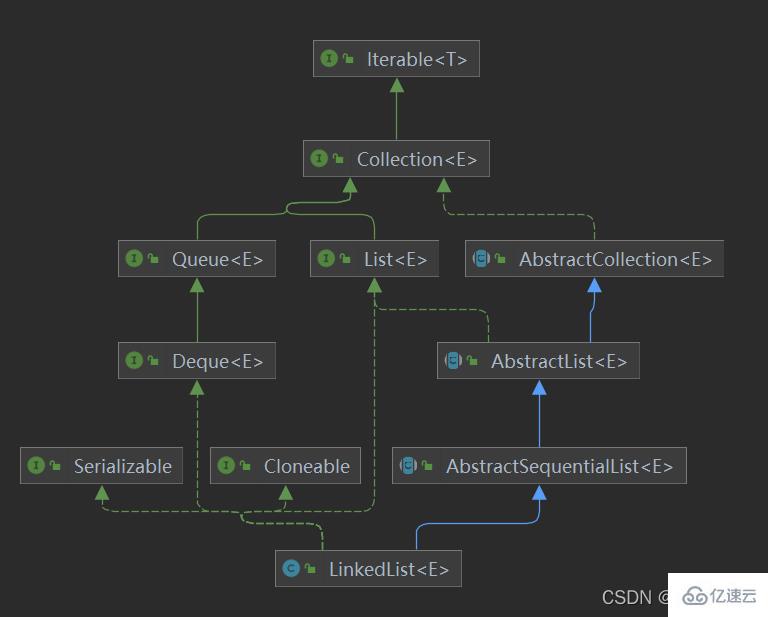
JavaйӣҶеҗҲжЎҶжһ¶жҳҜд»Җд№Ҳ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶJavaйӣҶеҗҲжЎҶжһ¶жҳҜд»Җд№ҲпјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« д№ӢеҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©е°Ҹзј–еёҰзқҖеӨ§е®¶дёҖиө·дәҶи§ЈдёҖдёӢгҖӮ
дёҖгҖҒз®Җд»Ӣ
1гҖҒйӣҶеҗҲжЎҶжһ¶д»Ӣз»Қ
JavaйӣҶеҗҲжЎҶжһ¶жҸҗдҫӣдәҶдёҖеҘ—жҖ§иғҪдјҳиүҜпјҢдҪҝз”Ёж–№дҫҝзҡ„жҺҘеҸЈе’Ңзұ»пјҢ他们дҪҚдәҺjava.utilеҢ…дёӯгҖӮе®№еҷЁдё»иҰҒеҢ…жӢ¬ Collection е’Ң Map дёӨз§ҚпјҢCollection еӯҳеӮЁзқҖеҜ№иұЎзҡ„йӣҶеҗҲпјҢиҖҢ Map еӯҳеӮЁзқҖй”®еҖјеҜ№(дёӨдёӘеҜ№иұЎ)зҡ„жҳ е°„иЎЁ
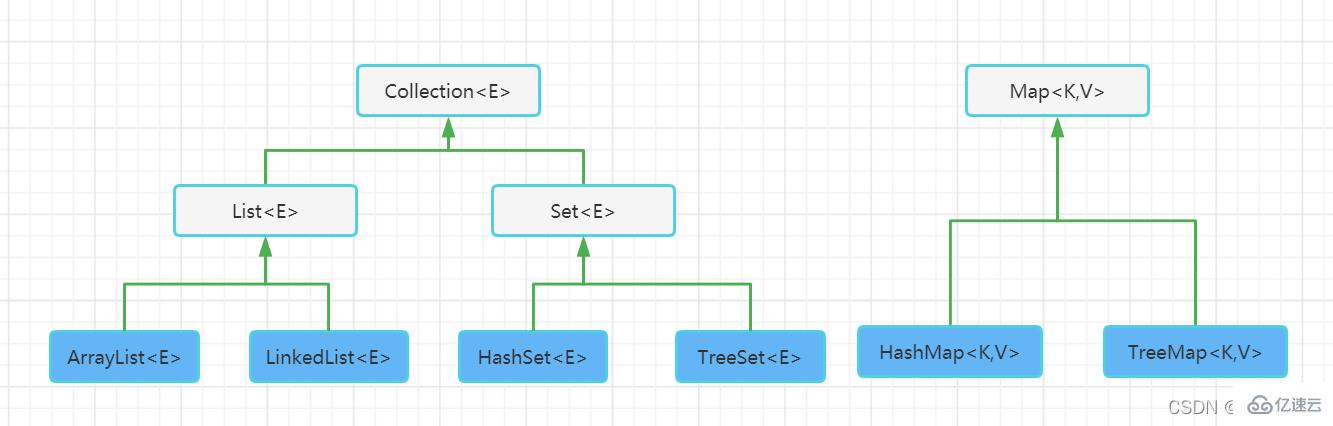
2гҖҒзӣёе…іе®№еҷЁд»Ӣз»Қ
2.1 Setзӣёе…і
TreeSet
еҹәдәҺзәўй»‘ж ‘е®һзҺ°пјҢж”ҜжҢҒжңүеәҸжҖ§ж“ҚдҪңпјҢдҫӢеҰӮж №жҚ®дёҖдёӘиҢғеӣҙжҹҘжүҫе…ғзҙ зҡ„ж“ҚдҪңгҖӮдҪҶжҳҜжҹҘжүҫж•ҲзҺҮдёҚеҰӮ HashSetпјҢHashSet жҹҘжүҫзҡ„ж—¶й—ҙеӨҚжқӮеәҰдёә O(1)пјҢTreeSet еҲҷдёә O(logN)
HashSet
еҹәдәҺе“ҲеёҢиЎЁе®һзҺ°пјҢж”ҜжҢҒеҝ«йҖҹжҹҘжүҫпјҢдҪҶдёҚж”ҜжҢҒжңүеәҸжҖ§ж“ҚдҪңгҖӮ并且еӨұеҺ»дәҶе…ғзҙ зҡ„жҸ’е…ҘйЎәеәҸдҝЎжҒҜпјҢд№ҹе°ұжҳҜиҜҙдҪҝз”Ё Iterator йҒҚеҺҶ HashSet еҫ—еҲ°зҡ„з»“жһңжҳҜдёҚзЎ®е®ҡзҡ„гҖӮ
LinkedHashSet
е…·жңү HashSet зҡ„жҹҘжүҫж•ҲзҺҮпјҢдё”еҶ…йғЁдҪҝз”ЁеҸҢеҗ‘й“ҫиЎЁз»ҙжҠӨе…ғзҙ зҡ„жҸ’е…ҘйЎәеәҸгҖӮ
2.2 Listзӣёе…і
ArrayList
еҹәдәҺеҠЁжҖҒж•°з»„е®һзҺ°пјҢж”ҜжҢҒйҡҸжңәи®ҝй—®гҖӮ
Vector
е’Ң ArrayList зұ»дјјпјҢдҪҶе®ғжҳҜзәҝзЁӢе®үе…Ёзҡ„гҖӮ
LinkedList
еҹәдәҺеҸҢеҗ‘й“ҫиЎЁе®һзҺ°пјҢеҸӘиғҪйЎәеәҸи®ҝй—®пјҢдҪҶжҳҜеҸҜд»Ҙеҝ«йҖҹең°еңЁй“ҫиЎЁдёӯй—ҙжҸ’е…Ҙе’ҢеҲ йҷӨе…ғзҙ гҖӮдёҚд»…еҰӮжӯӨпјҢLinkedList иҝҳеҸҜд»Ҙз”ЁдҪңж ҲгҖҒйҳҹеҲ—е’ҢеҸҢеҗ‘йҳҹеҲ—гҖӮ
2.3 Queueзӣёе…і
2.4 Mapзӣёе…і
TreeMap
еҹәдәҺзәўй»‘ж ‘е®һзҺ°гҖӮ
HashMap
еҹәдәҺе“ҲеёҢиЎЁе®һзҺ°гҖӮ
HashTable
е’Ң HashMap зұ»дјјпјҢдҪҶе®ғжҳҜзәҝзЁӢе®үе…Ёзҡ„пјҢиҝҷж„Ҹе‘ізқҖеҗҢдёҖж—¶еҲ»еӨҡдёӘзәҝзЁӢеҸҜд»ҘеҗҢж—¶еҶҷе…Ҙ HashTable 并且дёҚдјҡеҜјиҮҙж•°жҚ®дёҚдёҖиҮҙгҖӮе®ғжҳҜйҒ—з•ҷзұ»пјҢдёҚеә”иҜҘеҺ»дҪҝз”Ёе®ғгҖӮзҺ°еңЁеҸҜд»ҘдҪҝз”Ё ConcurrentHashMap жқҘж”ҜжҢҒзәҝзЁӢе®үе…ЁпјҢ并且 ConcurrentHashMap зҡ„ж•ҲзҺҮдјҡжӣҙй«ҳпјҢеӣ дёә ConcurrentHashMap еј•е…ҘдәҶеҲҶж®өй”ҒгҖӮ
LinkedHashMap
дҪҝз”ЁеҸҢеҗ‘й“ҫиЎЁжқҘз»ҙжҠӨе…ғзҙ зҡ„йЎәеәҸпјҢйЎәеәҸдёәжҸ’е…ҘйЎәеәҸжҲ–иҖ…жңҖиҝ‘жңҖе°‘дҪҝз”Ё(LRU)йЎәеәҸ
3гҖҒйӣҶеҗҲйҮҚзӮ№
Collection жҺҘеҸЈеӯҳеӮЁдёҖз»„дёҚе”ҜдёҖпјҢж— еәҸзҡ„еҜ№иұЎ
List жҺҘеҸЈеӯҳеӮЁдёҖз»„дёҚе”ҜдёҖпјҢжңүеәҸзҡ„еҜ№иұЎгҖӮ
Set жҺҘеҸЈеӯҳеӮЁдёҖз»„е”ҜдёҖпјҢж— еәҸзҡ„еҜ№иұЎ
Map жҺҘеҸЈеӯҳеӮЁдёҖз»„й”®еҖјеҜ№иұЎпјҢжҸҗдҫӣkeyеҲ°valueзҡ„жҳ е°„
ArrayListе®һзҺ°дәҶй•ҝеәҰеҸҜеҸҳзҡ„ж•°з»„пјҢеңЁеҶ…еӯҳдёӯеҲҶй…Қиҝһз»ӯзҡ„з©әй—ҙгҖӮйҒҚеҺҶе…ғзҙ е’ҢйҡҸжңәи®ҝй—®е…ғзҙ зҡ„ж•ҲзҺҮжҜ”иҫғй«ҳ
LinkedListйҮҮз”Ёй“ҫиЎЁеӯҳеӮЁж–№ејҸгҖӮжҸ’е…ҘгҖҒеҲ йҷӨе…ғзҙ ж—¶ж•ҲзҺҮжҜ”иҫғй«ҳ
HashSetйҮҮз”Ёе“ҲеёҢз®—жі•е®һзҺ°зҡ„Set
HashSetзҡ„еә•еұӮжҳҜз”ЁHashMapе®һзҺ°зҡ„пјҢеӣ жӯӨжҹҘиҜўж•ҲзҺҮиҫғй«ҳпјҢз”ұдәҺйҮҮз”ЁhashCodeз®—жі•зӣҙжҺҘзЎ®е®ҡ е…ғзҙ зҡ„еҶ…еӯҳең°еқҖпјҢеўһеҲ ж•ҲзҺҮй«ҳ
дәҢгҖҒArrayListеҲҶжһҗ
1гҖҒArrayListдҪҝз”Ё
| ж–№жі• | иҜҙжҳҺ |
|---|
| boolean add(Object o) | еңЁеҲ—иЎЁзҡ„жң«е°ҫйЎәеәҸж·»еҠ е…ғзҙ пјҢиө·е§Ӣзҙўеј•дҪҚзҪ®д»Һ0ејҖе§Ӣ |
| void add(int index, Object o) | еңЁжҢҮе®ҡзҡ„зҙўеј•дҪҚзҪ®ж·»еҠ е…ғзҙ пјҢзҙўеј•дҪҚзҪ®еҝ…йЎ»д»ӢдәҺ0е’ҢеҲ—иЎЁдёӯе…ғзҙ дёӘж•°д№Ӣй—ҙ |
| int size() | иҝ”еӣһеҲ—иЎЁдёӯзҡ„е…ғзҙ дёӘж•° |
| Object get(int index) | иҝ”еӣһжҢҮе®ҡзҙўеј•дҪҚзҪ®еӨ„зҡ„е…ғзҙ гҖӮеҸ–еҮәзҡ„е…ғзҙ жҳҜObjectзұ»еһӢпјҢдҪҝз”ЁеүҚе“ҒиҰҒиҝӣиЎҢзӣҠеҲ¶зұ»еһӢиҪ¬жҚў |
| boolean contains(Object o) | еҲӨж–ӯеҲ—иЎЁдёӯжҳҜеҗҰеӯҳеңЁжҢҮе®ҡе…ғзҙ |
| boolean remove(Object o) | д»ҺеҲ—иЎЁдёӯеҲ йҷӨе…ғзҙ |
| Object remove(int indexпјү | д»ҺеҲ—иЎЁдёӯеҲ йҷӨжҢҮе®ҡдҪҚзҪ®е…ғзҙ пјҢиө·е§Ӣзҙўеј•дҪҚйҮҸд»Һ0ејҖе§Ӣ |
2гҖҒArrayListд»Ӣз»Қ
ArrayListжҳҜеҸҜд»ҘеҠЁжҖҒеўһй•ҝе’Ңзј©еҮҸзҡ„зҙўеј•еәҸеҲ—пјҢе®ғжҳҜеҹәдәҺж•°з»„е®һзҺ°зҡ„Listзұ»
иҜҘзұ»е°ҒиЈ…дәҶдёҖдёӘеҠЁжҖҒеҶҚеҲҶй…Қзҡ„Object[]ж•°з»„пјҢжҜҸдёҖдёӘзұ»еҜ№иұЎйғҪжңүдёҖдёӘcapacity[е®№йҮҸ]еұһжҖ§пјҢиЎЁзӨәе®ғ们жүҖе°ҒиЈ…зҡ„Object[]ж•°з»„зҡ„й•ҝеәҰпјҢеҪ“еҗ‘ArrayListдёӯж·»еҠ е…ғзҙ ж—¶пјҢиҜҘеұһжҖ§еҖјдјҡиҮӘеҠЁеўһеҠ гҖӮеҰӮжһңжғіArrayListдёӯж·»еҠ еӨ§йҮҸе…ғзҙ пјҢеҸҜдҪҝз”ЁensureCapacityж–№жі•дёҖж¬ЎжҖ§еўһеҠ capacityпјҢеҸҜд»ҘеҮҸе°‘еўһеҠ йҮҚеҲҶй…Қзҡ„ж¬Ўж•°жҸҗй«ҳжҖ§иғҪ
ArrayListзҡ„з”Ёжі•е’ҢVectorеҗ‘зұ»дјјпјҢдҪҶжҳҜVectorжҳҜдёҖдёӘиҫғиҖҒзҡ„йӣҶеҗҲпјҢе…·жңүеҫҲеӨҡзјәзӮ№пјҢдёҚе»әи®®дҪҝз”Ё
еҸҰеӨ–пјҢArrayListе’ҢVectorзҡ„еҢәеҲ«жҳҜпјҡArrayListжҳҜзәҝзЁӢдёҚе®үе…Ёзҡ„пјҢеҪ“еӨҡжқЎзәҝзЁӢи®ҝй—®еҗҢдёҖдёӘArrayListйӣҶеҗҲж—¶пјҢзЁӢеәҸйңҖиҰҒжүӢеҠЁдҝқиҜҒиҜҘйӣҶеҗҲзҡ„еҗҢжӯҘжҖ§пјҢиҖҢVectorеҲҷжҳҜзәҝзЁӢе®үе…Ёзҡ„гҖӮ
3гҖҒжәҗз ҒеҲҶжһҗ
3.1 继жүҝз»“жһ„дёҺеұӮж¬Ўе…ізі»
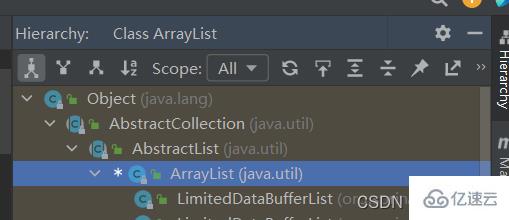
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
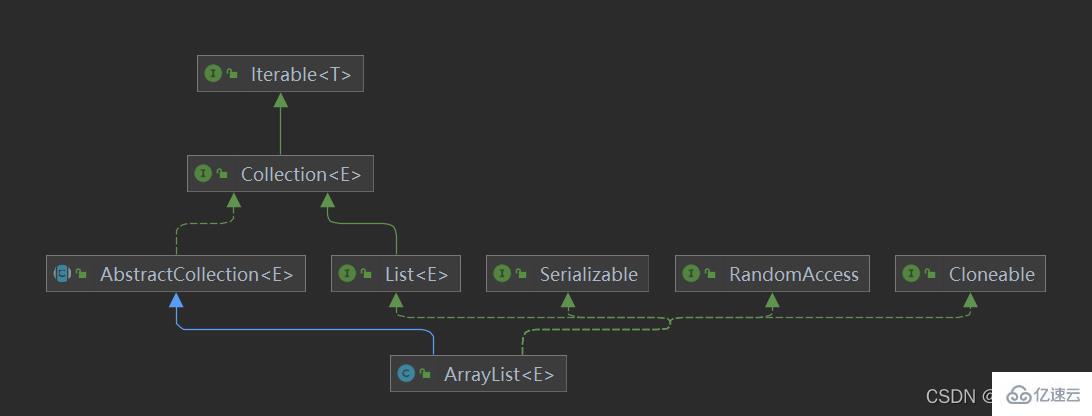
иҝҷйҮҢз®ҖеҚ•и§ЈйҮҠдёҖдёӢеҮ дёӘжҺҘеҸЈ
RandomAccessжҺҘеҸЈ
иҝҷдёӘжҳҜдёҖдёӘж Үи®°жҖ§жҺҘеҸЈпјҢйҖҡиҝҮжҹҘзңӢapiж–ҮжЎЈпјҢе®ғзҡ„дҪңз”Ёе°ұжҳҜз”ЁжқҘеҝ«йҖҹйҡҸжңәеӯҳеҸ–пјҢжңүе…іж•ҲзҺҮзҡ„й—®йўҳпјҢеңЁе®һзҺ°дәҶиҜҘжҺҘеҸЈзҡ„иҜқпјҢйӮЈд№ҲдҪҝз”Ёжҷ®йҖҡзҡ„forеҫӘзҺҜжқҘйҒҚеҺҶпјҢжҖ§иғҪжӣҙй«ҳпјҢдҫӢеҰӮArrayListгҖӮиҖҢжІЎжңүе®һзҺ°иҜҘжҺҘеҸЈзҡ„иҜқпјҢдҪҝз”ЁIteratorжқҘиҝӯд»ЈпјҢиҝҷж ·жҖ§иғҪжӣҙй«ҳпјҢдҫӢеҰӮlinkedListгҖӮжүҖд»ҘиҝҷдёӘж Үи®°жҖ§еҸӘжҳҜдёәдәҶ и®©жҲ‘们зҹҘйҒ“жҲ‘们用д»Җд№Ҳж ·зҡ„ж–№ејҸеҺ»иҺ·еҸ–ж•°жҚ®жҖ§иғҪжӣҙеҘҪгҖӮ
