жҖҺд№Ҳз”ЁnodeжҠ“еҸ–е°ҸиҜҙз« иҠӮ
жң¬ж–Үе°Ҹзј–дёәеӨ§е®¶иҜҰз»Ҷд»Ӣз»ҚвҖңжҖҺд№Ҳз”ЁnodeжҠ“еҸ–е°ҸиҜҙз« иҠӮвҖқпјҢеҶ…е®№иҜҰз»ҶпјҢжӯҘйӘӨжё…жҷ°пјҢз»ҶиҠӮеӨ„зҗҶеҰҘеҪ“пјҢеёҢжңӣиҝҷзҜҮвҖңжҖҺд№Ҳз”ЁnodeжҠ“еҸ–е°ҸиҜҙз« иҠӮвҖқж–Үз« иғҪеё®еҠ©еӨ§е®¶и§ЈеҶіз–‘жғ‘пјҢдёӢйқўи·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘеӯҰд№ ж–°зҹҘиҜҶеҗ§гҖӮ

еҮҶеӨҮз”ЁelectronеҲ¶дҪңдёҖдёӘе°ҸиҜҙйҳ…иҜ»е·Ҙе…·з»ғз»ғжүӢпјҢйӮЈд№ҲйҰ–е…ҲиҰҒи§ЈеҶізҡ„е°ұжҳҜж•°жҚ®й—®йўҳпјҢд№ҹе°ұжҳҜе°ҸиҜҙзҡ„ж–Үжң¬гҖӮ
иҝҷйҮҢеҮҶеӨҮдҪҝз”ЁnodejsеҜ№е°ҸиҜҙзҪ‘з«ҷиҝӣиЎҢзҲ¬иҷ«зҲ¬еҸ–пјҢе°қиҜ•зҲ¬дёӢдёҖжң¬е°ҸиҜҙпјҢж•°жҚ®е°ұдёҚеӯҳж”ҫж•°жҚ®еә“дәҶпјҢе…ҲдҪҝз”ЁtxtдҪңдёәж–Үжң¬еӯҳеӮЁ
еңЁnodeдёӯеҜ№дәҺзҪ‘з«ҷзҡ„иҜ·жұӮпјҢжң¬иә«е°ұеӯҳеңЁhttpе’Ңhttpsеә“пјҢеҶ…йғЁеҗ«жңүrequestиҜ·жұӮж–№жі•гҖӮ
е®һдҫӢ:
request = https.request(TestUrl, { encoding:'utf-8' }, (res)=>{
let chunks = ''
res.on('data', (chunk)=>{
chunks += chunk
})
res.on('end',function(){
console.log('иҜ·жұӮз»“жқҹ');
})
})дҪҶжҳҜд№ҹе°ұеҲ°жӯӨдёәжӯўдәҶпјҢеҸӘжҳҜеӯҳеҸ–дәҶдёҖдёӘhtmlзҡ„ж–Үжң¬ж•°жҚ®пјҢ并дёҚиғҪеӨҹеҜ№еҶ…йғЁе…ғзҙ иҝӣиЎҢжҸҗеҸ–д№Ӣзұ»зҡ„е·ҘдҪңпјҲд№ҹеҸҜд»ҘжӯЈеҲҷжӢҝпјҢдҪҶжҳҜеӨӘиҝҮеӨҚжқӮпјүгҖӮ
жҲ‘е°Ҷи®ҝй—®еҲ°зҡ„ж•°жҚ®йҖҡиҝҮfs.writeFileж–№жі•еӯҳеӮЁиө·жқҘдәҶпјҢиҝҷеҸӘжҳҜж•ҙдёӘзҪ‘йЎөзҡ„html
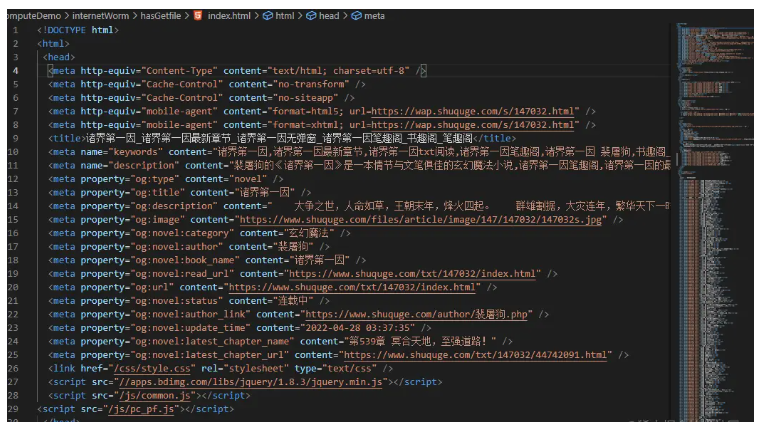
дҪҶжҳҜжҲ‘жғіиҰҒзҡ„иҝҳжңүеҗ„дёӘз« иҠӮдёӯзҡ„еҶ…е®№пјҢиҝҷж ·дёҖжқҘе°ұйңҖиҰҒиҺ·еҸ–з« иҠӮзҡ„и¶…й“ҫжҺҘпјҢз»„жҲҗи¶…й“ҫжҺҘй“ҫиЎЁиҝӣеҺ»зҲ¬еҸ–
