MySQLдёӯзҡ„жҹҘиҜўдјҳеҢ–еҷЁжҖҺд№Ҳз”Ё
жң¬зҜҮеҶ…е®№дё»иҰҒи®Іи§ЈвҖңMySQLдёӯзҡ„жҹҘиҜўдјҳеҢ–еҷЁжҖҺд№Ҳз”ЁвҖқпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢдёҚеҰЁжқҘзңӢзңӢгҖӮжң¬ж–Үд»Ӣз»Қзҡ„ж–№жі•ж“ҚдҪңз®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәгҖӮдёӢйқўе°ұи®©е°Ҹзј–жқҘеёҰеӨ§е®¶еӯҰд№ вҖңMySQLдёӯзҡ„жҹҘиҜўдјҳеҢ–еҷЁжҖҺд№Ҳз”ЁвҖқеҗ§!

еҜ№дәҺдёҖдёӘSQLиҜӯеҸҘпјҢжҹҘиҜўдјҳеҢ–еҷЁе…ҲзңӢжҳҜдёҚжҳҜиғҪиҪ¬жҚўжҲҗJOINпјҢеҶҚе°ҶJOINиҝӣиЎҢдјҳеҢ–
дјҳеҢ–еҲҶдёәпјҡ1. жқЎд»¶дјҳеҢ–пјҢ2.и®Ўз®—е…ЁиЎЁжү«жҸҸжҲҗжң¬пјҢ3. жүҫеҮәжүҖжңүиғҪз”ЁеҲ°зҡ„зҙўеј•пјҢ4. й’ҲеҜ№жҜҸдёӘзҙўеј•и®Ўз®—дёҚеҗҢзҡ„и®ҝй—®ж–№ејҸзҡ„жҲҗжң¬пјҢ5. йҖүеҮәжҲҗжң¬жңҖе°Ҹзҡ„зҙўеј•д»ҘеҸҠи®ҝй—®ж–№ејҸ
дёҖгҖҒејҖеҗҜжҹҘиҜўдјҳеҢ–еҷЁж—Ҙеҝ—
-- ејҖеҗҜ
set optimizer_trace="enabled=on";
-- жү§иЎҢsql
-- жҹҘзңӢж—Ҙеҝ—дҝЎжҒҜ
select * from information_schema.OPTIMIZER_TRACE;
-- е…ій—ӯ
set optimizer_trace="enabled=off";
дәҢгҖҒдјҳеҢ–еҷЁеҺҹеҲҷ
1гҖҒеёёйҮҸдј йҖ’пјҲconstant_propagationпјү
a = 1 AND b > a
дёҠйқўиҝҷдёӘsqlеҸҜд»ҘиҪ¬жҚўдёәпјҡ
a = 1 AND b > 1
2гҖҒзӯүеҖјдј йҖ’пјҲequality_propagationпјү
a = b and b = c and c = 5
дёҠйқўиҝҷдёӘsqlеҸҜд»ҘиҪ¬жҚўдёәпјҡ
a = 5 and b = 5 and c = 5
3гҖҒ移йҷӨжІЎз”Ёзҡ„жқЎд»¶пјҲtrivial_condition_removalпјү
a = 1 and 1 = 1
дёҠйқўиҝҷдёӘsqlеҸҜд»ҘиҪ¬жҚўдёәпјҡ
a = 1
4гҖҒеҹәдәҺжҲҗжң¬
дёҖдёӘжҹҘиҜўеҸҜд»ҘжңүдёҚеҗҢзҡ„жү§иЎҢж–№жЎҲпјҢеҸҜд»ҘйҖүжӢ©жҹҗдёӘзҙўеј•иҝӣиЎҢжҹҘиҜўпјҢд№ҹеҸҜд»ҘйҖүжӢ©е…ЁиЎЁжү«жҸҸпјҢжҹҘиҜўдјҳеҢ–еҷЁдјҡйҖүжӢ©е…¶дёӯжҲҗжң¬жңҖдҪҺзҡ„ж–№жЎҲеҺ»жү§иЎҢжҹҘиҜўгҖӮ
1пјүI/OжҲҗжң¬
InnoDBеӯҳеӮЁеј•ж“ҺйғҪжҳҜе°Ҷж•°жҚ®е’Ңзҙўеј•йғҪеӯҳеӮЁеҲ°зЈҒзӣҳдёҠзҡ„пјҢеҪ“жҲ‘们жғіжҹҘиҜўиЎЁдёӯзҡ„и®°еҪ•ж—¶пјҢйңҖиҰҒе…ҲжҠҠж•°жҚ®жҲ–иҖ…зҙўеј•еҠ иҪҪеҲ°еҶ…еӯҳдёӯ然еҗҺеҶҚж“ҚдҪңгҖӮиҝҷдёӘд»ҺзЈҒзӣҳеҲ°еҶ…еӯҳиҝҷдёӘеҠ иҪҪзҡ„иҝҮзЁӢжҚҹиҖ—зҡ„ж—¶й—ҙз§°д№ӢдёәI/OжҲҗжң¬
2пјүCPUжҲҗжң¬
иҜ»еҸ–д»ҘеҸҠжЈҖжөӢи®°еҪ•жҳҜеҗҰж»Ўи¶іеҜ№еә”зҡ„жҗңзҙўжқЎд»¶гҖҒеҜ№з»“жһңйӣҶиҝӣиЎҢжҺ’еәҸзӯүиҝҷдәӣж“ҚдҪңжҚҹиҖ—зҡ„ж—¶й—ҙз§°д№ӢдёәCPUжҲҗжң¬гҖӮ
InnoDBеӯҳеӮЁеј•ж“Һ规е®ҡиҜ»еҸ–дёҖдёӘйЎөйқўиҠұиҙ№зҡ„жҲҗжң¬й»ҳи®ӨжҳҜ1.0пјҢиҜ»еҸ–д»ҘеҸҠжЈҖжөӢдёҖжқЎи®°еҪ•жҳҜеҗҰз¬ҰеҗҲжҗңзҙўжқЎд»¶зҡ„жҲҗжң¬й»ҳи®ӨжҳҜ0.2гҖӮ
