеҠЁ -> и§ҰеҸ‘еҲқе§ӢеҢ–еҠЁдҪң ->еҚ•зәҝзЁӢд»Һж•°жҚ®еә“дёӯжҚһеҸ–ж•°жҚ® -> з»„иЈ…жҲҗжҲ‘们йңҖиҰҒзҡ„ж•°жҚ®з»“жһ„ -> ж”ҫеҲ° JVM еҶ…еӯҳдёӯгҖӮ
еңЁйЎ№зӣ®еҗҜеҠЁж—¶пјҢдёәдәҶйҳІжӯўе…ұдә«иө„жәҗиў«еӨҡж¬ЎеҠ иҪҪпјҢжҲ‘们еҫҖеҫҖдјҡеҠ дёҠжҺ’е®ғй”ҒпјҢи®©дёҖдёӘзәҝзЁӢеҠ иҪҪе…ұдә«иө„жәҗе®ҢжҲҗд№ӢеҗҺпјҢеҸҰеӨ–дёҖдёӘзәҝзЁӢжүҚиғҪ继з»ӯеҠ иҪҪпјҢжӯӨж—¶зҡ„жҺ’е®ғй”ҒжҲ‘们еҸҜд»ҘйҖүжӢ© synchronized жҲ–иҖ… ReentrantLockпјҢжҲ‘们д»Ҙ synchronized дёәдҫӢпјҢеҶҷдәҶ mock зҡ„д»Јз ҒпјҢеҰӮдёӢпјҡ
// е…ұдә«иө„жәҗ
private static final Map<String, String> SHARED_MAP = Maps.newConcurrentMap();
// жңүж— еҲқе§ӢеҢ–е®ҢжҲҗзҡ„ж Үеҝ—дҪҚ
private static boolean loaded = false;
/**
* еҲқе§ӢеҢ–е…ұдә«иө„жәҗ
*/
@PostConstruct
public void init(){
if(loaded){
return;
}
synchronized (this){
// еҶҚж¬Ў check
if(loaded){
return;
}
log.info("SynchronizedDemo init begin");
// д»Һж•°жҚ®еә“дёӯжҚһеҸ–ж•°жҚ®пјҢз»„иЈ…жҲҗ SHARED_MAP зҡ„ж•°жҚ®ж јејҸ
loaded = true;
log.info("SynchronizedDemo init end");
}
}дёҚзҹҘйҒ“еӨ§е®¶жңүжІЎжңүд»ҺдёҠиҝ°д»Јз ҒдёӯеҸ‘зҺ° @PostConstruct жіЁи§ЈпјҢ@PostConstruct жіЁи§Јзҡ„дҪңз”ЁжҳҜеңЁ Spring е®№еҷЁеҲқе§ӢеҢ–ж—¶пјҢеҶҚжү§иЎҢиҜҘжіЁи§Јжү“дёҠзҡ„ж–№жі•пјҢд№ҹе°ұжҳҜиҜҙдёҠеӣҫиҜҙзҡ„ init ж–№жі•и§ҰеҸ‘зҡ„ж—¶жңәпјҢжҳҜеңЁ Spring е®№еҷЁеҗҜеҠЁзҡ„ж—¶еҖҷгҖӮ
