这篇文章主要介绍“Python线程的创建与常用方法是什么”,在日常操作中,相信很多人在Python线程的创建与常用方法是什么问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Python线程的创建与常用方法是什么”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!

在Python中有很多的多线程模块,其中 threading 模块就是比较常用的。下面就来看一下如何利用 threading 创建线程以及它的常用方法。
函数名 介绍 举例 Thread 创建线程 Thread(target, args) Thread 的动能介绍:通过调用
threading模块的Thread类来实例化一个线程对象;它有两个参数:target 与 args(与创建进程时,参数相同)。target为创建线程时要执行的函数,而args为是要执行这个函数时需要传入的参数。
接下里看一下线程对象中都有哪些常用的方法:
函数名 介绍 用法 start 启动线程 start() join 阻塞线程直到线程执行结束 join(timeout=None) getName 获取线程的名字 getName() setName 设置线程的名字 setName(name) is_alive 判断线程是否存活 is_alive() setDaemon 守护线程 setDaemon(True)
start 函数:启动一个线程;没有任何返回值和参数。
join 函数:和进程中的 join 函数一样;阻塞当前的程序,主线程的任务需要等待当前子线程的任务结束后才可以继续执行;参数为
timeout:代表阻塞的超时时间。getName 函数:获取当前线程的名字。
setName 函数:给当前的线程设置名字;参数为
name:是一个字符串类型is_alive 函数:判断当前线程的状态是否存货
setDaemon 函数:它是一个守护线程;如果脚本任务执行完成之后,即便进程池还没有执行完成业务也会被强行终止。子线程也是如此,如果希望主进程或者是主线程先执行完自己的业务之后,依然允许子线程继续工作而不是强行关闭它们,只需要设置
setDaemon()为True就可以了。PS:通过上面的介绍,会发现其实线程对象里面的函数几乎和进程对象中的函数非常相似,它们的使用方法和使用场景几乎是相同的。
演示 多线程之前 先看一下下面这个案例,运行结束后看看共计耗时多久
1、定义一个列表,里面写一些内容。
2、再定义一个新列表,将上一个列表的内容随机写入到新列表中;并且删除上一个列表中随机获取到的内容。
3、这里需要使用到
r andom内置模块
代码示例如下:
# coding:utf-8import timeimport random
old_lists = ['罗马假日', '怦然心动', '时空恋旅人', '天使爱美丽', '天使之城', '倒霉爱神', '爱乐之城']new_lists = []def work():
if len(old_lists) == 0: # 判断 old_list 的长度,如果为0 ,则表示 该列表的内容已经被删光了
return '\'old_list\' 列表内容已经全部删除'