дёүгҖҒеҹәдәҺжҲҗжң¬зҡ„дјҳеҢ–жӯҘйӘӨ
еңЁдёҖжқЎеҚ•иЎЁжҹҘиҜўиҜӯеҸҘзңҹжӯЈжү§иЎҢд№ӢеүҚпјҢMySQLзҡ„жҹҘиҜўдјҳеҢ–еҷЁдјҡжүҫеҮәжү§иЎҢиҜҘиҜӯеҸҘжүҖжңүеҸҜиғҪдҪҝз”Ёзҡ„ж–№жЎҲпјҢеҜ№жҜ”д№ӢеҗҺжүҫеҮәжҲҗжң¬жңҖдҪҺзҡ„ж–№жЎҲпјҢиҝҷдёӘжҲҗжң¬жңҖдҪҺзҡ„ж–№жЎҲе°ұжҳҜжүҖи°“зҡ„жү§иЎҢи®ЎеҲ’пјҢд№ӢеҗҺжүҚдјҡи°ғз”ЁеӯҳеӮЁеј•ж“ҺжҸҗдҫӣзҡ„жҺҘеҸЈзңҹжӯЈзҡ„жү§иЎҢжҹҘиҜўгҖӮ
дёӢиҫ№жҲ‘们е°ұд»ҘдёҖдёӘе®һдҫӢжқҘеҲҶжһҗдёҖдёӢиҝҷдәӣжӯҘйӘӨпјҢеҚ•иЎЁжҹҘиҜўиҜӯеҸҘеҰӮдёӢпјҡ
select * from employees.titles where emp_no > '10101' and emp_no < '20000' and to_date = '1991-10-10';
1гҖҒж №жҚ®жҗңзҙўжқЎд»¶пјҢжүҫеҮәжүҖжңүеҸҜиғҪдҪҝз”Ёзҡ„зҙўеј•
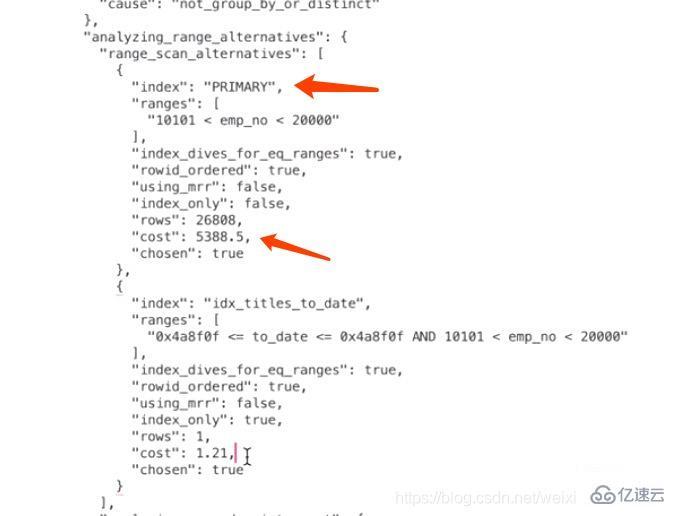
вҖў emp_no > вҖҳ10101вҖҷпјҢиҝҷдёӘжҗңзҙўжқЎд»¶еҸҜд»ҘдҪҝз”Ёдё»й”®зҙўеј•PRIMARYгҖӮ
вҖў to_date = вҖҳ1991-10-10вҖҷпјҢиҝҷдёӘжҗңзҙўжқЎд»¶еҸҜд»ҘдҪҝз”ЁдәҢзә§зҙўеј•idx_titles_to_dateгҖӮ
з»јдёҠжүҖиҝ°пјҢдёҠиҫ№зҡ„жҹҘиҜўиҜӯеҸҘеҸҜиғҪз”ЁеҲ°зҡ„зҙўеј•пјҢд№ҹе°ұжҳҜpossible keysеҸӘжңүPRIMARYе’Ңidx_titles_to_dateгҖӮ
2гҖҒи®Ўз®—е…ЁиЎЁжү«жҸҸзҡ„д»Јд»·
еҜ№дәҺInnoDBеӯҳеӮЁеј•ж“ҺжқҘиҜҙпјҢе…ЁиЎЁжү«жҸҸзҡ„ж„ҸжҖқе°ұжҳҜжҠҠиҒҡз°Үзҙўеј•дёӯзҡ„и®°еҪ•йғҪдҫқж¬Ўе’Ңз»ҷе®ҡзҡ„жҗңзҙўжқЎд»¶еҒҡдёҖдёӢжҜ”иҫғпјҢжҠҠз¬ҰеҗҲжҗңзҙўжқЎд»¶зҡ„и®°еҪ•еҠ е…ҘеҲ°з»“жһңйӣҶпјҢжүҖд»ҘйңҖиҰҒе°ҶиҒҡз°Үзҙўеј•еҜ№еә”зҡ„йЎөйқўеҠ иҪҪеҲ°еҶ…еӯҳдёӯпјҢ然еҗҺеҶҚжЈҖжөӢи®°еҪ•жҳҜеҗҰз¬ҰеҗҲжҗңзҙўжқЎд»¶гҖӮз”ұдәҺжҹҘиҜўжҲҗжң¬=I/OжҲҗжң¬+CPUжҲҗжң¬пјҢжүҖд»Ҙи®Ўз®—е…ЁиЎЁжү«жҸҸзҡ„д»Јд»·йңҖиҰҒдёӨдёӘдҝЎжҒҜпјҡ
1пјүиҒҡз°Үзҙўеј•еҚ з”Ёзҡ„йЎөйқўж•°
2пјүиҜҘиЎЁдёӯзҡ„и®°еҪ•ж•°
MySQLдёәжҜҸдёӘиЎЁз»ҙжҠӨдәҶдёҖзі»еҲ—зҡ„з»ҹи®ЎдҝЎжҒҜпјҢSHOW TABLE STATUSиҜӯеҸҘжқҘжҹҘзңӢиЎЁзҡ„з»ҹи®ЎдҝЎжҒҜгҖӮ
SHOW TABLE STATUS LIKE 'titles';
Rows
иЎЁзӨәиЎЁдёӯзҡ„и®°еҪ•жқЎж•°гҖӮеҜ№дәҺдҪҝз”ЁMyISAMеӯҳеӮЁеј•ж“Һзҡ„иЎЁжқҘиҜҙпјҢиҜҘеҖјжҳҜеҮҶзЎ®зҡ„пјҢеҜ№дәҺдҪҝз”ЁInnoDBеӯҳеӮЁеј•ж“Һзҡ„иЎЁжқҘиҜҙпјҢиҜҘеҖјжҳҜдёҖдёӘдј°и®ЎеҖјгҖӮ
Data_length
