PythonВ pandasзҙўеј•еҰӮдҪ•и®ҫзҪ®е’Ңдҝ®ж”№
иҝҷзҜҮвҖңPython pandasзҙўеј•еҰӮдҪ•и®ҫзҪ®е’Ңдҝ®ж”№вҖқж–Үз« зҡ„зҹҘиҜҶзӮ№еӨ§йғЁеҲҶдәәйғҪдёҚеӨӘзҗҶи§ЈпјҢжүҖд»Ҙе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеҶ…е®№иҜҰз»ҶпјҢжӯҘйӘӨжё…жҷ°пјҢе…·жңүдёҖе®ҡзҡ„еҖҹйүҙд»·еҖјпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« иғҪжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘзңӢзңӢиҝҷзҜҮвҖңPython pandasзҙўеј•еҰӮдҪ•и®ҫзҪ®е’Ңдҝ®ж”№вҖқж–Үз« еҗ§гҖӮ
еҲӣе»әзҙўеј•
еҝ«йҖҹеӣһйЎҫдёӢPandasеҲӣе»әзҙўеј•зҡ„еёёи§Ғж–№жі•пјҡ
pd.Index
In [1]:
import pandas as pd
import numpy as np
In [2]:
# жҢҮе®ҡзұ»еһӢе’ҢеҗҚз§°
s1 = pd.Index([1,2,3,4,5,6,7],
dtype="int",
name="Peter")
s1
Out[2]:
Int64Index([1, 2, 3, 4, 5, 6, 7], dtype='int64', name='Peter')
pd.IntervalIndex
ж–°зҡ„й—ҙйҡ”зҙўеј• IntervalIndex йҖҡеёёдҪҝз”Ё interval_range()еҮҪж•°жқҘиҝӣиЎҢжһ„йҖ пјҢе®ғдҪҝз”Ёзҡ„жҳҜж•°жҚ®жҲ–иҖ…ж•°еҖјеҢәй—ҙпјҢеҹәжң¬з”Ёжі•пјҡ
