Javaд№ӢJVMзҡ„зҹҘиҜҶзӮ№жңүе“Әдәӣ
д»ҠеӨ©е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢJavaд№ӢJVMзҡ„зҹҘиҜҶзӮ№жңүе“Әдәӣзҡ„зӣёе…ізҹҘиҜҶзӮ№пјҢеҶ…е®№иҜҰз»ҶпјҢйҖ»иҫ‘жё…жҷ°пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳеӨӘдәҶи§Јиҝҷж–№йқўзҡ„зҹҘиҜҶпјҢжүҖд»ҘеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘдәҶи§ЈдёҖдёӢеҗ§гҖӮ

дёҖ.JVMеҶ…еӯҳеҢәеҹҹеҲ’еҲҶ
JVMдёәд»Җд№ҲиҰҒеҲ’еҲҶеҮәиҝҷдәӣеҢәеҹҹе‘ў?JVMеҶ…еӯҳжҳҜд»Һж“ҚдҪңзі»з»ҹйҮҢйқўз”іиҜ·иҝҮжқҘзҡ„,иҖҢJVMе°ұж №жҚ®еҠҹиғҪйңҖжұӮе°ҶиҝҷдәӣеҲ’еҲҶжҲҗдәҶдёҖдәӣе°Ҹзҡ„жЁЎеқ—,иҝҷж ·дёҖеқ—еӨ§зҡ„еңәең°е°ұеҸҜд»ҘеҲ’еҲҶжҲҗдёҖдәӣе°Ҹзҡ„жЁЎеқ—,然еҗҺжҜҸдёӘжЁЎеқ—е°ұиҙҹиҙЈиҮӘе·ұзҡ„еҠҹиғҪе°ұеҸҜд»ҘдәҶ,йӮЈжҺҘдёӢжқҘзңӢзңӢиҝҷдәӣеҢәеҹҹзҡ„еҠҹиғҪеҲ°еә•жҳҜд»Җд№Ҳе‘ў!
1.зЁӢеәҸи®Ўж•°еҷЁ
зЁӢеәҸи®Ўж•°еҷЁжҳҜеҶ…еӯҳдёӯжңҖе°Ҹзҡ„еҢәеҹҹ,иҝҷйҮҢйқўдё»иҰҒдҝқеӯҳдәҶдёӢдёҖжқЎиҰҒжү§иЎҢзҡ„жҢҮд»Өзҡ„ең°еқҖеңЁе“ӘйҮҢ(жҢҮд»Өе°ұжҳҜеӯ—иҠӮз Ғ,дёҖиҲ¬зЁӢеәҸиҰҒиҝҗиЎҢ,JVMе°ұйңҖиҰҒжҠҠеӯ—иҠӮз ҒеҠ иҪҪеҮәжқҘж”ҫеҲ°еҶ…еӯҳдёӯ,然еҗҺзЁӢеәҸеҶҚжҠҠдёҖжқЎдёҖжқЎзҡ„жҢҮд»Өд»ҺеҶ…еӯҳдёӯеҸ–еҮәжқҘж”ҫеҲ°CPUдёҠеҺ»жү§иЎҢ,жүҖд»Ҙеҝ…йЎ»иҰҒи®°дҪҸеҪ“еүҚжү§иЎҢеҲ°е“ӘдёҖжқЎжҢҮд»Ө,д»ҘеҸҠдёӢдёҖжқЎеңЁе“ӘйҮҢ,еӣ дёәCPUдёҚжҳҜеҸӘз»ҷдёҖдёӘиҝӣзЁӢжҸҗдҫӣжңҚеҠЎзҡ„,жҳҜз»ҷжүҖжңүзҡ„иҝӣзЁӢйғҪжҸҗдҫӣжңҚеҠЎ,жҳҜ并еҸ‘ејҸзҡ„жү§иЎҢзЁӢеәҸзҡ„,еҸҲеӣ дёәж“ҚдҪңзі»з»ҹжҳҜд»ҘзәҝзЁӢдёәеҚ•дҪҚиҝӣиЎҢи°ғеәҰжү§иЎҢзҡ„,жүҖд»ҘжҜҸдёӘзәҝзЁӢйғҪиҰҒжңүиҮӘе·ұзҡ„жү§иЎҢдҪҚзҪ®,д№ҹе°ұжҳҜжҜҸдёҖдёӘзәҝзЁӢйғҪйңҖиҰҒжңүдёҖдёӘзЁӢеәҸи®Ўж•°еҷЁжқҘи®°еҪ•дҪҚзҪ®!)
2.ж Ҳ
ж ҲйҮҢйқўеӯҳж”ҫзҡ„дё»иҰҒжҳҜеұҖйғЁеҸҳйҮҸе’Ңж–№жі•и°ғз”ЁдҝЎжҒҜ,еҸӘиҰҒж¶үеҸҠеҲ°ж–°ж–№жі•зҡ„и°ғз”Ё,е°ұдјҡжңү"е…Ҙж Ҳ"зҡ„ж“ҚдҪң,жҜҸжү§иЎҢе®ҢжҲҗдёҖдёӘж–№жі•,е°ұдјҡжңү"еҮәж Ҳ"зҡ„ж“ҚдҪң,иҖҢдё”ж Ҳд№ҹжҳҜжҜҸдёӘзәҝзЁӢйғҪжңүдёҖд»Ҫзҡ„
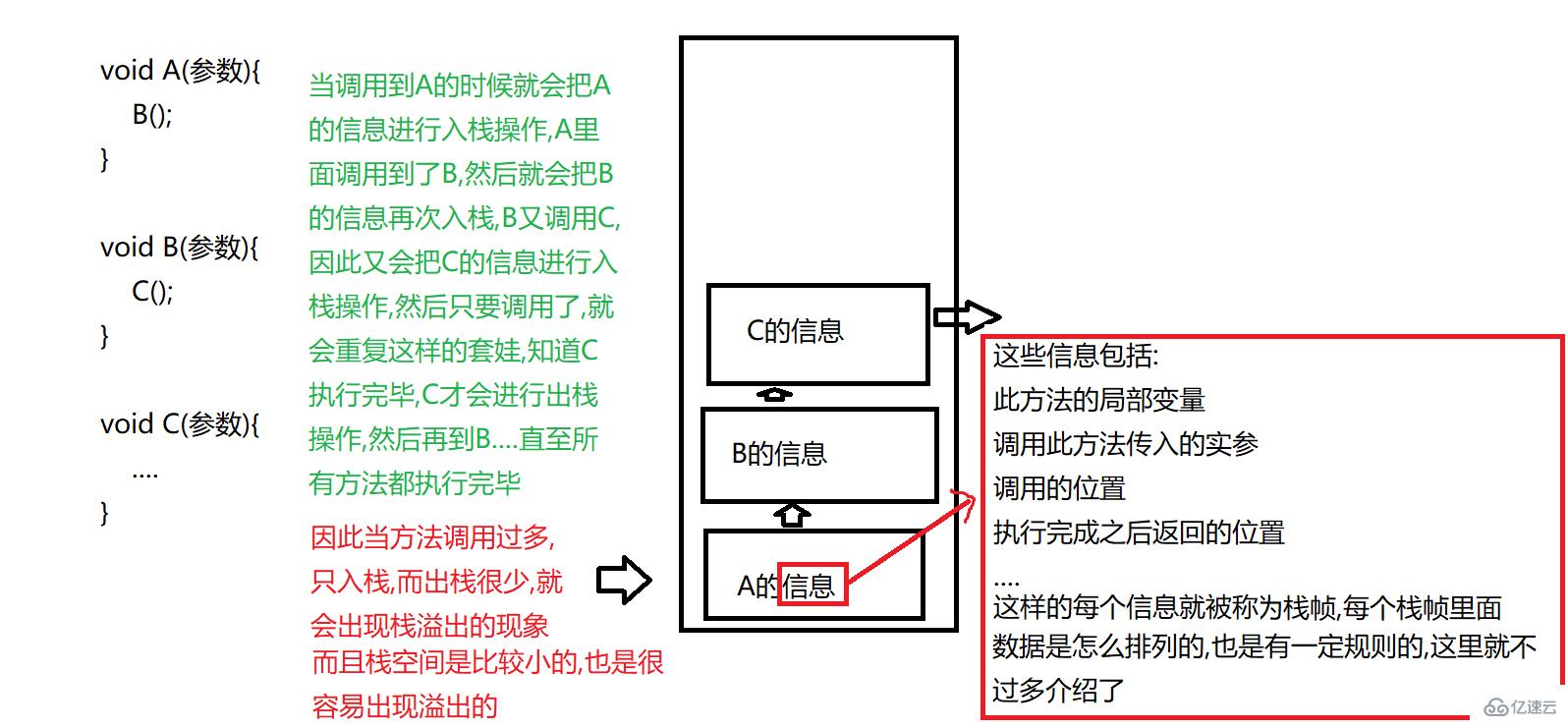
еӣ жӯӨеҜ№дәҺйҖ’еҪ’жқҘиҜҙ,дёҖе®ҡиҰҒжҺ§еҲ¶еҘҪйҖ’еҪ’жқЎд»¶,еҗҰеҲҷеҫҲжңүеҸҜиғҪдјҡеҮәзҺ°ж ҲжәўеҮә(StackOverflowException)ејӮеёёзҡ„!
3.е Ҷ
е ҶжҳҜеҶ…еӯҳдёӯз©әй—ҙжңҖеӨ§зҡ„еҢәеҹҹ,иҖҢдё”е ҶжҳҜжҜҸдёӘиҝӣзЁӢеҸӘжңүдёҖд»Ҫзҡ„,иҝӣзЁӢдёӯзҡ„еӨҡдёӘзәҝзЁӢе…¬з”ЁдёҖдёӘе Ҷ,йҮҢйқўдё»иҰҒеӯҳж”ҫзқҖnewеҮәжқҘзҡ„еҜ№иұЎд»ҘеҸҠеҜ№иұЎзҡ„жҲҗе‘ҳеҸҳйҮҸ,дҫӢеҰӮString s = new String()еҰӮжһңеңЁж–№жі•йҮҢйқўиҝҷйҮҢзҡ„sе°ұжҳҜеұҖйғЁеҸҳйҮҸжҳҜеңЁж ҲдёҠзҡ„,еҰӮжһңиҝҷдёӘsжҳҜжҲҗе‘ҳеҸҳйҮҸ,е°ұжҳҜеңЁе ҶдёҠзҡ„,иҖҢеҗҺйқўnew String()жҳҜеҜ№иұЎзҡ„жң¬дҪ“,еҜ№иұЎжҳҜеңЁе ҶдёҠзҡ„,иҝҷжҳҜе®№жҳ“ж··ж·Ҷзҡ„ең°ж–№,еҸҰеӨ–е ҶиҝҳжңүдёҖдёӘйҮҚиҰҒзҡ„зӮ№е°ұжҳҜе…ідәҺеһғеңҫеӣһ收问йўҳ,иҝҷдёӘеҗҺйқўеҶҚиҜҰз»Ҷд»Ӣз»Қ!
