这篇文章主要介绍“Redis热点数据问题怎么解决”,在日常操作中,相信很多人在Redis热点数据问题怎么解决问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Redis热点数据问题怎么解决”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!

问题分析:上次听群里大佬面试阿里 p7 就被问到这个问题,难度指数五颗星,对我等小白着实是加分项。
答:关于热点数据问题我有话要说,这个问题我早在刚刚学习使用 Redis 时就从已经意识到了,所以在使用时会刻意避免,坚决不会给自己挖坑,热点数据最大的问题会造成 Reids 集群负载不均衡(也就是数据倾斜)导致的故障,这些问题对于 Redis 集群都是致命打击。
先说说造成 Reids 集群负载不均衡故障的主要原因:
高访问量的 Key,也就是热 key,根据过去的维护经验一个 key 访问的 QPS 超过 1000 就要高度关注了,比如热门商品,热门话题等。
大 Value,有些 key 访问 QPS 虽然不高,但是由于 value 很大,造成网卡负载较大,网卡流量被打满,单台机器可能出现千兆 / 秒,IO 故障。
热点 Key + 大 Value 同时存在,服务器杀手。
那么热点 key 或大 Value 会造成哪些故障呢:
数据倾斜问题:大 Value 会导致集群不同节点数据分布不均匀,造成数据倾斜问题,大量读写比例非常高的请求都会落到同一个 redis server 上,该 redis 的负载就会严重升高,容易打挂。
QPS 倾斜:分片上的 QPS 不均。
大 Value 会导致 Redis 服务器缓冲区不足,造成 get 超时。
由于 Value 过大,导致机房网卡流量不足。
Redis 缓存失效导致数据库层被击穿的连锁反应。
答:这个问题的解决办法比较宽泛,要具体看不同业务场景,比如公司组织促销活动,那参加促销的商品肯定是有办法提前统计的,这种场景就可以通过预估法。对于突发事件,不确定因素,Redis 会自己监控热点数据。大概归纳下:
提前获知法:
根据业务,人肉统计 or 系统统计可能会成为热点的数据,如,促销活动商品,热门话题,节假日话题,纪念日活动等。
Redis 客户端收集法:
调用端通过计数的方式统计 key 的请求次数,但是无法预知 key 的个数,代码侵入性强。
public Connection sendCommand(final ProtocolCommand cmd, final byte[]... args) {
//从参数中获取key
String key = analysis(args);
//计数