иЎЁзӨәиЎЁеҚ з”Ёзҡ„еӯҳеӮЁз©әй—ҙеӯ—иҠӮж•°гҖӮдҪҝз”ЁMyISAMеӯҳеӮЁеј•ж“Һзҡ„иЎЁжқҘиҜҙпјҢиҜҘеҖје°ұжҳҜж•°жҚ®ж–Ү件зҡ„еӨ§е°ҸпјҢеҜ№дәҺдҪҝз”ЁInnoDBеӯҳеӮЁеј•ж“Һзҡ„иЎЁжқҘиҜҙпјҢиҜҘеҖје°ұзӣёеҪ“дәҺиҒҡз°Үзҙўеј•еҚ з”Ёзҡ„еӯҳеӮЁз©әй—ҙеӨ§е°ҸпјҢд№ҹе°ұжҳҜиҜҙеҸҜд»Ҙиҝҷж ·и®Ўз®—иҜҘеҖјзҡ„еӨ§е°Ҹпјҡ
Data_length = иҒҡз°Үзҙўеј•зҡ„йЎөйқўж•°йҮҸ x жҜҸдёӘйЎөйқўзҡ„еӨ§е°Ҹ
жҲ‘们зҡ„titlesдҪҝз”Ёй»ҳи®Ө16KBзҡ„йЎөйқўеӨ§е°ҸпјҢиҖҢдёҠиҫ№жҹҘиҜўз»“жһңжҳҫзӨәData_lengthзҡ„еҖјжҳҜ20512768пјҢжүҖд»ҘжҲ‘们еҸҜд»ҘеҸҚеҗ‘жқҘжҺЁеҜјеҮәиҒҡз°Үзҙўеј•зҡ„йЎөйқўж•°йҮҸпјҡ
иҒҡз°Үзҙўеј•зҡ„йЎөйқўж•°йҮҸ = Data_length Г· 16 Г· 1024 = 20512768 Г· 16 Г· 1024 = 1252
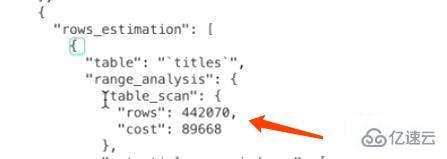
жҲ‘们зҺ°еңЁе·Із»Ҹеҫ—еҲ°дәҶиҒҡз°Үзҙўеј•еҚ з”Ёзҡ„йЎөйқўж•°йҮҸд»ҘеҸҠиҜҘиЎЁи®°еҪ•ж•°зҡ„дј°и®ЎеҖјпјҢжүҖд»Ҙе°ұеҸҜд»Ҙи®Ўз®—е…ЁиЎЁжү«жҸҸжҲҗжң¬дәҶгҖӮдҪҶжҳҜMySQLеңЁзңҹе®һи®Ўз®—жҲҗжң¬ж—¶дјҡиҝӣиЎҢдёҖдәӣеҫ®и°ғгҖӮ
I/OжҲҗжң¬пјҡ12521 = 1252гҖӮ1252жҢҮзҡ„жҳҜиҒҡз°Үзҙўеј•еҚ з”Ёзҡ„йЎөйқўж•°пјҢ1.0жҢҮзҡ„жҳҜеҠ иҪҪдёҖдёӘйЎөйқўзҡ„жҲҗжң¬еёёж•°гҖӮ
CPUжҲҗжң¬пјҡ4420700.2=88414гҖӮ442070жҢҮзҡ„жҳҜз»ҹи®Ўж•°жҚ®дёӯиЎЁзҡ„и®°еҪ•ж•°пјҢеҜ№дәҺInnoDBеӯҳеӮЁеј•ж“ҺжқҘиҜҙжҳҜдёҖдёӘдј°и®ЎеҖјпјҢ0.2жҢҮзҡ„жҳҜи®ҝй—®дёҖжқЎи®°еҪ•жүҖйңҖзҡ„жҲҗжң¬еёёж•°
жҖ»жҲҗжң¬пјҡ1252+88414 = 89666гҖӮ
з»јдёҠжүҖиҝ°пјҢеҜ№дәҺtitlesзҡ„е…ЁиЎЁжү«жҸҸжүҖйңҖзҡ„жҖ»жҲҗжң¬е°ұжҳҜ89666гҖӮ
жҲ‘们еүҚиҫ№иҜҙиҝҮиЎЁдёӯзҡ„и®°еҪ•е…¶е®һйғҪеӯҳеӮЁеңЁиҒҡз°Үзҙўеј•еҜ№еә”B+ж ‘зҡ„еҸ¶еӯҗиҠӮзӮ№дёӯпјҢжүҖд»ҘеҸӘиҰҒжҲ‘们йҖҡиҝҮж №иҠӮзӮ№иҺ·еҫ—дәҶжңҖе·Ұиҫ№зҡ„еҸ¶еӯҗиҠӮзӮ№пјҢе°ұеҸҜд»ҘжІҝзқҖеҸ¶еӯҗиҠӮзӮ№з»„жҲҗзҡ„еҸҢеҗ‘й“ҫиЎЁжҠҠжүҖжңүи®°еҪ•йғҪжҹҘзңӢдёҖйҒҚгҖӮд№ҹе°ұжҳҜиҜҙе…ЁиЎЁжү«жҸҸиҝҷдёӘиҝҮзЁӢе…¶е®һжңүзҡ„B+ж ‘еҶ…иҠӮзӮ№жҳҜдёҚйңҖиҰҒи®ҝй—®зҡ„пјҢдҪҶжҳҜMySQLеңЁи®Ўз®—е…ЁиЎЁжү«жҸҸжҲҗжң¬ж—¶зӣҙжҺҘдҪҝз”ЁиҒҡз°Үзҙўеј•еҚ з”Ёзҡ„йЎөйқўж•°дҪңдёәи®Ўз®—I/OжҲҗжң¬зҡ„дҫқжҚ®пјҢжҳҜдёҚеҢәеҲҶеҶ…иҠӮзӮ№е’ҢеҸ¶еӯҗиҠӮзӮ№зҡ„гҖӮ
3гҖҒи®Ўз®—PRIMARYйңҖиҰҒжҲҗжң¬
и®Ўз®—PRIMARYйңҖиҰҒеӨҡе°‘жҲҗжң¬зҡ„е…ій”®й—®йўҳжҳҜпјҡйңҖиҰҒйў„дј°еҮәж №жҚ®еҜ№еә”зҡ„whereжқЎд»¶еңЁдё»й”®зҙўеј•B+ж ‘дёӯеӯҳеңЁеӨҡе°‘жқЎз¬ҰеҗҲжқЎд»¶зҡ„и®°еҪ•гҖӮ
иҢғеӣҙеҢәй—ҙж•°