4.ж–№жі•еҢә
ж–№жі•еҢәдёӯеӯҳж”ҫзҡ„жҳҜ"зұ»еҜ№иұЎ",е№іеёёжүҖеҶҷзҡ„.javaд»Јз Ғз»ҸиҝҮзј–иҜ‘еҷЁзҝ»иҜ‘иҝҮеҗҺе°ұдјҡеҸҳжҲҗ.class(дәҢиҝӣеҲ¶еӯ—иҠӮз Ғ),然еҗҺ.classе°ұдјҡиў«еҠ иҪҪеҲ°еҶ…еӯҳдёӯ,д№ҹе°ұиў«JVMжһ„йҖ жҲҗдәҶзұ»еҜ№иұЎ(еҠ иҪҪзҡ„иҝҮзЁӢе°ұжҳҜз§°дёә"зұ»еҠ иҪҪ"),иҖҢиҝҷдәӣзұ»еҜ№иұЎе°ұдјҡеӯҳж”ҫеҲ°ж–№жі•еҢәдёӯ,иҝҷйҮҢйқўе°ұе…·дҪ“жҸҸиҝ°дәҶзұ»й•ҝе•Ҙж ·(зұ»зҡ„еҗҚеӯ—,зұ»зҡ„жҲҗе‘ҳеҸҠе…¶жҲҗе‘ҳеҗҚжҲҗе‘ҳзұ»еһӢ,зұ»зҡ„ж–№жі•еҸҠе…¶ж–№жі•еҗҚж–№жі•зұ»еһӢ,д»ҘеҸҠдёҖдәӣжҢҮд»ӨвҖҰеҸҰеӨ–зұ»еҜ№иұЎйҮҢйқўиҝҳеӯҳж”ҫдәҶдёҖдёӘеҫҲйҮҚиҰҒзҡ„дёңиҘҝ,е°ұжҳҜйқҷжҖҒжҲҗе‘ҳ,дёҖиҲ¬иў«staticдҝ®йҘ°зҡ„жҲҗе‘ҳе°ұжҲҗдёәдәҶзұ»еұһжҖ§,иҖҢжҷ®йҖҡзҡ„ж–№жі•иў«з§°дёәе®һдҫӢеұһжҖ§,иҝҷжҳҜжңүеҫҲеӨ§е·®еҲ«зҡ„)!
дёҠйқўжүҖд»Ӣз»Қзҡ„жҳҜJVMдёӯжҜ”иҫғеёёи§Ғзҡ„еҢәеҹҹ,иҖҢдёҖдәӣJVMзҡ„еҶ…еӯҳеҢәеҹҹеҲ’еҲҶдёҚдёҖе®ҡжҳҜз¬ҰеҗҲе®һйҷ…жғ…еҶөзҡ„,JVMеңЁе®һзҺ°зҡ„иҝҮзЁӢдёӯеҢәеҹҹзҡ„еҲ’еҲҶжҳҜдёҚе°ҪзӣёеҗҢзҡ„,дёҚеҗҢзҡ„еҺӮе•ҶдёҚеҗҢзүҲжң¬зҡ„JVMйғҪжҳҜжңүеҸҜиғҪеӯҳеңЁе·®ејӮзҡ„,дёҚиҝҮеҜ№дәҺжҲ‘们жҷ®йҖҡзҡ„зЁӢеәҸе‘ҳиҖҢи®І,еҸӘиҰҒдёҚжҳҜеҺ»е®һзҺ°JVM,йӮЈд№Ҳе°ұдёҚйңҖиҰҒдәҶи§ЈйӮЈд№Ҳж·ұеҲ»,и®ІдёҠйқўзҡ„еҮ дёӘеёёи§Ғзҡ„еҢәеҹҹеҠ д»ҘдәҶи§Је°ұеҸҜд»ҘдәҶ!
дәҢ.JVMзұ»еҠ иҪҪжңәеҲ¶
зұ»еҠ иҪҪе…¶е®һжҳҜи®ҫи®ЎдёҖдёӘиҝҗиЎҢж—¶зҺҜеўғзҡ„дёҖдёӘйҮҚиҰҒзҡ„еҠҹж ёеҝғеҠҹиғҪ,иҝҷжҳҜйқһеёёйҮҚйҮҸзә§зҡ„,еӣ жӯӨжҲ‘иҝҷйҮҢд№ҹе°ұз®ҖеҚ•д»Ӣз»ҚдёҖдёӢ!
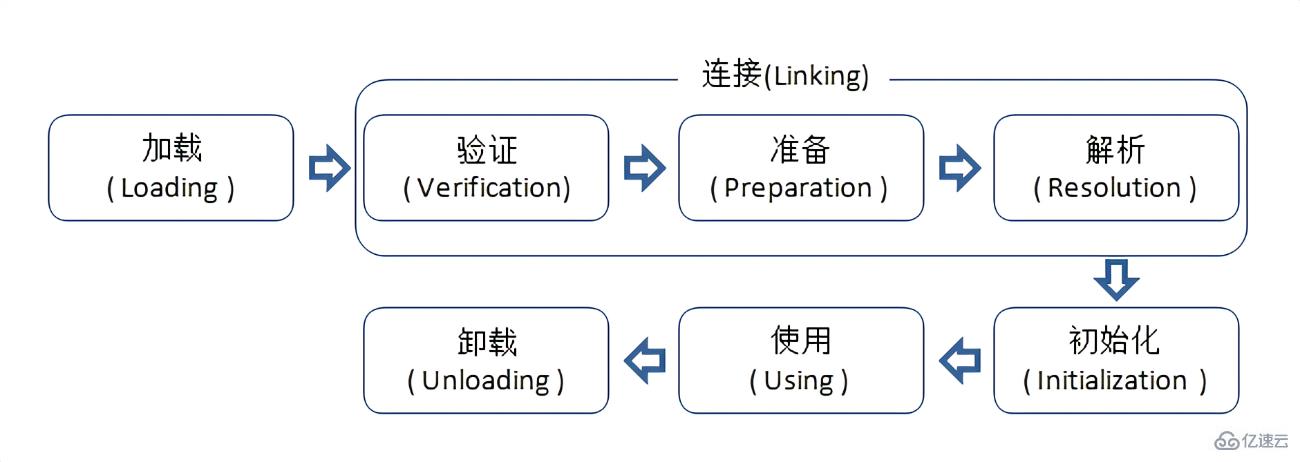
дёҠиҝ°е°ұжҳҜзұ»еҠ иҪҪзҡ„е…·дҪ“иҝҮзЁӢ,жңҖеҗҺйқўзҡ„Usingе’ҢUnloadingе°ұжҳҜдҪҝз”Ёзҡ„иҝҮзЁӢе°ұдёҚд»Ӣз»ҚдәҶ,е°ұд»Ӣз»ҚдёҖдёӢеүҚйқўзҡ„дёүдёӘеӨ§зҡ„жӯҘйӘӨ:
1.Loading(еҠ иҪҪ)
еңЁloadingйҳ¶ж®өе°ұдјҡе…ҲжүҫеҲ°еҜ№еә”зҡ„.classж–Ү件,然еҗҺжү“ејҖ并иҜ»еҸ–(ж №жҚ®еӯ—иҠӮжөҒ).classж–Ү件,еҗҢж—¶еҲқжӯҘз”ҹжҲҗдёҖдёӘзұ»еҜ№иұЎ,иҝҷдёӘе’Ңе®ҢжҲҗзҡ„зұ»еҠ иҪҪ(class Loading)жҳҜдёҚзӣёеҗҢзҡ„,дёҚиҰҒеј„ж··ж·ҶдәҶ!
classж–Ү件зҡ„е…·дҪ“ж јејҸ(еҰӮжһңиҰҒе®һзҺ°дёҖдёӘJavaзј–иҜ‘еҷЁе°ұеҫ—жҢүз…§иҝҷж ·зҡ„ж јејҸжқҘжһ„йҖ ,е®һзҺ°JVMе°ұеҫ—жҢүз…§иҝҷдёӘж јејҸжқҘиҝӣиЎҢеҠ иҪҪ!):

и§ӮеҜҹиҝҷдёӘж јејҸе°ұеҸҜд»ҘзңӢеҲ°.classж–Ү件е°ұжҠҠ.javaж–Ү件дёӯзҡ„ж ёеҝғдҝЎжҒҜйғҪиЎЁиҝ°иҝӣеҺ»дәҶ,еҸӘдёҚиҝҮз»„з»Үж јејҸдёҠеҸ‘з”ҹдәҶиҪ¬еҸҳ,жүҖд»ҘloadingзҺҜиҠӮе°ұдјҡжҠҠиҜ»еҸ–еҲ°зҡ„дҝЎжҒҜ,еҲқжӯҘеЎ«еҶҷеҲ°зұ»еҜ№иұЎдёӯ
2.Linking(иҝһжҺҘ)
иҝһжҺҘдёҖиҲ¬е°ұжҳҜе»әз«ӢеҘҪеӨҡдёӘе®һдҪ“д№Ӣй—ҙзҡ„иҒ”зі»
2.1.Verification(йӘҢиҜҒ)
Verificationе°ұжҳҜдёҖдёӘж ЎйӘҢзҡ„иҝҮзЁӢ,дё»иҰҒе°ұжҳҜйӘҢиҜҒиҜ»еҲ°зҡ„еҶ…е®№жҳҜдёҚжҳҜе’Ң规иҢғдёӯ规е®ҡзҡ„ж јејҸе®Ңе…ЁеҢ№й…Қ,еҰӮжһңеҸ‘зҺ°иҜ»еҲ°зҡ„ж•°жҚ®ж јејҸдёҚз¬ҰеҗҲ规иҢғ,е°ұдјҡзұ»еҠ иҪҪеӨұиҙҘ,并且жҠӣеҮәејӮеёё!
2.2.Preparation(еҮҶеӨҮ)
Preparationйҳ¶ж®өжҳҜжӯЈејҸдёәе®ҡд№үзҡ„еҸҳйҮҸ(йқҷжҖҒеҸҳйҮҸ,е°ұжҳҜstaticдҝ®йҘ°зҡ„еҸҳйҮҸ)еҲҶй…ҚеҶ…еӯҳ并и®ҫзҪ®зұ»еҸҳйҮҸеҲқе§ӢеҖјзҡ„йҳ¶ж®ө,е°ұдјҡз»ҷжҜҸдёӘйқҷжҖҒеҸҳйҮҸеҲҶй…ҚеҶ…еӯҳ,并且и®ҫзҪ®дёә0еҖј!