In [3]:
s2 = pd.interval_range(start=0, end=6, closed="left")
s2
Out[3]:
IntervalIndex([[0, 1), [1, 2), [2, 3), [3, 4), [4, 5), [5, 6)],
closed='left',
dtype='interval[int64]')
pd.CategoricalIndex
In [4]:
s3 = pd.CategoricalIndex(
# еҫ…жҺ’еәҸзҡ„ж•°жҚ®
["S","M","L","XS","M","L","S","M","L","XL"],
# жҢҮе®ҡеҲҶзұ»йЎәеәҸ
categories=["XS","S","M","L","XL"],
# жҺ’йңҖ
ordered=True,
# зҙўеј•еҗҚеӯ—
name="category"
)
s3
Out[4]:
CategoricalIndex(['S', 'M', 'L', 'XS', 'M', 'L', 'S', 'M', 'L', 'XL'],
categories=['XS', 'S', 'M', 'L', 'XL'],
ordered=True,
name='category',
dtype='category')
pd.DatetimeIndex
д»Ҙж—¶й—ҙе’Ңж—ҘжңҹдҪңдёәзҙўеј•пјҢйҖҡиҝҮdate_rangeеҮҪж•°жқҘз”ҹжҲҗпјҢе…·дҪ“дҫӢеӯҗдёәпјҡ
In [5]:
# ж—ҘжңҹдҪңдёәзҙўеј•пјҢDд»ЈиЎЁеӨ©
s4 = pd.date_range("2022-01-01",periods=6, freq="D")
s4Out[5]:
DatetimeIndex(['2022-01-01', '2022-01-02', '2022-01-03',
'2022-01-04','2022-01-05', '2022-01-06'],