еҪ“жҲ‘们д»Һзҙўеј•дёӯжҹҘиҜўи®°еҪ•ж—¶пјҢдёҚз®ЎжҳҜ=гҖҒinгҖҒ>гҖҒ<иҝҷдәӣж“ҚдҪңйғҪйңҖиҰҒд»Һзҙўеј•дёӯзЎ®е®ҡдёҖдёӘиҢғеӣҙпјҢдёҚи®әиҝҷдёӘиҢғеӣҙеҢәй—ҙзҡ„зҙўеј•еҲ°еә•еҚ з”ЁдәҶеӨҡе°‘йЎөйқўпјҢжҹҘиҜўдјҳеҢ–еҷЁзІ—жҡҙзҡ„и®ӨдёәиҜ»еҸ–зҙўеј•зҡ„дёҖдёӘиҢғеӣҙеҢәй—ҙзҡ„I/OжҲҗжң¬е’ҢиҜ»еҸ–дёҖдёӘйЎөйқўжҳҜзӣёеҗҢзҡ„гҖӮ
жң¬дҫӢдёӯдҪҝз”ЁPRIMARYзҡ„иҢғеӣҙеҢәй—ҙеҸӘжңүдёҖдёӘпјҡ(10101, 20000)пјҢжүҖд»ҘзӣёеҪ“дәҺи®ҝй—®иҝҷдёӘиҢғеӣҙеҢәй—ҙзҡ„зҙўеј•д»ҳеҮәзҡ„I/OжҲҗжң¬е°ұжҳҜпјҡ1 x 1.0 = 1.0
йў„дј°иҢғеӣҙеҶ…зҡ„и®°еҪ•ж•°
дјҳеҢ–еҷЁйңҖиҰҒи®Ўз®—зҙўеј•зҡ„жҹҗдёӘиҢғеӣҙеҢәй—ҙеҲ°еә•еҢ…еҗ«еӨҡе°‘жқЎи®°еҪ•пјҢеҜ№дәҺжң¬дҫӢжқҘиҜҙе°ұжҳҜиҰҒи®Ўз®—PRIMARYеңЁ(10101, 20000)иҝҷдёӘиҢғеӣҙеҢәй—ҙдёӯеҢ…еҗ«еӨҡе°‘жқЎж•°жҚ®и®°еҪ•пјҢи®Ўз®—иҝҮзЁӢжҳҜиҝҷж ·зҡ„пјҡ
жӯҘйӘӨ1пјҡе…Ҳж №жҚ®emp_no > 10101иҝҷдёӘжқЎд»¶и®ҝй—®дёҖдёӢPRIMARYеҜ№еә”зҡ„B+ж ‘зҙўеј•пјҢжүҫеҲ°ж»Ўи¶іemp_no > 10101иҝҷдёӘжқЎд»¶зҡ„第дёҖжқЎи®°еҪ•пјҢжҲ‘们жҠҠиҝҷжқЎи®°еҪ•з§°д№ӢдёәеҢәй—ҙжңҖе·Ұи®°еҪ•гҖӮ
жӯҘйӘӨ2пјҡ然еҗҺеҶҚж №жҚ®emp_no < 20000иҝҷдёӘжқЎд»¶з»§з»ӯд»ҺPRIMARYеҜ№еә”зҡ„B+ж ‘зҙўеј•дёӯжүҫеҮә第дёҖжқЎж»Ўи¶іиҝҷдёӘжқЎд»¶зҡ„и®°еҪ•пјҢжҲ‘们жҠҠиҝҷжқЎи®°еҪ•з§°д№ӢдёәеҢәй—ҙжңҖеҸіи®°еҪ•гҖӮ
жӯҘйӘӨ3пјҡеҰӮжһңеҢәй—ҙжңҖе·Ұи®°еҪ•е’ҢеҢәй—ҙжңҖеҸіи®°еҪ•зӣёйҡ”дёҚеӨӘиҝңпјҲеҸӘиҰҒзӣёйҡ”дёҚеӨ§дәҺ10дёӘйЎөйқўеҚіеҸҜпјүпјҢйӮЈе°ұеҸҜд»ҘзІҫзЎ®з»ҹи®ЎеҮәж»Ўи¶іemp_no > '10101' and emp_no < '20000'жқЎд»¶зҡ„и®°еҪ•жқЎж•°гҖӮеҗҰеҲҷеҸӘжІҝзқҖеҢәй—ҙжңҖе·Ұи®°еҪ•еҗ‘еҸіиҜ»10дёӘйЎөйқўпјҢи®Ўз®—е№іеқҮжҜҸдёӘйЎөйқўдёӯеҢ…еҗ«еӨҡе°‘и®°еҪ•пјҢ然еҗҺз”ЁиҝҷдёӘе№іеқҮеҖјд№ҳд»ҘеҢәй—ҙжңҖе·Ұи®°еҪ•е’ҢеҢәй—ҙжңҖеҸіи®°еҪ•д№Ӣй—ҙзҡ„йЎөйқўж•°йҮҸе°ұеҸҜд»ҘдәҶгҖӮйӮЈд№Ҳй—®йўҳеҸҲжқҘдәҶпјҢжҖҺд№Ҳдј°и®ЎеҢәй—ҙжңҖе·Ұи®°еҪ•е’ҢеҢәй—ҙжңҖеҸіи®°еҪ•д№Ӣй—ҙжңүеӨҡе°‘дёӘйЎөйқўе‘ўпјҹи®Ўз®—е®ғ们зҲ¶иҠӮзӮ№дёӯеҜ№еә”зҡ„зӣ®еҪ•йЎ№и®°еҪ•д№Ӣй—ҙйҡ”зқҖеҮ жқЎи®°еҪ•е°ұеҸҜд»ҘдәҶгҖӮ
ж №жҚ®дёҠйқўзҡ„жӯҘйӘӨеҸҜд»Ҙз®—еҮәжқҘPRIMARYзҙўеј•зҡ„и®°еҪ•жқЎж•°пјҢжүҖд»ҘиҜ»еҸ–и®°еҪ•зҡ„CPUжҲҗжң¬дёәпјҡ26808*0.2=5361.6пјҢе…¶дёӯ26808жҳҜйў„дј°зҡ„йңҖиҰҒиҜ»еҸ–зҡ„ж•°жҚ®и®°еҪ•жқЎж•°пјҢ0.2жҳҜиҜ»еҸ–дёҖжқЎи®°еҪ•жҲҗжң¬еёёж•°гҖӮ
PRIMARYзҡ„жҖ»жҲҗжң¬
зЎ®е®ҡи®ҝй—®зҡ„IOжҲҗжң¬+иҝҮж»Өж•°жҚ®зҡ„CPUжҲҗжң¬=1+5361.6=5362.6
4гҖҒи®Ўз®—idx_titles_to_dateйңҖиҰҒжҲҗжң¬