CloneableжҺҘеҸЈ
е®һзҺ°дәҶиҜҘжҺҘеҸЈпјҢе°ұеҸҜд»ҘдҪҝз”ЁObject.Clone()ж–№жі•дәҶгҖӮ
SerializableжҺҘеҸЈ
е®һзҺ°иҜҘеәҸеҲ—еҢ–жҺҘеҸЈпјҢиЎЁжҳҺиҜҘзұ»еҸҜд»Ҙиў«еәҸеҲ—еҢ–гҖӮд»Җд№ҲжҳҜеәҸеҲ—еҢ–пјҹз®ҖеҚ•зҡ„иҜҙпјҢе°ұжҳҜиғҪеӨҹд»Һзұ»еҸҳжҲҗеӯ—иҠӮжөҒдј иҫ“пјҢ然еҗҺиҝҳиғҪд»Һеӯ—иҠӮжөҒеҸҳжҲҗеҺҹжқҘзҡ„зұ»гҖӮ
иҝҷйҮҢзҡ„继жүҝз»“жһ„еҸҜйҖҡиҝҮIDEAдёӯNavigate>Type HierarchyжҹҘзңӢ
3.2 еұһжҖ§
//зүҲжң¬еҸ·
private static final long serialVersionUID = 8683452581122892189L;
//зјәзңҒе®№йҮҸ
private static final int DEFAULT_CAPACITY = 10;
//з©әеҜ№иұЎж•°з»„
private static final Object[] EMPTY_ELEMENTDATA = {};
//зјәзңҒз©әеҜ№иұЎж•°з»„
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//еӯҳеӮЁзҡ„ж•°з»„е…ғзҙ
transient Object[] elementData; // non-private to simplify nested class access
//е®һйҷ…е…ғзҙ еӨ§е°ҸпјҢй»ҳи®Өдёә0
private int size;
//жңҖеӨ§ж•°з»„е®№йҮҸ
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;3.3 жһ„йҖ ж–№жі•
/**
* жһ„йҖ е…·жңүжҢҮе®ҡеҲқе§Ӣе®№йҮҸзҡ„з©әеҲ—иЎЁ
* еҰӮжһңжҢҮе®ҡзҡ„еҲқе§Ӣе®№йҮҸдёәиҙҹпјҢеҲҷдёәIllegalArgumentException
*/public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}}/**
* й»ҳи®Өз©әж•°з»„зҡ„еӨ§е°Ҹдёә10
* ArrayListдёӯеӮЁеӯҳж•°жҚ®зҡ„е…¶е®һе°ұжҳҜдёҖдёӘж•°з»„пјҢиҝҷдёӘж•°з»„е°ұжҳҜelementData
*/public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}/**
* жҢүз…§йӣҶеҗҲиҝӯд»ЈеҷЁиҝ”еӣһе…ғзҙ зҡ„йЎәеәҸжһ„йҖ еҢ…еҗ«жҢҮе®ҡйӣҶеҗҲзҡ„е…ғзҙ зҡ„еҲ—иЎЁ
*/public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// иҪ¬жҚўдёәж•°з»„
//жҜҸдёӘйӣҶеҗҲзҡ„toarray()зҡ„е®һзҺ°ж–№жі•дёҚдёҖж ·пјҢжүҖд»ҘйңҖиҰҒеҲӨж–ӯдёҖдёӢпјҢеҰӮжһңдёҚжҳҜObject[].classзұ»еһӢпјҢйӮЈд№Ҳд№…йңҖиҰҒдҪҝз”ЁArrayListдёӯзҡ„ж–№жі•еҺ»ж”№йҖ дёҖдёӢгҖӮ
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// еҗҰеҲҷе°ұз”Ёз©әж•°з»„д»Јжӣҝ
this.elementData = EMPTY_ELEMENTDATA;
}}3.4 иҮӘеҠЁжү©е®№
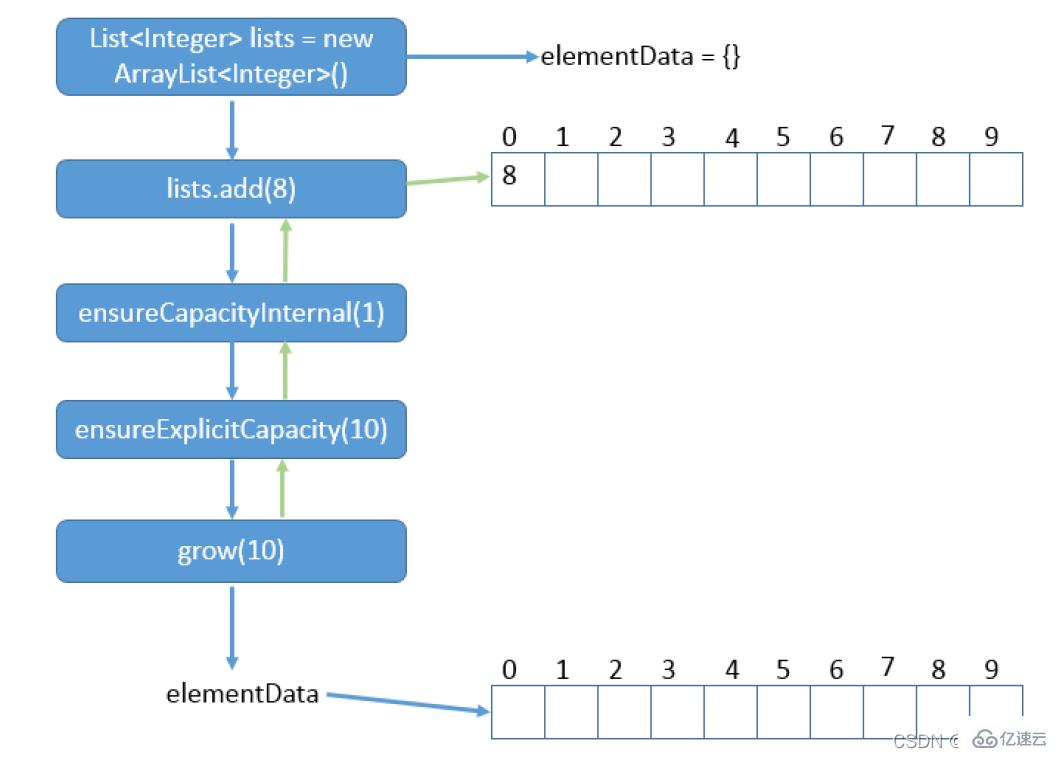
жҜҸеҪ“еҗ‘ж•°з»„дёӯж·»еҠ е…ғзҙ ж—¶пјҢйғҪиҰҒеҺ»жЈҖжҹҘж·»еҠ еҗҺе…ғзҙ зҡ„дёӘж•°жҳҜеҗҰдјҡи¶…еҮәеҪ“еүҚж•°з»„зҡ„й•ҝеәҰпјҢеҰӮжһңи¶…еҮәпјҢж•°з»„е°ҶдјҡиҝӣиЎҢжү©е®№пјҢд»Ҙж»Ўи¶іж·»еҠ ж•°жҚ®зҡ„йңҖжұӮгҖӮж•°з»„жү©е®№йҖҡиҝҮдёҖдёӘе…¬ејҖзҡ„ж–№жі•ensureCapacity(int minCapacity)жқҘе®һзҺ°гҖӮеңЁе®һйҷ…ж·»еҠ еӨ§йҮҸе…ғзҙ еүҚпјҢжҲ‘д№ҹеҸҜд»ҘдҪҝз”ЁensureCapacityжқҘжүӢеҠЁеўһеҠ ArrayListе®һдҫӢзҡ„е®№йҮҸпјҢд»ҘеҮҸе°‘йҖ’еўһејҸеҶҚеҲҶй…Қзҡ„ж•°йҮҸгҖӮ
ж•°з»„иҝӣиЎҢжү©е®№ж—¶пјҢдјҡе°Ҷ**иҖҒж•°з»„дёӯзҡ„е…ғзҙ йҮҚж–°жӢ·иҙқдёҖд»ҪеҲ°ж–°зҡ„ж•°з»„дёӯпјҢжҜҸж¬Ўж•°з»„е®№йҮҸзҡ„еўһй•ҝеӨ§зәҰжҳҜе…¶еҺҹе®№йҮҸзҡ„1.5еҖҚгҖӮ**иҝҷз§Қж“ҚдҪңзҡ„д»Јд»·жҳҜеҫҲй«ҳзҡ„пјҢеӣ жӯӨеңЁе®һйҷ…дҪҝз”Ёж—¶пјҢжҲ‘们еә”иҜҘе°ҪйҮҸйҒҝе…Қж•°з»„е®№йҮҸзҡ„жү©еј гҖӮеҪ“жҲ‘们еҸҜйў„зҹҘиҰҒдҝқеӯҳзҡ„е…ғзҙ зҡ„еӨҡе°‘ж—¶пјҢиҰҒеңЁжһ„йҖ ArrayListе®һдҫӢж—¶пјҢе°ұжҢҮе®ҡе…¶е®№йҮҸпјҢд»ҘйҒҝе…Қж•°з»„жү©е®№зҡ„еҸ‘з”ҹгҖӮжҲ–иҖ…ж №жҚ®е®һйҷ…йңҖжұӮпјҢйҖҡиҝҮи°ғз”ЁensureCapacityж–№жі•жқҘжүӢеҠЁеўһеҠ ArrayListе®һдҫӢзҡ„е®№йҮҸгҖӮ
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));}private static int calculateCapacity(Object[] elementData, int minCapacity) {
//еҲӨж–ӯеҲқе§ӢеҢ–зҡ„elementDataжҳҜдёҚжҳҜз©әзҡ„ж•°з»„пјҢд№ҹе°ұжҳҜжІЎжңүй•ҝеәҰ
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//еӣ дёәеҰӮжһңжҳҜз©әзҡ„иҜқпјҢminCapacity=size+1пјӣе…¶е®һе°ұжҳҜзӯүдәҺ1пјҢз©әзҡ„ж•°з»„жІЎжңүй•ҝеәҰе°ұеӯҳж”ҫдёҚдәҶ
//жүҖд»Ҙе°ұе°ҶminCapacityеҸҳжҲҗ10пјҢд№ҹе°ұжҳҜй»ҳи®ӨеӨ§е°ҸпјҢдҪҶжҳҜеңЁиҝҷйҮҢпјҢиҝҳжІЎжңүзңҹжӯЈзҡ„еҲқе§ӢеҢ–иҝҷдёӘelementDataзҡ„еӨ§е°Ҹ
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
//зЎ®и®Өе®һйҷ…зҡ„е®№йҮҸпјҢдёҠйқўеҸӘжҳҜе°ҶminCapacity=10пјҢиҝҷдёӘж–№жі•е°ұжҳҜзңҹжӯЈзҡ„еҲӨж–ӯelementDataжҳҜеҗҰеӨҹз”Ё
return minCapacity;}private void ensureExplicitCapacity(int minCapacity) {
modCount++;
//minCapacityеҰӮжһңеӨ§дәҺдәҶе®һйҷ…elementDataзҡ„й•ҝеәҰпјҢйӮЈд№Ҳе°ұиҜҙжҳҺelementDataж•°з»„зҡ„й•ҝеәҰдёҚеӨҹз”Ё
/*第дёҖз§Қжғ…еҶөпјҡз”ұдәҺelementDataеҲқе§ӢеҢ–ж—¶жҳҜз©әзҡ„ж•°з»„пјҢйӮЈд№Ҳ第дёҖж¬Ўaddзҡ„ж—¶еҖҷпјҢ
minCapacity=size+1пјӣд№ҹе°ұminCapacity=1пјҢеңЁдёҠдёҖдёӘж–№жі•(зЎ®е®ҡеҶ…йғЁе®№йҮҸensureCapacityInternal)
е°ұдјҡеҲӨж–ӯеҮәжҳҜз©әзҡ„ж•°з»„пјҢе°ұдјҡз»ҷе°ҶminCapacity=10пјҢеҲ°иҝҷдёҖжӯҘдёәжӯўпјҢиҝҳжІЎжңүж”№еҸҳelementDataзҡ„еӨ§е°ҸгҖӮ
第дәҢз§Қжғ…еҶөпјҡelementDataдёҚжҳҜз©әзҡ„ж•°з»„дәҶпјҢйӮЈд№ҲеңЁaddзҡ„ж—¶еҖҷпјҢminCapacity=size+1пјӣд№ҹе°ұжҳҜ
minCapacityд»ЈиЎЁзқҖelementDataдёӯеўһеҠ д№ӢеҗҺзҡ„е®һйҷ…ж•°жҚ®дёӘж•°пјҢжӢҝзқҖе®ғеҲӨж–ӯelementDataзҡ„length
жҳҜеҗҰеӨҹз”ЁпјҢеҰӮжһңlengthдёҚеӨҹз”ЁпјҢйӮЈд№ҲиӮҜе®ҡиҰҒжү©еӨ§е®№йҮҸпјҢдёҚ然еўһеҠ зҡ„иҝҷдёӘе…ғзҙ е°ұдјҡжәўеҮәгҖӮ*/
if (minCapacity - elementData.length > 0)
grow(minCapacity);}//ArrayListж ёеҝғзҡ„ж–№жі•пјҢиғҪжү©еұ•ж•°з»„еӨ§е°Ҹзҡ„зңҹжӯЈз§ҳеҜҶгҖӮprivate void grow(int minCapacity) {
//е°Ҷжү©е……еүҚзҡ„elementDataеӨ§е°Ҹз»ҷoldCapacity
int oldCapacity = elementData.length;
//newCapacityе°ұжҳҜ1.5еҖҚзҡ„oldCapacity
int newCapacity = oldCapacity + (oldCapacity >> 1);
/*иҝҷеҸҘиҜқе°ұжҳҜйҖӮеә”дәҺelementDataе°ұз©әж•°з»„зҡ„ж—¶еҖҷпјҢlength=0пјҢйӮЈд№ҲoldCapacity=0пјҢnewCapacity=0пјҢ
жүҖд»ҘиҝҷдёӘеҲӨж–ӯжҲҗз«ӢпјҢеңЁиҝҷйҮҢе°ұжҳҜзңҹжӯЈзҡ„еҲқе§ӢеҢ–elementDataзҡ„еӨ§е°ҸдәҶпјҢе°ұжҳҜдёә10.еүҚйқўзҡ„е·ҘдҪңйғҪжҳҜеҮҶеӨҮе·ҘдҪңгҖӮ
*/