counterKey(key);
//ignore
}Redis 集群代理层统计:
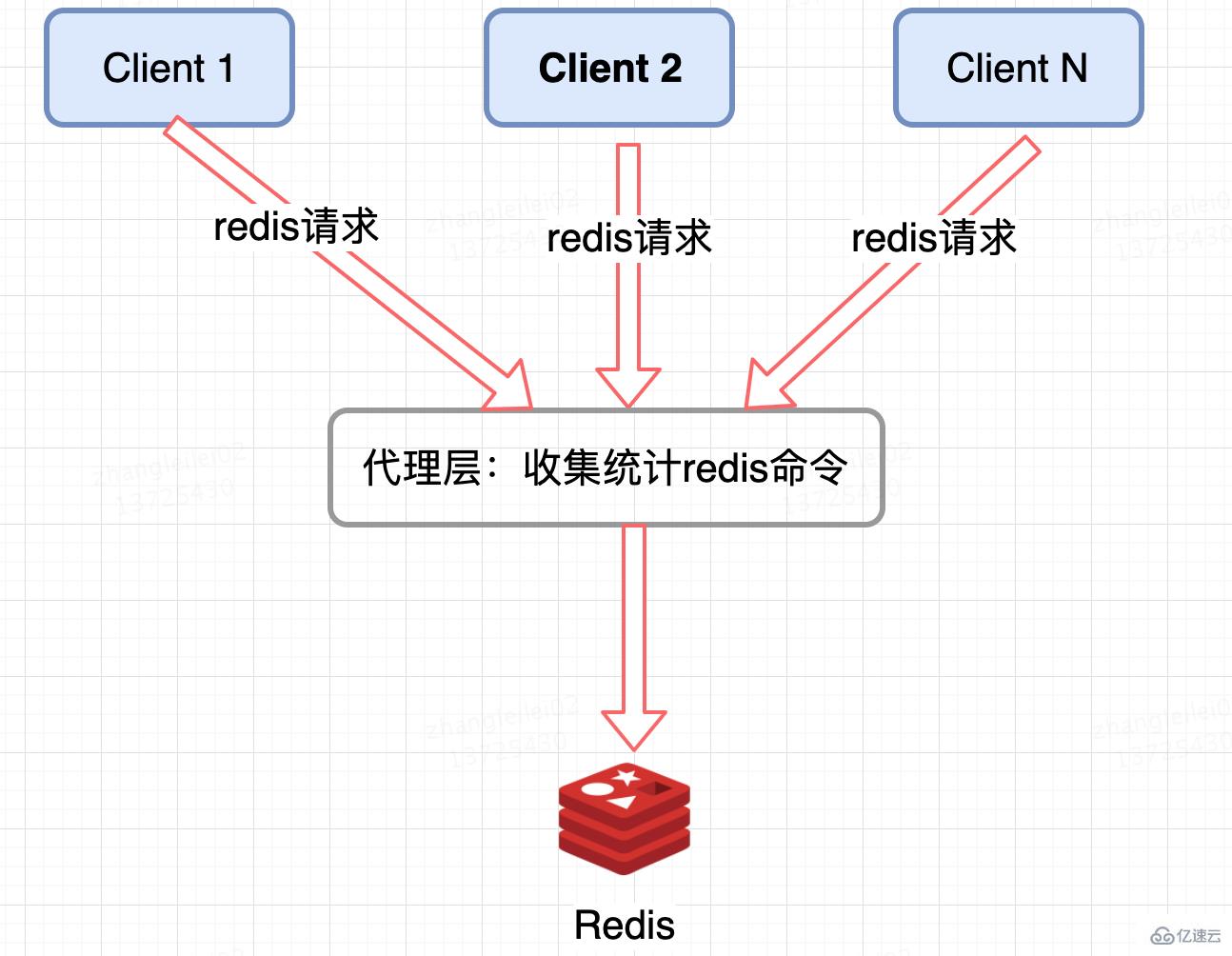
像 Twemproxy,codis 这些基于代理的 Redis 分布式架构,统一的入口,可以在 Proxy 层做收集上报,但是缺点很明显,并非所有的 Redis 集群架构都有 proxy。
Redis 服务端收集:
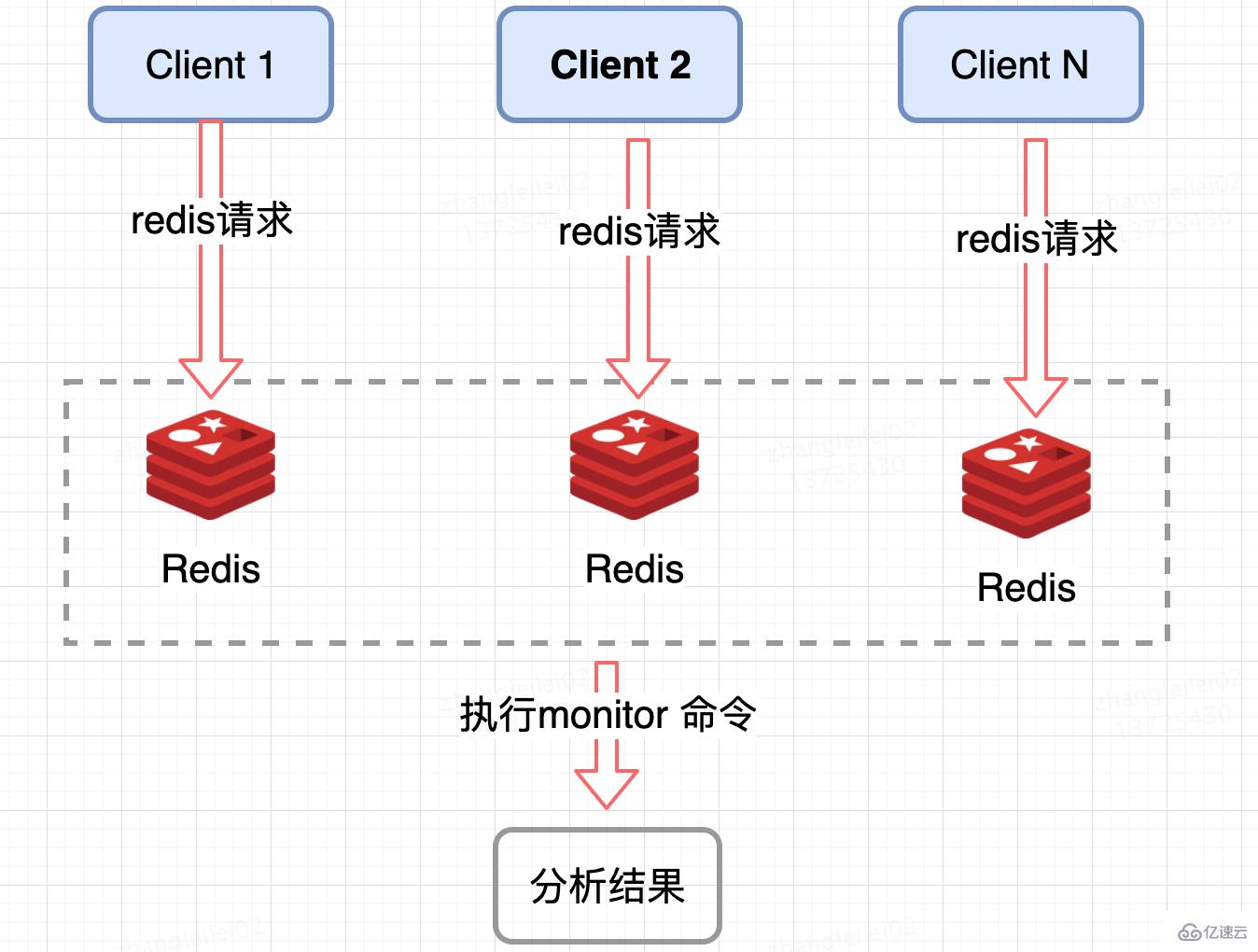
监控 Redis 单个分片的 QPS,发现 QPS 倾斜到一定程度的节点进行 monitor,获取热点 key, Redis 提供了 monitor 命令,可以统计出一段时间内的某 Redis 节点上的所有命令,分析热点 key,在高并发条件下,会存在内存暴涨和 Redis 性能的隐患,所以此种方法适合在短时间内使用;同样只能统计一个 Redis 节点的热点 key,对于集群需要汇总统计,业务角度讲稍微麻烦一点。
以上为说的这 4 个方法都是现在业界比较常用的,方法,我通过学习 Redis 源码还有一个新的想法。第 5 种:修改 Redis 源码。
修改 Redis 源代码:(从读源码中想到的思路)
我发现 Redis4.0 为我们带来了许多新特性,其中便包括基于 LFU 的热点 key 发现机制,有了这个新特性,我们就可以在此基础上实现热点 key 的统计,这个只是我的个人思路。
面试官心理:小伙子还挺有想法,思路挺开阔,还打起了修改源码的注意,我都没这个野心。团队里就需要这样的人。
(发现问题,分析问题,解决问题,不等面试官发问,直接讲述如何解决热点数据问题,这才是核心内容)
答:关于如何治理热点数据问题,解决这个问题主要从两个方面考虑,第一是数据分片,让压力均摊到集群的多个分片上,防止单个机器打挂,第二是迁移隔离。
概括总结:
key 拆分:
如果当前 key 的类型是一个二级数据结构,例如哈希类型。如果该哈希元素个数较多,可以考虑将当前 hash 进行拆分,这样该热点 key 可以拆分为若干个新的 key 分布到不同 Redis 节点上,从而减轻压力
迁移热点 key:
以 Redis Cluster 为例,可以将热点 key 所在的 slot 单独迁移到一个新的 Redis 节点上,这样这个热点 key 即使 QPS 很高,也不会影响到整个集群的其他业务,还可以定制化开发,热点 key 自动迁移到独立节点上,这种方案也较多副本。
热点 key 限流:
对于读命令我们可以通过迁移热点 key 然后添加从节点来解决,对于写命令我们可以通过单独针对这个热点 key 来限流。
增加本地缓存:
对于数据一致性不是那么高的业务,可以将热点 key 缓存到业务机器的本地缓存中,因为是业务端的本地内存中,省去了一次远程的 IO 调用。但是当数据更新时,可能会造成业务和 Redis 数据不一致。
面试官:你回答得很好,考虑得很全面。
问题分析:相比热点 key 大概念,大 Value 的概念比好好理解,由于 Redis 是单线程运行的,如果一次操作的 value 很大会对整个 redis 的响应时间造成负面影响,因为 Redis 是 Key - Value 结构数据库,大 value 就是单个 value 占用内存较大,对 Redis 集群造成最直接的影响就是数据倾斜。
答:(想难倒我?我可是有备而来。)
我先说说多大的 Value 算大,根据公司基础架构给出的经验值可做以下划分:
注:(经验值不是标准,都是根据集群运维人员长期观察线上 case 总结出来的)
大:string 类型 value > 10K,set、list、hash、zset 等集合数据类型中的元素个数 > 1000。
超大: string 类型 value > 100K,set、list、hash、zset 等集合数据类型中的元素个数 > 10000。
由于 Redis 是单线程运行的,如果一次操作的 value 很大会对整个 redis 的响应时间造成负面影响,所以,业务上能拆则拆,下面举几个典型的分拆方案:
一个较大的 key-value 拆分成几个 key-value ,将操作压力平摊到多个 redis 实例中,降低对单个 redis 的 IO 影响
将分拆后的几个 key-value 存储在一个 hash 中,每个 field 代表一个具体的属性,使用 hget,hmget 来获取部分的 value,使用 hset,hmset 来更新部分属性。
hash、set、zset、list 中存储过多的元素
类似于场景一中的第一个做法,可以将这些元素分拆。
以 hash 为例,原先的正常存取流程是:
hget(hashKey, field); hset(hashKey, field, value)
现在,固定一个桶的数量,比如 10000,每次存取的时候,先在本地计算 field 的 hash 值,模除 10000,确定该 field 落在哪个 key 上,核心思想就是将 value 打散,每次只 get 你需要的。
newHashKey = hashKey + (hash(field) % 10000); hset(newHashKey, field, value); hget(newHashKey, field)
到此,关于“Redis热点数据问题怎么解决”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