еӣ дёәйҖҡиҝҮдәҢзә§зҙўеј•жҹҘиҜўйңҖиҰҒеӣһиЎЁпјҢжүҖд»ҘеңЁи®Ўз®—дәҢзә§зҙўеј•йңҖиҰҒжҲҗжң¬ж—¶иҝҳиҰҒеҠ дёҠеӣһиЎЁзҡ„жҲҗжң¬пјҢиҖҢеӣһиЎЁзҡ„жҲҗжң¬е°ұзӣёеҪ“дәҺдёӢйқўиҝҷдёӘSQLжү§иЎҢпјҡ
select * from employees.titles where дё»й”®еӯ—ж®ө in пјҲдё»й”®еҖј1пјҢдё»й”®еҖј2пјҢгҖӮгҖӮгҖӮпјҢдё»й”®еҖј3пјү;
жүҖд»Ҙidx_titles_to_dateзҡ„жҲҗжң¬ = иҫ…еҠ©зҙўеј•зҡ„жҹҘиҜўжҲҗжң¬ + еӣһиЎЁжҹҘиҜўзҡ„жҲҗжң¬
5гҖҒжҜ”иҫғеҗ„жҲҗжң¬йҖүеҮәжңҖдјҳиҖ…
йҖүжӢ©жҲҗжң¬жңҖе°Ҹзҡ„зҙўеј•
еӣӣгҖҒеҹәдәҺзҙўеј•з»ҹи®Ўж•°жҚ®зҡ„жҲҗжң¬и®Ўз®—
жңүж—¶еҖҷдҪҝз”Ёзҙўеј•жү§иЎҢжҹҘиҜўж—¶дјҡжңүи®ёеӨҡеҚ•зӮ№еҢәй—ҙпјҢжҜ”еҰӮдҪҝз”ЁINиҜӯеҸҘе°ұеҫҲе®№жҳ“дә§з”ҹйқһеёёеӨҡзҡ„еҚ•зӮ№еҢәй—ҙпјҢжҜ”еҰӮдёӢиҫ№иҝҷдёӘжҹҘиҜўпјҡ
select * from employees.titles where to_date in ('a','b','c','d', ..., 'e');еҫҲжҳҫ然пјҢиҝҷдёӘжҹҘиҜўеҸҜиғҪдҪҝз”ЁеҲ°зҡ„зҙўеј•е°ұжҳҜidx_titles_to_dateпјҢз”ұдәҺиҝҷдёӘзҙўеј•е№¶дёҚжҳҜе”ҜдёҖдәҢзә§зҙўеј•пјҢжүҖд»Ҙ并дёҚиғҪзЎ®е®ҡдёҖдёӘеҚ•зӮ№еҢәй—ҙеҜ№еә”зҡ„дәҢзә§зҙўеј•и®°еҪ•зҡ„жқЎж•°жңүеӨҡе°‘пјҢйңҖиҰҒжҲ‘们еҺ»и®Ўз®—гҖӮи®Ўз®—ж–№ејҸжҲ‘们дёҠиҫ№е·Із»Ҹд»Ӣз»ҚиҝҮдәҶпјҢе°ұжҳҜе…ҲиҺ·еҸ–зҙўеј•еҜ№еә”зҡ„B+ж ‘зҡ„еҢәй—ҙжңҖе·Ұи®°еҪ•е’ҢеҢәй—ҙжңҖеҸіи®°еҪ•пјҢ然еҗҺеҶҚи®Ўз®—иҝҷдёӨжқЎи®°еҪ•д№Ӣй—ҙжңүеӨҡе°‘и®°еҪ•пјҲи®°еҪ•жқЎж•°е°‘зҡ„ж—¶еҖҷеҸҜд»ҘеҒҡеҲ°зІҫзЎ®и®Ўз®—пјҢеӨҡзҡ„ж—¶еҖҷеҸӘиғҪдј°з®—пјүгҖӮиҝҷз§ҚйҖҡиҝҮзӣҙжҺҘи®ҝй—®зҙўеј•еҜ№еә”зҡ„B+ж ‘жқҘи®Ўз®—жҹҗдёӘиҢғеӣҙеҢәй—ҙеҜ№еә”зҡ„зҙўеј•и®°еҪ•жқЎж•°зҡ„ж–№ејҸз§°д№Ӣдёәindex peгҖӮ
еҰӮжһңеҸӘжңүеҮ дёӘеҚ•зӮ№еҢәй—ҙзҡ„иҜқпјҢдҪҝз”Ёindex peзҡ„ж–№ејҸеҺ»и®Ўз®—иҝҷдәӣеҚ•зӮ№еҢәй—ҙеҜ№еә”зҡ„и®°еҪ•ж•°д№ҹдёҚжҳҜд»Җд№Ҳй—®йўҳпјҢеҸҜжҳҜеҰӮжһңеҫҲеӨҡе‘ўпјҢжҜ”еҰӮжңү20000ж¬ЎпјҢMySQLзҡ„жҹҘиҜўдјҳеҢ–еҷЁдёәдәҶи®Ўз®—иҝҷдәӣеҚ•зӮ№еҢәй—ҙеҜ№еә”зҡ„зҙўеј•и®°еҪ•жқЎж•°пјҢиҰҒиҝӣиЎҢ20000ж¬Ўindex peж“ҚдҪңпјҢйӮЈд№Ҳиҝҷз§Қжғ…еҶөдёӢжҳҜеҫҲиҖ—жҖ§иғҪзҡ„пјҢжүҖд»ҘMySQLжҸҗдҫӣдәҶдёҖдёӘзі»з»ҹеҸҳйҮҸeq_range_index_pe_limitпјҢжҲ‘们зңӢдёҖдёӢиҝҷдёӘзі»з»ҹеҸҳйҮҸзҡ„й»ҳи®ӨеҖјпјҡSHOW VARIABLES LIKE вҖҳ%pe%вҖҷ;дёә200гҖӮ