еӨ§е®¶еҸҜд»ҘдёӢиҪҪжј”зӨәд»Јз ҒпјҢжүҫеҲ° DemoApplication еҗҜеҠЁж–Ү件пјҢеңЁ DemoApplication ж–Ү件дёҠеҸіеҮ» runпјҢе°ұеҸҜд»ҘеҗҜеҠЁж•ҙдёӘ Spring Boot йЎ№зӣ®пјҢеңЁ init ж–№жі•дёҠжү“дёҠж–ӯзӮ№е°ұеҸҜд»Ҙи°ғиҜ•дәҶгҖӮ
жҲ‘们еңЁд»Јз ҒдёӯдҪҝз”ЁдәҶ synchronized жқҘдҝқиҜҒеҗҢдёҖж—¶еҲ»пјҢеҸӘжңүдёҖдёӘзәҝзЁӢеҸҜд»Ҙжү§иЎҢеҲқе§ӢеҢ–е…ұдә«иө„жәҗзҡ„ж“ҚдҪңпјҢ并且жҲ‘们еҠ дәҶдёҖдёӘе…ұдә«иө„жәҗеҠ иҪҪе®ҢжҲҗзҡ„ж ҮиҜҶдҪҚпјҲloadedпјүпјҢжқҘеҲӨж–ӯжҳҜеҗҰеҠ иҪҪе®ҢжҲҗдәҶпјҢеҰӮжһңеҠ иҪҪе®ҢжҲҗпјҢйӮЈд№Ҳе…¶е®ғеҠ иҪҪзәҝзЁӢзӣҙжҺҘиҝ”еӣһгҖӮ
еҰӮжһңжҠҠ synchronized жҚўжҲҗ ReentrantLock д№ҹжҳҜдёҖж ·зҡ„е®һзҺ°пјҢеҸӘдёҚиҝҮйңҖиҰҒжҳҫзӨәзҡ„дҪҝз”Ё ReentrantLock зҡ„ API иҝӣиЎҢеҠ й”Ғе’ҢйҮҠж”ҫй”ҒпјҢдҪҝз”Ё ReentrantLock жңүдёҖзӮ№йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢжҲ‘们йңҖиҰҒеңЁ try ж–№жі•еқ—дёӯеҠ й”ҒпјҢеңЁ finally ж–№жі•еқ—дёӯйҮҠж”ҫй”ҒпјҢиҝҷж ·дҝқиҜҒеҚідҪҝ try дёӯеҠ й”ҒеҗҺеҸ‘з”ҹејӮеёёпјҢеңЁ finally дёӯд№ҹеҸҜд»ҘжӯЈзЎ®зҡ„йҮҠж”ҫй”ҒгҖӮ
жңүзҡ„еҗҢеӯҰеҸҜиғҪдјҡй—®пјҢдёҚжҳҜеҸҜд»ҘзӣҙжҺҘдҪҝз”ЁдәҶ ConcurrentHashMap д№ҲпјҢдёәд»Җд№ҲиҝҳйңҖиҰҒеҠ й”Ғе‘ўпјҹзҡ„зЎ® ConcurrentHashMap жҳҜзәҝзЁӢе®үе…Ёзҡ„пјҢдҪҶе®ғеҸӘиғҪеӨҹдҝқиҜҒ Map еҶ…йғЁж•°жҚ®ж“ҚдҪңж—¶зҡ„зәҝзЁӢе®үе…ЁпјҢжҳҜж— жі•дҝқиҜҒеӨҡзәҝзЁӢжғ…еҶөдёӢпјҢжҹҘиҜўж•°жҚ®еә“并组装数жҚ®зҡ„ж•ҙдёӘеҠЁдҪңеҸӘжү§иЎҢдёҖж¬Ўзҡ„пјҢжҲ‘们еҠ synchronized й”ҒдҪҸзҡ„жҳҜж•ҙдёӘж“ҚдҪңпјҢдҝқиҜҒж•ҙдёӘж“ҚдҪңеҸӘжү§иЎҢдёҖж¬ЎгҖӮ
