这篇文章主要介绍“python数据处理之Pandas类型转换怎么实现”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“python数据处理之Pandas类型转换怎么实现”文章能帮助大家解决问题。
tips['sex_str'] = tips['sex'].astype(str)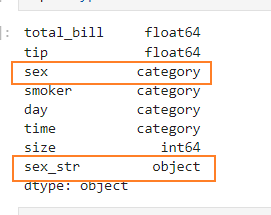
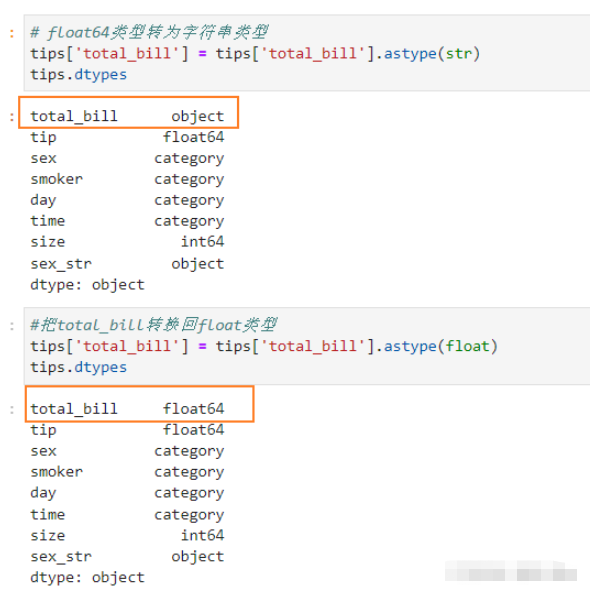
DataFrame每一列的数据类型必须相同,当有些数据中有缺失,但不是NaN时(如missing,null等),会使整列数据变成字符串类型而不是数值型,这个时候可以使用to_numeric处理
#创造包含'missing'为缺失值的数据
tips_sub_miss = tips.head(10)
tips_sub_miss.loc[[1,3,5,7],'total_bill'] = 'missing'
tips_sub_miss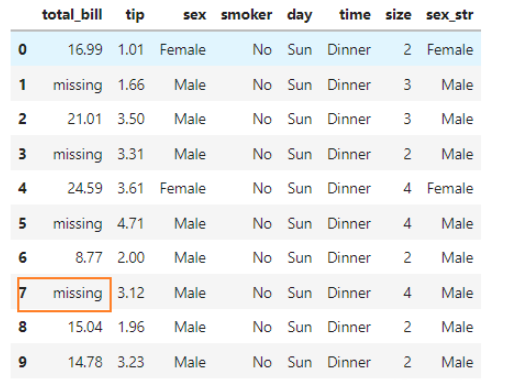
自动转换为了字符串类型:
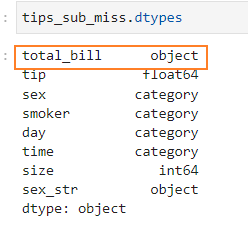
使用astype转换报错:
tips_sub_miss['total_bill'].astype(float)
使用to_numeric()函数:
直接使用to_numeric()函数还是会报错,添加errors参数
errors可变参数:
ignore 遇到错误跳过 (只是跳过没转类型)
coerce 遇到不能转的值强转为NaN
pd.to_numeric(tips_sub_miss['total_bill'],errors='ignore')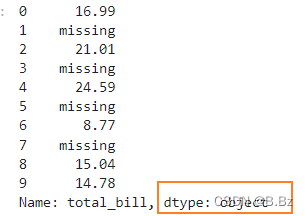
pd.to_numeric(tips_sub_miss['total_bill'],errors='coerce')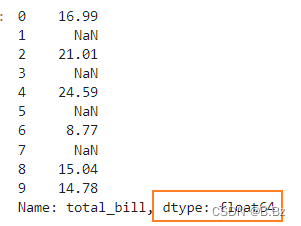
to_numeric向下转型:
downcast参数
integer 和 signed最小的有符号int dtype
float 最小的float dtype
unsigned 最小的无符号int dtype
downcast参数设置为float之后, total_bill的数据类型由float64变为float32
pd.to_numeric(tips_sub_miss['total_bill'],errors='coerce',downcast='float')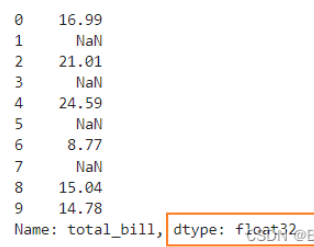
利用pd.Categorical()创建categorical数据,Categorical()常用三个参数
参1 values,如果values中的值,不在categories参数中,会被NaN代替
参2 categories,指定可能存在的类别数据
参3 ordered, 是否指定顺序
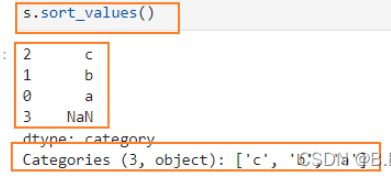
s = pd.Series(pd.Categorical(["a","b","c","d"],categories=['c','b','a']))
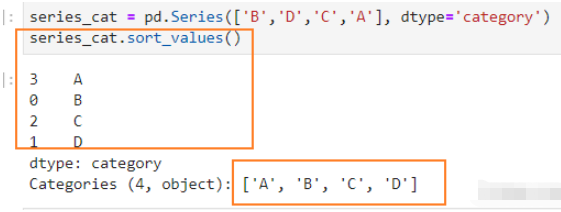
分类数据排序会自动根据分类排序:
ordered指定顺序:
from pandas.api.types import CategoricalDtype
# 创建一个分类 ordered 指定顺序
cat = CategoricalDtype(categories=['B','D','A','C'],ordered=True)
# 指定series_cat1转换类型为创建的分类类型
series_cat1 = series_cat.astype(cat)
print(series_cat.sort_values())
print(series_cat1.sort_values())
| 知识点 | 内容 |
|---|---|
| Numpy的特点 | 1. Numpy是一个高效科学计算库,Pandas的数据计算功能是对Numpy的封装 2. ndarray是Numpy的基本数据结构,Pandas的Series和DataFrame好多函数和属性都与ndarray一样 3. Numpy的计算效率比原生Python效率高很多,并且支持并行计算 |
| Pandas数据类型转换 | 1. Pandas除了数值型的int 和 float类型外,还有object ,category,bool,datetime类型 2. 可以通过as_type 和 to_numeric 函数进行数据类型转换 |
| Pandas 分类数据类型 | 1. category类型,可以用来进行排序,并且可以自定义排序顺序 2. CategoricalDtype可以用来定义顺序 |
关于“python数据处理之Pandas类型转换怎么实现”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识,可以关注亿速云行业资讯频道,小编每天都会为大家更新不同的知识点。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