д№ҹе°ұжҳҜиҜҙеҰӮжһңжҲ‘们зҡ„INиҜӯеҸҘдёӯзҡ„еҸӮж•°дёӘж•°е°ҸдәҺ200дёӘзҡ„иҜқпјҢе°ҶдҪҝз”Ёindex peзҡ„ж–№ејҸи®Ўз®—еҗ„дёӘеҚ•зӮ№еҢәй—ҙеҜ№еә”зҡ„и®°еҪ•жқЎж•°пјҢеҰӮжһңеӨ§дәҺжҲ–зӯүдәҺ200дёӘзҡ„иҜқпјҢеҸҜе°ұдёҚиғҪдҪҝз”Ёindex peдәҶпјҢиҰҒдҪҝз”ЁжүҖи°“зҡ„зҙўеј•з»ҹи®Ўж•°жҚ®жқҘиҝӣиЎҢдј°з®—гҖӮеғҸдјҡдёәжҜҸдёӘиЎЁз»ҙжҠӨдёҖд»Ҫз»ҹи®Ўж•°жҚ®дёҖж ·пјҢMySQLд№ҹдјҡдёәиЎЁдёӯзҡ„жҜҸдёҖдёӘзҙўеј•з»ҙжҠӨдёҖд»Ҫз»ҹи®Ўж•°жҚ®пјҢжҹҘзңӢжҹҗдёӘиЎЁдёӯзҙўеј•зҡ„з»ҹи®Ўж•°жҚ®еҸҜд»ҘдҪҝз”ЁSHOW INDEX FROM иЎЁеҗҚзҡ„иҜӯжі•гҖӮ
CardinalityеұһжҖ§иЎЁзӨәзҙўеј•еҲ—дёӯдёҚйҮҚеӨҚеҖјзҡ„дёӘж•°гҖӮжҜ”еҰӮеҜ№дәҺдёҖдёӘдёҖдёҮиЎҢи®°еҪ•зҡ„иЎЁжқҘиҜҙпјҢжҹҗдёӘзҙўеј•еҲ—зҡ„CardinalityеұһжҖ§жҳҜ10000пјҢйӮЈж„Ҹе‘ізқҖиҜҘеҲ—дёӯжІЎжңүйҮҚеӨҚзҡ„еҖјпјҢеҰӮжһңCardinalityеұһжҖ§жҳҜ1зҡ„иҜқпјҢе°ұж„Ҹе‘ізқҖиҜҘеҲ—зҡ„еҖје…ЁйғЁжҳҜйҮҚеӨҚзҡ„гҖӮдёҚиҝҮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеҜ№дәҺInnoDBеӯҳеӮЁеј•ж“ҺжқҘиҜҙпјҢдҪҝз”ЁSHOW INDEXиҜӯеҸҘеұ•зӨәеҮәжқҘзҡ„жҹҗдёӘзҙўеј•еҲ—зҡ„CardinalityеұһжҖ§жҳҜдёҖдёӘдј°и®ЎеҖјпјҢ并дёҚжҳҜзІҫзЎ®зҡ„гҖӮеҸҜд»Ҙж №жҚ®иҝҷдёӘеұһжҖ§жқҘдј°з®—INиҜӯеҸҘдёӯзҡ„еҸӮж•°жүҖеҜ№еә”зҡ„и®°еҪ•ж•°пјҡ
1пјүдҪҝз”ЁSHOW TABLE STATUSеұ•зӨәеҮәзҡ„RowsеҖјпјҢд№ҹе°ұжҳҜдёҖдёӘиЎЁдёӯжңүеӨҡе°‘жқЎи®°еҪ•гҖӮ
2пјүдҪҝз”ЁSHOW INDEXиҜӯеҸҘеұ•зӨәеҮәзҡ„CardinalityеұһжҖ§гҖӮ
3пјүж №жҚ®дёҠйқўдёӨдёӘеҖјеҸҜд»Ҙз®—еҮәidx_key1зҙўеј•еҜ№дәҺзҡ„key1еҲ—е№іеқҮеҚ•дёӘеҖјзҡ„йҮҚеӨҚж¬Ўж•°пјҡRows/Cardinality
4пјүжүҖд»ҘжҖ»е…ұйңҖиҰҒеӣһиЎЁзҡ„и®°еҪ•ж•°е°ұжҳҜпјҡINиҜӯеҸҘдёӯзҡ„еҸӮж•°дёӘж•°*Rows/CardinalityгҖӮ
NULLеҖјеӨ„зҗҶ
дёҠйқўзҹҘйҒ“еңЁз»ҹи®ЎеҲ—дёҚйҮҚеӨҚеҖјзҡ„ж—¶еҖҷпјҢдјҡеҪұе“ҚеҲ°жҹҘиҜўдјҳеҢ–еҷЁгҖӮ
еҜ№дәҺNULLпјҢжңүдёүз§ҚзҗҶи§Јж–№ејҸпјҡ
NULLеҖјд»ЈиЎЁдёҖдёӘжңӘзЎ®е®ҡзҡ„еҖјпјҢжҜҸдёҖдёӘNULLеҖјйғҪжҳҜзӢ¬дёҖж— дәҢзҡ„пјҢеңЁз»ҹи®ЎеҲ—дёҚйҮҚеӨҚеҖјзҡ„ж—¶еҖҷеә”иҜҘйғҪеҪ“дҪңзӢ¬з«Ӣзҡ„гҖӮ
NULLеҖјеңЁдёҡеҠЎдёҠе°ұжҳҜд»ЈиЎЁжІЎжңүпјҢжүҖжңүзҡ„NULLеҖјд»ЈиЎЁзҡ„ж„Ҹд№үжҳҜдёҖж ·зҡ„пјҢжүҖд»ҘжүҖжңүзҡ„NULLеҖјйғҪдёҖж ·пјҢеңЁз»ҹи®ЎеҲ—дёҚйҮҚеӨҚеҖјзҡ„ж—¶еҖҷеә”иҜҘеҸӘз®—дёҖдёӘгҖӮ
NULLе®Ңе…ЁжІЎжңүж„Ҹд№үпјҢеңЁз»ҹи®ЎеҲ—дёҚйҮҚеӨҚеҖјзҡ„ж—¶еҖҷеә”иҜҘеҝҪз•ҘNULLгҖӮ
innodbжҸҗдҫӣдәҶдёҖдёӘзі»з»ҹеҸҳйҮҸпјҡ
show global variables like '%innodb_stats_method%';