2гҖҒCountDownLatch
2.1гҖҒеңәжҷҜ
1пјҡе°ҸжҳҺеңЁж·ҳе®қдёҠд№°дәҶдёҖдёӘе•Ҷе“ҒпјҢи§үеҫ—дёҚеҘҪпјҢжҠҠиҝҷдёӘе•Ҷе“ҒйҖҖжҺү(е•Ҷе“ҒиҝҳжІЎжңүеҸ‘иҙ§пјҢеҸӘйҖҖй’ұ)пјҢжҲ‘们еҸ«еҒҡеҚ•е•Ҷе“ҒйҖҖж¬ҫпјҢеҚ•е•Ҷе“ҒйҖҖж¬ҫеңЁеҗҺеҸ°зі»з»ҹдёӯиҝҗиЎҢж—¶пјҢж•ҙдҪ“иҖ—ж—¶ 30 жҜ«з§’гҖӮ
2пјҡеҸҢ 11пјҢе°ҸжҳҺеңЁж·ҳе®қдёҠд№°дәҶ 40 дёӘе•Ҷе“ҒпјҢз”ҹжҲҗдәҶеҗҢдёҖдёӘи®ўеҚ•пјҲе®һйҷ…еҸҜиғҪдјҡз”ҹжҲҗеӨҡдёӘи®ўеҚ•пјҢдёәдәҶж–№дҫҝжҸҸиҝ°пјҢжҲ‘们иҜҙжҲҗдёҖдёӘпјүпјҢ第дәҢеӨ©е°ҸжҳҺеҸ‘зҺ°е…¶дёӯ 30 дёӘе•Ҷе“ҒжҳҜиҮӘе·ұеҶІеҠЁж¶Ҳиҙ№зҡ„пјҢйңҖиҰҒжҠҠ 30 дёӘе•Ҷе“ҒдёҖиө·йҖҖжҺүгҖӮ
2.2гҖҒе®һзҺ°
жӯӨж—¶еҗҺеҸ°еҸӘжңүеҚ•е•Ҷе“ҒйҖҖж¬ҫзҡ„еҠҹиғҪпјҢжІЎжңүжү№йҮҸе•Ҷе“ҒйҖҖж¬ҫзҡ„еҠҹиғҪпјҲ30 дёӘе•Ҷе“ҒдёҖж¬ЎйҖҖжҲ‘们称дёәжү№йҮҸпјүпјҢдёәдәҶеҝ«йҖҹе®һзҺ°иҝҷдёӘеҠҹиғҪпјҢеҗҢеӯҰ A жҢүз…§иҝҷж ·зҡ„ж–№жЎҲеҒҡзҡ„пјҡfor еҫӘзҺҜи°ғз”Ё 30 ж¬ЎеҚ•е•Ҷе“ҒйҖҖж¬ҫзҡ„жҺҘеҸЈпјҢеңЁ qa зҺҜеўғжөӢиҜ•зҡ„ж—¶еҖҷеҸ‘зҺ°пјҢеҰӮжһңиҰҒйҖҖж¬ҫ 30 дёӘе•Ҷе“Ғзҡ„иҜқпјҢйңҖиҰҒиҖ—ж—¶пјҡ30 * 30 = 900 жҜ«з§’пјҢеҶҚеҠ дёҠе…¶е®ғзҡ„йҖ»иҫ‘пјҢйҖҖж¬ҫ 30 дёӘе•Ҷе“Ғе·®дёҚеӨҡйңҖиҰҒ 1 з§’дәҶпјҢиҝҷдёӘиҖ—ж—¶е…¶е®һз®—еҫҲд№…дәҶпјҢеҪ“ж—¶еҗҢеӯҰ A жҸҗеҮәдәҶиҝҷдёӘй—®йўҳпјҢеёҢжңӣеӨ§е®¶её®еҝҷзңӢзңӢеҰӮдҪ•дјҳеҢ–ж•ҙдёӘеңәжҷҜзҡ„иҖ—ж—¶гҖӮ