2.3.Resolution(и§Јжһҗ)
Resolutionйҳ¶ж®өжҳҜJavaиҷҡжӢҹжңәе°ҶеёёйҮҸжұ еҶ…зҡ„з¬ҰеҸ·еј•з”ЁжӣҝжҚўдёәзӣҙжҺҘеј•з”Ёзҡ„иҝҮзЁӢ,д№ҹе°ұжҳҜеҲқе§ӢеҢ–еёёйҮҸзҡ„иҝҮзЁӢ,.classж–Ү件дёӯеёёйҮҸжҳҜйӣҶдёӯж”ҫзҪ®зҡ„,жҜҸдёӘеёёйҮҸдјҡжңүдёҖдёӘзј–еҸ·,иҖҢеңЁ.classж–Ү件дёӯзҡ„з»“жһ„дҪ“йҮҢеҲқе§Ӣжғ…еҶөе°ұеҸӘжҳҜи®°еҪ•зҡ„зј–еҸ·,然еҗҺе°ұеҸҜд»Ҙж №жҚ®иҝҷдёӘзј–еҸ·жүҫеҲ°еҜ№еә”зҡ„еҶ…е®№,еҶҚеЎ«е……еҲ°зұ»еҜ№иұЎдёӯ!
3.Initialization(еҲқе§ӢеҢ–)
Initializationйҳ¶ж®өе°ұжҳҜзңҹжӯЈзҡ„еҜ№зұ»еҜ№иұЎиҝӣиЎҢеҲқе§ӢеҢ–(ж №жҚ®еҶҷзҡ„д»Јз Ғ),е°Өе…¶жҳҜй’ҲеҜ№йқҷжҖҒжҲҗе‘ҳ
4.е…ёеһӢзҡ„йқўиҜ•йўҳ
class A {
public A(){
System.out.println("Aзҡ„жһ„йҖ ж–№жі•");
}
{
System.out.println("Aзҡ„жһ„йҖ д»Јз Ғеқ—");
}
static {
System.out.println("Aзҡ„йқҷжҖҒд»Јз Ғеқ—");
}}class B extends A{
public B(){
System.out.println("Bзҡ„жһ„йҖ ж–№жі•");
}
{
System.out.println("Bзҡ„жһ„йҖ д»Јз Ғеқ—");
}
static {
System.out.println("Bзҡ„йқҷжҖҒд»Јз Ғеқ—");
}}public class Test extends B{
public static void main(String[] args) {
new Test();
new Test();
}}еҸҜд»ҘиҮӘе·ұе…Ҳе°қиҜ•еҶҷдёҖдёӢиҫ“еҮәзҡ„з»“жһң
еҒҡиҝҷж ·зҡ„йўҳе°ұйңҖиҰҒжҠҠжҸЎеҮ дёӘеӨ§зҡ„еҺҹеҲҷ:
зұ»еҠ иҪҪйҳ¶ж®өе°ұдјҡиҝӣиЎҢйқҷжҖҒд»Јз Ғеқ—зҡ„жү§иЎҢ,иҰҒжғіеҲӣе»әе®һдҫӢ,еҠҝеҝ…иҰҒе…ҲиҝӣиЎҢзұ»еҠ иҪҪ
йқҷжҖҒд»Јз Ғеқ—еҸӘжҳҜзұ»еҠ иҪҪйҳ¶ж®өжү§иЎҢдёҖж¬Ў,е…¶д»–йҳ¶ж®өйғҪдёҚдјҡеҶҚжү§иЎҢ
жһ„йҖ ж–№жі•е’Ңжһ„йҖ д»Јз Ғеқ—жҜҸж¬Ўе®һдҫӢеҢ–йғҪдјҡжү§иЎҢ,иҖҢдё”жһ„йҖ д»Јз Ғеқ—дјҡеңЁжһ„йҖ ж–№жі•еүҚйқўжү§иЎҢ~~
зҲ¶зұ»жү§иЎҢеңЁеүҚ,еӯҗзұ»жү§иЎҢеңЁеҗҺ!
зЁӢеәҸжҳҜд»ҺmainејҖе§Ӣжү§иЎҢзҡ„,mainзҡ„Testзҡ„ж–№жі•,еӣ жӯӨиҰҒжү§иЎҢmainе°ұйңҖиҰҒе…ҲеҠ иҪҪTestзұ»
еҸӘжңүж¶үеҸҠеҲ°иҝҷдёӘзұ»дәҶ,зұ»йҮҢйқўзҡ„дёңиҘҝжүҚдјҡиў«еҠ иҪҪ
иҫ“еҮәз»“жһң:
Aзҡ„йқҷжҖҒд»Јз Ғеқ—
Bзҡ„йқҷжҖҒд»Јз Ғеқ—
Aзҡ„жһ„йҖ д»Јз Ғеқ—
Aзҡ„жһ„йҖ ж–№жі•
Bзҡ„жһ„йҖ д»Јз Ғеқ—
Bзҡ„жһ„йҖ ж–№жі•
Aзҡ„жһ„йҖ д»Јз Ғеқ—
Aзҡ„жһ„йҖ ж–№жі•
Bзҡ„жһ„йҖ д»Јз Ғеқ—
Bзҡ„жһ„йҖ ж–№жі•
5.еҸҢдәІе§”жҙҫжЁЎеһӢ
иҝҷдёӘдёңиҘҝжҳҜзұ»еҠ иҪҪдёӯзҡ„дёҖдёӘзҺҜиҠӮ,еӨ„дәҺLoadingйҳ¶ж®ө(жҜ”иҫғйқ еүҚзҡ„йғЁеҲҶ),еҸҢдәІе§”жҙҫжЁЎеһӢжҸҸиҝ°зҡ„е°ұжҳҜJVMдёӯзҡ„зұ»еҠ иҪҪеҷЁ,еҰӮдҪ•ж №жҚ®зұ»зҡ„е…Ёйҷҗе®ҡеҗҚ(java.lang.String)жүҫеҲ°.classж–Ү件зҡ„иҝҮзЁӢгҖӮиҝҷйҮҢзҡ„зұ»еҠ иҪҪеҷЁжҳҜJVMдё“й—ЁжҸҗдҫӣзҡ„еҜ№иұЎ,дё»иҰҒиҙҹиҙЈиҝӣиЎҢзұ»еҠ иҪҪ,жүҖд»Ҙжүҫж–Ү件зҡ„иҝҮзЁӢд№ҹжҳҜз”ұзұ»еҠ иҪҪеҷЁжқҘиҙҹиҙЈзҡ„,.classж–Ү件еҸҜиғҪж”ҫзҪ®зҡ„дҪҚзҪ®жңүеҫҲеӨҡ,жңүзҡ„иҰҒж”ҫеҲ°JDKзӣ®еҪ•йҮҢйқў,жңүзҡ„ж”ҫеҲ°йЎ№зӣ®зӣ®еҪ•йҮҢйқў,иҝҳжңүзҡ„еңЁе…¶д»–зү№е®ҡзҡ„дҪҚзҪ®йҮҢйқў,еӣ жӯӨJVMжҸҗдҫӣдәҶеӨҡдёӘзұ»еҠ иҪҪеҷЁ,жҜҸдёӘзұ»еҠ иҪҪеҷЁиҙҹиҙЈдёҖдёӘзүҮеҢә,иҖҢй»ҳи®Өзҡ„зұ»еҠ иҪҪеҷЁдё»иҰҒжңү3дёӘ:
BootStrapClassLoader:иҙҹиҙЈеҠ иҪҪж ҮеҮҶеә“дёӯзҡ„зұ»(String,ArrayList,Random,ScannerвҖҰ)
ExtensionClassLoader:иҙҹиҙЈеҠ иҪҪJDKжү©еұ•зҡ„зұ»(зҺ°еңЁеҫҲе°‘з”ЁеҲ°)
ApplicationClassLoader:иҙҹиҙЈеҠ иҪҪеҪ“еүҚйЎ№зӣ®зӣ®еҪ•дёӯзҡ„зұ»
еҸҰеӨ–зЁӢеәҸе‘ҳиҝҳеҸҜд»ҘиҮӘе®ҡд№үзұ»еҠ иҪҪеҷЁ,жқҘеҠ иҪҪе…¶д»–зӣ®еҪ•дёӯзҡ„зұ»,Tomcatе°ұиҮӘе®ҡд№үдәҶзұ»еҠ иҪҪеҷЁ,з”ЁжқҘдё“й—ЁеҠ иҪҪwebappsйҮҢйқўзҡ„.class
еҸҢдәІе§”жҙҫжЁЎеһӢе°ұжҸҸиҝ°дәҶиҝҷдёӘжүҫзӣ®еҪ•зҡ„иҝҮзЁӢ,д№ҹе°ұжҳҜдёҠиҝ°зұ»еҠ иҪҪеҷЁжҳҜеҰӮдҪ•й…ҚеҗҲзҡ„
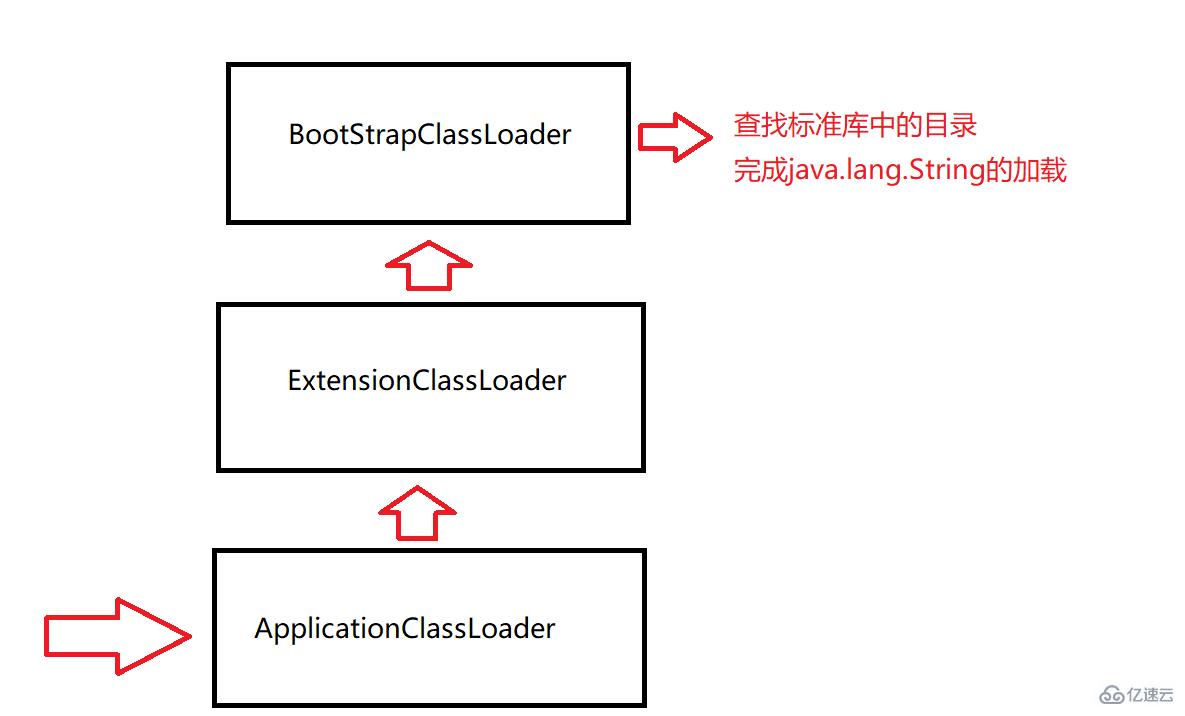
иҖғиҷ‘жүҫдёҖдёӢjava.lang.String:
зЁӢеәҸеҗҜеҠЁ,е°ұдјҡе…Ҳиҝӣе…ҘApplicationClassLoaderзұ»еҠ иҪҪеҷЁ
ApplicationClassLoaderзұ»еҠ иҪҪеҷЁе°ұдјҡжЈҖжҹҘдёӢ,е®ғзҡ„зҲ¶еҠ иҪҪеҷЁжҳҜеҗҰе·Із»ҸеҠ иҪҪиҝҮдәҶ,еҰӮжһңжІЎжңү,е°ұи°ғз”ЁзҲ¶ зұ»еҠ иҪҪеҷЁExtensionClassLoader
ExtensionClassLoaderзұ»еҠ иҪҪеҷЁе°ұдјҡжЈҖжҹҘдёӢ,е®ғзҡ„зҲ¶еҠ иҪҪеҷЁжҳҜеҗҰе·Із»ҸеҠ иҪҪиҝҮдәҶ,еҰӮжһңжІЎжңү,е°ұи°ғз”ЁзҲ¶ зұ»еҠ иҪҪеҷЁBootStrapClassLoader
BootStrapClassLoaderзұ»еҠ иҪҪеҷЁд№ҹдјҡжЈҖжҹҘдёӢ,е®ғзҡ„зҲ¶еҠ иҪҪеҷЁжҳҜеҗҰе·Із»ҸеҠ иҪҪиҝҮдәҶ,然еҗҺеҸ‘зҺ°жІЎжңүзҲ¶дәІ,дәҺжҳҜе°ұжү«жҸҸиҮӘе·ұиҙҹиҙЈзҡ„зӣ®еҪ•
然еҗҺjava.lang.StringиҝҷдёӘзұ»е°ұеңЁж ҮеҮҶеә“дёӯиғҪжүҫеҲ°,然еҗҺеҗҺз»ӯе°ұз”ұBootStrapClassLoaderеҠ иҪҪеҷЁиҙҹиҙЈеҗҺз»ӯзҡ„еҠ иҪҪиҝҮзЁӢ,жҹҘжүҫзҺҜиҠӮе°ұз»“жқҹдәҶ!