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//еҰӮжһңnewCapacityи¶…иҝҮдәҶжңҖеӨ§зҡ„е®№йҮҸйҷҗеҲ¶пјҢе°ұи°ғз”ЁhugeCapacityпјҢд№ҹе°ұжҳҜе°ҶиғҪз»ҷзҡ„жңҖеӨ§еҖјз»ҷnewCapacity
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
//ж–°зҡ„е®№йҮҸеӨ§е°Ҹе·Із»ҸзЎ®е®ҡеҘҪе°ұcopyж•°з»„пјҢж”№еҸҳе®№йҮҸеӨ§е°ҸгҖӮ
elementData = Arrays.copyOf(elementData, newCapacity);}//з”ЁжқҘиөӢжңҖеӨ§еҖјprivate static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
//еҰӮжһңminCapacityйғҪеӨ§дәҺMAX_ARRAY_SIZEпјҢйӮЈд№Ҳе°ұInteger.MAX_VALUEиҝ”еӣһпјҢеҸҚд№Ӣе°ҶMAX_ARRAY_SIZEиҝ”еӣһгҖӮ
//зӣёеҪ“дәҺз»ҷArrayListдёҠдәҶдёӨеұӮйҳІжҠӨ
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;}3.5 add()ж–№жі•
/**
* ж·»еҠ дёҖдёӘзү№е®ҡзҡ„е…ғзҙ еҲ°listзҡ„жң«е°ҫгҖӮ
* е…Ҳsize+1еҲӨж–ӯж•°з»„е®№йҮҸжҳҜеҗҰеӨҹз”ЁпјҢжңҖеҗҺеҠ е…Ҙе…ғзҙ
*/public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;}/**
* Inserts the specified element at the specified position in this
* list. Shifts the element currently at that position (if any) and
* any subsequent elements to the right (adds one to their indices).
*
* @param index index at which the specified element is to be inserted
* @param element element to be inserted
* @throws IndexOutOfBoundsException {@inheritDoc}
*/public void add(int index, E element) {
//жЈҖжҹҘindexд№ҹе°ұжҳҜжҸ’е…Ҙзҡ„дҪҚзҪ®жҳҜеҗҰеҗҲзҗҶгҖӮ
rangeCheckForAdd(index);
//жЈҖжҹҘе®№йҮҸжҳҜеҗҰеӨҹз”ЁпјҢдёҚеӨҹе°ұиҮӘеҠЁжү©е®№
ensureCapacityInternal(size + 1); // Increments modCount!!
//иҝҷдёӘж–№жі•е°ұжҳҜз”ЁжқҘеңЁжҸ’е…Ҙе…ғзҙ д№ӢеҗҺпјҢиҰҒе°Ҷindexд№ӢеҗҺзҡ„е…ғзҙ йғҪеҫҖеҗҺ移дёҖдҪҚ
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;}еҪ“и°ғз”Ёadd()ж–№жі•ж—¶пјҢе®һйҷ…еҮҪж•°и°ғз”Ёпјҡ
addвҶ’ensureCapacityInternalвҶ’ensureExplicitCapacity(вҶ’growвҶ’hugeCapacity)
дҫӢеҰӮеҲҡејҖе§ӢеҲқе§ӢеҢ–дёҖдёӘз©әж•°з»„еҗҺaddдёҖдёӘеҖјпјҢдјҡйҰ–е…ҲиҝӣиЎҢиҮӘеҠЁжү©е®№
3.6 trimToSize()
е°Ҷеә•еұӮж•°з»„зҡ„е®№йҮҸи°ғж•ҙдёәеҪ“еүҚеҲ—иЎЁдҝқеӯҳзҡ„е®һйҷ…е…ғзҙ зҡ„еӨ§е°Ҹзҡ„еҠҹиғҪ
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA : Arrays.copyOf(elementData, size);
}}3.7 remove()ж–№жі•
remove()ж–№жі•д№ҹжңүдёӨдёӘзүҲжң¬пјҢдёҖдёӘжҳҜremove(int index)еҲ йҷӨжҢҮе®ҡдҪҚзҪ®зҡ„е…ғзҙ пјҢеҸҰдёҖдёӘжҳҜremove(Object o)еҲ йҷӨ第дёҖдёӘж»Ўи¶іo.equals(elementData[index])зҡ„е…ғзҙ гҖӮеҲ йҷӨж“ҚдҪңжҳҜadd()ж“ҚдҪңзҡ„йҖҶиҝҮзЁӢпјҢйңҖиҰҒе°ҶеҲ йҷӨзӮ№д№ӢеҗҺзҡ„е…ғзҙ еҗ‘еүҚ移еҠЁдёҖдёӘдҪҚзҪ®гҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜдёәдәҶи®©GCиө·дҪңз”ЁпјҢеҝ…йЎ»жҳҫејҸзҡ„дёәжңҖеҗҺдёҖдёӘдҪҚзҪ®иөӢnullеҖјгҖӮ
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; //жё…йҷӨиҜҘдҪҚзҪ®зҡ„еј•з”ЁпјҢи®©GCиө·дҪңз”Ё
return oldValue;
}3.8 е…¶д»–ж–№жі•
иҝҷйҮҢз®ҖеҚ•д»Ӣз»ҚдәҶж ёеҝғж–№жі•пјҢе…¶д»–ж–№жі•жҹҘзңӢжәҗз ҒеҸҜд»ҘеҫҲеҝ«дәҶи§Ј
3.9 Fail-FastжңәеҲ¶
ArrayListйҮҮз”ЁдәҶеҝ«йҖҹеӨұиҙҘзҡ„жңәеҲ¶пјҢйҖҡиҝҮи®°еҪ•modCountеҸӮж•°жқҘе®һзҺ°гҖӮеңЁйқўеҜ№е№¶еҸ‘зҡ„дҝ®ж”№ж—¶пјҢиҝӯд»ЈеҷЁеҫҲеҝ«е°ұдјҡе®Ңе…ЁеӨұиҙҘпјҢ并жҠӣеҮәConcurrentModificationExceptionејӮеёёпјҢиҖҢдёҚжҳҜеҶ’зқҖеңЁе°ҶжқҘжҹҗдёӘдёҚзЎ®е®ҡж—¶й—ҙеҸ‘з”ҹд»»ж„ҸдёҚзЎ®е®ҡиЎҢдёәзҡ„йЈҺйҷ©
4гҖҒжҖ»з»“
ArrayListеҸҜд»Ҙеӯҳж”ҫnull
ArrayListжң¬иҙЁдёҠе°ұжҳҜдёҖдёӘelementDataж•°з»„
ArrayListеҢәеҲ«дәҺж•°з»„зҡ„ең°ж–№еңЁдәҺиғҪеӨҹиҮӘеҠЁжү©еұ•еӨ§е°ҸпјҢе…¶дёӯе…ій”®зҡ„ж–№жі•е°ұжҳҜgorw()ж–№жі•
ArrayListдёӯremoveAll(collection c)е’Ңclear()зҡ„еҢәеҲ«е°ұжҳҜremoveAllеҸҜд»ҘеҲ йҷӨжү№йҮҸжҢҮе®ҡзҡ„е…ғзҙ пјҢиҖҢclearжҳҜе…ЁжҳҜеҲ йҷӨйӣҶеҗҲдёӯзҡ„е…ғзҙ
ArrayListз”ұдәҺжң¬иҙЁжҳҜж•°з»„пјҢжүҖд»Ҙе®ғеңЁж•°жҚ®зҡ„жҹҘиҜўж–№йқўдјҡеҫҲеҝ«пјҢиҖҢеңЁжҸ’е…ҘеҲ йҷӨиҝҷдәӣж–№йқўпјҢжҖ§иғҪдёӢйҷҚеҫҲеӨҡпјҢжңү移еҠЁеҫҲеӨҡж•°жҚ®жүҚиғҪиҫҫеҲ°еә”жңүзҡ„ж•Ҳжһң
ArrayListе®һзҺ°дәҶRandomAccessпјҢжүҖд»ҘеңЁйҒҚеҺҶе®ғзҡ„ж—¶еҖҷжҺЁиҚҗдҪҝз”ЁforеҫӘзҺҜ
дёүгҖҒLinkedListеҲҶжһҗ
1гҖҒLinkedListдҪҝз”Ё
| ж–№жі•еҗҚ | иҜҙжҳҺ |
|---|
| void addFirst(Object o) | еңЁеҲ—иЎЁзҡ„йҰ–йғЁж·»еҠ е…ғзҙ |
| void addLast(Object o) | еңЁеҲ—иЎЁзҡ„жңӘе°ҫж·»еҠ е…ғзҙ |
| Object getFirst() | иҝ”еӣһеҲ—иЎЁдёӯзҡ„第дёҖдёӘе…ғзҙ |
| Object getLast() | иҝ”еӣһеҲ—иЎЁдёӯзҡ„жңҖеҗҺдёҖдёӘе…ғзҙ |
| Object removeFirst() | еҲ йҷӨ并иҝ”еӣһеҲ—иЎЁдёӯзҡ„第дёҖдёӘе…ғзҙ |
| Object removeLast() | еҲ йҷӨ并иҝ”еӣһеҲ—иЎЁдёӯзҡ„жңҖеҗҺдёҖдёӘе…ғзҙ |
2гҖҒLinkedListд»Ӣз»Қ
LinkedListеҗҢж—¶е®һзҺ°дәҶListжҺҘеҸЈе’ҢDequeжҺҘеҸЈпјҢд№ҹе°ұжҳҜиҜҙе®ғж—ўеҸҜд»ҘзңӢдҪңдёҖдёӘйЎәеәҸе®№еҷЁпјҢеҸҲеҸҜд»ҘзңӢдҪңдёҖдёӘйҳҹеҲ—(Queue)пјҢеҗҢж—¶еҸҲеҸҜд»ҘзңӢдҪңдёҖдёӘж Ҳ(Stack)гҖӮиҝҷж ·зңӢжқҘпјҢLinkedListз®Җзӣҙе°ұжҳҜдёӘе…ЁиғҪеҶ еҶӣгҖӮеҪ“дҪ йңҖиҰҒдҪҝз”Ёж ҲжҲ–иҖ…йҳҹеҲ—ж—¶пјҢеҸҜд»ҘиҖғиҷ‘дҪҝз”ЁLinkedListпјҢдёҖж–№йқўжҳҜеӣ дёәJavaе®ҳж–№е·Із»ҸеЈ°жҳҺдёҚе»әи®®дҪҝз”ЁStackзұ»пјҢжӣҙйҒ—жҶҫзҡ„жҳҜпјҢJavaйҮҢж №жң¬жІЎжңүдёҖдёӘеҸ«еҒҡQueue_зҡ„зұ»(е®ғжҳҜдёӘжҺҘеҸЈеҗҚеӯ—)гҖӮе…ідәҺж ҲжҲ–йҳҹеҲ—пјҢзҺ°еңЁзҡ„йҰ–йҖүжҳҜArrayDequeпјҢе®ғжңүзқҖжҜ”LinkedList(еҪ“дҪңж ҲжҲ–йҳҹеҲ—дҪҝз”Ёж—¶)жңүзқҖжӣҙеҘҪзҡ„жҖ§иғҪгҖӮ
LinkedListзҡ„е®һзҺ°ж–№ејҸеҶіе®ҡдәҶжүҖжңүи·ҹдёӢж Үзӣёе…ізҡ„ж“ҚдҪңйғҪжҳҜзәҝжҖ§ж—¶й—ҙпјҢиҖҢеңЁйҰ–ж®өжҲ–иҖ…жң«е°ҫеҲ йҷӨе…ғзҙ еҸӘйңҖиҰҒеёёж•°ж—¶й—ҙгҖӮдёәиҝҪжұӮж•ҲзҺҮLinkedListжІЎжңүе®һзҺ°еҗҢжӯҘ(synchronized)пјҢеҰӮжһңйңҖиҰҒеӨҡдёӘзәҝзЁӢ并еҸ‘и®ҝй—®пјҢеҸҜд»Ҙе…ҲйҮҮз”ЁCollections.synchronizedList()ж–№жі•еҜ№е…¶иҝӣиЎҢеҢ…иЈ…