еҗҢеӯҰ B еҪ“ж—¶е°ұжҸҗеҮәпјҢдҪ еҸҜд»ҘдҪҝз”ЁзәҝзЁӢжұ иҝӣиЎҢжү§иЎҢе‘ҖпјҢжҠҠд»»еҠЎйғҪжҸҗдәӨеҲ°зәҝзЁӢжұ йҮҢйқўеҺ»пјҢеҒҮеҰӮжңәеҷЁзҡ„ CPU жҳҜ 4 ж ёзҡ„пјҢжңҖеӨҡеҗҢж—¶иғҪжңү 4 дёӘеҚ•е•Ҷе“ҒйҖҖж¬ҫеҸҜд»ҘеҗҢж—¶жү§иЎҢпјҢеҗҢеӯҰ A и§үеҫ—еҫҲжңүйҒ“зҗҶпјҢдәҺжҳҜеҮҶеӨҮдҝ®ж”№ж–№жЎҲпјҢдёәдәҶдҫҝдәҺзҗҶи§ЈпјҢжҲ‘们жҠҠдёӨдёӘж–№жЎҲйғҪз”»еҮәжқҘпјҢеҜ№жҜ”дёҖдёӢпјҡ
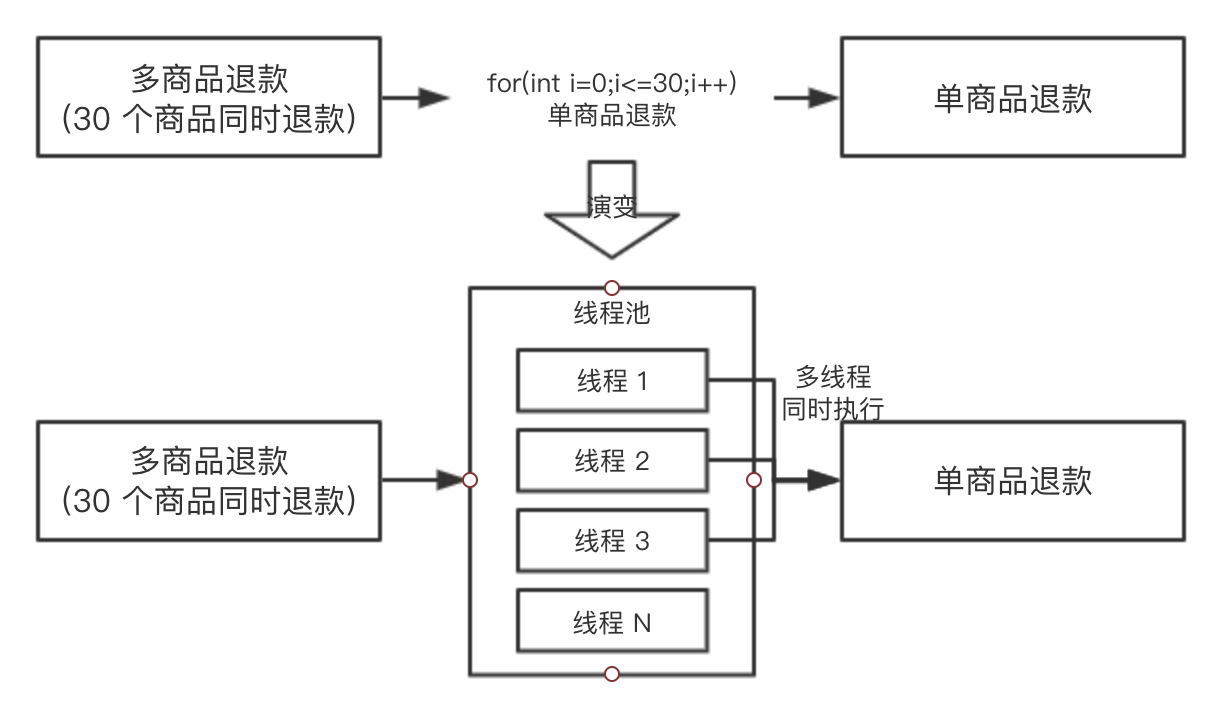
еҗҢеӯҰ A дәҺжҳҜе°ұжҢүз…§жј”еҸҳзҡ„ж–№жЎҲеҺ»еҶҷд»Јз ҒдәҶпјҢиҝҮдәҶдёҖеӨ©пјҢжҠӣеҮәдәҶдёҖдёӘй—®йўҳпјҡеҗ‘зәҝзЁӢжұ жҸҗдәӨдәҶ 30 дёӘд»»еҠЎеҗҺпјҢдё»зәҝзЁӢеҰӮдҪ•зӯүеҫ… 30 дёӘд»»еҠЎйғҪжү§иЎҢе®ҢжҲҗе‘ўпјҹеӣ дёәдё»зәҝзЁӢйңҖиҰҒ收йӣҶ 30 дёӘеӯҗд»»еҠЎзҡ„жү§иЎҢжғ…еҶөпјҢ并жұҮжҖ»иҝ”еӣһз»ҷеүҚз«ҜгҖӮ
еӨ§е®¶еҸҜд»Ҙе…ҲдёҚеҫҖдёӢзңӢпјҢиҮӘе·ұе…ҲжҖқиҖғдёҖдёӢпјҢжҲ‘们еүҚеҮ з« иҜҙзҡ„йӮЈз§Қй”ҒеҸҜд»Ҙеё®еҠ©и§ЈеҶіиҝҷдёӘй—®йўҳпјҹ
CountDownLatch еҸҜд»Ҙзҡ„пјҢCountDownLatch е…·жңүиҝҷз§ҚеҠҹиғҪпјҢи®©дё»зәҝзЁӢеҺ»зӯүеҫ…еӯҗд»»еҠЎе…ЁйғЁжү§иЎҢе®ҢжҲҗд№ӢеҗҺжүҚ继з»ӯжү§иЎҢгҖӮ
жӯӨж—¶иҝҳжңүдёҖдёӘе…ій”®пјҢжҲ‘们йңҖиҰҒзҹҘйҒ“еӯҗзәҝзЁӢжү§иЎҢзҡ„з»“жһңпјҢжүҖд»ҘжҲ‘们用 Runnable дҪңдёәзәҝзЁӢд»»еҠЎе°ұдёҚиЎҢдәҶпјҢеӣ дёә Runnable жҳҜжІЎжңүиҝ”еӣһеҖјзҡ„пјҢжҲ‘们йңҖиҰҒйҖүжӢ© Callable дҪңдёәд»»еҠЎгҖӮ
жҲ‘们еҶҷдәҶдёҖдёӘ demoпјҢйҰ–е…ҲжҲ‘们жқҘзңӢдёҖдёӢеҚ•дёӘе•Ҷе“ҒйҖҖж¬ҫзҡ„д»Јз Ғпјҡ