иҖғиҷ‘жүҫдёҖдёӢиҮӘе·ұеҶҷзҡ„Testзұ»:
зЁӢеәҸеҗҜеҠЁ,е°ұдјҡе…Ҳиҝӣе…ҘApplicationClassLoaderзұ»еҠ иҪҪеҷЁ
ApplicationClassLoaderзұ»еҠ иҪҪеҷЁе°ұдјҡжЈҖжҹҘдёӢ,е®ғзҡ„зҲ¶еҠ иҪҪеҷЁжҳҜеҗҰе·Із»ҸеҠ иҪҪиҝҮдәҶ,еҰӮжһңжІЎжңү,е°ұи°ғз”ЁзҲ¶ зұ»еҠ иҪҪеҷЁExtensionClassLoader
ExtensionClassLoaderзұ»еҠ иҪҪеҷЁе°ұдјҡжЈҖжҹҘдёӢ,е®ғзҡ„зҲ¶еҠ иҪҪеҷЁжҳҜеҗҰе·Із»ҸеҠ иҪҪиҝҮдәҶ,еҰӮжһңжІЎжңү,е°ұи°ғз”ЁзҲ¶ зұ»еҠ иҪҪеҷЁBootStrapClassLoader
BootStrapClassLoaderзұ»еҠ иҪҪеҷЁд№ҹдјҡжЈҖжҹҘдёӢ,е®ғзҡ„зҲ¶еҠ иҪҪеҷЁжҳҜеҗҰе·Із»ҸеҠ иҪҪиҝҮдәҶ,然еҗҺеҸ‘зҺ°жІЎжңүзҲ¶дәІ,дәҺжҳҜе°ұжү«жҸҸиҮӘе·ұиҙҹиҙЈзҡ„зӣ®еҪ•,жІЎжү«жҸҸеҲ°,е°ұдјҡеӣһеҲ°еӯҗеҠ иҪҪеҷЁдёӯ继з»ӯжү«жҸҸ
ExtensionClassLoaderжү«жҸҸиҮӘе·ұиҙҹиҙЈзҡ„зӣ®еҪ•,д№ҹжІЎжңүжү«жҸҸеҲ°,еҶҚеӣһеҲ°еӯҗеҠ иҪҪеҷЁдёӯ继з»ӯжү«жҸҸ
ApplicationClassLoaderд№ҹжү«жҸҸиҮӘе·ұиҙҹиҙЈзҡ„зӣ®еҪ•,иҮӘе·ұеҶҷзҡ„зұ»е°ұеңЁиҮӘе·ұзҡ„йЎ№зӣ®зӣ®еҪ•дёӢ,еӣ жӯӨе°ұиғҪжүҫеҲ°,然еҗҺеҗҺз»ӯзҡ„зұ»еҠ иҪҪе°ұз”ұApplicationClassLoadе®ҢжҲҗ,жӯӨж—¶жҹҘжүҫзӣ®еҪ•зҡ„зҺҜиҠӮе°ұз»“жқҹдәҶ~~(еҸҰеӨ–еҰӮжһңApplicationClassLoaderд№ҹжІЎжңүжүҫеҲ°д»¬е°ұдјҡжҠӣеҮәClassNotFoundExceptionејӮеёё)
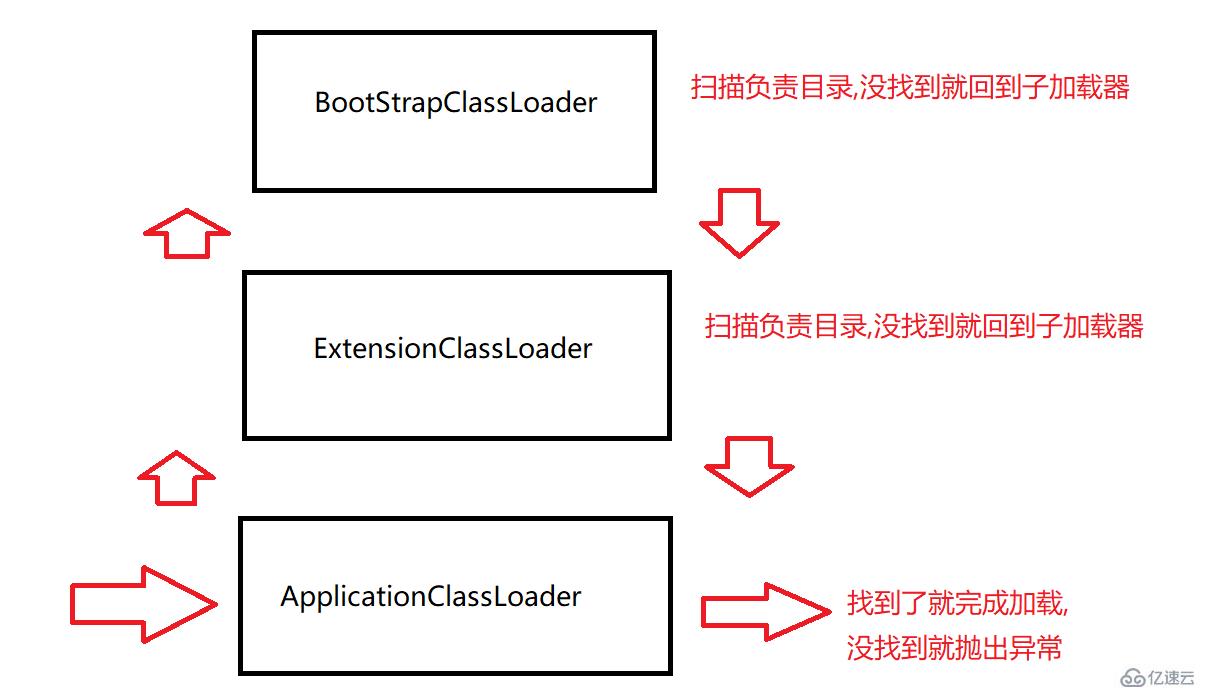
иҝҷдёҖеҘ—жҹҘжүҫ规еҲҷе°ұз§°дёәеҸҢдәІе§”жҙҫжЁЎеһӢ,йӮЈдёәе•ҘJVMиҰҒиҝҷж ·и®ҫи®Ўе‘ў,зҗҶз”ұе°ұжҳҜдёҖж—ҰзЁӢеәҸе‘ҳиҮӘе·ұеҶҷзҡ„зұ»е’Ңе…Ёйҷҗе®ҡзұ»еҗҚйҮҚеӨҚдәҶ,д№ҹиғҪеӨҹжҲҗеҠҹеҠ иҪҪж ҮеҮҶеә“дёӯзҡ„зұ»,иҖҢдёҚжҳҜиҮӘе·ұеҶҷзҡ„зұ»!!!
еҸҰеӨ–еҰӮжһңжҳҜиҮӘе®ҡд№үзҡ„зұ»еҠ иҪҪеҷЁ,иҰҒдёҚиҰҒйҒөе®ҲиҝҷдёӘеҸҢдәІе§”жҙҫжЁЎеһӢе‘ў?
зӯ”жЎҲжҳҜеҸҜд»ҘйҒөе®Ҳд№ҹеҸҜд»ҘдёҚйҒөе®Ҳ,дё»иҰҒзңӢйңҖжұӮ,дҫӢеҰӮTomcatеҠ иҪҪwebappдёӯзҡ„зұ»,е°ұжІЎжңүйҒөе®Ҳ,еӣ дёәйҒөе®ҲдәҶдёҠйқўзҡ„зұ»еҠ иҪҪеҷЁд№ҹжҳҜдёҚеҸҜиғҪжүҫеҲ°зҡ„!