иҝҷдёӘеҸҳйҮҸжңүдёүдёӘеҖјпјҡ
nulls_equalпјҡи®ӨдёәжүҖжңүNULLеҖјйғҪжҳҜзӣёзӯүзҡ„гҖӮиҝҷдёӘеҖјд№ҹжҳҜinnodb_stats_methodзҡ„й»ҳи®ӨеҖјгҖӮеҰӮжһңжҹҗдёӘзҙўеј•еҲ—дёӯNULLеҖјзү№еҲ«еӨҡзҡ„иҜқпјҢиҝҷз§Қз»ҹи®Ўж–№ејҸдјҡи®©дјҳеҢ–еҷЁи®ӨдёәжҹҗдёӘеҲ—дёӯе№іеқҮдёҖдёӘеҖјйҮҚеӨҚж¬Ўж•°зү№еҲ«еӨҡпјҢжүҖд»ҘеҖҫеҗ‘дәҺдёҚдҪҝз”Ёзҙўеј•иҝӣиЎҢи®ҝй—®гҖӮ
nulls_unequalпјҡи®ӨдёәжүҖжңүNULLеҖјйғҪжҳҜдёҚзӣёзӯүзҡ„гҖӮеҰӮжһңжҹҗдёӘзҙўеј•еҲ—дёӯNULLеҖјзү№еҲ«еӨҡзҡ„иҜқпјҢиҝҷз§Қз»ҹи®Ўж–№ејҸдјҡи®©дјҳеҢ–еҷЁи®ӨдёәжҹҗдёӘеҲ—дёӯе№іеқҮдёҖдёӘеҖјйҮҚеӨҚж¬Ўж•°зү№еҲ«е°‘пјҢжүҖд»ҘеҖҫеҗ‘дәҺдҪҝз”Ёзҙўеј•иҝӣиЎҢи®ҝй—®гҖӮ
nulls_ignoredпјҡзӣҙжҺҘжҠҠNULLеҖјеҝҪз•ҘжҺүгҖӮ
жңҖеҘҪдёҚеңЁзҙўеј•еҲ—дёӯеӯҳж”ҫNULLеҖјжүҚжҳҜжӯЈи§Ј
дә”гҖҒз»ҹи®Ўж•°жҚ®
InnoDBжҸҗдҫӣдәҶдёӨз§ҚеӯҳеӮЁз»ҹи®Ўж•°жҚ®зҡ„ж–№ејҸпјҡ
вҖў з»ҹи®Ўж•°жҚ®еӯҳеӮЁеңЁзЈҒзӣҳдёҠгҖӮ
вҖў з»ҹи®Ўж•°жҚ®еӯҳеӮЁеңЁеҶ…еӯҳдёӯпјҢеҪ“жңҚеҠЎеҷЁе…ій—ӯж—¶иҝҷдәӣиҝҷдәӣз»ҹи®Ўж•°жҚ®е°ұйғҪиў«жё…йҷӨжҺүдәҶгҖӮ
MySQLз»ҷжҲ‘们жҸҗдҫӣдәҶзі»з»ҹеҸҳйҮҸinnodb_stats_persistentжқҘжҺ§еҲ¶еҲ°еә•йҮҮз”Ёе“Әз§Қж–№ејҸеҺ»еӯҳеӮЁз»ҹи®Ўж•°жҚ®гҖӮеңЁMySQL 5.6.6д№ӢеүҚпјҢinnodb_stats_persistentзҡ„еҖјй»ҳи®ӨжҳҜOFFпјҢд№ҹе°ұжҳҜиҜҙInnoDBзҡ„з»ҹи®Ўж•°жҚ®й»ҳи®ӨжҳҜеӯҳеӮЁеҲ°еҶ…еӯҳзҡ„пјҢд№ӢеҗҺзҡ„зүҲжң¬дёӯinnodb_stats_persistentзҡ„еҖјй»ҳи®ӨжҳҜONпјҢд№ҹе°ұжҳҜз»ҹи®Ўж•°жҚ®й»ҳи®Өиў«еӯҳеӮЁеҲ°зЈҒзӣҳдёӯгҖӮ
дёҚиҝҮInnoDBй»ҳи®ӨжҳҜд»ҘиЎЁдёәеҚ•дҪҚжқҘ收йӣҶе’ҢеӯҳеӮЁз»ҹи®Ўж•°жҚ®зҡ„пјҢд№ҹе°ұжҳҜиҜҙжҲ‘们еҸҜд»ҘжҠҠжҹҗдәӣиЎЁзҡ„з»ҹи®Ўж•°жҚ®пјҲд»ҘеҸҠиҜҘиЎЁзҡ„зҙўеј•з»ҹи®Ўж•°жҚ®пјүеӯҳеӮЁеңЁзЈҒзӣҳдёҠпјҢжҠҠеҸҰдёҖдәӣиЎЁзҡ„з»ҹи®Ўж•°жҚ®еӯҳеӮЁеңЁеҶ…еӯҳдёӯгҖӮжҲ‘们еҸҜд»ҘеңЁеҲӣе»әе’Ңдҝ®ж”№иЎЁзҡ„ж—¶еҖҷйҖҡиҝҮжҢҮе®ҡSTATS_PERSISTENTеұһжҖ§жқҘжҢҮжҳҺиҜҘиЎЁзҡ„з»ҹи®Ўж•°жҚ®еӯҳеӮЁж–№ејҸгҖӮ
1гҖҒеҹәдәҺзЈҒзӣҳзҡ„ж°ёд№…жҖ§з»ҹи®Ўж•°жҚ®
еҪ“жҲ‘们йҖүжӢ©жҠҠжҹҗдёӘиЎЁд»ҘеҸҠиҜҘиЎЁзҙўеј•зҡ„з»ҹи®Ўж•°жҚ®еӯҳж”ҫеҲ°зЈҒзӣҳдёҠж—¶пјҢе®һйҷ…дёҠжҳҜжҠҠиҝҷдәӣз»ҹи®Ўж•°жҚ®еӯҳеӮЁеҲ°дәҶдёӨдёӘиЎЁйҮҢпјҡ
вҖў innodb_table_statsеӯҳеӮЁдәҶе…ідәҺиЎЁзҡ„з»ҹи®Ўж•°жҚ®пјҢжҜҸдёҖжқЎи®°еҪ•еҜ№еә”зқҖдёҖдёӘиЎЁзҡ„з»ҹи®Ўж•°жҚ®