dtype='datetime64[ns]', freq='D')
pd.PeriodIndex
pd.PeriodIndexжҳҜдёҖдёӘдё“й—Ёй’ҲеҜ№е‘ЁжңҹжҖ§ж•°жҚ®зҡ„зҙўеј•пјҢж–№дҫҝй’ҲеҜ№е…·жңүдёҖе®ҡе‘Ёжңҹзҡ„ж•°жҚ®иҝӣиЎҢеӨ„зҗҶпјҢе…·дҪ“з”Ёжі•еҰӮдёӢпјҡ
In [6]:
s5 = pd.PeriodIndex(['2022-01-01', '2022-01-02',
'2022-01-03', '2022-01-04'],
freq = '2H')
s5
Out[6]:
PeriodIndex(['2022-01-01 00:00', '2022-01-02 00:00',
'2022-01-03 00:00','2022-01-04 00:00'],
dtype='period[2H]', freq='2H')
pd.TimedeltaIndex
In [7]:
data = pd.timedelta_range(start='1 day', end='3 days', freq='6H')
data
Out[7]:
TimedeltaIndex(['1 days 00:00:00', '1 days 06:00:00', '1 days 12:00:00',
'1 days 18:00:00', '2 days 00:00:00', '2 days 06:00:00',
'2 days 12:00:00', '2 days 18:00:00', '3 days 00:00:00'],
dtype='timedelta64[ns]', freq='6H')
In [8]:
s6 = pd.TimedeltaIndex(data)
s6
Out[8]:
TimedeltaIndex(['1 days 00:00:00', '1 days 06:00:00', '1 days 12:00:00',