// еҚ•е•Ҷе“ҒйҖҖж¬ҫпјҢиҖ—ж—¶ 30 жҜ«з§’пјҢйҖҖж¬ҫжҲҗеҠҹиҝ”еӣһ trueпјҢеӨұиҙҘиҝ”еӣһ false
@Slf4j
public class RefundDemo {
/**
* ж №жҚ®е•Ҷе“Ғ ID иҝӣиЎҢйҖҖж¬ҫ
* @param itemId
* @return
*/
public boolean refundByItem(Long itemId) {
try {
// зәҝзЁӢжІүзқЎ 30 жҜ«з§’пјҢжЁЎжӢҹеҚ•дёӘе•Ҷе“ҒйҖҖж¬ҫиҝҮзЁӢ
Thread.sleep(30);
log.info("refund success,itemId is {}", itemId);
return true;
} catch (Exception e) {
log.error("refundByItemError,itemId is {}", itemId);
return false;
}
}
}жҺҘзқҖжҲ‘们зңӢдёӢ 30 дёӘе•Ҷе“Ғзҡ„жү№йҮҸйҖҖж¬ҫпјҢд»Јз ҒеҰӮдёӢпјҡ
@Slf4j
public class BatchRefundDemo {
// е®ҡд№үзәҝзЁӢжұ
public static final ExecutorService EXECUTOR_SERVICE =
new ThreadPoolExecutor(10, 10, 0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(20));
@Test
public void batchRefund() throws InterruptedException {
// state еҲқе§ӢеҢ–дёә 30
CountDownLatch countDownLatch = new CountDownLatch(30);
RefundDemo refundDemo = new RefundDemo();
// еҮҶеӨҮ 30 дёӘе•Ҷе“Ғ
List<Long> items = Lists.newArrayListWithCapacity(30);
for (int i = 0; i < 30; i++) {
items.add(Long.valueOf(i+""));
}
// еҮҶеӨҮејҖе§Ӣжү№йҮҸйҖҖж¬ҫ
List<Future> futures = Lists.newArrayListWithCapacity(30);
for (Long item : items) {