3гҖҒжәҗз ҒеҲҶжһҗ
3.1 继жүҝз»“жһ„дёҺеұӮж¬Ў
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
иҝҷйҮҢеҸҜд»ҘеҸ‘зҺ°LinkedListеӨҡдәҶдёҖеұӮAbstractSequentialListзҡ„жҠҪиұЎзұ»пјҢиҝҷжҳҜдёәдәҶеҮҸе°‘е®һзҺ°йЎәеәҸеӯҳеҸ–пјҲдҫӢеҰӮLinkedListпјүиҝҷз§Қзұ»зҡ„е·ҘдҪңгҖӮеҰӮжһңиҮӘе·ұжғіе®һзҺ°йЎәеәҸеӯҳеҸ–иҝҷз§Қзү№жҖ§зҡ„зұ»(е°ұжҳҜй“ҫиЎЁеҪўејҸ)пјҢйӮЈд№Ҳе°ұ继жүҝ иҝҷдёӘAbstractSequentialListжҠҪиұЎзұ»пјҢеҰӮжһңжғіеғҸж•°з»„йӮЈж ·зҡ„йҡҸжңәеӯҳеҸ–зҡ„зұ»пјҢйӮЈд№Ҳе°ұеҺ»е®һзҺ°AbstracListжҠҪиұЎзұ»гҖӮ
ListжҺҘеҸЈ
еҲ—иЎЁaddгҖҒsetзӯүдёҖдәӣеҜ№еҲ—иЎЁиҝӣиЎҢж“ҚдҪңзҡ„ж–№жі•
DequeжҺҘеҸЈ
жңүйҳҹеҲ—зҡ„еҗ„з§Қзү№жҖ§
CloneableжҺҘеҸЈ
иғҪеӨҹеӨҚеҲ¶пјҢдҪҝз”ЁйӮЈдёӘcopyж–№жі•
SerializableжҺҘеҸЈ
иғҪеӨҹеәҸеҲ—еҢ–гҖӮ
жІЎжңүRandomAccess
жҺЁиҚҗдҪҝз”ЁiteratorпјҢеңЁе…¶дёӯе°ұжңүдёҖдёӘforeachпјҢеўһејәзҡ„forеҫӘзҺҜпјҢе…¶дёӯеҺҹзҗҶд№ҹе°ұжҳҜiteratorпјҢжҲ‘们еңЁдҪҝз”Ёзҡ„ж—¶еҖҷпјҢдҪҝз”ЁforeachжҲ–иҖ…iterator
3.2 еұһжҖ§дёҺжһ„йҖ ж–№жі•
transientе…ій”®еӯ—дҝ®йҘ°пјҢиҝҷд№ҹж„Ҹе‘ізқҖеңЁеәҸеҲ—еҢ–ж—¶иҜҘеҹҹжҳҜдёҚдјҡеәҸеҲ—еҢ–зҡ„
//е®һйҷ…е…ғзҙ дёӘж•°transient int size = 0;
//еӨҙз»“зӮ№transient Node<E> first;
//е°ҫз»“зӮ№transient Node<E> last;
public LinkedList() {}public LinkedList(Collection<? extends E> c) {
this();
//е°ҶйӣҶеҗҲcдёӯзҡ„еҗ„дёӘе…ғзҙ жһ„е»әжҲҗLinkedListй“ҫиЎЁ
addAll(c);}3.3 еҶ…йғЁзұ»Node
//ж №жҚ®еүҚйқўд»Ӣз»ҚеҸҢеҗ‘й“ҫиЎЁе°ұзҹҘйҒ“иҝҷдёӘд»ЈиЎЁд»Җд№ҲдәҶпјҢlinkedListзҡ„еҘҘз§ҳе°ұеңЁиҝҷйҮҢprivate static class Node<E> {
// ж•°жҚ®еҹҹпјҲеҪ“еүҚиҠӮзӮ№зҡ„еҖјпјү
E item;
//еҗҺ继
Node<E> next;
//еүҚй©ұ
Node<E> prev;
// жһ„йҖ еҮҪж•°пјҢиөӢеҖјеүҚй©ұеҗҺ继
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}}3.4 ж ёеҝғж–№жі•add()е’ҢaddAll()
public boolean add(E e) {
linkLast(e);
return true;}void linkLast(E e) {
//дёҙж—¶иҠӮзӮ№l(Lзҡ„е°ҸеҶҷ)дҝқеӯҳlastпјҢд№ҹе°ұжҳҜlжҢҮеҗ‘дәҶжңҖеҗҺдёҖдёӘиҠӮзӮ№
final Node<E> l = last;
//е°Ҷeе°ҒиЈ…дёәиҠӮзӮ№пјҢ并且e.prevжҢҮеҗ‘дәҶжңҖеҗҺдёҖдёӘиҠӮзӮ№
final Node<E> newNode = new Node<>(l, e, null);
//newNodeжҲҗдёәдәҶжңҖеҗҺдёҖдёӘиҠӮзӮ№пјҢжүҖд»ҘlastжҢҮеҗ‘дәҶе®ғ
last = newNode;
if (l == null)
//еҲӨж–ӯжҳҜдёҚжҳҜдёҖејҖе§Ӣй“ҫиЎЁдёӯе°ұд»Җд№ҲйғҪжІЎжңүпјҢеҰӮжһңжІЎжңүпјҢеҲҷnew Nodeе°ұжҲҗдёәдәҶ第дёҖдёӘз»“зӮ№пјҢfirstе’ҢlastйғҪжҢҮеҗ‘е®ғ
first = newNode;
else
//жӯЈеёёзҡ„еңЁжңҖеҗҺдёҖдёӘиҠӮзӮ№еҗҺиҝҪеҠ пјҢйӮЈд№ҲеҺҹе…Ҳзҡ„жңҖеҗҺдёҖдёӘиҠӮзӮ№зҡ„nextе°ұиҰҒжҢҮеҗ‘зҺ°еңЁзңҹжӯЈзҡ„ жңҖеҗҺдёҖдёӘиҠӮзӮ№пјҢеҺҹе…Ҳзҡ„жңҖеҗҺдёҖдёӘиҠӮзӮ№е°ұеҸҳжҲҗдәҶеҖ’数第дәҢдёӘиҠӮзӮ№
l.next = newNode;
//ж·»еҠ дёҖдёӘиҠӮзӮ№пјҢsizeиҮӘеўһ
size++;
modCount++;}addAll()жңүдёӨдёӘйҮҚиҪҪеҮҪж•°пјҢaddAll(Collection<? extends E>)еһӢе’ҢaddAll(int,Collection<? extends E>)еһӢпјҢжҲ‘д»¬е№іж—¶д№ жғҜи°ғз”Ёзҡ„addAll(Collection<?extends E>)еһӢдјҡиҪ¬еҢ–дёәaddAll(int,Collection<? extends<E>)еһӢ
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);}public boolean addAll(int index, Collection<? extends E> c) {
//жЈҖжҹҘindexиҝҷдёӘжҳҜеҗҰдёәеҗҲзҗҶ
checkPositionIndex(index);
//е°ҶйӣҶеҗҲcиҪ¬жҚўдёәObjectж•°з»„
Object[] a = c.toArray();
//ж•°з»„aзҡ„й•ҝеәҰnumNewпјҢд№ҹе°ұжҳҜз”ұеӨҡе°‘дёӘе…ғзҙ
int numNew = a.length;
if (numNew == 0)
//еҰӮжһңз©әзҡ„е°ұд»Җд№Ҳд№ҹдёҚеҒҡ
return false;
Node<E> pred, succ;
//жһ„йҖ ж–№жі•дёӯдј иҝҮжқҘзҡ„е°ұжҳҜindex==size
//жғ…еҶөдёҖпјҡжһ„йҖ ж–№жі•еҲӣе»әзҡ„дёҖдёӘз©әзҡ„й“ҫиЎЁпјҢйӮЈд№Ҳsize=0пјҢlastгҖҒе’ҢfirstйғҪдёәnullгҖӮlinkedListдёӯжҳҜз©әзҡ„гҖӮ
//д»Җд№ҲиҠӮзӮ№йғҪжІЎжңүгҖӮsucc=nullгҖҒpred=last=null
//жғ…еҶөдәҢпјҡй“ҫиЎЁдёӯжңүиҠӮзӮ№пјҢsizeе°ұдёҚжҳҜдёә0пјҢfirstе’ҢlastйғҪеҲҶеҲ«жҢҮеҗ‘第дёҖдёӘиҠӮзӮ№пјҢе’ҢжңҖеҗҺдёҖдёӘиҠӮзӮ№пјҢ
//еңЁжңҖеҗҺдёҖдёӘиҠӮзӮ№д№ӢеҗҺиҝҪеҠ е…ғзҙ пјҢе°ұеҫ—и®°еҪ•дёҖдёӢжңҖеҗҺдёҖдёӘиҠӮзӮ№жҳҜд»Җд№ҲпјҢжүҖд»ҘжҠҠlastдҝқеӯҳеҲ°predдёҙж—¶иҠӮзӮ№дёӯгҖӮ
//жғ…еҶөдёүindexпјҒ=sizeпјҢиҜҙжҳҺдёҚжҳҜеүҚйқўдёӨз§Қжғ…еҶөпјҢиҖҢжҳҜеңЁй“ҫиЎЁдёӯй—ҙжҸ’е…Ҙе…ғзҙ пјҢйӮЈд№Ҳе°ұеҫ—зҹҘйҒ“indexдёҠзҡ„иҠӮзӮ№жҳҜи°ҒпјҢ
//дҝқеӯҳеҲ°succдёҙж—¶иҠӮзӮ№дёӯпјҢ然еҗҺе°Ҷsuccзҡ„еүҚдёҖдёӘиҠӮзӮ№дҝқеӯҳеҲ°predдёӯпјҢиҝҷж ·дҝқеӯҳдәҶиҝҷдёӨдёӘиҠӮзӮ№пјҢе°ұиғҪеӨҹеҮҶзЎ®зҡ„жҸ’е…ҘиҠӮзӮ№дәҶ
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
/*еҰӮжһңsucc==nullпјҢиҜҙжҳҺжҳҜжғ…еҶөдёҖжҲ–иҖ…жғ…еҶөдәҢпјҢ
жғ…еҶөдёҖгҖҒжһ„йҖ ж–№жі•пјҢд№ҹе°ұжҳҜеҲҡеҲӣе»әзҡ„дёҖдёӘз©әй“ҫиЎЁпјҢpredе·Із»ҸжҳҜnewNodeдәҶпјҢ
last=newNodeпјҢжүҖд»ҘlinkedListзҡ„firstгҖҒlastйғҪжҢҮеҗ‘第дёҖдёӘиҠӮзӮ№гҖӮ
жғ…еҶөдәҢгҖҒеңЁжңҖеҗҺиҠӮеҗҺд№ӢеҗҺиҝҪеҠ иҠӮзӮ№пјҢйӮЈд№ҲеҺҹе…Ҳзҡ„lastе°ұеә”иҜҘжҢҮеҗ‘зҺ°еңЁзҡ„жңҖеҗҺдёҖдёӘиҠӮзӮ№дәҶпјҢ
е°ұжҳҜnewNodeгҖӮ*/
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;}//ж №жҚ®еј•дёӢж ҮжүҫеҲ°иҜҘз»“зӮ№е№¶иҝ”еӣһNode<E> node(int index) {
//еҲӨж–ӯжҸ’е…Ҙзҡ„дҪҚзҪ®еңЁй“ҫиЎЁеүҚеҚҠж®өжҲ–иҖ…жҳҜеҗҺеҚҠж®ө
if (index < (size >> 1)) {
Node<E> x = first;
//д»ҺеӨҙз»“зӮ№ејҖе§ӢжӯЈеҗ‘йҒҚеҺҶ
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
//д»Һе°ҫз»“зӮ№ејҖе§ӢеҸҚеҗ‘йҒҚеҺҶ
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}}3.5 remove()
/*еҰӮжһңжҲ‘们иҰҒ移йҷӨзҡ„еҖјеңЁй“ҫиЎЁдёӯеӯҳеңЁеӨҡдёӘдёҖж ·зҡ„еҖјпјҢйӮЈд№ҲжҲ‘们
дјҡ移йҷӨindexжңҖе°Ҹзҡ„йӮЈдёӘпјҢд№ҹе°ұжҳҜжңҖе…ҲжүҫеҲ°зҡ„йӮЈдёӘеҖјпјҢеҰӮжһңдёҚеӯҳеңЁиҝҷдёӘеҖјпјҢйӮЈд№Ҳд»Җд№Ҳд№ҹдёҚеҒҡ