cheerioеә“
еңЁж–ҮжЎЈдёӯпјҢеҸҜд»ҘдҪҝз”ЁзӨәдҫӢиҝӣиЎҢи°ғиҜ•
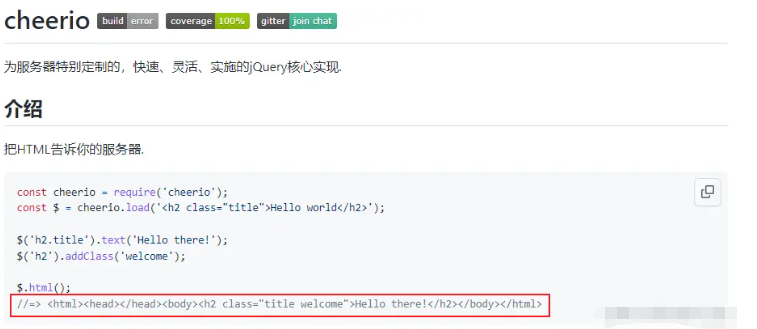
дҪҝз”Ёcheerioи§ЈжһҗHTML
cheerioи§Јжһҗhtmlж—¶пјҢиҺ·еҸ–domиҠӮзӮ№зҡ„ж–№ејҸдёҺjqueryзӣёдјјгҖӮ
ж №жҚ®д№ӢеүҚиҺ·еҸ–еҲ°зҡ„д№ҰзұҚйҰ–йЎөзҡ„htmlпјҢжҹҘжүҫиҮӘе·ұжғіиҰҒзҡ„domиҠӮзӮ№ж•°жҚ®
const fs = require('fs')
const cheerio = require('cheerio');
// еј•е…ҘиҜ»еҸ–ж–№жі•
const { getFile, writeFun } = require('./requestNovel')
let hasIndexPromise = getFile('./hasGetfile/index.html');
let bookArray = [];
hasIndexPromise.then((res)=>{
let htmlstr = res;
let $ = cheerio.load(htmlstr);
$(".listmain dl dd a").map((index, item)=>{
let name = $(item).text(), href = 'https://www.shuquge.com/txt/147032/' + $(item).attr('href')
if (index > 11){
bookArray.push({ name, href })
}
})
// console.log(bookArray)
writeFun('./hasGetfile/hrefList.txt', JSON.stringify(bookArray), 'w')
})жү“еҚ°дёҖдёӢдҝЎжҒҜ
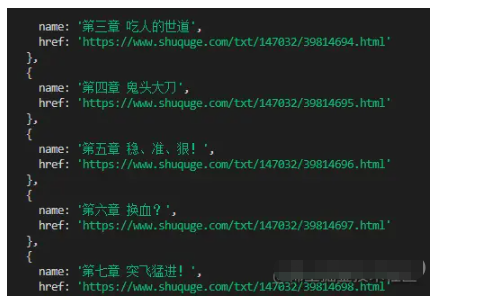
еҸҜд»ҘеҗҢж—¶е°ҶиҝҷдәӣдҝЎжҒҜд№ҹеӯҳеӮЁиө·жқҘ
зҺ°еңЁз« иҠӮж•°е’Ңз« иҠӮзҡ„й“ҫжҺҘйғҪжңүдәҶпјҢйӮЈд№Ҳе°ұеҸҜд»ҘиҺ·еҸ–з« иҠӮзҡ„еҶ…е®№дәҶгҖӮ
еӣ дёәжү№йҮҸзҲ¬еҸ–жңҖеҗҺйңҖиҰҒIPд»ЈзҗҶпјҢиҝҷйҮҢиҝҳжІЎеҮҶеӨҮпјҢжҡӮж—¶е…ҲеҶҷиҺ·еҸ–жҹҗдёҖз« иҠӮе°ҸиҜҙзҡ„еҶ…е®№ж–№жі•
зҲ¬еҸ–жҹҗдёҖз« иҠӮзҡ„еҶ…е®№е…¶е®һд№ҹжҜ”иҫғз®ҖеҚ•пјҡ
// зҲ¬еҸ–жҹҗдёҖз« иҠӮзҡ„еҶ…е®№ж–№жі•
function getOneChapter(n) {
return new Promise((resolve, reject)=>{
if (n >= bookArray.length) {