old_choice_data = random.choice(old_lists) # random 模块的 choice函数可以随机获取传入的 old_list 的元素
old_lists.remove(old_choice_data) # 当获取到这个随机元素之后,将该元素从 old_lists 中删除
new_choice_data = '%s_new' % old_choice_data # 将随机获取到的随机元素通过格式化方式重新赋值,区别于之前的元素
new_lists.append(new_choice_data) # 将格式化的新的随机元素添加至 new_lists 列表
time.sleep(1)if __name__ == '__main__':
strat_time = time.time()
for i in range(len(old_lists)):
work()
if len(old_lists) ==0:
print('\'old_lists\' 当前为:{}'.format(None))
else:
print(('\'old_lists\' 当前为:{}'.format(old_lists)))
if not len(new_lists) == 0:
print(('\'new_lists\' 当前为:{}'.format(new_lists)))
else:
print('\'new_lists\' 当前为:{}'.format(None))
end_time = time.time()
print('运行结束,累计耗时:{} 秒'.format(end_time - strat_time))运行结果如下:
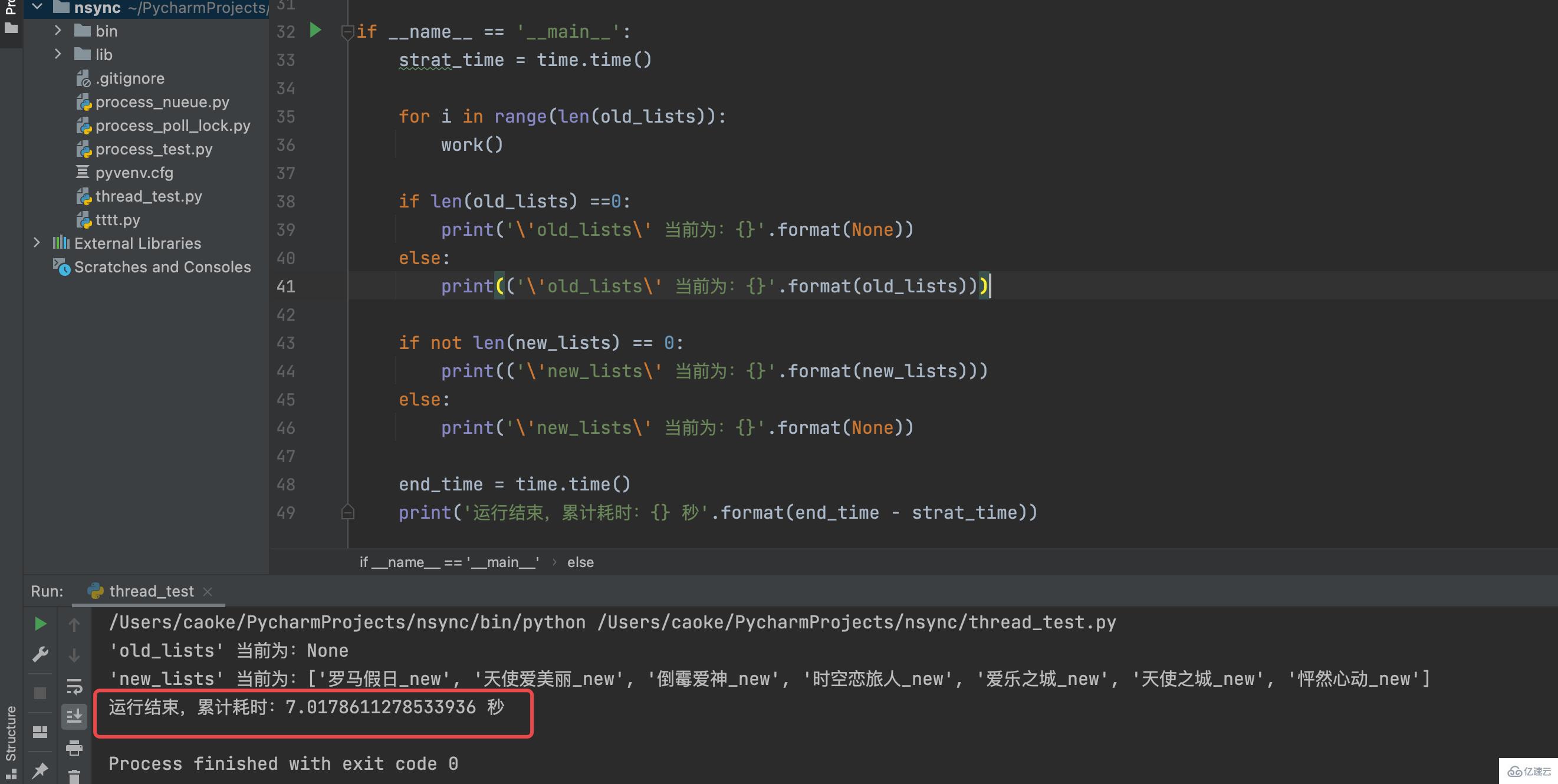
从运行输出结果我们可以看到整个脚本运行共计耗时7秒,而且 new_lists 列表内的元素都经过格式化处理后加上了 _new ;不仅如此, 因为 random模块的choice函数 原因,new_lists 的内容顺序与 old_lists 也是不一样;每次运行顺序都会不一样,所以 old_lists 的顺序是无法得到保障的。
代码示例如下:
# coding:utf-8import timeimport randomimport threading
old_lists = ['罗马假日', '怦然心动', '时空恋旅人', '天使爱美丽', '天使之城', '倒霉爱神', '爱乐之城']new_lists = []def work():
if len(old_lists) == 0: # 判断 old_list 的长度,如果为0 ,则表示 该列表的内容已经被删光了
return '\'old_list\' 列表内容已经全部删除'
old_choice_data = random.choice(old_lists) # random 模块的 choice函数可以随机获取传入的 old_list 的元素
old_lists.remove(old_choice_data) # 当获取到这个随机元素之后,将该元素从 old_lists 中删除
new_choice_data = '%s_new' % old_choice_data # 将随机获取到的随机元素通过格式化方式重新赋值,区别于之前的元素