*/public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;}дёҚиғҪдј дёҖдёӘnullеҖјE unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
//xзҡ„еүҚеҗҺжҢҮеҗ‘йғҪдёәnullдәҶпјҢд№ҹжҠҠitemдёәnullпјҢи®©gcеӣһ收е®ғ
x.item = null;
size--;
modCount++;
return element;}3.6 е…¶д»–ж–№жі•
**get(index)гҖҒindexOf(Object o)**зӯүжҹҘзңӢжәҗз ҒеҚіеҸҜ
3.7 LinkedListзҡ„иҝӯд»ЈеҷЁ
еңЁLinkedListдёӯйҷӨдәҶжңүдёҖдёӘNodeзҡ„еҶ…йғЁзұ»еӨ–пјҢеә”иҜҘиҝҳиғҪзңӢеҲ°еҸҰеӨ–дёӨдёӘеҶ…йғЁзұ»пјҢйӮЈе°ұжҳҜListItrпјҢиҝҳжңүдёҖдёӘжҳҜDescendingIteratorеҶ…йғЁзұ»
/*иҝҷдёӘзұ»пјҢиҝҳжҳҜи°ғз”Ёзҡ„ListItrпјҢдҪңз”ЁжҳҜе°ҒиЈ…дёҖдёӢItrдёӯеҮ дёӘж–№жі•пјҢи®©дҪҝз”ЁиҖ…д»ҘжӯЈеёёзҡ„жҖқз»ҙеҺ»еҶҷд»Јз ҒпјҢ
дҫӢеҰӮпјҢеңЁд»ҺеҗҺеҫҖеүҚйҒҚеҺҶзҡ„ж—¶еҖҷпјҢд№ҹжҳҜи·ҹд»ҺеүҚеҫҖеҗҺйҒҚеҺҶдёҖж ·пјҢдҪҝз”Ёnextзӯүж“ҚдҪңпјҢиҖҢдёҚз”ЁдҪҝз”Ёзү№ж®Ҡзҡ„previousгҖӮ
*/private class DescendingIterator implements Iterator<E> {
private final ListItr itr = new ListItr(size());
public boolean hasNext() {
return itr.hasPrevious();
}
public E next() {
return itr.previous();
}
public void remove() {
itr.remove();
}}4гҖҒжҖ»з»“
linkedListжң¬иҙЁдёҠжҳҜдёҖдёӘеҸҢеҗ‘й“ҫиЎЁпјҢйҖҡиҝҮдёҖдёӘNodeеҶ…йғЁзұ»е®һзҺ°зҡ„иҝҷз§Қй“ҫиЎЁз»“жһ„гҖӮlinkedListиғҪеӯҳеӮЁnullеҖј
и·ҹArrayListзӣёжҜ”иҫғпјҢе°ұзңҹжӯЈзҡ„зҹҘйҒ“дәҶпјҢLinkedListеңЁеҲ йҷӨе’ҢеўһеҠ зӯүж“ҚдҪңдёҠжҖ§иғҪеҘҪпјҢиҖҢArrayListеңЁжҹҘиҜўзҡ„жҖ§иғҪдёҠеҘҪпјҢд»Һжәҗз ҒдёӯзңӢпјҢе®ғдёҚеӯҳеңЁе®№йҮҸдёҚи¶ізҡ„жғ…еҶө
linkedListдёҚе…үиғҪеӨҹеҗ‘еүҚиҝӯд»ЈпјҢиҝҳиғҪеғҸеҗҺиҝӯд»ЈпјҢ并且еңЁиҝӯд»Јзҡ„иҝҮзЁӢдёӯпјҢеҸҜд»Ҙдҝ®ж”№еҖјгҖҒж·»еҠ еҖјгҖҒиҝҳиғҪ移йҷӨеҖј
linkedListдёҚе…үиғҪеҪ“й“ҫиЎЁпјҢиҝҳиғҪеҪ“йҳҹеҲ—дҪҝз”ЁпјҢиҝҷдёӘе°ұжҳҜеӣ дёәе®һзҺ°дәҶDequeжҺҘеҸЈ
еӣӣгҖҒListжҖ»з»“
1гҖҒArrayListе’ҢLinkedListеҢәеҲ«
ArrayListеә•еұӮжҳҜз”Ёж•°з»„е®һзҺ°зҡ„йЎәеәҸиЎЁпјҢжҳҜйҡҸжңәеӯҳеҸ–зұ»еһӢпјҢеҸҜиҮӘеҠЁжү©еўһпјҢ并且еңЁеҲқе§ӢеҢ–ж—¶пјҢж•°з»„зҡ„й•ҝеәҰжҳҜ0пјҢеҸӘжңүеңЁеўһеҠ е…ғзҙ ж—¶пјҢй•ҝеәҰжүҚдјҡеўһеҠ гҖӮй»ҳи®ӨжҳҜ10пјҢдёҚиғҪж— йҷҗжү©еўһпјҢжңүдёҠйҷҗпјҢеңЁжҹҘиҜўж“ҚдҪңзҡ„ж—¶еҖҷжҖ§иғҪжӣҙеҘҪ
LinkedListеә•еұӮжҳҜз”Ёй“ҫиЎЁжқҘе®һзҺ°зҡ„пјҢжҳҜдёҖдёӘеҸҢеҗ‘й“ҫиЎЁпјҢжіЁж„ҸиҝҷйҮҢдёҚжҳҜеҸҢеҗ‘еҫӘзҺҜй“ҫиЎЁ,йЎәеәҸеӯҳеҸ–зұ»еһӢгҖӮеңЁжәҗз ҒдёӯпјҢдјјд№ҺжІЎжңүе…ғзҙ дёӘж•°зҡ„йҷҗеҲ¶гҖӮеә”иҜҘиғҪж— йҷҗеўһеҠ дёӢеҺ»пјҢзӣҙеҲ°еҶ…еӯҳж»ЎдәҶеңЁиҝӣиЎҢеҲ йҷӨпјҢеўһеҠ ж“ҚдҪңж—¶жҖ§иғҪжӣҙеҘҪгҖӮ
дёӨдёӘйғҪжҳҜзәҝзЁӢдёҚе®үе…Ёзҡ„пјҢеңЁiteratorж—¶пјҢдјҡеҸ‘з”ҹfail-fastпјҡеҝ«йҖҹеӨұж•ҲгҖӮ
2гҖҒArrayListе’ҢVectorеҢәеҲ«
3гҖҒfail-fastе’Ңfail-safeеҢәеҲ«дёҺжғ…еҶөиҜҙжҳҺ
еңЁjava.utilдёӢзҡ„йӣҶеҗҲйғҪжҳҜеҸ‘з”ҹfail-fastпјҢиҖҢеңЁjava.util.concurrentдёӢзҡ„еҸ‘з”ҹзҡ„йғҪжҳҜfail-safe
fail-fast
еҝ«йҖҹеӨұиҙҘпјҢдҫӢеҰӮеңЁarrayListдёӯдҪҝз”Ёиҝӯд»ЈеҷЁйҒҚеҺҶж—¶пјҢжңүеҸҰеӨ–зҡ„зәҝзЁӢеҜ№arrayListзҡ„еӯҳеӮЁж•°з»„иҝӣиЎҢдәҶж”№еҸҳпјҢжҜ” еҰӮaddгҖҒdeleteзӯүдҪҝд№ӢеҸ‘з”ҹдәҶз»“жһ„дёҠзҡ„ж”№еҸҳпјҢжүҖд»ҘIteratorе°ұдјҡеҝ«йҖҹжҠҘдёҖдёӘjava.util.ConcurrentModiп¬ҒcationExceptionејӮеёёпјҲ并еҸ‘дҝ®ж”№ејӮеёёпјүпјҢиҝҷе°ұжҳҜеҝ«йҖҹеӨұиҙҘ
fail-safe
е®үе…ЁеӨұиҙҘпјҢеңЁjava.util.concurrentдёӢзҡ„зұ»пјҢйғҪжҳҜзәҝзЁӢе®үе…Ёзҡ„зұ»пјҢ他们еңЁиҝӯд»Јзҡ„иҝҮзЁӢдёӯпјҢеҰӮжһңжңүзәҝзЁӢиҝӣиЎҢз»“жһ„зҡ„ж”№еҸҳпјҢдёҚдјҡжҠҘејӮеёёпјҢиҖҢжҳҜжӯЈеёёйҒҚеҺҶпјҢиҝҷе°ұжҳҜе®үе…ЁеӨұиҙҘ
дёәд»Җд№ҲеңЁjava.util.concurrentеҢ…дёӢеҜ№йӣҶеҗҲжңүз»“жһ„зҡ„ж”№еҸҳеҚҙдёҚдјҡжҠҘејӮеёёпјҹ
еңЁconcurrentдёӢзҡ„йӣҶеҗҲзұ»еўһеҠ е…ғзҙ зҡ„ж—¶еҖҷдҪҝз”ЁArrays.copyOf()жқҘжӢ·иҙқеүҜжң¬пјҢеңЁеүҜжң¬дёҠеўһеҠ е…ғзҙ пјҢеҰӮжһңжңүе…¶д»–зәҝзЁӢеңЁжӯӨж”№еҸҳдәҶйӣҶеҗҲзҡ„з»“жһ„пјҢйӮЈд№ҹжҳҜеңЁеүҜжң¬дёҠзҡ„ж”№еҸҳпјҢиҖҢдёҚжҳҜеҪұе“ҚеҲ°еҺҹйӣҶеҗҲпјҢиҝӯд»ЈеҷЁиҝҳжҳҜз…§еёёйҒҚеҺҶпјҢйҒҚеҺҶе®Ңд№ӢеҗҺпјҢж”№еҸҳеҺҹеј•з”ЁжҢҮеҗ‘еүҜжң¬пјҢжүҖд»ҘжҖ»зҡ„дёҖеҸҘиҜқе°ұжҳҜеҰӮжһңеңЁжӯӨеҢ…дёӢзҡ„зұ»иҝӣиЎҢеўһеҠ еҲ йҷӨпјҢе°ұдјҡеҮәзҺ°дёҖдёӘеүҜжң¬гҖӮжүҖд»ҘиғҪйҳІжӯўfail-fastпјҢиҝҷз§ҚжңәеҲ¶е№¶дёҚдјҡеҮәй”ҷпјҢжүҖд»ҘжҲ‘们еҸ«иҝҷз§ҚзҺ°иұЎдёәfail-safe
vectorд№ҹжҳҜзәҝзЁӢе®үе…Ёзҡ„пјҢдёәд»Җд№ҲжҳҜfail-fastе‘ўпјҹ
еҮәзҺ°fail-safeжҳҜеӣ дёә他们еңЁе®һзҺ°еўһеҲ зҡ„еә•еұӮжңәеҲ¶дёҚдёҖж ·пјҢе°ұеғҸдёҠйқўиҜҙзҡ„пјҢдјҡжңүдёҖдёӘеүҜжң¬пјҢиҖҢеғҸarrayListгҖҒlinekdListгҖҒverctorзӯү他们еә•еұӮе°ұжҳҜеҜ№зқҖзңҹжӯЈзҡ„еј•з”ЁиҝӣиЎҢж“ҚдҪңпјҢжүҖд»ҘжүҚдјҡеҸ‘з”ҹејӮеёё
4гҖҒдёәд»Җд№ҲзҺ°еңЁйғҪдёҚжҸҗеҖЎдҪҝз”ЁVector
vectorе®һзҺ°зәҝзЁӢе®үе…Ёзҡ„ж–№жі•жҳҜеңЁжҜҸдёӘж“ҚдҪңж–№жі•дёҠеҠ й”ҒпјҢиҝҷдәӣй”Ғ并дёҚжҳҜеҝ…йЎ»иҰҒзҡ„пјҢеңЁе®һйҷ…ејҖеҸ‘дёӯпјҢдёҖиҲ¬йғҪжҳҜйҖҡиҝҮй”ҒдёҖзі»еҲ—зҡ„ж“ҚдҪңжқҘе®һзҺ°зәҝзЁӢе®үе…ЁпјҢд№ҹе°ұжҳҜиҜҙе°ҶйңҖиҰҒеҗҢжӯҘзҡ„иө„жәҗж”ҫдёҖиө·еҠ й”ҒжқҘдҝқиҜҒзәҝзЁӢе®үе…Ё
еҰӮжһңеӨҡдёӘThread并еҸ‘жү§иЎҢдёҖдёӘе·Із»ҸеҠ й”Ғзҡ„ж–№жі•пјҢдҪҶжҳҜеңЁиҜҘж–№жі•дёӯпјҢеҸҲжңүVectorзҡ„еӯҳеңЁпјҢVector
жң¬иә«е®һзҺ°дёӯе·Із»ҸеҠ й”ҒдәҶпјҢйӮЈд№ҲзӣёеҪ“дәҺй”ҒдёҠеҸҲеҠ й”ҒпјҢдјҡйҖ жҲҗйўқеӨ–зҡ„ејҖй”Җ
Vectorиҝҳжңүfail-fastзҡ„й—®йўҳпјҢд№ҹе°ұжҳҜиҜҙе®ғд№ҹж— жі•дҝқиҜҒйҒҚеҺҶе®үе…ЁпјҢеңЁ йҒҚеҺҶж—¶еҸҲеҫ—йўқеӨ–еҠ й”ҒпјҢеҸҲжҳҜйўқеӨ–зҡ„ејҖй”ҖпјҢиҝҳдёҚеҰӮзӣҙжҺҘз”ЁarrayListпјҢ然еҗҺеҶҚеҠ й”Ғ
жҖ»з»“пјҡVectorеңЁдҪ дёҚйңҖиҰҒиҝӣиЎҢзәҝзЁӢе®үе…Ёзҡ„ж—¶еҖҷпјҢд№ҹдјҡз»ҷдҪ еҠ й”ҒпјҢд№ҹе°ұеҜјиҮҙдәҶйўқеӨ–ејҖй”ҖпјҢжүҖд»ҘеңЁjdk1.5д№ӢеҗҺе°ұиў«ејғз”ЁдәҶпјҢзҺ°еңЁеҰӮжһңиҰҒз”ЁеҲ°зәҝзЁӢе®үе…Ёзҡ„йӣҶеҗҲпјҢйғҪжҳҜд»Һjava.util.concurrentеҢ…дёӢеҺ»жӢҝзӣёеә”зҡ„зұ»гҖӮ
дә”гҖҒHashMapеҲҶжһҗ
1гҖҒHashMapд»Ӣз»Қ
1.1 Java8д»ҘеүҚзҡ„HashMap