вҖў innodb_index_statsеӯҳеӮЁдәҶе…ідәҺзҙўеј•зҡ„з»ҹи®Ўж•°жҚ®пјҢжҜҸдёҖжқЎи®°еҪ•еҜ№еә”зқҖдёҖдёӘзҙўеј•зҡ„дёҖдёӘз»ҹи®ЎйЎ№зҡ„з»ҹи®Ўж•°жҚ®
2гҖҒе®ҡжңҹжӣҙж–°з»ҹи®Ўж•°жҚ®
вҖў зі»з»ҹеҸҳйҮҸinnodb_stats_auto_recalcеҶіе®ҡзқҖжңҚеҠЎеҷЁжҳҜеҗҰиҮӘеҠЁйҮҚж–°и®Ўз®—з»ҹи®Ўж•°жҚ®пјҢе®ғзҡ„й»ҳи®ӨеҖјжҳҜONпјҢд№ҹе°ұжҳҜиҜҘеҠҹиғҪй»ҳи®ӨжҳҜејҖеҗҜзҡ„гҖӮжҜҸдёӘиЎЁйғҪз»ҙжҠӨдәҶдёҖдёӘеҸҳйҮҸпјҢиҜҘеҸҳйҮҸи®°еҪ•зқҖеҜ№иҜҘиЎЁиҝӣиЎҢеўһеҲ ж”№зҡ„и®°еҪ•жқЎж•°пјҢеҰӮжһңеҸ‘з”ҹеҸҳеҠЁзҡ„и®°еҪ•ж•°йҮҸи¶…иҝҮдәҶиЎЁеӨ§е°Ҹзҡ„10%пјҢ并且иҮӘеҠЁйҮҚж–°и®Ўз®—з»ҹи®Ўж•°жҚ®зҡ„еҠҹиғҪжҳҜжү“ејҖзҡ„пјҢйӮЈд№ҲжңҚеҠЎеҷЁдјҡйҮҚж–°иҝӣиЎҢдёҖж¬Ўз»ҹи®Ўж•°жҚ®зҡ„и®Ўз®—пјҢ并且жӣҙж–°innodb_table_statsе’Ңinnodb_index_statsиЎЁгҖӮдёҚиҝҮиҮӘеҠЁйҮҚж–°и®Ўз®—з»ҹи®Ўж•°жҚ®зҡ„иҝҮзЁӢжҳҜејӮжӯҘеҸ‘з”ҹзҡ„пјҢд№ҹе°ұжҳҜеҚідҪҝиЎЁдёӯеҸҳеҠЁзҡ„и®°еҪ•ж•°и¶…иҝҮдәҶ10%пјҢиҮӘеҠЁйҮҚж–°и®Ўз®—з»ҹи®Ўж•°жҚ®д№ҹдёҚдјҡз«ӢеҚіеҸ‘з”ҹпјҢеҸҜиғҪдјҡ延иҝҹеҮ з§’жүҚдјҡиҝӣиЎҢи®Ўз®—гҖӮ
вҖўеҰӮжһңinnodb_stats_auto_recalcзі»з»ҹеҸҳйҮҸзҡ„еҖјдёәOFFзҡ„иҜқпјҢжҲ‘们д№ҹеҸҜд»ҘжүӢеҠЁи°ғз”ЁANALYZE TABLEиҜӯеҸҘжқҘйҮҚж–°и®Ўз®—з»ҹи®Ўж•°жҚ®гҖӮANALYZE TABLE single_table;
3гҖҒжҺ§еҲ¶жү§иЎҢи®ЎеҲ’
Index Hints
вҖўUSE INDEXпјҡйҷҗеҲ¶зҙўеј•зҡ„дҪҝз”ЁиҢғеӣҙпјҢеңЁж•°жҚ®иЎЁйҮҢе»әз«ӢдәҶеҫҲеӨҡзҙўеј•пјҢеҪ“MySQLеҜ№зҙўеј•иҝӣиЎҢйҖүжӢ©ж—¶пјҢиҝҷдәӣзҙўеј•йғҪеңЁиҖғиҷ‘зҡ„иҢғеӣҙеҶ…гҖӮдҪҶжңүж—¶жҲ‘们еёҢжңӣMySQLеҸӘиҖғиҷ‘еҮ дёӘзҙўеј•пјҢиҖҢдёҚжҳҜе…ЁйғЁзҡ„зҙўеј•пјҢиҝҷе°ұйңҖиҰҒз”ЁеҲ°USE INDEXеҜ№жҹҘиҜўиҜӯеҸҘиҝӣиЎҢи®ҫзҪ®гҖӮ
вҖўIGNORE INDEX пјҡйҷҗеҲ¶дёҚдҪҝз”Ёзҙўеј•зҡ„иҢғеӣҙ
вҖўFORCE INDEXпјҡжҲ‘们еёҢжңӣMySQLеҝ…йЎ»иҰҒдҪҝз”ЁжҹҗдёҖдёӘзҙўеј•(з”ұдәҺ MySQLеңЁжҹҘиҜўж—¶еҸӘиғҪдҪҝз”ЁдёҖдёӘзҙўеј•пјҢеӣ жӯӨеҸӘиғҪејәиҝ«MySQLдҪҝз”ЁдёҖдёӘзҙўеј•)гҖӮиҝҷе°ұйңҖиҰҒдҪҝз”ЁFORCE INDEXжқҘе®ҢжҲҗиҝҷдёӘеҠҹиғҪгҖӮ
еҹәжң¬иҜӯжі•ж јејҸпјҡ
SELECT * FROM table1 USE|IGNORE|FORCE INDEX (col1_index,col2_index) WHERE col1=1 AND col2=2 AND col3=3
еҲ°жӯӨпјҢзӣёдҝЎеӨ§е®¶еҜ№вҖңMySQLдёӯзҡ„жҹҘиҜўдјҳеҢ–еҷЁжҖҺд№Ҳз”ЁвҖқжңүдәҶжӣҙж·ұзҡ„дәҶи§ЈпјҢдёҚеҰЁжқҘе®һйҷ…ж“ҚдҪңдёҖз•Әеҗ§пјҒиҝҷйҮҢжҳҜдәҝйҖҹдә‘зҪ‘з«ҷпјҢжӣҙеӨҡзӣёе…іеҶ…е®№еҸҜд»Ҙиҝӣе…Ҙзӣёе…ійў‘йҒ“иҝӣиЎҢжҹҘиҜўпјҢе…іжіЁжҲ‘们пјҢ继з»ӯеӯҰд№ пјҒ