дёү.JVMзҡ„еһғеңҫеӣһ收
JVMдёӯзҡ„еһғеңҫеӣһ收жңәеҲ¶(GC),дёҖиҲ¬еңЁеҶҷд»Јз Ғзҡ„ж—¶еҖҷ,з»Ҹеёёе°ұдјҡж¶үеҸҠеҲ°з”іиҜ·еҶ…еӯҳ,дҫӢеҰӮеҲӣе»әдёҖдёӘеҸҳйҮҸ,newдёҖдёӘеҜ№иұЎ,и°ғз”ЁдёҖдёӘж–№жі•,еҠ иҪҪзұ»вҖҰиҖҢз”іиҜ·еҶ…еӯҳзҡ„ж—¶жңәдёҖиҲ¬жҳҜжҳҺзЎ®зҡ„(йңҖиҰҒдҝқеӯҳжҹҗдёӘжҲ–жҹҗдәӣж•°жҚ®е°ұйңҖиҰҒз”іиҜ·еҶ…еӯҳ),дҪҶжҳҜйҮҠж”ҫеҶ…еӯҳзҡ„ж—¶жңә,еҚҙжҳҜдёҚйӮЈд№Ҳжё…жҘҡзҡ„,йҮҠж”ҫзҡ„ж—©дәҶд№ҹдёҚиЎҢ(еҰӮжһңиҝҳжҳҜиҰҒдҪҝз”Ёзҡ„,з»“жһңе·Із»Ҹиў«йҮҠж”ҫдәҶиҝҷе°ұи®©е…¶ж— еҶ…еӯҳеҸҜз”ЁдәҶ,е°ұи®©иҝҷдәӣж•°жҚ®"ж— еӨ„еҸҜеҺ»"),йҮҠж”ҫзҡ„жҷҡдәҶд№ҹдёҚиЎҢ(йҮҠж”ҫжҷҡдәҶ,еӨ§йҮҸзҡ„еӣӨз§ҜеҫҲжңүеҸҜиғҪи®©еҸҜз”ЁеҶ…еӯҳйҖҗжёҗеҸҳе°‘,еҫҲжңүеҸҜиғҪдјҡеҮәзҺ°еҶ…еӯҳжі„жјҸй—®йўҳ,е°ұжҳҜж— еҶ…еӯҳеҸҜд»ҘдҪҝз”Ё),еӣ жӯӨеҶ…еӯҳзҡ„йҮҠж”ҫиҰҒжҒ°еҲ°еҘҪеӨ„жүҚеҘҪ!
иҖҢеһғеңҫеӣһ收зҡ„жң¬иҒҢжҳҜйқ иҝҗиЎҢж—¶зҺҜеўғйўқеӨ–еҒҡдәҶеҫҲеӨҡзҡ„е·ҘдҪңжқҘе®ҢжҲҗйҮҠж”ҫеҶ…еӯҳж“ҚдҪңзҡ„,иҝҷи®©зЁӢеәҸе‘ҳзҡ„еҝғжҷәиҙҹжӢ…еӨ§еӨ§йҷҚдҪҺдәҶ,дҪҶжҳҜеһғеңҫеӣһ收д№ҹжҳҜжңүеҠЈеҠҝзҡ„:в‘ ж¶ҲиҖ—йўқеӨ–зҡ„ејҖй”Җ(ж¶ҲиҖ—иө„жәҗиҖ•жӣҙеӨҡдәҶ);в‘ЎеҸҜиғҪдјҡеҪұе“ҚзЁӢеәҸзҡ„жөҒз•…иҝҗиЎҢ(еһғеңҫеӣһ收дјҡз»Ҹеёёеј•е…ҘSTWй—®йўҳ(Stop The World))
еһғеңҫеӣһ收зҡ„еҶ…еӯҳжңүе“Әдәӣе‘ў,жҳҜе…ЁйғЁйғҪиҰҒеӣһ收еҳӣ?
еҪ“然дёҚжҳҜдәҶ,е°ұз”ЁдёҠйқўзҡ„еӣӣдёӘеҢәеҹҹжқҘиҜҙдёҖдёӢ:
зЁӢеәҸи®Ўж•°еҷЁ:иҝҷдёӘеҶ…еӯҳжҳҜеӣәе®ҡеӨ§е°Ҹзҡ„,дёҚж¶үеҸҠеҲ°йҮҠж”ҫ,д№ҹе°ұдёҚйңҖиҰҒGCдәҶ;
ж Ҳ:еҪ“еҮҪж•°и°ғз”Ёе®ҢжҜ•,еҜ№еә”зҡ„ж Ҳеё§д№ҹе°ұиҮӘеҠЁйҮҠж”ҫдәҶ,д№ҹжҳҜдёҚйңҖиҰҒGCзҡ„;
е Ҷ:иҝҷжҳҜжңҖйңҖиҰҒGCзҡ„еҶ…еӯҳ,дёҖиҲ¬д»Јз Ғдёӯзҡ„еӨ§йҮҸзҡ„еҶ…еӯҳйғҪеңЁе ҶдёҠ;
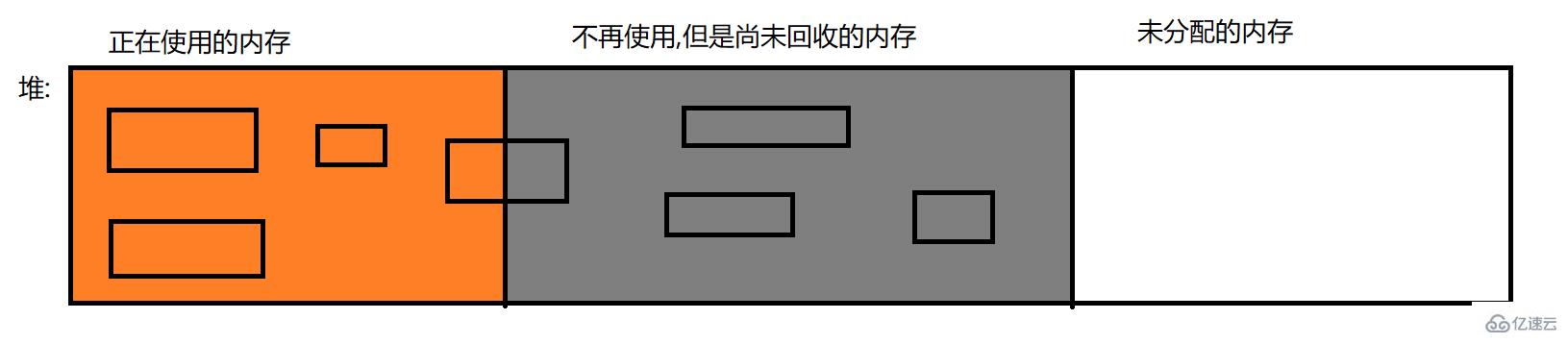
иҖҢиҝҷдёүдёӘеҢәеҹҹеҲ°еә•е“ӘдәӣжҳҜйңҖиҰҒйҮҠж”ҫзҡ„,еҜ№дәҺиҝҷз§ҚдёҖйғЁеҲҶеңЁдҪҝз”Ё,дёҖйғЁеҲҶдёҚеҶҚдҪҝз”Ёзҡ„еҜ№иұЎ,ж•ҙдҪ“жқҘиҜҙе°ұжҳҜдёҚйҮҠж”ҫзҡ„,еҸӘжңүзӯүеҲ°иҝҷдёӘеҜ№иұЎе®Ңе…ЁдёҚеҶҚдҪҝз”Ё,жүҚзңҹжӯЈзҡ„иҝӣиЎҢйҮҠж”ҫ,еӣ жӯӨеңЁGCдёӯе°ұдёҚдјҡеҮәзҺ°еҚҠдёӘеҜ№иұЎзҡ„жғ…еҶө,еӣ жӯӨеһғеңҫеӣһ收зҡ„еҹәжң¬еҚ•дҪҚе°ұжҳҜеҜ№иұЎ,иҖҢдёҚжҳҜеӯ—иҠӮ!
ж–№жі•еҢә:зұ»еҜ№иұЎ,зұ»еҠ иҪҪзҡ„,иҖҢеҸӘжңүиҝӣиЎҢеҲ°зұ»еҚёиҪҪзҡ„ж—¶еҖҷжүҚйңҖиҰҒиҝӣиЎҢйҮҠж”ҫеҶ…еӯҳ,иҖҢеҚёиҪҪж“ҚдҪңжҳҜйқһеёёдҪҺйў‘зҡ„,еӣ жӯӨеҮ д№Һе°ұдёҚж¶үеҸҠеҲ°GC!
