本篇内容介绍了“Python怎么实现将Excel内容批量导出为PDF文件”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
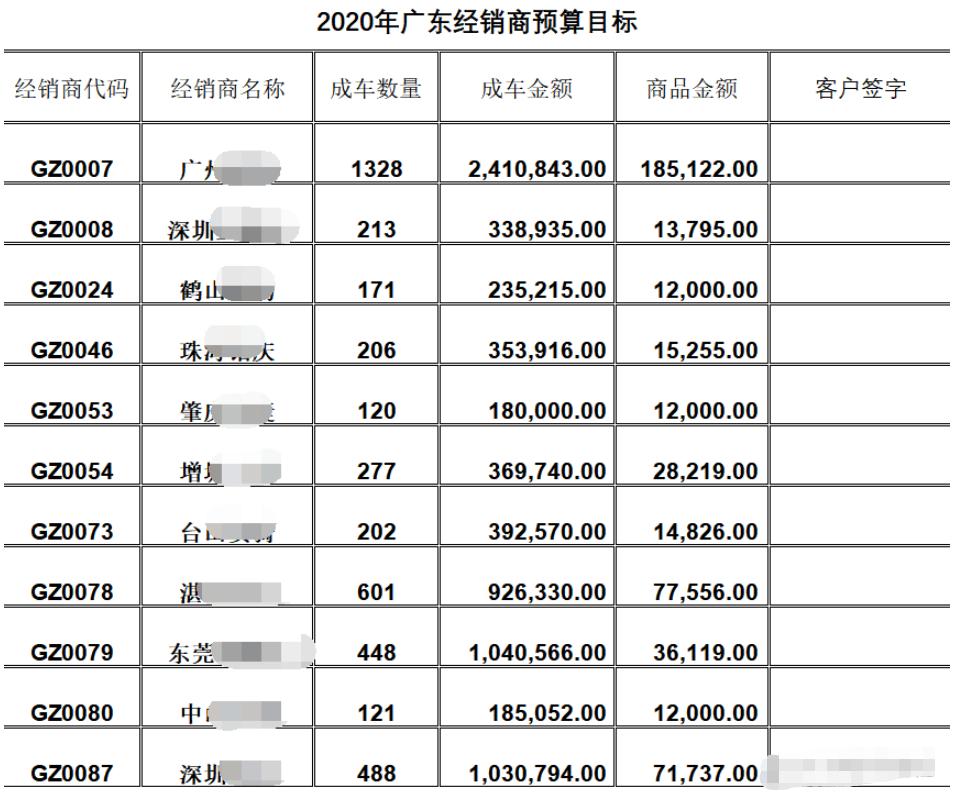
部分数据
然后需要安装一下这个软件 wkhtmltopdf
效果展示
数据单独导出为一个PDF

import pdfkit
import openpyxl
import os
target_dir = '经销商预算'
if not os.path.exists(target_dir):
os.mkdir(target_dir)
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<style>
table {
font-size: 22px;
font-weight: bolder;
width: 850px;
}
</style>
</head>
<body>
<table border="1" align="center" cellspacing="1">
<tr>
<td class='title' align="center" colspan="6">2020年广东经销商预算目标</td>
</tr>
<tr>
<td>经销商代码</td>
<td>经销商名称</td>
<td>成车数量</td>
<td>成车金额</td>
<td>商品金额</td>
<td>客户签字</td>
</tr>
<tr>
<td>[code]</td>
<td>{name}</td>
<td>{number}</td>
<td>{money}</td>
<td>{total}</td>
<td></td>
</tr>
</table>
</body>
</html>
"""
def html_to_pdf(filename_html, filename_pdf):
"""HTML 2 PDF"""
config = pdfkit.configuration(wkhtmltopdf='D:\\wkhtmltopdf\\bin\\wkhtmltopdf.exe')
pdfkit.from_file(filename_html, filename_pdf, configuration=config)
wb = openpyxl.load_workbook('2020经销商目标.xlsx')
sheet = wb['Sheet1']
print(sheet.rows)
for row in list(sheet.rows)[3:]:
data = [value.value for value in row]
data = data[1:-1]
format_html = html.replace('[code]', data[0])
format_html = format_html.replace('{name}', data[1])
format_html = format_html.replace('{number}', str(data[2]))
format_html = format_html.replace('{money}', f'{data[3]:.2f}')
format_html = format_html.replace('{total}', f'{data[4]:.2f}')
with open('example.html', mode='w', encoding='utf-8') as f:
f.write(format_html)
html_to_pdf('example.html', target_dir + os.path.sep + data[0] + " " + data[1] + '.pdf')“Python怎么实现将Excel内容批量导出为PDF文件”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