йҖҡиҝҮkeyгҖҒvalueе°ҒиЈ…жҲҗдёҖдёӘentryеҜ№иұЎпјҢ然еҗҺйҖҡиҝҮkeyзҡ„еҖјжқҘи®Ўз®—иҜҘentryзҡ„hashеҖјпјҢйҖҡиҝҮentryзҡ„hash еҖје’Ңж•°з»„зҡ„й•ҝеәҰlengthжқҘи®Ўз®—еҮәentryж”ҫеңЁж•°з»„дёӯзҡ„е“ӘдёӘдҪҚзҪ®дёҠйқўпјҢжҜҸж¬Ўеӯҳж”ҫйғҪжҳҜе°Ҷentryж”ҫеңЁз¬¬дёҖдёӘдҪҚзҪ®гҖӮ
HashMapе®һзҺ°дәҶMapжҺҘеҸЈпјҢеҚіе…Ғи®ёж”ҫе…Ҙkeyдёәnullзҡ„е…ғзҙ пјҢд№ҹе…Ғи®ёжҸ’е…Ҙvalueдёәnullзҡ„е…ғзҙ пјӣйҷӨиҜҘзұ»жңӘе®һзҺ°еҗҢжӯҘеӨ–пјҢе…¶дҪҷи·ҹHashtableеӨ§иҮҙзӣёеҗҢпјӣи·ҹTreeMapдёҚеҗҢпјҢиҜҘе®№еҷЁдёҚдҝқиҜҒе…ғзҙ йЎәеәҸпјҢж №жҚ®йңҖиҰҒиҜҘе®№еҷЁеҸҜиғҪдјҡеҜ№е…ғзҙ йҮҚж–°е“ҲеёҢпјҢе…ғзҙ зҡ„йЎәеәҸд№ҹдјҡиў«йҮҚж–°жү“ж•ЈпјҢеӣ жӯӨдёҚеҗҢж—¶й—ҙиҝӯд»ЈеҗҢдёҖдёӘHashMapзҡ„йЎәеәҸеҸҜиғҪдјҡдёҚеҗҢгҖӮ ж №жҚ®еҜ№еҶІзӘҒзҡ„еӨ„зҗҶж–№ејҸдёҚеҗҢпјҢе“ҲеёҢиЎЁжңүдёӨз§Қе®һзҺ°ж–№ејҸпјҢдёҖз§ҚејҖж”ҫең°еқҖж–№ејҸ(Open addressing)пјҢеҸҰдёҖз§ҚжҳҜеҶІзӘҒй“ҫиЎЁж–№ејҸ(Separate chaining with linked lists)гҖӮJava7 HashMapйҮҮз”Ёзҡ„жҳҜеҶІзӘҒй“ҫиЎЁж–№ејҸгҖӮ

1.2 Java8еҗҺзҡ„HashMap
Java8 еҜ№ HashMap иҝӣиЎҢдәҶдёҖдәӣдҝ®ж”№пјҢжңҖеӨ§зҡ„дёҚеҗҢе°ұжҳҜеҲ©з”ЁдәҶзәўй»‘ж ‘пјҢжүҖд»Ҙе…¶з”ұ ж•°з»„+й“ҫиЎЁ+зәўй»‘ж ‘ з»„жҲҗгҖӮж №жҚ® Java7 HashMap зҡ„д»Ӣз»ҚпјҢжҲ‘们зҹҘйҒ“пјҢжҹҘжүҫзҡ„ж—¶еҖҷпјҢж №жҚ® hash еҖјжҲ‘们иғҪеӨҹеҝ«йҖҹе®ҡдҪҚеҲ°ж•°з»„зҡ„е…·дҪ“дёӢж ҮпјҢдҪҶжҳҜд№ӢеҗҺзҡ„иҜқпјҢйңҖиҰҒйЎәзқҖй“ҫиЎЁдёҖдёӘдёӘжҜ”иҫғдёӢеҺ»жүҚиғҪжүҫеҲ°жҲ‘们йңҖиҰҒзҡ„пјҢж—¶й—ҙеӨҚжқӮеәҰеҸ–еҶідәҺй“ҫиЎЁзҡ„й•ҝеәҰдёә O(n)гҖӮдёәдәҶйҷҚдҪҺиҝҷйғЁеҲҶзҡ„ејҖй”ҖпјҢеңЁ Java8 дёӯпјҢеҪ“й“ҫиЎЁдёӯзҡ„е…ғзҙ иҫҫеҲ°дәҶ 8 дёӘж—¶пјҢдјҡе°Ҷй“ҫиЎЁиҪ¬жҚўдёәзәўй»‘ж ‘пјҢеңЁиҝҷдәӣдҪҚзҪ®иҝӣиЎҢжҹҘжүҫзҡ„ж—¶еҖҷеҸҜд»ҘйҷҚдҪҺж—¶й—ҙеӨҚжқӮеәҰдёә O(logN)гҖӮ
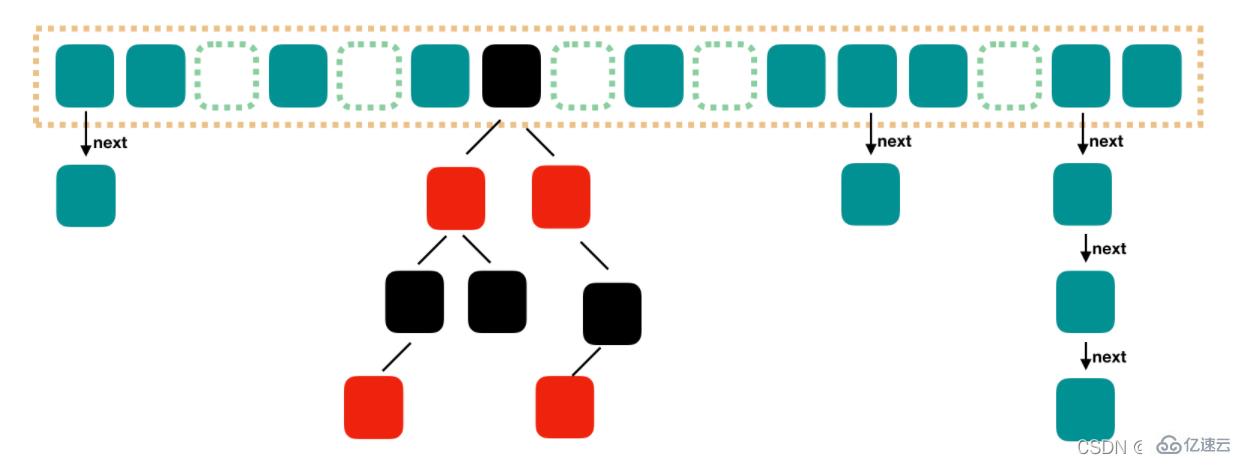
Java7 дёӯдҪҝз”Ё Entry жқҘд»ЈиЎЁжҜҸдёӘ HashMap дёӯзҡ„ж•°жҚ®иҠӮзӮ№пјҢJava8 дёӯдҪҝз”Ё NodeпјҢеҹәжң¬жІЎжңүеҢәеҲ«пјҢйғҪжҳҜ keyпјҢvalueпјҢhash е’Ң next иҝҷеӣӣдёӘеұһжҖ§пјҢдёҚиҝҮпјҢNode еҸӘиғҪз”ЁдәҺй“ҫиЎЁзҡ„жғ…еҶөпјҢзәўй»‘ж ‘зҡ„жғ…еҶөйңҖиҰҒдҪҝз”Ё TreeNode
2гҖҒJava8 HashMapжәҗз ҒеҲҶжһҗ
2.1 继жүҝз»“жһ„дёҺеұӮж¬Ў
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
2.2 еұһжҖ§
//еәҸеҲ—еҸ·private static final long serialVersionUID = 362498820763181265L;
//й»ҳи®Өзҡ„еҲқе§Ӣе®№йҮҸstatic final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// aka 16
//жңҖеӨ§е®№йҮҸstatic final int MAXIMUM_CAPACITY = 1 << 30;
//й»ҳи®ӨеҠ иҪҪеӣ еӯҗstatic final float DEFAULT_LOAD_FACTOR = 0.75f;
//еҪ“жЎ¶(bucket)дёҠзҡ„з»“зӮ№ж•°еӨ§дәҺиҝҷдёӘеҖјж—¶дјҡиҪ¬жҲҗзәўй»‘ж ‘static final int TREEIFY_THRESHOLD = 8;
//еҪ“жЎ¶(bucket)дёҠзҡ„з»“зӮ№ж•°е°ҸдәҺиҝҷдёӘеҖјж—¶ж ‘иҪ¬й“ҫиЎЁstatic final int UNTREEIFY_THRESHOLD = 6;
//жЎ¶дёӯз»“жһ„иҪ¬еҢ–дёәзәўй»‘ж ‘еҜ№еә”зҡ„tableзҡ„жңҖе°ҸеӨ§е°Ҹstatic final int MIN_TREEIFY_CAPACITY = 64;
//еӯҳеӮЁе…ғзҙ зҡ„ж•°з»„пјҢжҖ»жҳҜ2зҡ„е№Ӯж¬ЎеҖҚtransient Node<K,V>[] table;
//еӯҳж”ҫе…·дҪ“е…ғзҙ зҡ„йӣҶtransient Set<Map.Entry<K,V>> entrySet;
//еӯҳж”ҫе…ғзҙ зҡ„дёӘж•°пјҢжіЁж„ҸиҝҷдёӘдёҚзӯүдәҺж•°з»„зҡ„й•ҝеәҰtransient int size;
//жҜҸж¬Ўжү©е®№е’Ңжӣҙж”№mapз»“жһ„зҡ„и®Ўж•°еҷЁtransient int modCount;
//дёҙз•ҢеҖјпјҢеҪ“е®һйҷ…еӨ§е°Ҹ(е®№йҮҸ*еЎ«е……еӣ еӯҗ)и¶…иҝҮдёҙз•ҢеҖјж—¶пјҢдјҡиҝӣиЎҢжү©е®№int threshold;
//еЎ«е……еӣ еӯҗ,и®Ўз®—HashMapзҡ„е®һж—¶иЈ…иҪҪеӣ еӯҗзҡ„ж–№жі•дёәпјҡsize/capacityfinal float loadFactor;
2.3 жһ„йҖ ж–№жі•
public HashMap(int initialCapacity, float loadFactor) {
// еҲқе§Ӣе®№йҮҸдёҚиғҪе°ҸдәҺ0пјҢеҗҰеҲҷжҠҘй”ҷ
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// еҲқе§Ӣе®№йҮҸдёҚиғҪеӨ§дәҺжңҖеӨ§еҖјпјҢеҗҰеҲҷдёәжңҖеӨ§еҖј
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//еЎ«е……еӣ еӯҗдёҚиғҪе°ҸдәҺжҲ–зӯүдәҺ0пјҢдёҚиғҪдёәйқһж•°еӯ—
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
//еҲқе§ӢеҢ–еЎ«е……еӣ еӯҗ
this.loadFactor = loadFactor;
//еҲқе§ӢеҢ–thresholdеӨ§е°Ҹ
this.threshold = tableSizeFor(initialCapacity);}//иҝҷдёӘж–№жі•е°Ҷдј иҝӣжқҘзҡ„еҸӮж•°иҪ¬еҸҳдёә2зҡ„nж¬Ўж–№зҡ„ж•°еҖјstatic final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}/**
* иҮӘе®ҡд№үеҲқе§Ӣе®№йҮҸпјҢеҠ иҪҪеӣ еӯҗдёәй»ҳи®Ө
*/public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);}/**
* дҪҝз”Ёй»ҳи®Өзҡ„еҠ иҪҪеӣ еӯҗзӯүеӯ—ж®ө
*/public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}public HashMap(Map<? extends K, ? extends V> m) {
//еҲқе§ӢеҢ–еЎ«е……еӣ еӯҗ
this.loadFactor = DEFAULT_LOAD_FACTOR;
//е°Ҷmдёӯзҡ„жүҖжңүе…ғзҙ ж·»еҠ иҮіHashMapдёӯ
putMapEntries(m, false);}//е°Ҷmзҡ„жүҖжңүе…ғзҙ еӯҳе…ҘиҜҘе®һдҫӢfinal void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
//еҲӨж–ӯtableжҳҜеҗҰе·Із»ҸеҲқе§ӢеҢ–
if (table == null) { // pre-size
//жңӘеҲқе§ӢеҢ–пјҢsдёәmзҡ„е®һйҷ…е…ғзҙ дёӘж•°
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
//и®Ўз®—еҫ—еҲ°зҡ„tеӨ§дәҺйҳҲеҖјпјҢеҲҷеҲқе§ӢеҢ–йҳҲеҖј
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
//е°Ҷmдёӯзҡ„жүҖжңүе…ғзҙ ж·»еҠ иҮіHashMapдёӯ
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}}2.4 ж ёеҝғж–№жі•
put()ж–№жі•
е…Ҳи®Ўз®—keyзҡ„hashеҖјпјҢ然еҗҺж №жҚ®hashеҖјжҗңзҙўеңЁtableж•°з»„дёӯзҡ„зҙўеј•дҪҚзҪ®пјҢеҰӮжһңtableж•°з»„еңЁиҜҘдҪҚзҪ®еӨ„жңүе…ғзҙ пјҢеҲҷжҹҘжүҫжҳҜеҗҰеӯҳеңЁзӣёеҗҢзҡ„keyпјҢиӢҘеӯҳеңЁеҲҷиҰҶзӣ–еҺҹжқҘkeyзҡ„valueпјҢеҗҰеҲҷе°ҶиҜҘе…ғзҙ дҝқеӯҳеңЁй“ҫиЎЁе°ҫйғЁпјҢжіЁж„ҸJDK1.7дёӯйҮҮз”Ёзҡ„жҳҜеӨҙжҸ’жі•пјҢеҚіжҜҸж¬ЎйғҪе°ҶеҶІзӘҒзҡ„й”®еҖјеҜ№ж”ҫзҪ®еңЁй“ҫиЎЁеӨҙпјҢиҝҷж ·жңҖеҲқзҡ„йӮЈдёӘй”®еҖјеҜ№жңҖз»Ҳе°ұдјҡжҲҗдёәй“ҫе°ҫпјҢиҖҢJDK1.8дёӯдҪҝз”Ёзҡ„жҳҜе°ҫжҸ’жі•гҖӮжӯӨеӨ–пјҢиӢҘtableеңЁиҜҘеӨ„жІЎжңүе…ғзҙ пјҢеҲҷзӣҙжҺҘдҝқеӯҳгҖӮ