дёӢйқўе°ұе…·дҪ“жқҘзңӢдёҖдёӢжҳҜжҖҺд№Ҳеӣһ收зҡ„:
1.жүҫеһғеңҫ/еҲӨе®ҡеһғеңҫ
иҖҢеҪ“дёӢжңүдёӨдёӘдё»жөҒзҡ„ж–№жЎҲ:
1.1.еҹәдәҺеј•з”Ёи®Ўж•°
иҝҷдёҚжҳҜJavaдёӯйҮҮеҸ–зҡ„ж–№жЎҲ,иҝҷжҳҜPythonеҸҠе…¶д»–иҜӯиЁҖзҡ„ж–№жЎҲ,еӣ жӯӨиҝҷйҮҢе°ұз®ҖеҚ•д»Ӣз»ҚдёҖдёӢ,е°ұдёҚиҝҮеӨҡд»Ӣз»ҚдәҶ~
иҖҢеј•з”Ёи®Ўж•°зҡ„е…·дҪ“жҖқи·Ҝе°ұжҳҜй’ҲеҜ№жҜҸдёӘеҜ№иұЎ,йғҪдјҡйўқеӨ–еј•е…ҘдёҖе°Ҹеқ—еҶ…еӯҳ,жқҘдҝқеӯҳиҝҷдёӘеҜ№иұЎжңүеӨҡе°‘дёӘеј•з”ЁжҢҮеҗ‘е®ғ

иҖҢиҝҷж ·зҡ„еј•з”Ёи®Ўж•°еӯҳеңЁдёӨдёӘзјәйҷ·:
з©әй—ҙеҲ©з”ЁзҺҮжҜ”иҫғдҪҺ!!!,жҜҸдёӘnewзҡ„еҜ№иұЎйғҪйңҖиҰҒжҗӯй…ҚдёҖдёӘи®Ўж•°еҷЁ,еҒҮи®ҫдёҖдёӘи®Ўж•°еҷЁ4дёӘеӯ—иҠӮ,еҰӮжһңеҜ№иұЎжң¬иә«жҜ”иҫғеӨ§(еҮ зҷҫдёӘеӯ—иҠӮ),йӮЈд№ҲиҝҷдёӘи®Ўж•°еҷЁе°ұж— жүҖи°“,иҖҢдёҖж—ҰиҝҷдёӘеҜ№иұЎжң¬иә«е°ұжҜ”иҫғе°Ҹ(4дёӘеӯ—иҠӮ),йӮЈд№ҲеҶҚеӨҡеҮәжқҘ4дёӘеӯ—иҠӮ,е°ұзӣёеҪ“дәҺз©әй—ҙеҲ©з”ЁзҺҮе°ұжөӘиҙ№дәҶдёҖеҖҚ,еӣ жӯӨз©әй—ҙеҲ©з”ЁзҺҮдјҡжҜ”иҫғдҪҺ~
жңүеҫӘзҺҜеј•з”Ёзҡ„й—®йўҳ
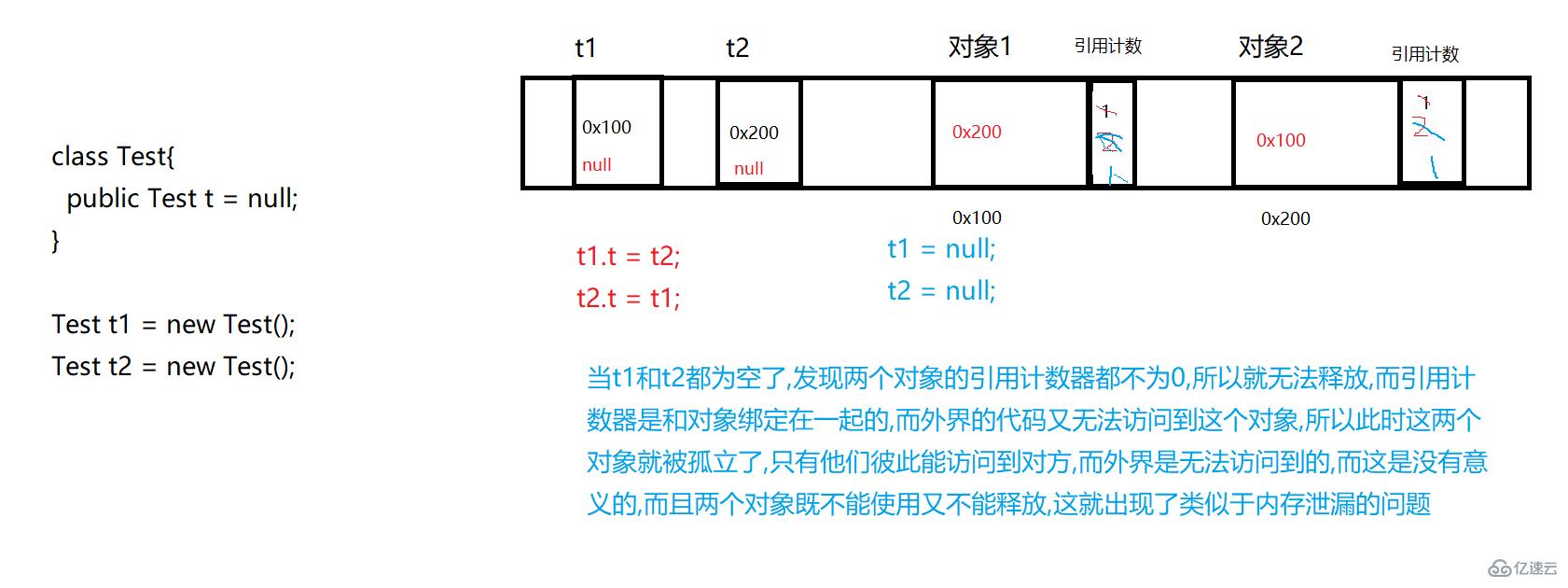
еӣ жӯӨдҪҝз”Ёеј•з”Ёи®Ўж•°д№ҹжҳҜдјҡжңүеӨ§йҮҸзҡ„й—®йўҳеҮәзҺ°зҡ„,иҖҢжғіPython,PHPд№Ӣзұ»зҡ„иҜӯиЁҖд№ҹдёҚжҳҜеҸӘдҪҝз”Ёеј•з”Ёи®Ўж•°еҷЁе°ұе®ҢжҲҗGCзҡ„,д№ҹжҳҜй…ҚеҗҲдәҶдёҖдәӣе…¶д»–зҡ„жңәеҲ¶жқҘе®ҢжҲҗзҡ„!
1.2.еҹәдәҺеҸҜиҫҫжҖ§еҲҶжһҗ
еҸҜиҫҫжҖ§еҲҶжһҗжҳҜJavaжүҖйҮҮеҸ–зҡ„ж–№жЎҲ,еҸҜиҫҫжҖ§еҲҶжһҗжҳҜйҖҡиҝҮдёҖдәӣйўқеӨ–зҡ„зәҝзЁӢ,е®ҡжңҹй’ҲеҜ№ж•ҙдёӘеҶ…еӯҳз©әй—ҙзҡ„еҜ№иұЎиҝӣиЎҢжү«жҸҸ,жңүдёҖдәӣиө·е§ӢдҪҚзҪ®(GCRoots),然еҗҺе°ұзұ»дјјдәҺж·ұеәҰдјҳе…ҲйҒҚеҺҶдёҖж ·(еҸҜд»ҘжғіиұЎжҲҗжҳҜдёҖжЈөж ‘),жҠҠеҸҜд»Ҙи®ҝй—®еҲ°зҡ„еҜ№иұЎйғҪж Үи®°дёҖиҫ№(еёҰжңүж Үи®°зҡ„еҜ№иұЎе°ұжҳҜеҸҜиҫҫзҡ„еҜ№иұЎ),иҖҢжІЎжңүиў«ж Үи®°зҡ„еҜ№иұЎ,е°ұжҳҜдёҚеҸҜиҫҫзҡ„еҜ№иұЎ,д№ҹе°ұжҳҜеһғеңҫ,еә”иҜҘиў«йҮҠж”ҫжҺү!
иҝҷйҮҢзҡ„GCRoots(д»ҺиҝҷдәӣдҪҚзҪ®ејҖе§ӢйҒҚеҺҶ):
еӣ жӯӨеҸҜиҫҫжҖ§еҲҶжһҗзҡ„дјҳзӮ№е°ұжҳҜи§ЈеҶідәҶеј•з”Ёи®Ўж•°зҡ„зјәзӮ№:з©әй—ҙеҲ©з”ЁзҺҮдҪҺ,еҫӘзҺҜеј•з”Ё;иҖҢеҸҜиҫҫжҖ§еҲҶжһҗзҡ„зјәзӮ№д№ҹеҫҲжҳҺжҳҫ:зі»з»ҹејҖй”ҖеӨ§,йҒҚеҺҶдёҖж¬ЎеҸҜиғҪжҜ”иҫғж…ў~
еӣ жӯӨжүҫеһғеңҫд№ҹжҳҜеҫҲз®ҖеҚ•зҡ„,ж ёеҝғе°ұжҳҜзЎ®и®ӨиҝҷдёӘеҜ№иұЎжңӘжқҘжҳҜеҗҰиҝҳдјҡдҪҝз”Ё,зңӢиҝҳжңүжІЎжңүеј•з”ЁжҢҮеҗ‘е®ғ,еә”дёҚеә”иҜҘйҮҠж”ҫжҺү!
2.йҮҠж”ҫеһғеңҫ
既然已з»ҸжҳҺзЎ®дәҶд»Җд№ҲжҳҜеһғеңҫ,жҺҘдёӢжқҘе°ұиҰҒеӣһ收еһғеңҫдәҶ,иҖҢеӣһ收еһғеңҫжңүдёүз§Қеҹәжң¬зӯ–з•Ҙ,дёӢйқўжқҘзңӢдёҖдёӢ!
2.1.ж Үи®°-иҜ·йҷӨ

иҝҷйҮҢзҡ„ж Үи®°е°ұжҳҜеҸҜиҫҫжҖ§еҲҶжһҗзҡ„иҝҮзЁӢ,иҖҢжё…йҷӨе°ұжҳҜйҮҠж”ҫеҶ…еӯҳ,еҒҮи®ҫдёҠйқўжҳҜдёҖеқ—еҶ…еӯҳ,иҖҢжү“й’©зҡ„еҢәеҹҹд»ЈиЎЁжҳҜеһғеңҫ,жӯӨж—¶еҰӮжһңзӣҙжҺҘйҮҠж”ҫжҺү,иҷҪ然еҶ…еӯҳжҳҜиҝҳз»ҷзі»з»ҹдәҶ,дҪҶжҳҜйҮҠж”ҫжҺүзҡ„еҶ…еӯҳжҳҜзҰ»ж•Јзҡ„,дёҚжҳҜиҝһз»ӯзҡ„,иҖҢиҝҷж ·еёҰжқҘзҡ„й—®йўҳе°ұжҳҜ"еҶ…еӯҳзўҺзүҮ",з©әй—Ізҡ„еҶ…еӯҳеҸҜиғҪдјҡжңүеҫҲеӨҡ,еҒҮи®ҫеҠ иө·жқҘдёҖе…ұжҳҜ1G,иҖҢжӯӨж—¶жғіиҰҒз”іиҜ·500MBзҡ„з©әй—ҙ,жҢүзҗҶжҳҜеҸҜд»Ҙз”іиҜ·еҲ°зҡ„,дҪҶеңЁиҝҷйҮҢжҳҜжңүеҸҜиғҪз”іиҜ·еӨұиҙҘзҡ„(еӣ дёәиҰҒз”іиҜ·зҡ„500MBжҳҜиҝһз»ӯзҡ„еҶ…еӯҳ,жҜҸж¬Ўз”іиҜ·зҡ„еҶ…еӯҳйғҪжҳҜиҝһз»ӯзҡ„еҶ…еӯҳз©әй—ҙ,иҖҢиҝҷйҮҢзҡ„1GеҸҜиғҪжҳҜеӨҡдёӘзўҺзүҮеҠ иө·жқҘзҡ„),еӣ жӯӨиҝҷж ·зҡ„й—®йўҳе…¶е®һжҳҜйқһеёёеҪұе“ҚзЁӢеәҸиҝҗиЎҢзҡ„
2.2.еӨҚеҲ¶з®—жі•
з”ұдәҺдёҠйқўзҡ„ж Үи®°-жё…йҷӨзӯ–з•ҘеҸҜиғҪдјҡеёҰжқҘеҶ…еӯҳзўҺзүҮзҡ„й—®йўҳ,еӣ жӯӨеј•е…ҘдәҶеӨҚеҲ¶з®—жі•жқҘи§ЈеҶіиҝҷдёҖй—®йўҳ
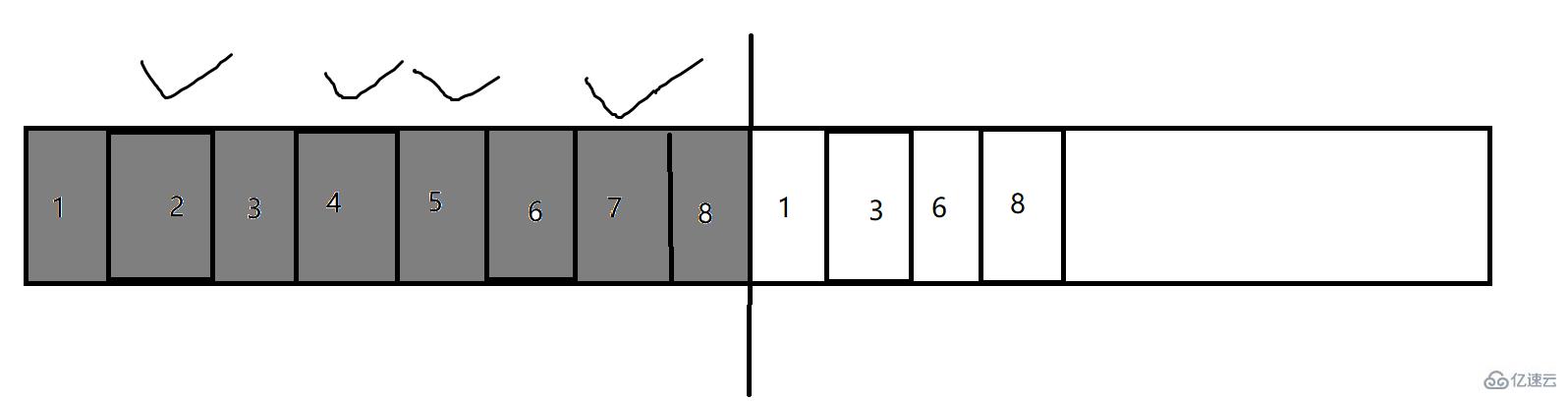
дёҠйқўжҳҜдёҖеқ—еҶ…еӯҳ,еӨҚеҲ¶з®—жі•зҡ„зӯ–з•Ҙе°ұжҳҜеҶ…еӯҳдҪҝз”ЁдёҖеҚҠ,дёўдёҖеҚҠ,дёҚе…ЁйғЁдҪҝз”Ё,еңЁдҪҝз”Ёзҡ„дёҖиҲ¬йҮҢйқўжҠҠдёҚжҳҜеһғеңҫзҡ„жӢ·иҙқеҲ°еҸҰдёҖеҚҠ(иҝҷдёӘжӢ·иҙқжҳҜJVMеҶ…йғЁеӨ„зҗҶеҘҪзҡ„,дёҚз”Ёзә з»“),然еҗҺжҠҠеүҚйқўдҪҝз”Ёзҡ„е…ЁйғЁеҶ…еӯҳйғҪйҮҠж”ҫжҺү,иҝҷж ·еҶ…еӯҳзўҺзүҮзҡ„й—®йўҳе°ұиҝҺеҲғиҖҢи§ЈдәҶ!