'1 days 18:00:00', '2 days 00:00:00', '2 days 06:00:00',
'2 days 12:00:00', '2 days 18:00:00', '3 days 00:00:00'],
dtype='timedelta64[ns]', freq='6H')
иҜ»еҸ–ж•°жҚ®
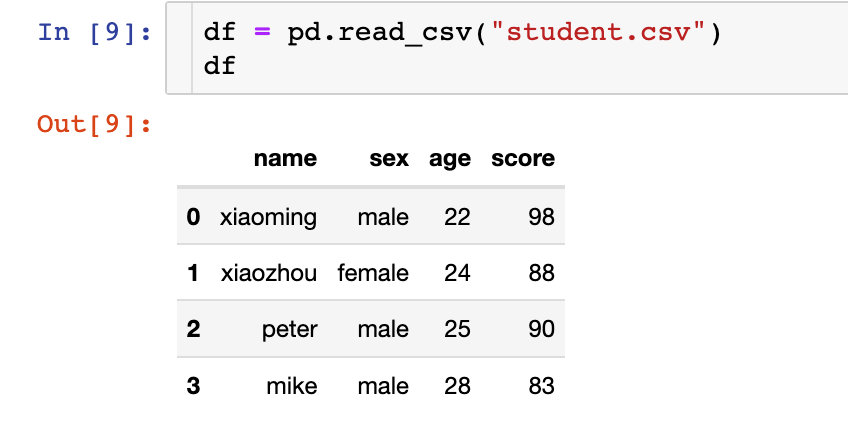
дёӢйқўйҖҡиҝҮдёҖд»Ҫ з®ҖеҚ•зҡ„ж•°жҚ®жқҘи®Іи§Ј4дёӘеҮҪж•°зҡ„дҪҝз”ЁгҖӮж•°жҚ®еҰӮдёӢпјҡ
set_index
и®ҫзҪ®еҚ•еұӮзҙўеј•
In [10]:
# и®ҫзҪ®еҚ•еұӮзҙўеј•
df1 = df.set_index("name")
df1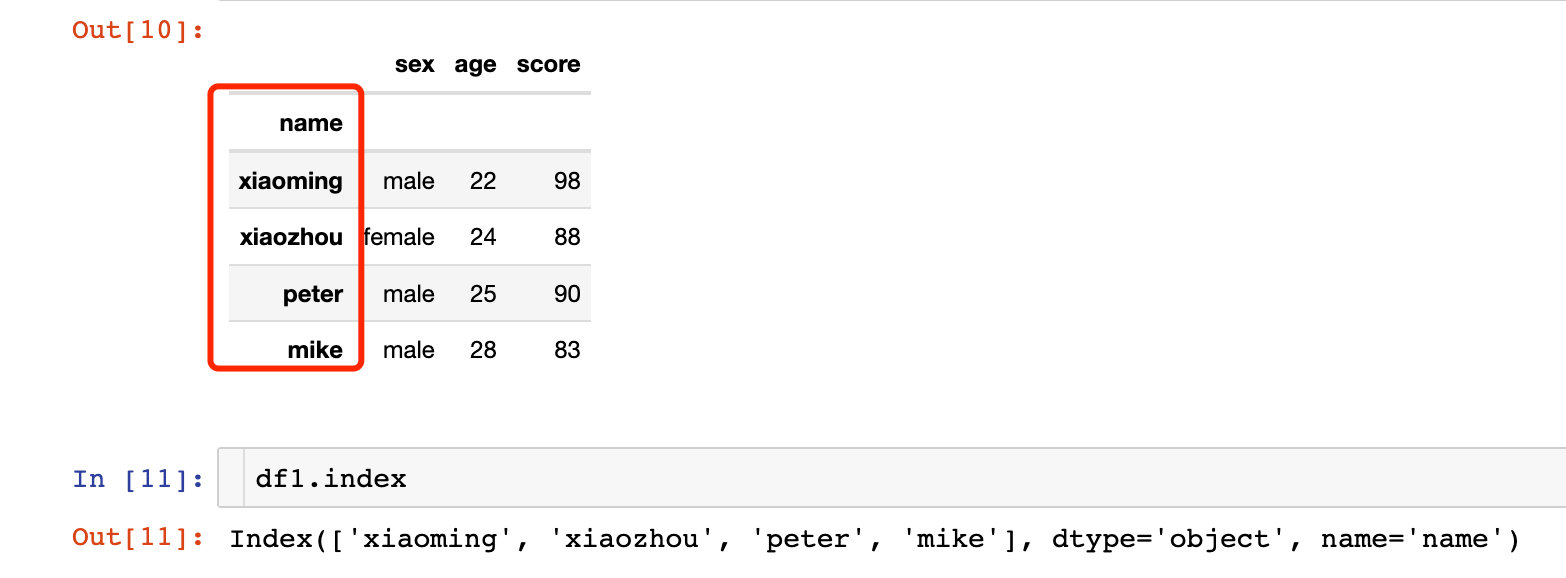
жҲ‘们еҸ‘зҺ°df1зҡ„зҙўеј•е·Із»ҸеҸҳжҲҗдәҶnameеӯ—ж®өзҡ„зӣёе…іеҖјгҖӮ
дёӢйқўжҳҜи®ҫзҪ®еӨҡеұӮзҙўеј•пјҡ
# и®ҫзҪ®дёӨеұӮзҙўеј•
df2 = df.set_index(["sex","name"])
df2

reset_index
еҜ№зҙўеј•зҡ„йҮҚзҪ®пјҡ
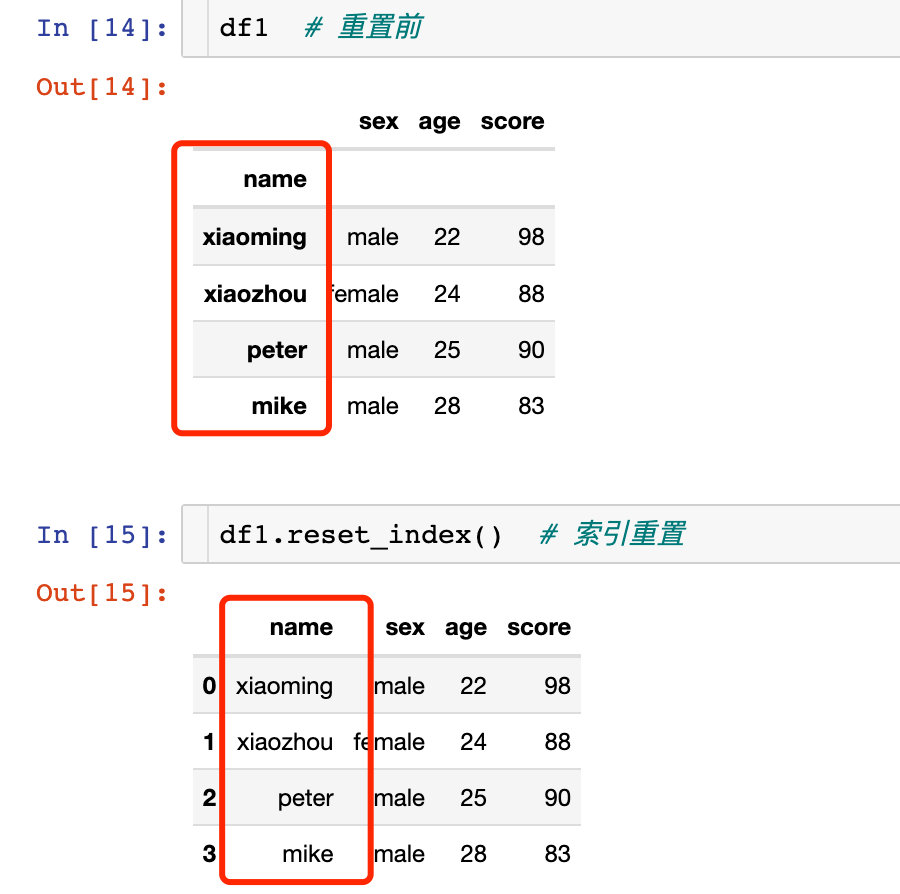
й’ҲеҜ№еӨҡеұӮзҙўеј•зҡ„йҮҚзҪ®пјҡ
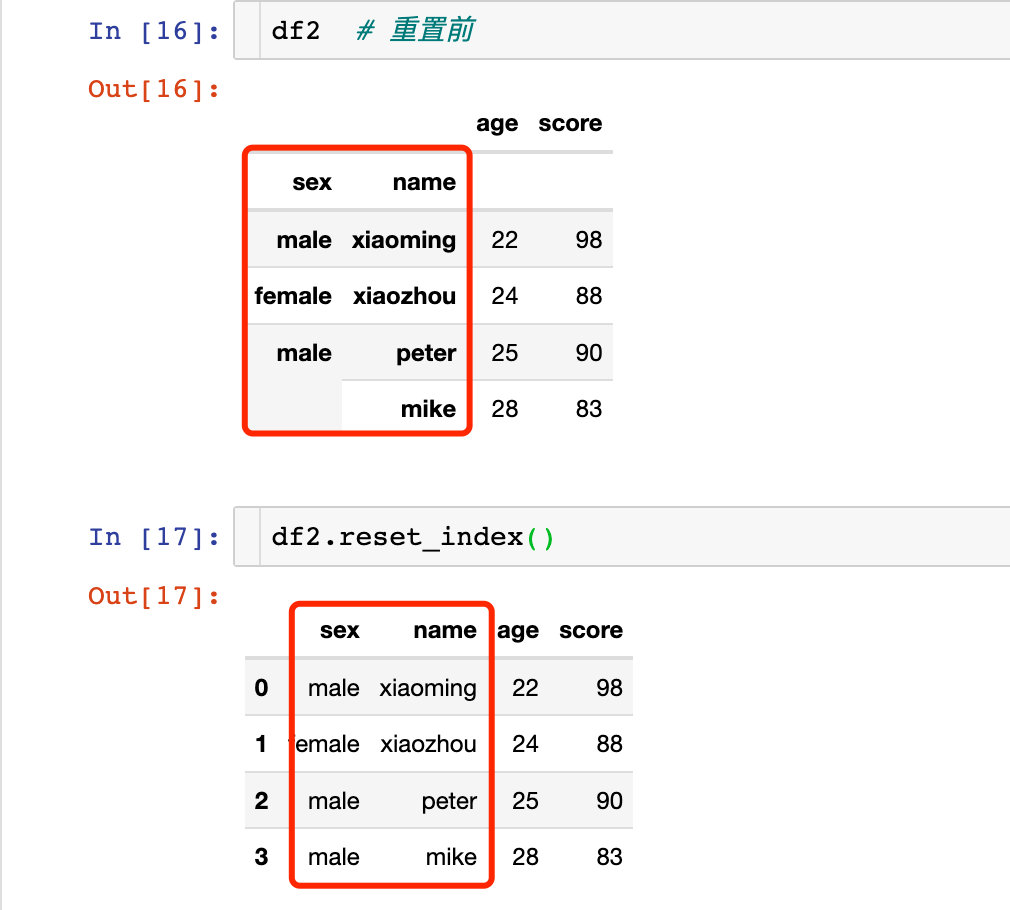
еӨҡеұӮзҙўеј•зӣҙжҺҘеҺҹең°дҝ®ж”№пјҡ
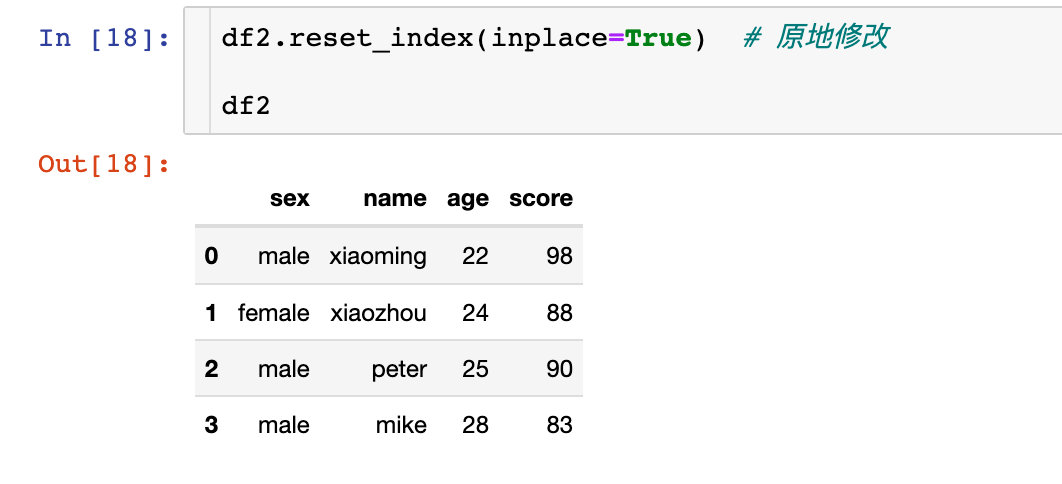
set_axis
е°ҶжҢҮе®ҡзҡ„ж•°жҚ®еҲҶй…Қз»ҷжүҖйңҖиҰҒзҡ„иҪҙaxisгҖӮе…¶дёӯaxis=0д»ЈиЎЁиЎҢж–№еҗ‘пјҢaxis=1д»ЈиЎЁеҲ—ж–№еҗ‘гҖӮ