// дҪҝз”Ё CallableпјҢеӣ дёәжҲ‘们йңҖиҰҒзӯүеҲ°иҝ”еӣһеҖј
Future<Boolean> future = EXECUTOR_SERVICE.submit(new Callable<Boolean>() {
@Override
public Boolean call() throws Exception {
boolean result = refundDemo.refundByItem(item);
// жҜҸдёӘеӯҗзәҝзЁӢйғҪдјҡжү§иЎҢ countDownпјҢдҪҝ state -1 пјҢдҪҶеҸӘжңүжңҖеҗҺдёҖдёӘжүҚиғҪзңҹзҡ„е”ӨйҶ’дё»зәҝзЁӢ
countDownLatch.countDown();
return result;
}
});
// 收йӣҶжү№йҮҸйҖҖж¬ҫзҡ„з»“жһң
futures.add(future);
}
log.info("30 дёӘе•Ҷе“Ғе·Із»ҸеңЁйҖҖж¬ҫдёӯ");
// дҪҝдё»зәҝзЁӢйҳ»еЎһпјҢдёҖзӣҙзӯүеҫ… 30 дёӘе•Ҷе“ҒйғҪйҖҖж¬ҫе®ҢжҲҗпјҢжүҚиғҪ继з»ӯжү§иЎҢ
countDownLatch.await();
log.info("30 дёӘе•Ҷе“Ғе·Із»ҸйҖҖж¬ҫе®ҢжҲҗ");
// жӢҝеҲ°жүҖжңүз»“жһңиҝӣиЎҢеҲҶжһҗ
List<Boolean> result = futures.stream().map(fu-> {
try {
// get зҡ„и¶…ж—¶ж—¶й—ҙи®ҫзҪ®зҡ„жҳҜ 1 жҜ«з§’пјҢжҳҜдёәдәҶиҜҙжҳҺжӯӨж—¶жүҖжңүзҡ„еӯҗзәҝзЁӢйғҪе·Із»Ҹжү§иЎҢе®ҢжҲҗдәҶ
return (Boolean) fu.get(1,TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
return false;
}).collect(Collectors.toList());
// жү“еҚ°з»“жһңз»ҹи®Ў
long success = result.stream().filter(r->r.equals(true)).count();
log.info("жү§иЎҢз»“жһңжҲҗеҠҹ{},еӨұиҙҘ{}",success,result.size()-success);
}
}дёҠиҝ°д»Јз ҒеҸӘжҳҜеӨ§жҰӮзҡ„еә•еұӮжҖқи·ҜпјҢзңҹе®һзҡ„йЎ№зӣ®дјҡеңЁжӯӨжҖқи·Ҝд№ӢдёҠеҠ дёҠиҜ·жұӮеҲҶз»„пјҢи¶…ж—¶жү“ж–ӯзӯүзӯүдјҳеҢ–жҺӘж–ҪгҖӮ