жүҖд»ҘеӨҚеҲ¶з®—жі•е°ұжңүдёӨдёӘеҫҲеӨ§зҡ„й—®йўҳ:
еҶ…еӯҳз©әй—ҙеҲ©з”ЁзҺҮдҪҺ(еҸӘдҪҝз”ЁдәҶдёҖиҲ¬зҡ„еҶ…еӯҳ);
еҰӮжһңиҰҒдҝқз•ҷзҡ„еҜ№иұЎеӨҡ,иҰҒйҮҠж”ҫзҡ„еҜ№иұЎе°‘,йӮЈд№ҲеӨҚеҲ¶зҡ„ејҖй”Җе°ұеҫҲеӨ§;
2.3.ж Үи®°-ж•ҙзҗҶ
иҝҷеҸҲжҳҜй’ҲеҜ№еӨҚеҲ¶з®—жі•,еҶҚиҝӣдёҖжӯҘеҒҡеҮәж”№иҝӣ!
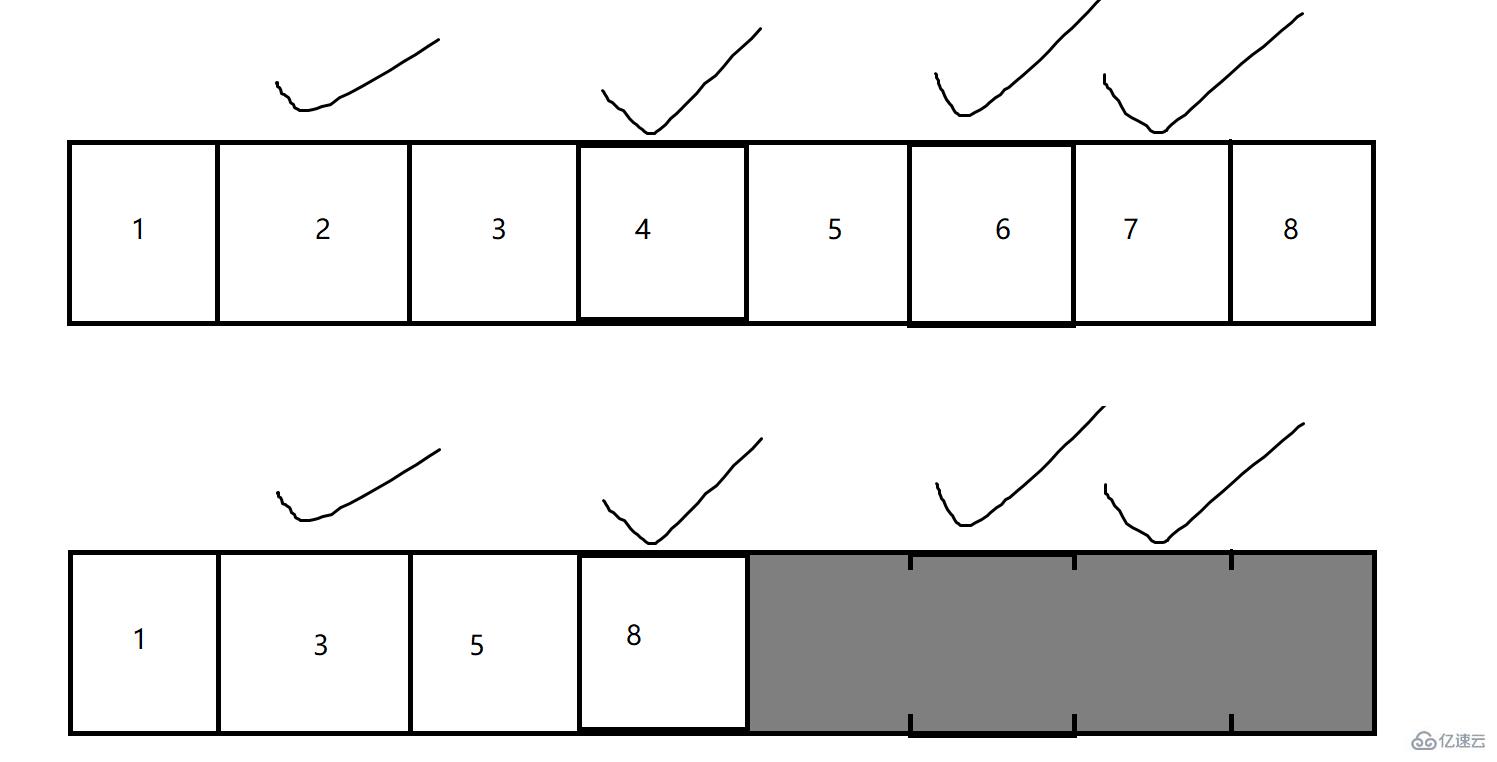
ж Үи®°ж•ҙзҗҶзҡ„зӯ–з•Ҙе°ұжҳҜе°ҶдёҚжҳҜеһғеңҫзҡ„еҶ…еӯҳж•ҙзҗҶеҲ°дёҖиө·,然еҗҺйҮҠж”ҫжҺүеҗҺйқўзҡ„е…ЁйғЁеҶ…еӯҳ,е°ұзұ»дјјдәҺйЎәеәҸиЎЁеҲ йҷӨдёӯй—ҙе…ғзҙ зҡ„ж“ҚдҪңдёҖж ·,жңүдёҖдёӘжҗ¬иҝҗзҡ„иҝҮзЁӢ!
иҝҷдёӘж–№жЎҲз©әй—ҙеҲ©з”ЁзҺҮжҳҜй«ҳдәҶ,дҪҶжҳҜд»Қ然没жңүеҠһжі•и§ЈеҶіеӨҚеҲ¶/жҗ¬иҝҗе…ғзҙ ејҖй”ҖеӨ§зҡ„й—®йўҳ!
дёҠиҝ°зҡ„дёүз§Қж–№жЎҲ,иҷҪ然иғҪеӨҹи§ЈеҶій—®йўҳ,дҪҶжҳҜйғҪжңүеҗ„иҮӘзҡ„зјәйҷ·,еӣ жӯӨе®һйҷ…дёҠJVMдёӯзҡ„е®һзҺ°,дјҡжҠҠеӨҡз§Қж–№жЎҲз»“еҗҲиө·жқҘдҪҝз”Ё,д№ҹе°ұжҳҜ"еҲҶд»Јеӣһ收"!!!
2.4еҲҶд»Јеӣһ收
иҝҷйҮҢзҡ„еҲҶд»Је°ұжҳҜй’ҲеҜ№еҜ№иұЎжқҘиҝӣиЎҢеҲҶзұ»(ж №жҚ®еҜ№иұЎзҡ„"е№ҙйҫ„"иҝӣиЎҢеҲҶзұ»,иҖҢиҝҷйҮҢзҡ„е№ҙйҫ„иЎЁзӨәдёҖдёӘеҜ№иұЎзҶ¬иҝҮдёҖиҪ®GCзҡ„жү«жҸҸ,е°ұз§°"й•ҝдәҶдёҖеІҒ"),иҖҢй’ҲеҜ№дёҚеҗҢе№ҙйҫ„зҡ„еҜ№иұЎ,е°ұйҮҮеҸ–дёҚеҗҢзҡ„ж–№жЎҲ!!!