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//第дёҖж¬Ўputе…ғзҙ ж—¶пјҢtableж•°з»„дёәз©әпјҢе…Ҳи°ғз”Ёresizeз”ҹжҲҗдёҖдёӘжҢҮе®ҡе®№йҮҸзҡ„ж•°з»„
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//hashеҖје’Ңn-1зҡ„дёҺиҝҗз®—з»“жһңдёәжЎ¶зҡ„дҪҚзҪ®пјҢеҰӮжһңиҜҘдҪҚзҪ®з©әе°ұзӣҙжҺҘж”ҫзҪ®дёҖдёӘNode
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//еҰӮжһңи®Ўз®—еҮәзҡ„bucketдёҚз©әпјҢеҚіеҸ‘з”ҹе“ҲеёҢеҶІзӘҒпјҢе°ұиҰҒиҝӣдёҖжӯҘеҲӨж–ӯ
else {
Node<K,V> e; K k;
//еҲӨж–ӯеҪ“еүҚNodeзҡ„keyдёҺиҰҒputзҡ„keyжҳҜеҗҰзӣёзӯү
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//еҲӨж–ӯеҪ“еүҚNodeжҳҜеҗҰжҳҜзәўй»‘ж ‘зҡ„иҠӮзӮ№
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//д»ҘдёҠйғҪдёҚжҳҜпјҢиҜҙжҳҺиҰҒnewдёҖдёӘNodeпјҢеҠ е…ҘеҲ°й“ҫиЎЁдёӯ
else {
for (int binCount = 0; ; ++binCount) {
//еңЁй“ҫиЎЁе°ҫйғЁжҸ’е…Ҙж–°иҠӮзӮ№пјҢжіЁж„Ҹjdk1.8жҳҜеңЁй“ҫиЎЁе°ҫйғЁжҸ’е…Ҙж–°иҠӮзӮ№
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// еҰӮжһңеҪ“еүҚй“ҫиЎЁдёӯзҡ„е…ғзҙ еӨ§дәҺж ‘еҢ–зҡ„йҳҲеҖјпјҢиҝӣиЎҢй“ҫиЎЁиҪ¬ж ‘зҡ„ж“ҚдҪң
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//еңЁй“ҫиЎЁдёӯ继з»ӯеҲӨж–ӯжҳҜеҗҰе·Із»ҸеӯҳеңЁе®Ңе…ЁзӣёеҗҢзҡ„key
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//иө°еҲ°иҝҷйҮҢпјҢиҜҙжҳҺжң¬ж¬ЎputжҳҜжӣҙж–°дёҖдёӘе·ІеӯҳеңЁзҡ„й”®еҖјеҜ№зҡ„value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//еңЁhashMapдёӯпјҢafterNodeAccessж–№жі•дҪ“дёәз©әпјҢдәӨз»ҷеӯҗзұ»еҺ»е®һзҺ°
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//еҰӮжһңеҪ“еүҚsizeи¶…иҝҮдёҙз•ҢеҖјпјҢе°ұжү©е®№гҖӮжіЁж„ҸжҳҜе…ҲжҸ’е…ҘиҠӮзӮ№еҶҚжү©е®№
if (++size > threshold)
resize();
//еңЁhashMapдёӯпјҢafterNodeInsertionж–№жі•дҪ“дёәз©әпјҢдәӨз»ҷеӯҗзұ»еҺ»е®һзҺ°
afterNodeInsertion(evict);
return null;}resize() ж•°з»„жү©е®№
з”ЁдәҺеҲқе§ӢеҢ–ж•°з»„жҲ–ж•°з»„жү©е®№пјҢжҜҸж¬Ўжү©е®№еҗҺпјҢе®№йҮҸдёәеҺҹжқҘзҡ„ 2 еҖҚпјҢ并иҝӣиЎҢж•°жҚ®иҝҒ移
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) { // еҜ№еә”ж•°з»„жү©е®№
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// е°Ҷж•°з»„еӨ§е°Ҹжү©еӨ§дёҖеҖҚ
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// е°ҶйҳҲеҖјжү©еӨ§дёҖеҖҚ
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // еҜ№еә”дҪҝз”Ё new HashMap(int initialCapacity) еҲқе§ӢеҢ–еҗҺпјҢ第дёҖж¬Ў put зҡ„ж—¶еҖҷ
newCap = oldThr;
else {// еҜ№еә”дҪҝз”Ё new HashMap() еҲқе§ӢеҢ–еҗҺпјҢ第дёҖж¬Ў put зҡ„ж—¶еҖҷ
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
// з”Ёж–°зҡ„ж•°з»„еӨ§е°ҸеҲқе§ӢеҢ–ж–°зҡ„ж•°з»„
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab; // еҰӮжһңжҳҜеҲқе§ӢеҢ–ж•°з»„пјҢеҲ°иҝҷйҮҢе°ұз»“жқҹдәҶпјҢиҝ”еӣһ newTab еҚіеҸҜ
if (oldTab != null) {
// ејҖе§ӢйҒҚеҺҶеҺҹж•°з»„пјҢиҝӣиЎҢж•°жҚ®иҝҒ移гҖӮ
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// еҰӮжһңиҜҘж•°з»„дҪҚзҪ®дёҠеҸӘжңүеҚ•дёӘе…ғзҙ пјҢйӮЈе°ұз®ҖеҚ•дәҶпјҢз®ҖеҚ•иҝҒ移иҝҷдёӘе…ғзҙ е°ұеҸҜд»ҘдәҶ
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// еҰӮжһңжҳҜзәўй»‘ж ‘пјҢе…·дҪ“жҲ‘们е°ұдёҚеұ•ејҖдәҶ
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
// иҝҷеқ—жҳҜеӨ„зҗҶй“ҫиЎЁзҡ„жғ…еҶөпјҢ
// йңҖиҰҒе°ҶжӯӨй“ҫиЎЁжӢҶжҲҗдёӨдёӘй“ҫиЎЁпјҢж”ҫеҲ°ж–°зҡ„ж•°з»„дёӯпјҢ并且дҝқз•ҷеҺҹжқҘзҡ„е…ҲеҗҺйЎәеәҸ
// loHeadгҖҒloTail еҜ№еә”дёҖжқЎй“ҫиЎЁпјҢhiHeadгҖҒhiTail еҜ№еә”еҸҰдёҖжқЎй“ҫиЎЁпјҢд»Јз ҒиҝҳжҳҜжҜ”иҫғз®ҖеҚ•зҡ„
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
// 第дёҖжқЎй“ҫиЎЁ
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 第дәҢжқЎй“ҫиЎЁзҡ„ж–°зҡ„дҪҚзҪ®жҳҜ j + oldCapпјҢиҝҷдёӘеҫҲеҘҪзҗҶи§Ј
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;}get()иҝҮзЁӢ
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;}final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// еҲӨж–ӯ第дёҖдёӘиҠӮзӮ№жҳҜдёҚжҳҜе°ұжҳҜйңҖиҰҒзҡ„
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
// еҲӨж–ӯжҳҜеҗҰжҳҜзәўй»‘ж ‘
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// й“ҫиЎЁйҒҚеҺҶ
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;}2.5 е…¶д»–ж–№жі•
HashSetжҳҜеҜ№HashMapзҡ„з®ҖеҚ•еҢ…иЈ…пјҢе…¶д»–иҝҳжңүиҝӯд»ЈеҷЁзӯү
3гҖҒжҖ»з»“
е…ідәҺж•°з»„жү©е®№пјҢд»ҺputValжәҗд»Јз ҒдёӯжҲ‘们еҸҜд»ҘзҹҘйҒ“пјҢеҪ“жҸ’е…ҘдёҖдёӘе…ғзҙ зҡ„ж—¶еҖҷsizeе°ұеҠ 1пјҢиӢҘsizeеӨ§дәҺthresholdзҡ„ж—¶еҖҷпјҢе°ұдјҡиҝӣиЎҢжү©е®№гҖӮеҒҮи®ҫжҲ‘们зҡ„capacityеӨ§е°Ҹдёә32пјҢloadFatorдёә0.75пјҢеҲҷthresholdдёә24 = 32 * 0.75пјҢжӯӨж—¶пјҢжҸ’е…ҘдәҶ25дёӘе…ғзҙ пјҢ并且жҸ’е…Ҙзҡ„иҝҷ25дёӘе…ғзҙ йғҪеңЁеҗҢдёҖдёӘжЎ¶дёӯпјҢжЎ¶дёӯзҡ„ж•°жҚ®з»“жһ„дёәзәўй»‘ж ‘пјҢеҲҷиҝҳжңү31дёӘжЎ¶жҳҜз©әзҡ„пјҢд№ҹдјҡиҝӣиЎҢжү©е®№еӨ„зҗҶпјҢе…¶е®һжӯӨж—¶пјҢиҝҳжңү31дёӘжЎ¶жҳҜз©әзҡ„пјҢеҘҪеғҸдјјд№ҺдёҚйңҖиҰҒиҝӣиЎҢжү©е®№еӨ„зҗҶпјҢдҪҶжҳҜжҳҜйңҖиҰҒжү©е®№еӨ„зҗҶзҡ„пјҢеӣ дёәжӯӨж—¶жҲ‘们зҡ„capacityеӨ§е°ҸеҸҜиғҪдёҚйҖӮеҪ“гҖӮжҲ‘们еүҚйқўзҹҘйҒ“пјҢжү©е®№еӨ„зҗҶдјҡйҒҚеҺҶжүҖжңүзҡ„е…ғзҙ пјҢж—¶й—ҙеӨҚжқӮеәҰеҫҲй«ҳпјӣеүҚйқўжҲ‘们иҝҳзҹҘйҒ“пјҢз»ҸиҝҮдёҖж¬Ўжү©е®№еӨ„зҗҶеҗҺпјҢе…ғзҙ дјҡжӣҙеҠ еқҮеҢҖзҡ„еҲҶеёғеңЁеҗ„дёӘжЎ¶дёӯпјҢдјҡжҸҗеҚҮи®ҝй—®ж•ҲзҺҮгҖӮжүҖд»ҘиҜҙе°ҪйҮҸйҒҝе…ҚиҝӣиЎҢжү©е®№еӨ„зҗҶпјҢд№ҹе°ұж„Ҹе‘ізқҖпјҢйҒҚеҺҶе…ғзҙ жүҖеёҰжқҘзҡ„еқҸеӨ„еӨ§дәҺе…ғзҙ еңЁжЎ¶дёӯеқҮеҢҖеҲҶеёғжүҖеёҰжқҘзҡ„еҘҪеӨ„гҖӮ