reject('жңӘиғҪжүҫеҲ°')
}
let name = bookArray[n].name;
request = https.request(bookArray[n].href, { encoding:'gbk' }, (res)=>{
let html = ''
res.on('data', chunk=>{
html += chunk;
})
res.on('end', ()=>{
let $ = cheerio.load(html);
let content = $("#content").text();
if (content) {
// еҶҷжҲҗtxt
writeFun(`./hasGetfile/${name}.txt`, content, 'w')
resolve(content);
} else {
reject('жңӘиғҪжүҫеҲ°')
}
})
})
request.end();
})
}
getOneChapter(10)
иҝҷж ·пјҢе°ұеҸҜд»Ҙж №жҚ®дёҠйқўзҡ„ж–№жі•пјҢжқҘеҲӣйҖ дёҖдёӘи°ғз”ЁжҺҘеҸЈпјҢдј е…ҘдёҚеҗҢзҡ„з« иҠӮеҸӮж•°пјҢиҺ·еҸ–еҪ“еүҚз« иҠӮзҡ„ж•°жҚ®
const express = require('express');
const IO = express();
const { getAllChapter, getOneChapter } = require('./readIndex')
// иҺ·еҸ–з« иҠӮи¶…й“ҫжҺҘй“ҫиЎЁ
getAllChapter();
IO.use('/book',function(req, res) {
// еҸӮж•°
let query = req.query;
if (query.n) {
// иҺ·еҸ–жҹҗдёҖз« иҠӮж•°жҚ®
let promise = getOneChapter(parseInt(query.n - 1));
promise.then((d)=>{
res.json({ d: d })
}, (d)=>{
res.json({ d: d })
})
} else {
res.json({ d: 404 })
}
})
//жңҚеҠЎеҷЁжң¬ең°дё»жңәзҡ„ж•°еӯ—
IO.listen('7001',function(){
console.log("еҗҜеҠЁдәҶгҖӮгҖӮгҖӮ");
})иҜ»еҲ°иҝҷйҮҢпјҢиҝҷзҜҮвҖңжҖҺд№Ҳз”ЁnodeжҠ“еҸ–е°ҸиҜҙз« иҠӮвҖқж–Үз« е·Із»Ҹд»Ӣз»Қе®ҢжҜ•пјҢжғіиҰҒжҺҢжҸЎиҝҷзҜҮж–Үз« зҡ„зҹҘиҜҶзӮ№иҝҳйңҖиҰҒеӨ§е®¶иҮӘе·ұеҠЁжүӢе®һи·өдҪҝз”ЁиҝҮжүҚиғҪйўҶдјҡпјҢеҰӮжһңжғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