жҲ‘们жқҘзңӢдёҖдёӢжү§иЎҢзҡ„з»“жһң:
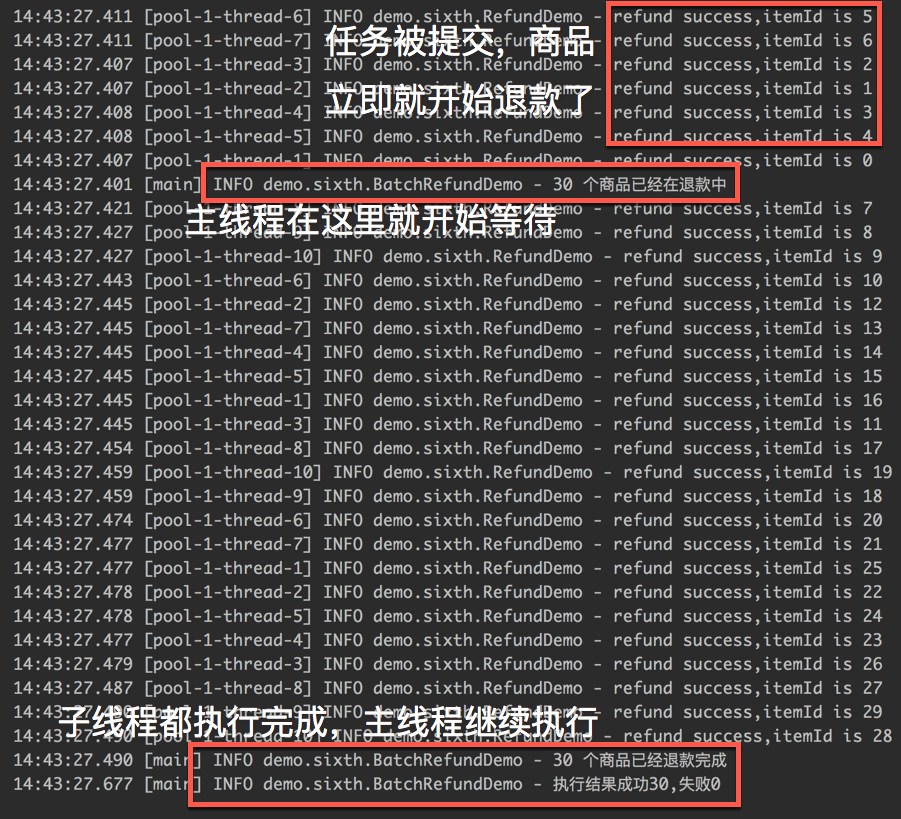
д»Һжү§иЎҢзҡ„жҲӘеӣҫдёӯпјҢжҲ‘们еҸҜд»ҘжҳҺжҳҫзҡ„зңӢеҲ° CountDownLatch е·Із»ҸеҸ‘жҢҘеҮәдәҶдҪңз”ЁпјҢдё»зәҝзЁӢдјҡдёҖзӣҙзӯүеҲ° 30 дёӘе•Ҷе“Ғзҡ„йҖҖж¬ҫз»“жһңд№ӢеҗҺжүҚдјҡ继з»ӯжү§иЎҢгҖӮ
жҺҘзқҖжҲ‘们еҒҡдәҶдёҖдёӘдёҚдёҘи°Ёзҡ„е®һйӘҢпјҲжҠҠд»ҘдёҠд»Јз Ғжү§иЎҢеҫҲеӨҡж¬ЎпјҢжұӮиҖ—ж—¶е№іеқҮеҖјпјүпјҢйҖҡиҝҮд»ҘдёҠд»Јз ҒпјҢ30 дёӘе•Ҷе“ҒйҖҖж¬ҫе®ҢжҲҗд№ӢеҗҺпјҢж•ҙдҪ“иҖ—ж—¶еӨ§жҰӮеңЁ 200 жҜ«з§’е·ҰеҸігҖӮ
иҖҢйҖҡиҝҮ for еҫӘзҺҜеҚ•е•Ҷе“ҒиҝӣиЎҢйҖҖж¬ҫпјҢеӨ§жҰӮиҖ—ж—¶еңЁ 1 з§’е·ҰеҸіпјҢеүҚеҗҺжҖ§иғҪзӣёе·® 5 еҖҚе·ҰеҸіпјҢfor еҫӘзҺҜйҖҖж¬ҫзҡ„д»Јз ҒеҰӮдёӢпјҡ
long begin1 = System.currentTimeMillis();
for (Long item : items) {
refundDemo.refundByItem(item);
}
log.info("for еҫӘзҺҜеҚ•дёӘйҖҖж¬ҫиҖ—ж—¶{}",System.currentTimeMillis()-begin1); жҖ§иғҪзҡ„е·ЁеӨ§жҸҗеҚҮжҳҜзәҝзЁӢжұ + й”ҒдёӨиҖ…з»“еҗҲзҡ„еҠҹеҠігҖӮ
д»ҘдёҠе°ұжҳҜвҖңJavaй”ҒеңЁе·ҘдҪңдёӯдҪҝз”ЁеңәжҷҜе®һдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« йғҪжңүеҫҲеӨ§зҡ„收иҺ·пјҢе°Ҹзј–жҜҸеӨ©йғҪдјҡдёәеӨ§е®¶жӣҙж–°дёҚеҗҢзҡ„зҹҘиҜҶпјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҡ„зҹҘиҜҶпјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