дёӨз§ҚдёҚеҗҢзҡ„еҶҷжі•пјҡ
axis=0 зӯүд»·дәҺ axis="index"
axis=1 зӯүд»·дәҺ axis="columns"
ж“ҚдҪңиЎҢзҙўеј•
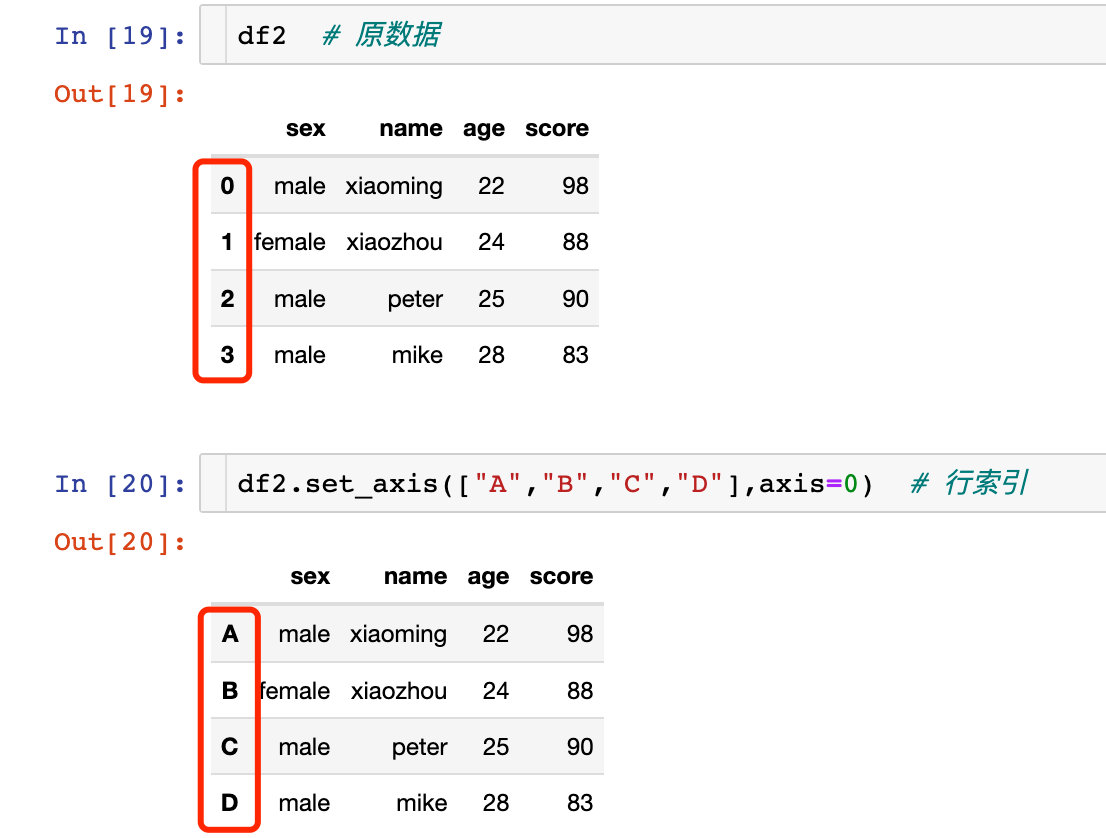
дҪҝз”Ё index ж•ҲжһңзӣёеҗҢпјҡ
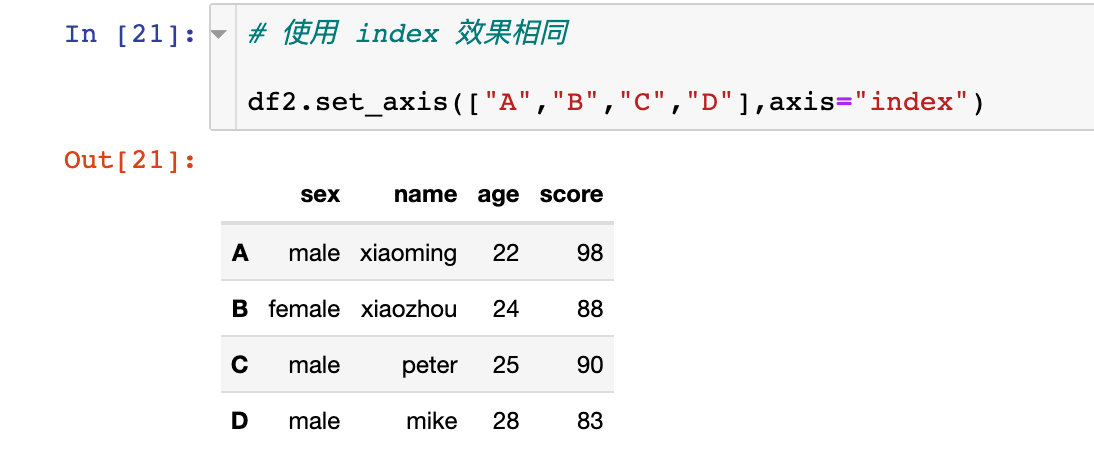
еҺҹжқҘзҡ„df2жҳҜжІЎжңүж”№еҸҳзҡ„гҖӮеҰӮжһңжҲ‘们жғіж”№еҸҳз”ҹж•ҲпјҢеҗҢж ·д№ҹеҸҜд»ҘзӣҙжҺҘеҺҹең°дҝ®ж”№пјҡ
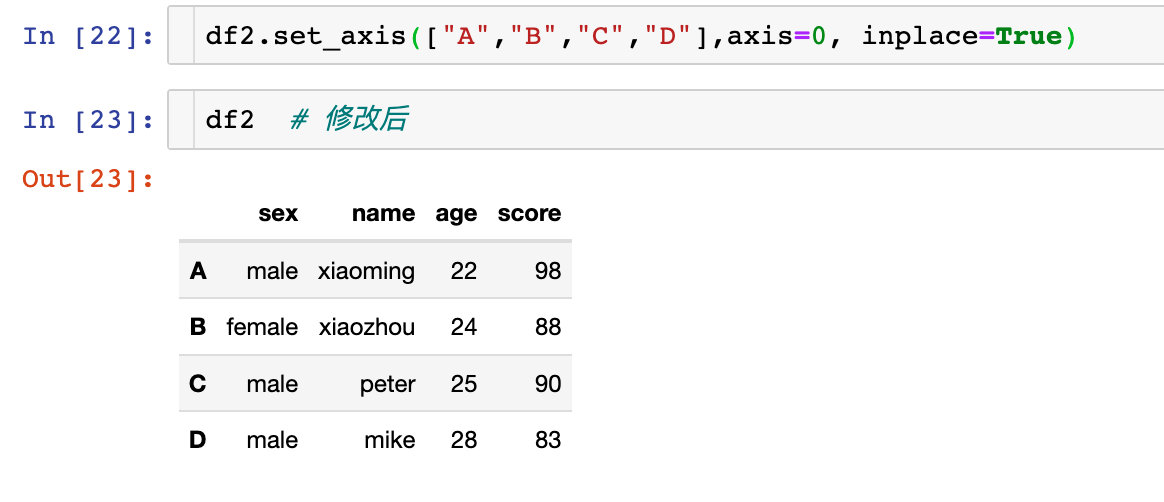
ж“ҚдҪңеҲ—зҙўеј•
й’ҲеҜ№axis=1жҲ–иҖ…axis="columns"ж–№еҗ‘дёҠзҡ„ж“ҚдҪңгҖӮ
1гҖҒзӣҙжҺҘдј е…ҘжҲ‘们йңҖиҰҒдҝ®ж”№зҡ„ж–°еҗҚз§°пјҡ
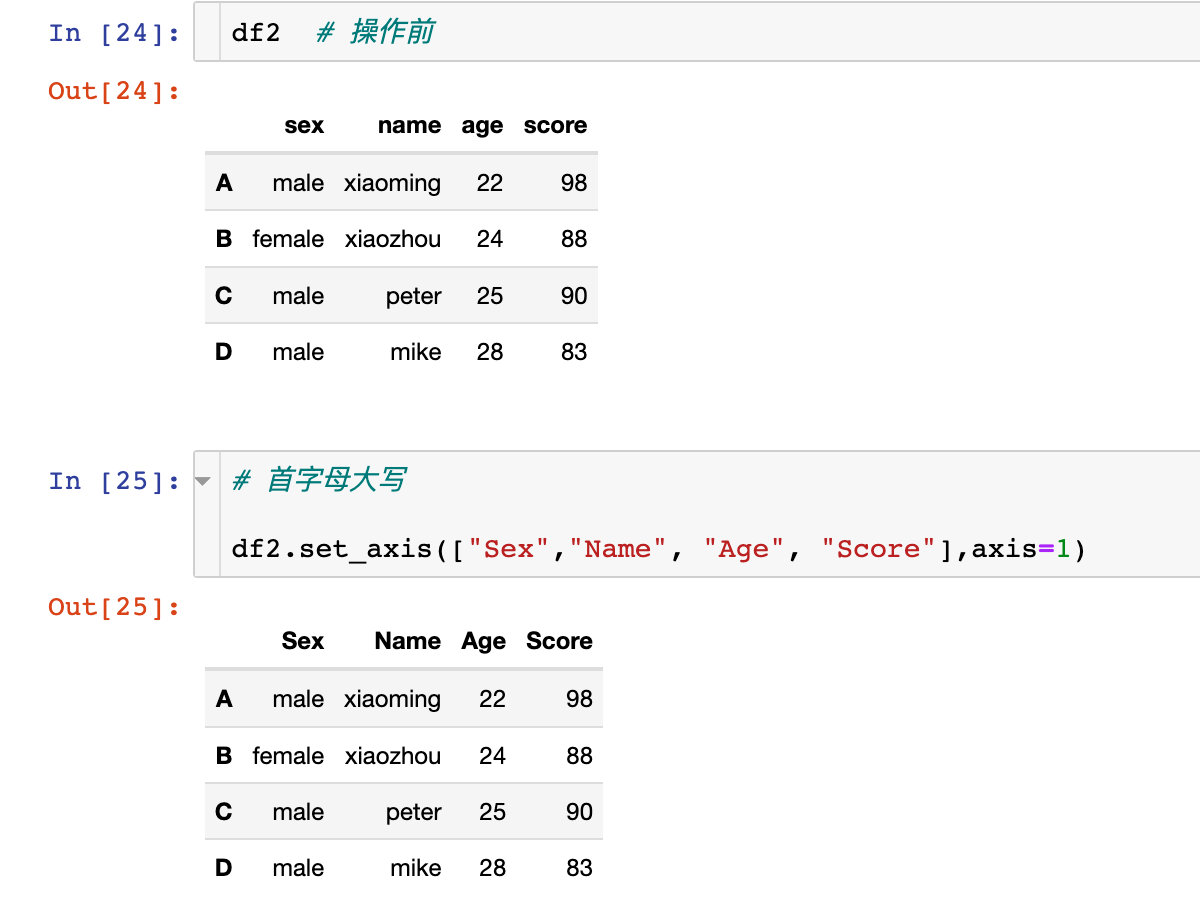
дҪҝз”Ёaxis="columns"ж•ҲжһңзӣёеҗҢпјҡ
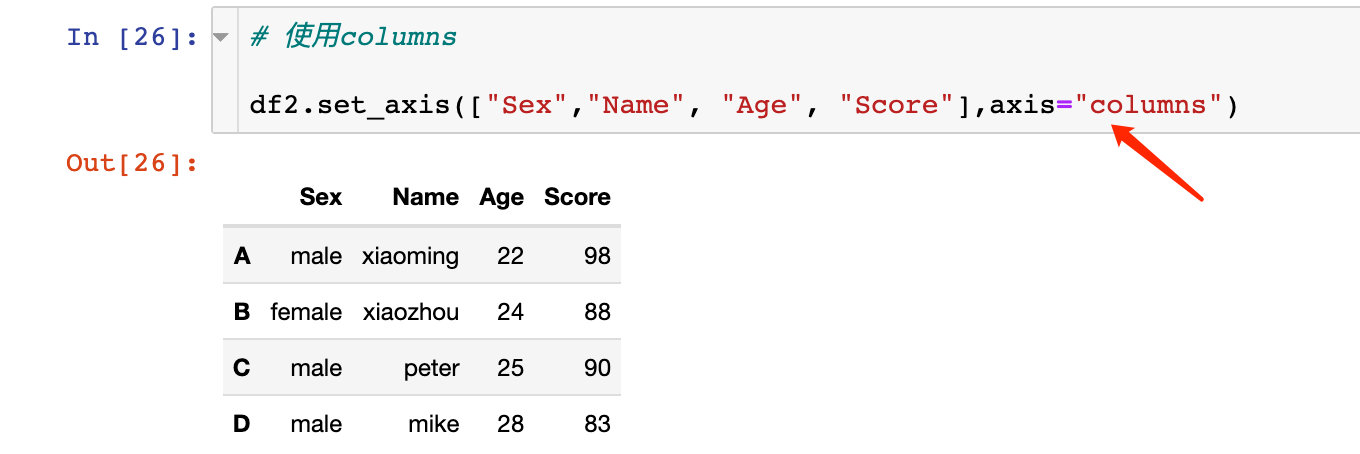
еҗҢж ·д№ҹеҸҜд»ҘзӣҙжҺҘеҺҹең°дҝ®ж”№пјҡ
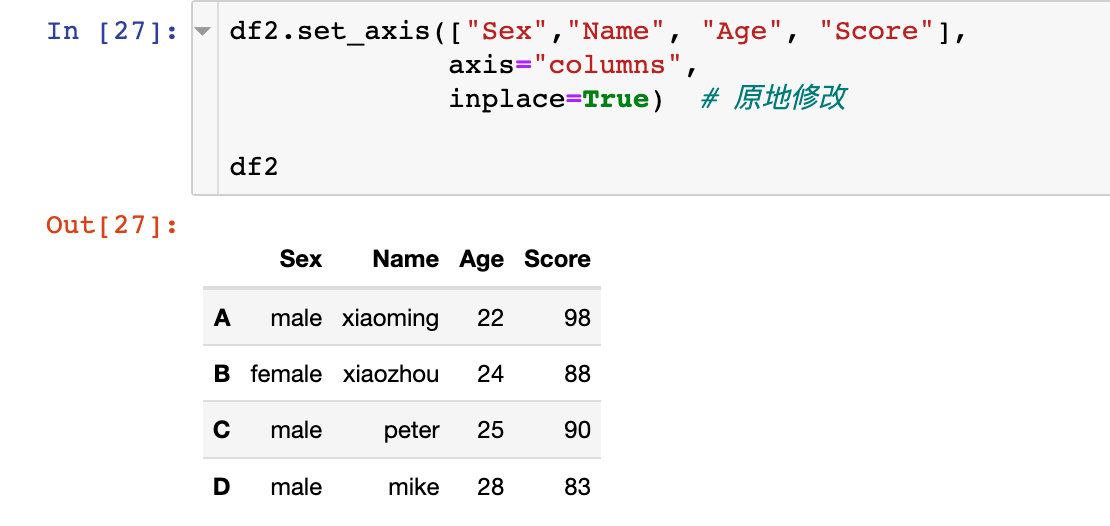
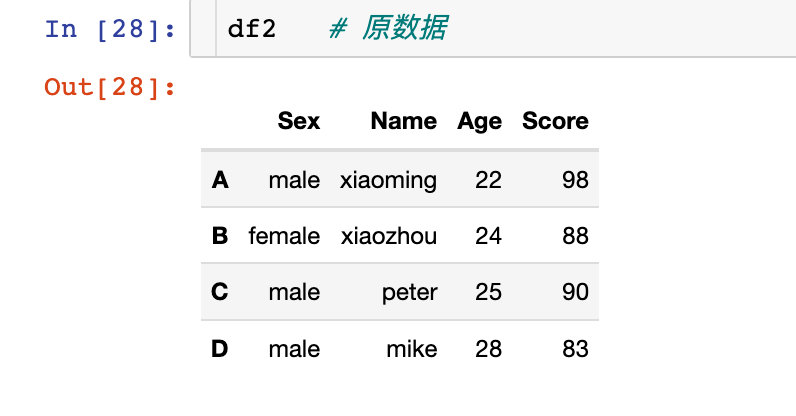
rename
з»ҷиЎҢзҙўеј•жҲ–иҖ…еҲ—зҙўеј•иҝӣиЎҢйҮҚе‘ҪеҗҚпјҢеҒҮи®ҫжҲ‘们зҡ„еҺҹе§Ӣж•°жҚ®еҰӮдёӢпјҡ
еӯ—е…ёеҪўејҸ