HashMapеңЁJDK1.8д»ҘеүҚжҳҜдёҖдёӘй“ҫиЎЁж•ЈеҲ—иҝҷж ·дёҖдёӘж•°жҚ®з»“жһ„пјҢиҖҢеңЁJDK1.8д»ҘеҗҺжҳҜдёҖдёӘж•°з»„еҠ й“ҫиЎЁеҠ зәўй»‘ж ‘зҡ„ж•°жҚ®з»“жһ„
йҖҡиҝҮжәҗз Ғзҡ„еӯҰд№ пјҢHashMapжҳҜдёҖдёӘиғҪеҝ«йҖҹйҖҡиҝҮkeyиҺ·еҸ–еҲ°valueеҖјеҫ—дёҖдёӘйӣҶеҗҲпјҢеҺҹеӣ жҳҜеҶ…йғЁдҪҝз”Ёзҡ„жҳҜhashжҹҘжүҫеҖјеҫ—ж–№жі•
еҸҰеӨ–LinkedHashMapжҳҜHashMapзҡ„зӣҙжҺҘеӯҗзұ»пјҢдәҢиҖ…е”ҜдёҖзҡ„еҢәеҲ«жҳҜLinkedHashMapеңЁHashMapзҡ„еҹәзЎҖдёҠпјҢйҮҮз”ЁеҸҢеҗ‘й“ҫиЎЁ(doubly-linked list)зҡ„еҪўејҸе°ҶжүҖжңү**entry**иҝһжҺҘиө·жқҘпјҢиҝҷж ·жҳҜдёәдҝқиҜҒе…ғзҙ зҡ„иҝӯд»ЈйЎәеәҸи·ҹжҸ’е…ҘйЎәеәҸзӣёеҗҢ
е…ӯгҖҒCollectionsе·Ҙе…·зұ»
1гҖҒжҰӮиҝ°
жӯӨзұ»е®Ңе…Ёз”ұеңЁ collection дёҠиҝӣиЎҢж“ҚдҪңжҲ–иҝ”еӣһ collection зҡ„йқҷжҖҒж–№жі•з»„жҲҗгҖӮе®ғеҢ…еҗ«еңЁ collection дёҠж“ҚдҪңзҡ„еӨҡжҖҒз®—жі•пјҢеҚівҖңеҢ…иЈ…еҷЁвҖқпјҢеҢ…иЈ…еҷЁиҝ”еӣһз”ұжҢҮе®ҡ collection ж”ҜжҢҒзҡ„ж–° collectionпјҢд»ҘеҸҠе°‘ж•°е…¶д»–еҶ…е®№гҖӮеҰӮжһңдёәжӯӨзұ»зҡ„ж–№жі•жүҖжҸҗдҫӣзҡ„ collection жҲ–зұ»еҜ№иұЎдёә nullпјҢеҲҷиҝҷдәӣж–№жі•йғҪе°ҶжҠӣеҮәNullPointerException
2гҖҒжҺ’еәҸеёёз”Ёж–№жі•
//еҸҚиҪ¬еҲ—иЎЁдёӯе…ғзҙ зҡ„йЎәеәҸ
static void reverse(List<?> list)
//еҜ№ListйӣҶеҗҲе…ғзҙ иҝӣиЎҢйҡҸжңәжҺ’еәҸ
static void shuffle(List<?> list)
//ж №жҚ®е…ғзҙ зҡ„иҮӘ然йЎәеәҸ еҜ№жҢҮе®ҡеҲ—иЎЁжҢүеҚҮеәҸиҝӣиЎҢжҺ’еәҸ
static void sort(List<T> list)
//ж №жҚ®жҢҮе®ҡжҜ”иҫғеҷЁдә§з”ҹзҡ„йЎәеәҸеҜ№жҢҮе®ҡеҲ—иЎЁиҝӣиЎҢжҺ’еәҸ
static <T> void sort(List<T> list, Comparator<? super T> c)
//еңЁжҢҮе®ҡListзҡ„жҢҮе®ҡдҪҚзҪ®i,jеӨ„дәӨжҚўе…ғзҙ
static void swap(List<?> list, int i, int j)
//еҪ“distanceдёәжӯЈж•°ж—¶пјҢе°ҶListйӣҶеҗҲзҡ„еҗҺdistanceдёӘе…ғзҙ вҖңж•ҙдҪ“вҖқ移еҲ°еүҚйқўпјӣеҪ“distanceдёәиҙҹж•°ж—¶пјҢе°ҶlistйӣҶеҗҲзҡ„еүҚdistanceдёӘе…ғзҙ вҖңж•ҙдҪ“вҖқ移еҲ°еҗҺиҫ№гҖӮиҜҘж–№жі•дёҚдјҡж”№еҸҳйӣҶеҗҲзҡ„й•ҝеәҰ
static void rotate(List<?> list, int distance)
3гҖҒжҹҘжүҫгҖҒжӣҝжҚўж“ҚдҪң
//дҪҝз”ЁдәҢеҲҶжҗңзҙўжі•жҗңзҙўжҢҮе®ҡеҲ—иЎЁпјҢд»ҘиҺ·еҫ—жҢҮе®ҡеҜ№иұЎеңЁListйӣҶеҗҲдёӯзҡ„зҙўеј•
//жіЁж„ҸпјҡжӯӨеүҚеҝ…йЎ»дҝқиҜҒListйӣҶеҗҲдёӯзҡ„е…ғзҙ е·Із»ҸеӨ„дәҺжңүеәҸзҠ¶жҖҒ
static <T> int binarySearch(List<? extends Comparable<? super T>>list, T key)
//ж №жҚ®е…ғзҙ зҡ„иҮӘ然йЎәеәҸпјҢиҝ”еӣһз»ҷе®ҡcollection зҡ„жңҖеӨ§е…ғзҙ
static Object max(Collection coll)
//ж №жҚ®жҢҮе®ҡжҜ”иҫғеҷЁдә§з”ҹзҡ„йЎәеәҸпјҢиҝ”еӣһз»ҷе®ҡ collection зҡ„жңҖеӨ§е…ғзҙ
static Object max(Collection coll,Comparator comp):
//ж №жҚ®е…ғзҙ зҡ„иҮӘ然йЎәеәҸпјҢиҝ”еӣһз»ҷе®ҡcollection зҡ„жңҖе°Ҹе…ғзҙ
static Object min(Collection coll):
//ж №жҚ®жҢҮе®ҡжҜ”иҫғеҷЁдә§з”ҹзҡ„йЎәеәҸпјҢиҝ”еӣһз»ҷе®ҡ collection зҡ„жңҖе°Ҹе…ғзҙ
static Object min(Collection coll,Comparator comp):
//дҪҝз”ЁжҢҮе®ҡе…ғзҙ жӣҝжҚўжҢҮе®ҡеҲ—иЎЁдёӯзҡ„жүҖжңүе…ғзҙ
static <T> void fill(List<? super T> list,T obj)
//иҝ”еӣһжҢҮе®ҡco1lectionдёӯзӯүдәҺжҢҮе®ҡеҜ№иұЎзҡ„еҮәзҺ°ж¬Ўж•°
static int frequency(collection<?>c,object o)
//иҝ”еӣһжҢҮе®ҡжәҗеҲ—иЎЁдёӯ第дёҖж¬ЎеҮәзҺ°жҢҮе®ҡзӣ®ж ҮеҲ—иЎЁзҡ„иө·е§ӢдҪҚзҪ®пјӣеҰӮжһңжІЎжңүеҮәзҺ°иҝҷж ·зҡ„еҲ—иЎЁпјҢеҲҷиҝ”еӣһ-1
static int indexofsubList(List<?>source, List<?>target)
//иҝ”еӣһжҢҮе®ҡжәҗеҲ—иЎЁдёӯжңҖеҗҺдёҖж¬ЎеҮәзҺ°жҢҮе®ҡзӣ®ж ҮеҲ—иЎЁзҡ„иө·е§ӢдҪҚзҪ®пјӣеҰӮжһңжІЎжңүеҮәзҺ°иҝҷж ·зҡ„еҲ—иЎЁпјҢеҲҷиҝ”еӣһ-1
static int lastIndexofsubList(List<?>source,List<?>target)
//дҪҝз”ЁдёҖдёӘж–°еҖјжӣҝжҚўListеҜ№иұЎзҡ„жүҖжңүж—§еҖјo1dval
static <T> boolean replaceA1l(list<T> list,T oldval,T newval)
4гҖҒеҗҢжӯҘжҺ§еҲ¶
CollectonsжҸҗдҫӣдәҶеӨҡдёӘsynchronizedXxx()ж–№жі•пјҢиҜҘж–№жі•еҸҜд»Ҙе°ҶжҢҮе®ҡйӣҶеҗҲеҢ…иЈ…жҲҗзәҝзЁӢеҗҢжӯҘзҡ„йӣҶеҗҲпјҢд»ҺиҖҢи§ЈеҶіеӨҡзәҝзЁӢ并еҸ‘и®ҝй—®йӣҶеҗҲж—¶зҡ„зәҝзЁӢе®үе…Ёй—®йўҳгҖӮжӯЈеҰӮеүҚйқўд»Ӣз»Қзҡ„HashSetпјҢTreeSetпјҢarrayListпјҢLinkedListпјҢHashMapпјҢTreeMapйғҪжҳҜзәҝзЁӢдёҚе®үе…Ёзҡ„гҖӮCollectionsжҸҗдҫӣдәҶеӨҡдёӘйқҷжҖҒж–№жі•еҸҜд»ҘжҠҠ他们еҢ…иЈ…жҲҗзәҝзЁӢеҗҢжӯҘзҡ„йӣҶеҗҲгҖӮ
//иҝ”еӣһжҢҮе®ҡ Collection ж”ҜжҢҒзҡ„еҗҢжӯҘпјҲзәҝзЁӢе®үе…Ёзҡ„пјүcollection
static <T> Collection<T> synchronizedCollection(Collection<T> c)
//иҝ”еӣһжҢҮе®ҡеҲ—иЎЁж”ҜжҢҒзҡ„еҗҢжӯҘпјҲзәҝзЁӢе®үе…Ёзҡ„пјүеҲ—иЎЁ
static <T> List<T> synchronizedList(List<T> list)
//иҝ”еӣһз”ұжҢҮе®ҡжҳ е°„ж”ҜжҢҒзҡ„еҗҢжӯҘпјҲзәҝзЁӢе®үе…Ёзҡ„пјүжҳ е°„
static <K,V> Map<K,V> synchronizedMap(Map<K,V> m)
//иҝ”еӣһжҢҮе®ҡ set ж”ҜжҢҒзҡ„еҗҢжӯҘпјҲзәҝзЁӢе®үе…Ёзҡ„пјүset
static <T> Set<T> synchronizedSet(Set<T> s)
5гҖҒCollectionи®ҫзҪ®дёҚеҸҜеҸҳйӣҶеҗҲ
//иҝ”еӣһдёҖдёӘз©әзҡ„гҖҒдёҚеҸҜеҸҳзҡ„йӣҶеҗҲеҜ№иұЎпјҢжӯӨеӨ„зҡ„йӣҶеҗҲж—ўеҸҜд»ҘжҳҜListпјҢд№ҹеҸҜд»ҘжҳҜSetпјҢиҝҳеҸҜд»ҘжҳҜMapгҖӮ
emptyXxx()
//иҝ”еӣһдёҖдёӘеҸӘеҢ…еҗ«жҢҮе®ҡеҜ№иұЎпјҲеҸӘжңүдёҖдёӘжҲ–дёҖдёӘе…ғзҙ пјүзҡ„дёҚеҸҜеҸҳзҡ„йӣҶеҗҲеҜ№иұЎпјҢжӯӨеӨ„зҡ„йӣҶеҗҲеҸҜд»ҘжҳҜпјҡListпјҢSetпјҢMapгҖӮ
singletonXxx():
//иҝ”еӣһжҢҮе®ҡйӣҶеҗҲеҜ№иұЎзҡ„дёҚеҸҜеҸҳи§ҶеӣҫпјҢжӯӨеӨ„зҡ„йӣҶеҗҲеҸҜд»ҘжҳҜпјҡListпјҢSetпјҢMap
unmodifiableXxx()
ж„ҹи°ўдҪ иғҪеӨҹи®Өзңҹйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« пјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„вҖңJavaйӣҶеҗҲжЎҶжһ¶жҳҜд»Җд№ҲвҖқиҝҷзҜҮж–Үз« еҜ№еӨ§е®¶жңүеё®еҠ©пјҢеҗҢж—¶д№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘пјҢе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶзӯүзқҖдҪ жқҘеӯҰд№ !