new_lists.append(new_choice_data) # 将格式化的新的随机元素添加至 new_lists 列表
time.sleep(1)if __name__ == '__main__':
strat_time = time.time()
print('\'old_lists\'初始长度为:{}'.format(len(old_lists))) # 获取 old_lists 与 new_lists 最初始的长度
print('\'new_lists\'初始长度为:{}'.format(len(new_lists)))
thread_list = [] # 定义一个空的 thread_list 对象,用以下方添加每个线程
for i in range(len(old_lists)):
thread_work = threading.Thread(target=work) # 定义一个线程实例化对象执行 work 函数,因为 work 函数没有参数所以不用传 args
thread_list.append(thread_work) # 将 thread_work 添加进 thread_list
thread_work.start() # 启动每一个线程
for t in thread_list: # 通过for循环将每一个线程进行阻塞
t.join()
if len(old_lists) ==0:
print('\'old_lists\' 当前为:{}'.format(None), '当前长度为:{}'.format(len(old_lists)))
else:
print(('\'old_lists\' 当前为:{}'.format(old_lists)))
if not len(new_lists) == 0:
print('\'new_lists\' 当前长度为:{}'.format(len(new_lists)))
print('\'new_lists\' 当前的值为:{}'.format(new_lists))
else:
print('\'new_lists\' 当前为:{}'.format(None))
end_time = time.time()
print('运行结束,累计耗时:{} 秒'.format(end_time - strat_time))运行结果如下:
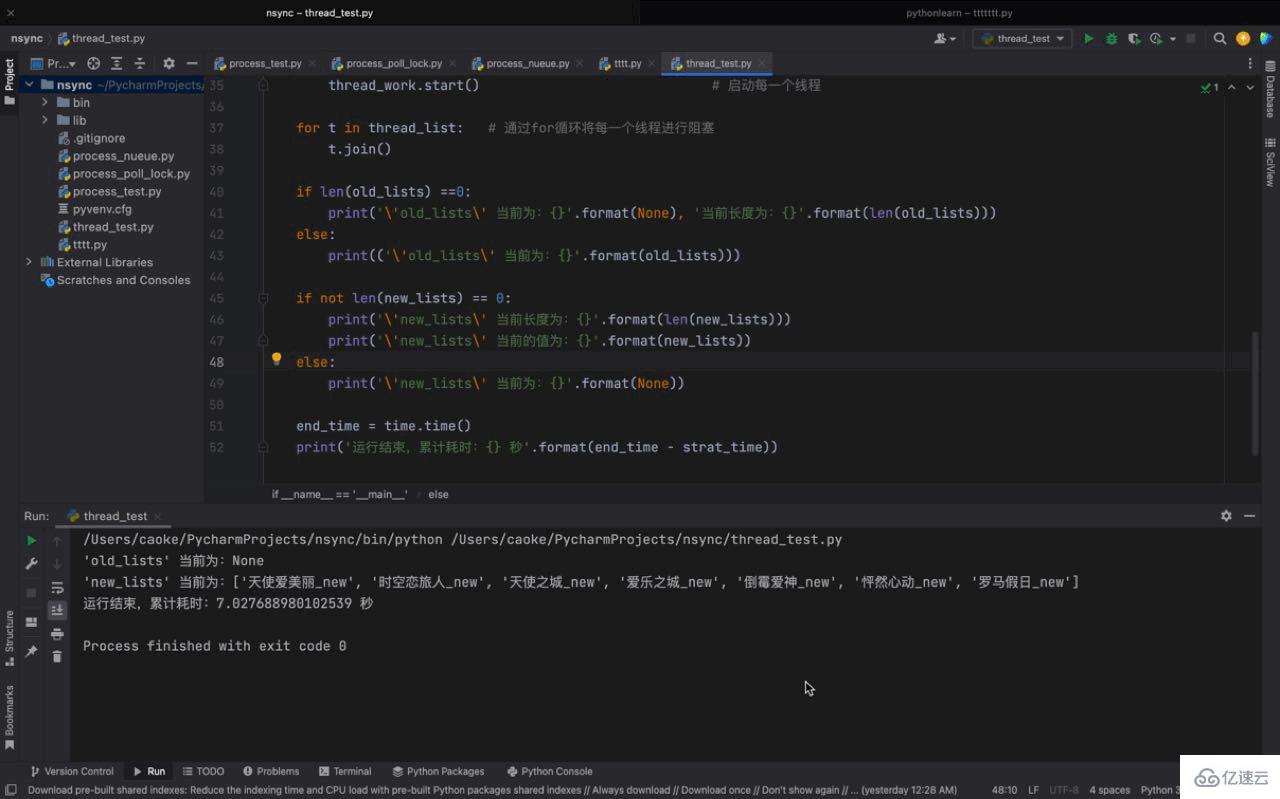
从运行的结果来看,我们初始的单线程任务耗时为 7秒,在使用多线程之后,仅耗时 1秒就完成了,大大的提高了我们的运行效率。
通过上面的练习,我们发现线程的使用方法几乎与进程是一模一样的。它们都可以互不干扰的执行程序,也可以使得主线程的程序不需要等待子线程的任务完成之后再去执行。只不过刚刚的演示案例中我们使用了 join() 函数进行了阻塞,这里可以吧 join() 去掉,看看执行效果。
与进程一样,线程也存在着一定的问题。
线程执行的函数,也同样是无法获取返回值的。
当多个线程同时修改文件一样会造成被修改文件的数据错乱的错误(因为都是并发去操作一个文件,特别是在处理交易场景的时候,需要尤为注意)。
到此,关于“Python线程的创建与常用方法是什么”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