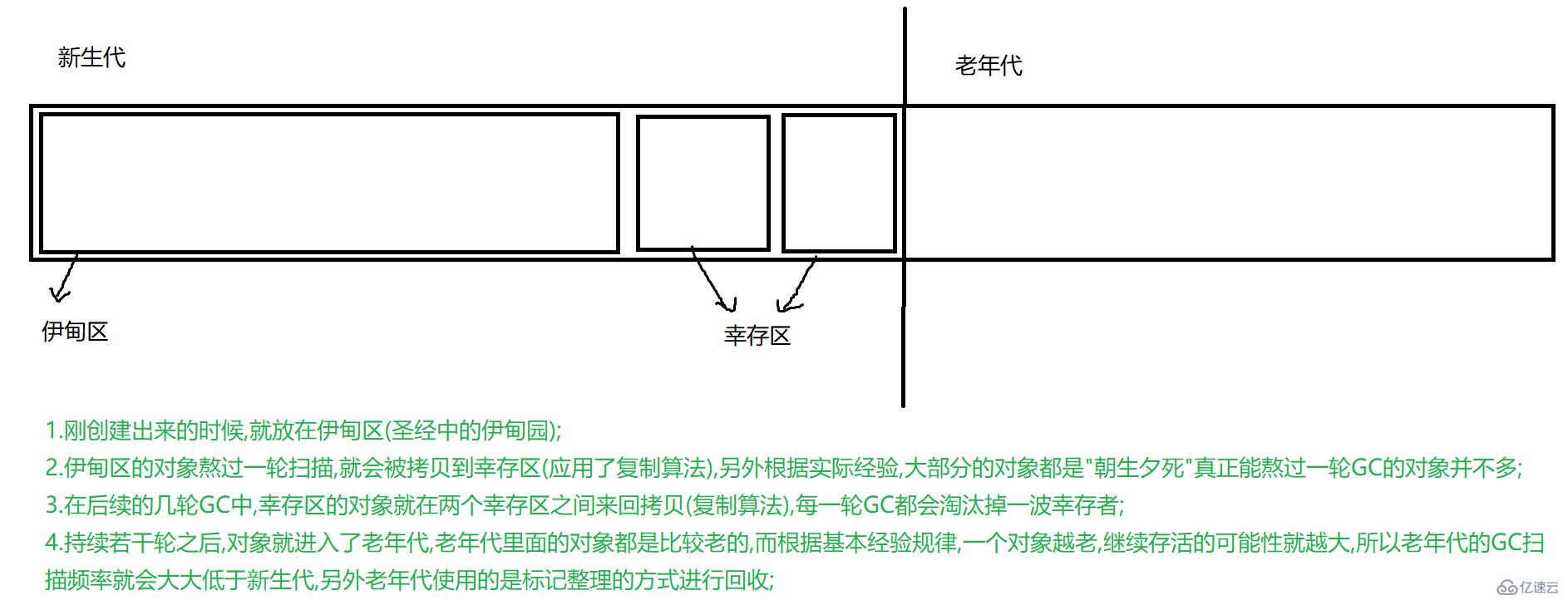
иҝҷе°ұжҳҜж•ҙдёӘеҲҶд»Јеӣһ收зҡ„иҝҮзЁӢ!
3.еһғеңҫеӣһ收еҷЁ
дёҠйқўзҡ„жүҫеһғеңҫе’ҢйҮҠж”ҫеһғеңҫйғҪеҸӘжҳҜз®—жі•зҡ„жҖқжғі,并дёҚжҳҜзңҹжӯЈзҡ„иҗҪең°е®һзҺ°зҡ„иҝҮзЁӢ,иҖҢзңҹжӯЈе®һзҺ°дёҠиҝ°з®—жі•жЁЎеқ—зҡ„жҳҜ"еһғеңҫеӣһ收еҷЁ",дёӢйқўжқҘд»Ӣз»ҚдёҖдәӣе…·дҪ“зҡ„еһғеңҫеӣһ收еҷЁ:
3.1.Serial收йӣҶеҷЁе’ҢSerial Old收йӣҶеҷЁ
Serial收йӣҶеҷЁжҳҜз»ҷж–°з”ҹд»ЈжҸҗдҫӣзҡ„еһғеңҫеӣһ收еҷЁ,Serial Old收йӣҶеҷЁжҳҜз»ҷиҖҒе№ҙд»ЈжҸҗдҫӣзҡ„еһғеңҫеӣһ收еҷЁ,иҝҷдёӨдёӘ收йӣҶеҷЁжҳҜдёІиЎҢ收йӣҶзҡ„,иҖҢдё”еңЁиҝӣиЎҢеһғеңҫзҡ„жү«жҸҸе’ҢйҮҠж”ҫзҡ„ж—¶еҖҷ,дёҡеҠЎзәҝзЁӢиҰҒеҒңжӯўе·ҘдҪң,жүҖд»Ҙиҝҷж ·зҡ„ж–№ејҸжү«жҸҸзҡ„ж»Ў,йҮҠж”ҫзҡ„д№ҹж…ў,иҖҢдё”д№ҹиғҪдә§з”ҹдёҘйҮҚзҡ„STW!
3.2.ParNew收йӣҶеҷЁ,Parallel Scavenge收йӣҶеҷЁе’ҢParallel Old收йӣҶеҷЁ
ParNew收йӣҶеҷЁ,Parallel Scavenge收йӣҶеҷЁйғҪжҳҜжҸҗдҫӣз»ҷж–°з”ҹд»Јзҡ„,Parallel Scavenge收йӣҶеҷЁжҜ”иө·ParNew收йӣҶеҷЁеҠ дәҶдёҖдәӣеҸӮж•°,еҸҜд»ҘжҺ§еҲ¶STWзҡ„ж—¶й—ҙ,е°ұжҳҜеӨҡдәҶдёҖдәӣжӣҙејәзҡ„еҠҹиғҪ,Parallel Old收йӣҶеҷЁжҳҜжҸҗдҫӣз»ҷиҖҒе№ҙд»Јзҡ„,иҝҷдёүдёӘ收йӣҶеҷЁйғҪжҳҜ并иЎҢ收йӣҶзҡ„,е°ұжҳҜеј•е…ҘдәҶеӨҡзәҝзЁӢзҡ„ж–№ејҸжқҘи§ЈеҶіжү«жҸҸеһғеңҫе’ҢйҮҠж”ҫеһғеңҫзҡ„еҠҹиғҪ!
дёҠйқўзҡ„иҝҷеҮ дёӘеӣһ收еҷЁйғҪжҳҜеҺҶеҸІйҒ—з•ҷдёӢжқҘзҡ„,д№ҹе°ұжҳҜжҜ”иҫғиҖҒзҡ„еһғеңҫеӣһ收方ејҸ,еҸҰеӨ–еҶҚд»Ӣз»ҚдёӨдёӘжӣҙж–°зҡ„еһғеңҫеӣһ收еҷЁ!
3.3.CMS收йӣҶеҷЁ
CMS收йӣҶеҷЁи®ҫи®Ўзҡ„жҜ”иҫғе·§еҰҷ,е…¶и®ҫи®Ўзҡ„еҲқиЎ·жҳҜе°ҪеҸҜиғҪи®©STWж—¶й—ҙзҹӯ,Java8дҪҝз”Ёзҡ„жӯЈжҳҜCMS收йӣҶеҷЁ,дёӢйқўз®ҖеҚ•д»Ӣз»ҚдёҖдёӢCMS收йӣҶеҷЁзҡ„иҝҮзЁӢ:
еҲқе§Ӣж Үи®°:йҖҹеәҰеҫҲеҝ«,дјҡеј•иө·зҹӯжҡӮзҡ„STW(еҸӘжҳҜжүҫеҲ°GCRoots);
并еҸ‘ж Үи®°:йҖҹеәҰеҫҲеҝ«,дҪҶжҳҜеҸҜд»Ҙе’ҢдёҡеҠЎзәҝзЁӢ并еҸ‘жү§иЎҢ,дёҚдјҡдә§з”ҹSTW;
йҮҚж–°ж Үи®°:еңЁ2дёҡеҠЎд»Јз ҒеҸҜиғҪдјҡеҪұе“Қ并еҸ‘ж Үи®°зҡ„з»“жһң(дёҡеҠЎзәҝзЁӢеңЁжү§иЎҢ,е°ұжңүеҸҜиғҪдә§з”ҹж–°зҡ„еһғеңҫ),еӣ жӯӨиҝҷдёҖжӯҘе°ұжҳҜй’ҲеҜ№2зҡ„з»“жһңиҝӣиЎҢеҫ®и°ғ,иҷҪ然дјҡеј•иө·STW,дҪҶеҸӘжҳҜеҫ®и°ғ,йҖҹеәҰеҫҲеҝ«;
дёҠйқўдёүжӯҘйғҪжҳҜеҹәдәҺеҸҜиҫҫжҖ§еҲҶжһҗ!
еӣһ收еҶ…еӯҳ:д№ҹжҳҜе’ҢдёҡеҠЎзәҝзЁӢ并еҸ‘жү§иЎҢ,дёҚдјҡдә§з”ҹSTW,иҝҷжҳҜеҹәдәҺж Үи®°ж•ҙзҗҶ;
3.4.G1收йӣҶеҷЁ
G1收йӣҶеҷЁжҳҜе”ҜдёҖдёҖж¬ҫе…ЁеҢәеҹҹзҡ„еһғеңҫеӣһ收еҷЁ,д»ҺJava11ејҖе§ӢдҪҝз”Ёзҡ„е°ұжҳҜG1收йӣҶеҷЁ,иҝҷдёӘ收йӣҶеҷЁжҳҜжҠҠж•ҙдёӘеҶ…еӯҳ,еҲҶжҲҗдәҶеҫҲеӨҡе°Ҹзҡ„еҢәеҹҹRegion,з»ҷиҝҷдәӣRegionиҝӣиЎҢдәҶдёҚеҗҢзҡ„ж Үи®°,жңүзҡ„Regionж”ҫж–°з”ҹд»ЈеҜ№иұЎ,жңүзҡ„Regionж”ҫиҖҒе№ҙд»ЈеҜ№иұЎ,然еҗҺжү«жҸҸзҡ„ж—¶еҖҷ,е°ұдёҖж¬Ўжү«жҸҸиӢҘе№ІдёӘRegion(дёҚиҝҪжұӮдёҖиҪ®GCе°ұжү«жҸҸе®Ң,йңҖиҰҒеҲҶеӨҡж¬Ўжү«жҸҸ),иҝҷж ·еҜ№дәҺдёҡеҠЎд»Јз Ғзҡ„еҪұе“Қд№ҹжҳҜжңҖе°Ҹзҡ„,
иҝҷдёӨдёӘж–°зҡ„收йӣҶеҷЁзҡ„ж ёеҝғжҖқжғіе°ұжҳҜеҢ–ж•ҙдёәйӣ¶,G1еҪ“дёӢеҸҜд»ҘдјҳеҢ–еҲ°и®©STWеҒңйЎҝж—¶й—ҙе°ҸдәҺ1ms,иҝҷжҳҜе®Ңе…ЁеҸҜд»ҘжҺҘ收зҡ„!дёҠйқўе°ұжҳҜе…ідәҺJVMзҡ„дёҖдәӣеӯҰд№ дәҶ,иҝҷйҮҢзҡ„收йӣҶеҷЁдё»иҰҒиҝҳжҳҜдәҶи§Јдёәдё»,дё»иҰҒиҝҳжҳҜдёҠйқўзҡ„еһғеңҫеӣһ收жҖқжғіеҫҲйҮҚиҰҒ!!!
д»ҘдёҠе°ұжҳҜвҖңJavaд№ӢJVMзҡ„зҹҘиҜҶзӮ№жңүе“ӘдәӣвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« йғҪжңүеҫҲеӨ§зҡ„收иҺ·пјҢе°Ҹзј–жҜҸеӨ©йғҪдјҡдёәеӨ§е®¶жӣҙж–°дёҚеҗҢзҡ„зҹҘиҜҶпјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҡ„зҹҘиҜҶпјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