1гҖҒйҖҡиҝҮдј е…Ҙзҡ„дёҖдёӘжҲ–иҖ…еӨҡдёӘеұһжҖ§зҡ„еӯ—е…ёеҪўејҸиҝӣиЎҢдҝ®ж”№пјҡ
In [29]:
# дҝ®ж”№еҚ•дёӘеҲ—зҙўеј•пјӣйқһеҺҹең°дҝ®ж”№
df2.rename(columns={"Sex":"sex"})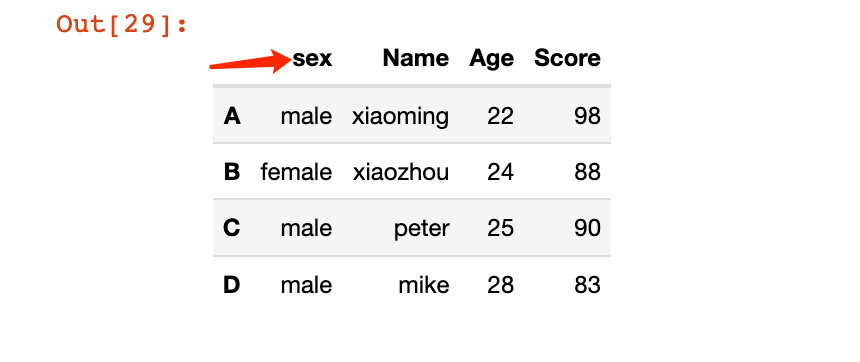
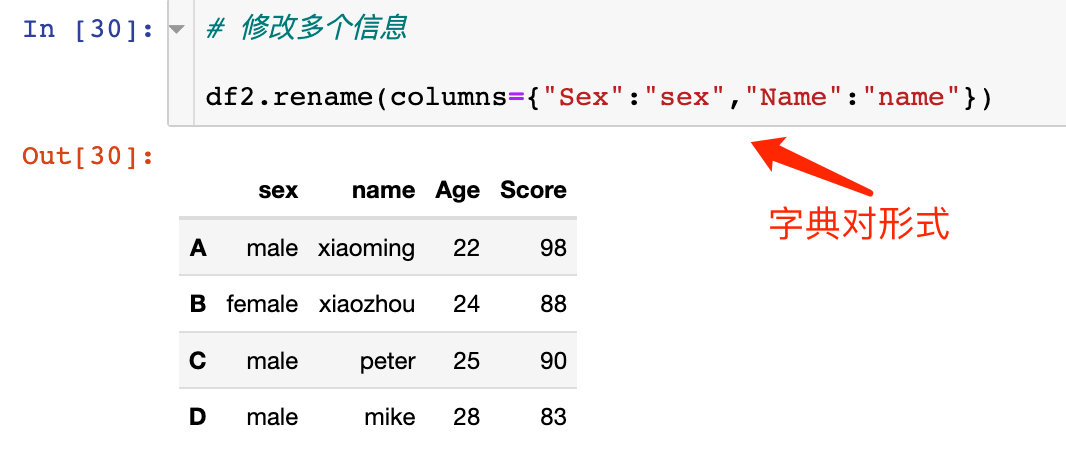
еҗҢж—¶дҝ®ж”№еӨҡдёӘеҲ—еұһжҖ§зҡ„еҗҚз§°пјҡ
еҮҪж•°еҪўејҸ
2гҖҒйҖҡиҝҮдј е…Ҙзҡ„еҮҪж•°иҝӣиЎҢдҝ®ж”№пјҡ
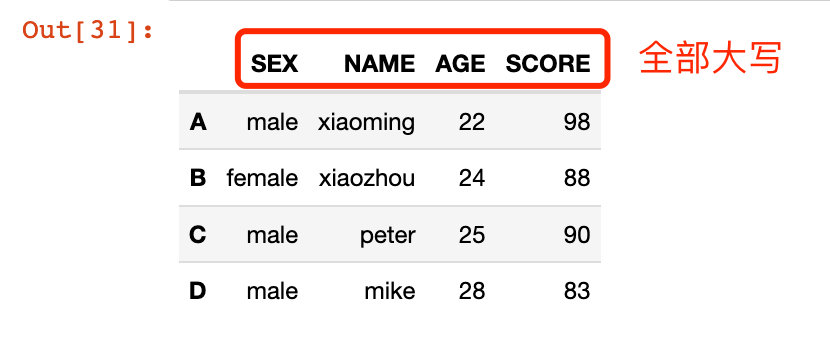
In [31]:
# дј е…ҘеҮҪж•°
df2.rename(str.upper, axis="columns")
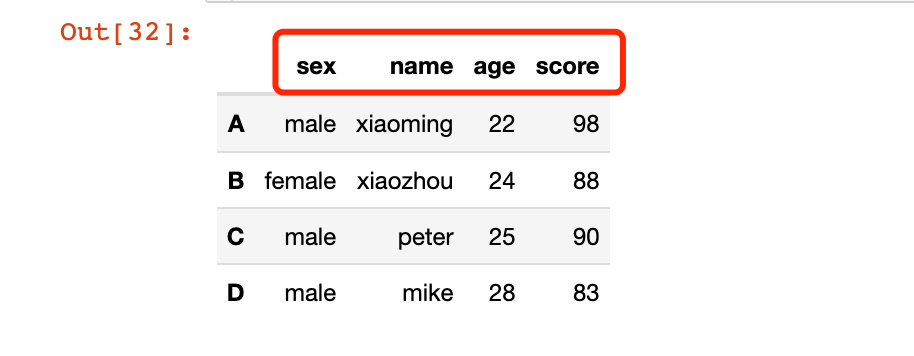
д№ҹеҸҜд»ҘдҪҝз”ЁеҢҝеҗҚеҮҪж•°lambdaпјҡ
# е…ЁйғЁеҸҳжҲҗе°ҸеҶҷ
df2.rename(lambda x: x.lower(), axis="columns")
дҪҝз”ЁжЎҲдҫӢ
In [33]:
еңЁиҝҷйҮҢжҲ‘们дҪҝз”Ёзҡ„жҳҜеҸҜи§ҶеҢ–еә“plotly_expressеә“дёӯзҡ„иҮӘеёҰж•°жҚ®йӣҶtipsпјҡ
import plotly_express as px
tips = px.data.tips()
tips
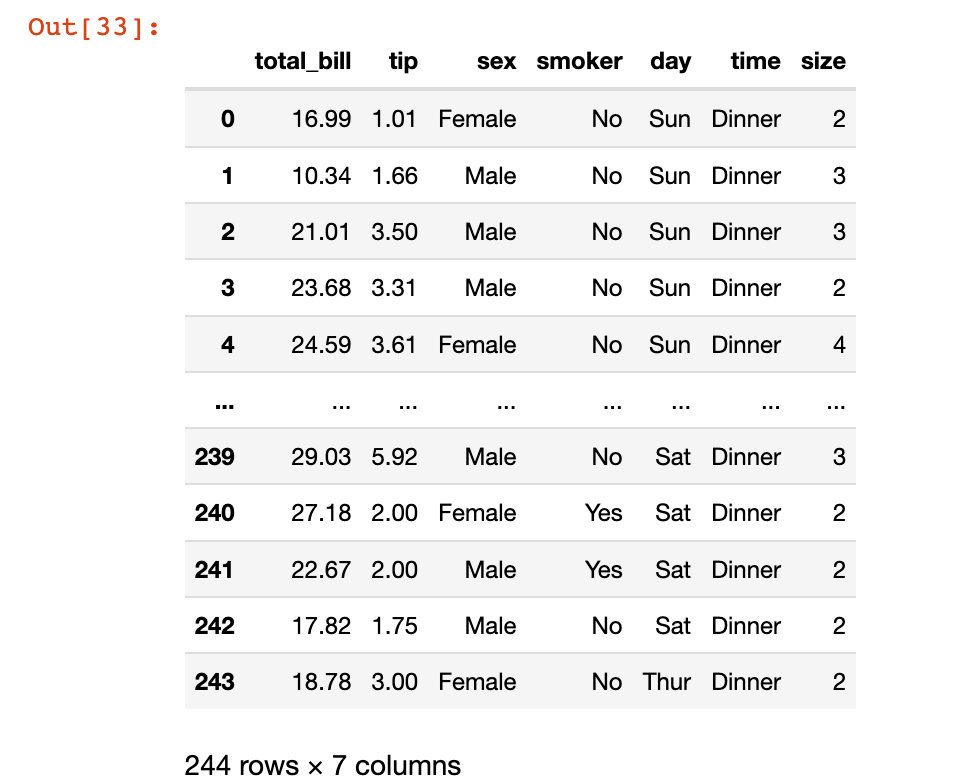
жҢүж—Ҙз»ҹи®ЎжҖ»ж¶Ҳиҙ№
In [34]:
df3 = tips.groupby("day")["total_bill"].sum()
df3Out[34]:
day
Fri 325.88
Sat 1778.40
Sun 1627.16
Thur 1096.33
Name: total_bill, dtype: float64
In [35]:
жҲ‘们еҸ‘зҺ°df3е…¶е®һжҳҜдёҖдёӘSeriesеһӢзҡ„ж•°жҚ®пјҡ
type(df3) # SeriesеһӢзҡ„ж•°жҚ®
Out[35]:
pandas.core.series.Series
In [36]:
дёӢйқўжҲ‘们йҖҡиҝҮreset_indexеҮҪж•°е°Ҷе…¶еҸҳжҲҗдәҶDataFrameж•°жҚ®пјҡ
df4 = df3.reset_index()
df4
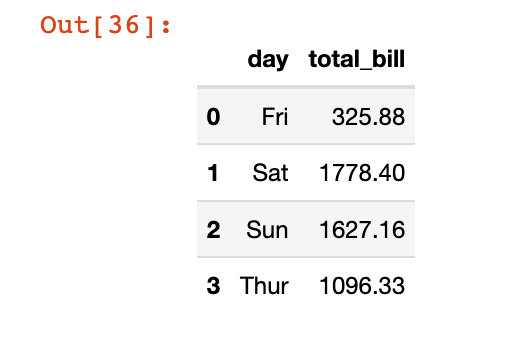
жҲ‘们жҠҠеҲ—ж–№еҗ‘дёҠзҡ„зҙўеј•йҮҚж–°е‘ҪеҗҚдёӢпјҡ
In [37]:
# зӣҙжҺҘеҺҹең°дҝ®ж”№
df4.rename(columns={"day":"Day", "total_bill":"Amount"},
inplace=True)
df4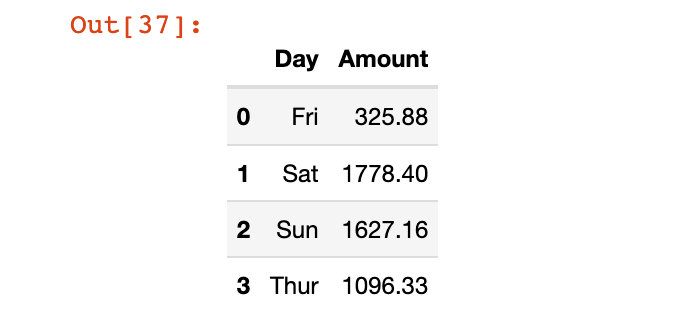
жҢүж—ҘгҖҒжҖ§еҲ«з»ҹи®Ўе°Ҹиҙ№еқҮеҖјпјҢж¶Ҳиҙ№жҖ»е’Ң
In [38]:
df5 = tips.groupby(["day","sex"]).agg({"tip":"mean", "total_bill":"sum"})
df5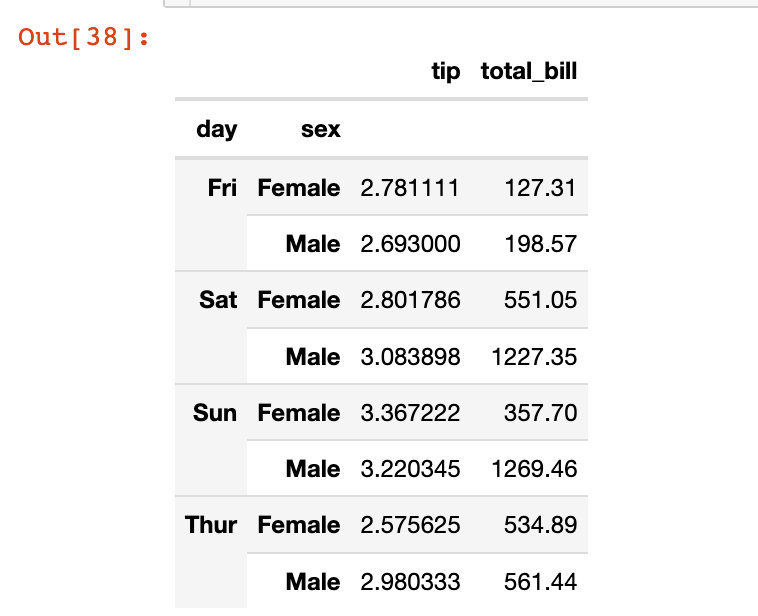
жҲ‘们еҸ‘зҺ°df5жҳҜdf5жҳҜдёҖдёӘе…·жңүеӨҡеұӮзҙўеј•зҡ„ж•°жҚ®жЎҶпјҡ
In [39]:
type(df5)
Out[39]:
pandas.core.frame.DataFrame
жҲ‘们еҸҜд»ҘйҖүжӢ©йҮҚзҪ®е…¶дёӯдёҖдёӘзҙўеј•пјҡ
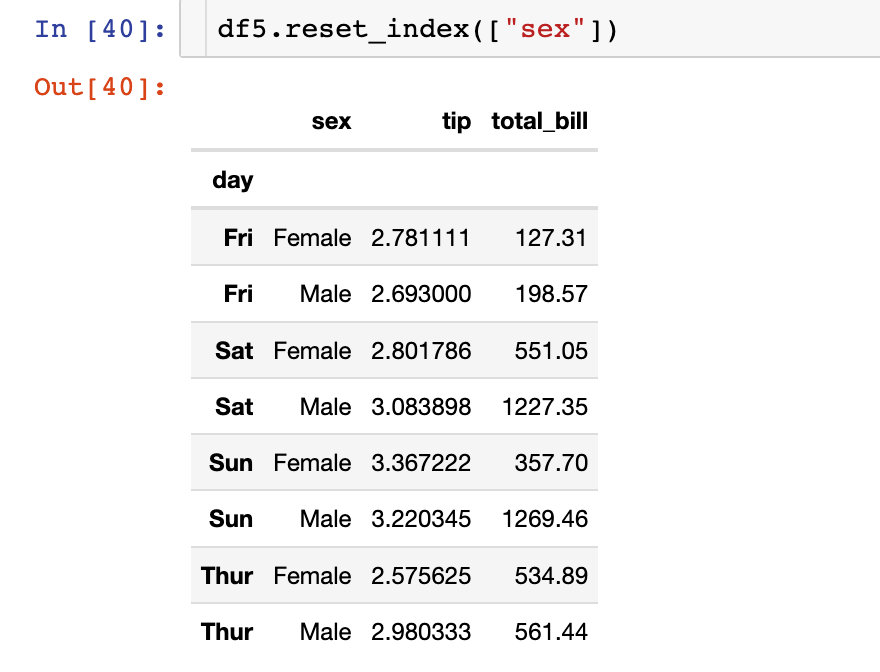
еңЁйҮҚзҪ®зҙўеј•зҡ„еҗҢж—¶пјҢзӣҙжҺҘдёўејғеҺҹжқҘзҡ„еӯ—ж®өдҝЎжҒҜпјҡдёӢйқўзҡ„sexдҝЎжҒҜиў«еҲ йҷӨ
In [41]:
df5.reset_index(["sex"],drop=True) # йқһеҺҹең°дҝ®ж”№
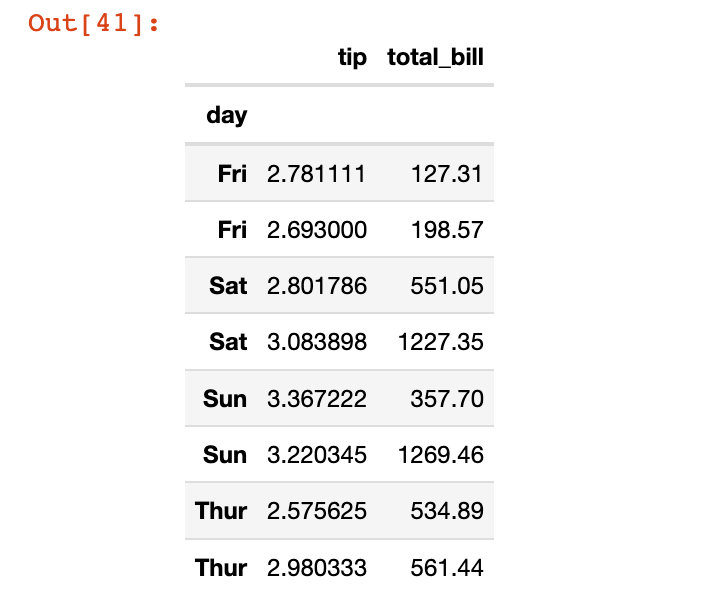
еҲ—ж–№еҗ‘дёҠзҡ„зҙўеј•зӣҙжҺҘеҺҹең°дҝ®ж”№пјҡ
df5.reset_index(inplace=True) # еҺҹең°дҝ®ж”№
df5
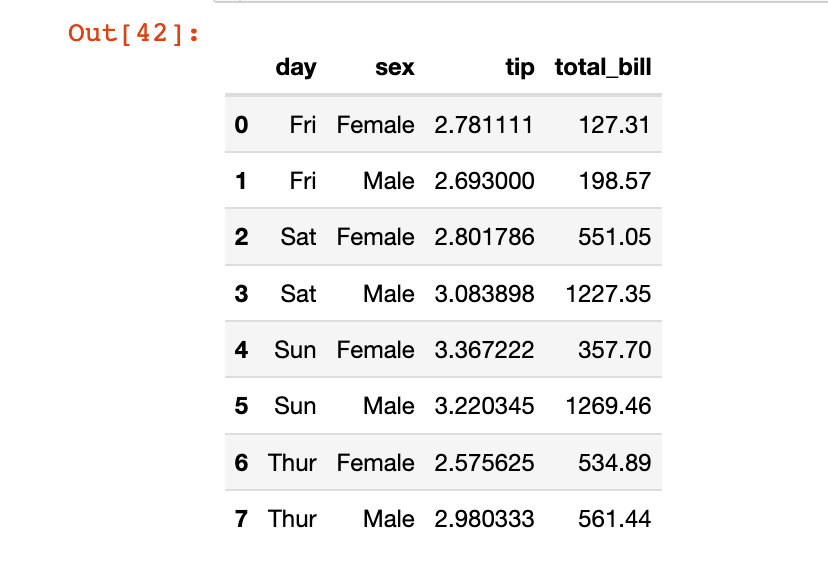
з¬Ёж–№жі•
жңҖеҗҺд»Ӣз»ҚдёҖдёӘз¬Ёж–№жі•жқҘдҝ®ж”№еҲ—зҙўеј•зҡ„еҗҚз§°пјҡе°ұжҳҜе°Ҷж–°зҡ„еҗҚз§°йҖҡиҝҮеҲ—иЎЁзҡ„еҪўејҸе…ЁйғЁиөӢеҖјз»ҷж•°жҚ®жЎҶзҡ„columnsеұһжҖ§
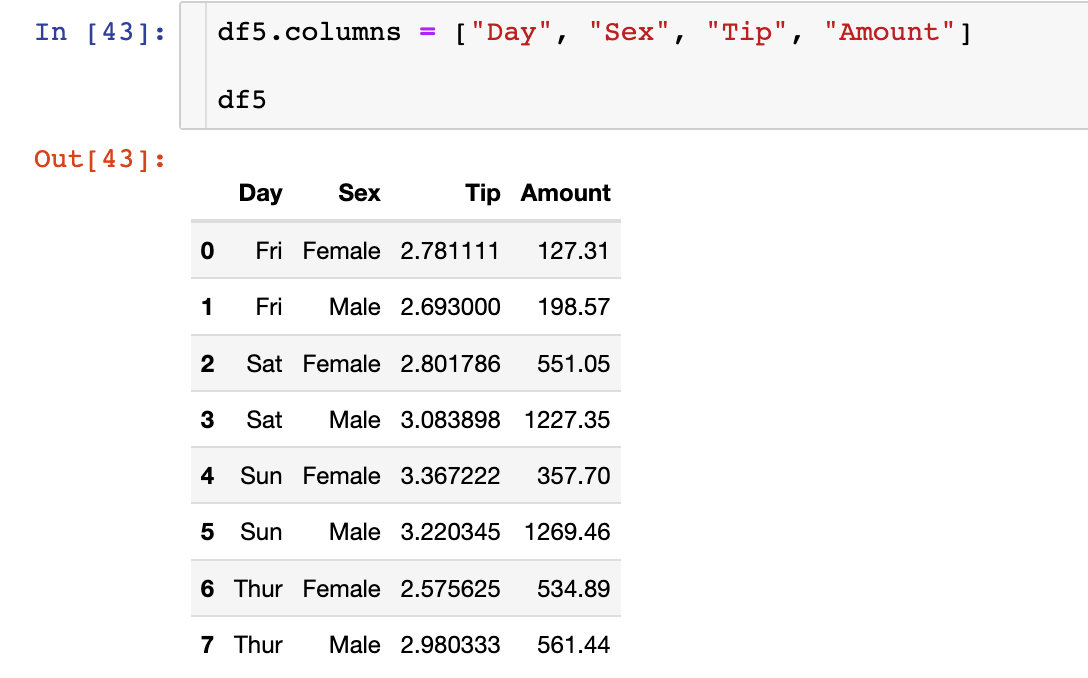
еңЁеҲ—зҙўеј•дёӘж•°е°‘зҡ„ж—¶еҖҷз”Ёиө·жқҘжҢәж–№дҫҝзҡ„пјҢеҰӮжһңеӨҡдәҶдёҚе»әи®®дҪҝз”ЁгҖӮ
д»ҘдёҠе°ұжҳҜе…ідәҺвҖңPython pandasзҙўеј•еҰӮдҪ•и®ҫзҪ®е’Ңдҝ®ж”№вҖқиҝҷзҜҮж–Үз« зҡ„еҶ…е®№пјҢзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢиӢҘжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҡ„зҹҘиҜҶеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





